移动应用的爆炸性增长,用户界面(UI)的设计越来越复杂,功能也越来越丰富。但现有的多模态大模型(MLLMs)在理解用户界面时存在局限,尤其是在处理具有特定分辨率和包含众多小型对象(如图标、文本)的移动 UI 屏幕时。这些模型通常难以准确识别和操作界面上的特定元素,也难以执行基于自然语言指令的复杂任务。
苹果团队提出的Ferret-UI,正是为了解决这一问题而设计的。它是一款专门针对移动 UI 屏幕理解而优化的 MLLM,具备强大的引用、定位和推理能力。通过创新的“任意分辨率”技术,Ferret-UI 能够放大 UI 屏幕上的细节,并通过精确的区域注释来增强视觉特征的编码。这使得 Ferret-UI 能够在不同尺寸和方向的屏幕上,对 UI 元素进行更准确的识别和操作,从而更好地理解和响应用户的指令。

Ferret-UI 的训练涉及从基础到高级的广泛任务,包括图标识别、文本查找、控件列表生成,以及详细描述、感知/交互对话和功能推断等。这些训练样本的精心策划和格式化,为模型提供了丰富的视觉和空间知识,使其能够在更深层次上理解 UI,并执行开放性指令。
方法
Ferret-UI 模型是在 Ferret 模型的基础上发展起来的。Ferret 是一个多模态大型语言模型,擅长处理自然图像中的引用和定位任务。然而,移动 UI 屏幕通常具有不同于自然图像的特定特征,例如更长的屏幕比例和更小的交互元素。为了解决这一问题,Ferret-UI 引入了“任意分辨率”技术,允许模型自适应不同尺寸和比例的屏幕。

Ferret-UI-anyres在 Ferret-UI-base 的基础上进行了扩展,以包含更细粒度的图像特征。
-
预训练图像编码器和投影层: Ferret-UI-anyres 使用了一个预训练的图像编码器(例如 CLIP-ViT-L/14)来处理整个屏幕的图像,并生成图像特征。这些特征为模型提供了对屏幕全局内容的理解。
-
子图像的额外图像特征: 根据原始图像的纵横比,屏幕被划分为子图像。每个子图像都独立地通过相同的图像编码器进行处理,以生成额外的图像特征。这种处理方式使得模型能够捕捉到更多的细节,尤其是在屏幕元素较小或距离较远时。
-
视觉采样器: 对于具有区域引用的文本,Ferret-UI-anyres 包含一个视觉采样器,它生成与文本区域相对应的连续特征。这使得模型能够更精确地理解和定位屏幕上的文本内容。
-
大模型(LLM)的集成使用: Ferret-UI-anyres 的核心是一个大模型,它利用全图像表示、子图像表示、区域特征和文本嵌入来生成响应。模型在生成回答时,不仅考虑了整体屏幕内容,还包括了细节层面的信息。
-
多模态特征融合: 模型融合了来自不同源的特征,包括全局和局部的视觉信息,以及与特定区域相关的文本信息。这种多模态特征的融合为模型提供了丰富的上下文,使其能够更准确地理解用户指令并做出适当的响应。
-
灵活适应不同纵横比: Ferret-UI-anyres 的架构设计使其能够灵活适应不同纵横比的屏幕,无论是垂直还是水平方向的屏幕,模型都能够有效地处理。
通过这种架构设计,Ferret-UI-anyres 能够更全面地理解和分析移动 UI 屏幕,从而在执行引用、定位和推理任务时表现出更高的准确性和效率。这种设计不仅提升了模型对 UI 元素的理解,也为处理更加复杂的用户界面交互任务提供了可能。
Ferret-UI 的任意分辨率技术是其创新之处。这项技术通过将屏幕分割成多个子图像来增强模型对细节的捕捉能力。具体来说,根据屏幕的原始纵横比,模型会选择最合适的网格配置(1x2 或 2x1),然后将屏幕调整大小以适应所选网格,并将其分割成子图像。这样,无论是纵向还是横向的屏幕,模型都能够捕捉到重要的视觉细节。
Ferret-UI 使用预训练的视觉编码器(如 CLIP-ViT-L/14)来提取整个屏幕和每个子图像的图像特征。这些特征随后通过投影层转换成适合语言模型处理的格式。这种转换使得语言模型能够更好地理解和处理视觉信息。
Ferret-UI 设计了一个空间感知的视觉采样器,用于处理具有区域引用的文本,生成相应的区域连续特征。这种采样器能够处理不同稀疏级别的区域形状的连续特征,从而增强模型对屏幕特定区域的理解和响应。
Ferret-UI 包括了一系列 UI 引用任务(如 OCR、图标识别、控件分类)和定位任务(如查找文本/图标/控件、控件列表)。这些任务帮助模型建立起对 UI 元素的语义和空间定位的理解,为高级 UI 交互打下了坚实的基础。
通过这些方法和技术的整合,Ferret-UI 能够更深入地理解移动 UI 屏幕,并有效地执行开放性的语言指令。这些技术的融合为移动 UI 自动化和智能化提供了新的可能性,推动了人机交互领域的进一步发展。
数据集与任务构建
为了训练 Ferret-UI,研究团队首先需要收集多样化的移动 UI 屏幕图像。这包括从 Android 和 iPhone 设备中获取的屏幕截图。对于 Android,团队使用了 RICO 数据集的一个子集,特别是 Spotlight 任务中公开可用的数据。而对于 iPhone,使用了 AMP 数据集,涵盖了广泛的应用程序,并从中随机选择了一部分进行训练和测试数据的划分。还使用了预训练的像素级 UI 检测模型来收集屏幕元素的细粒度注释,包括 UI 类型、边界框和显示的文本。

表 1 提供了移动 UI 屏幕和训练数据的统计信息,这些数据为 Ferret-UI 的训练提供了丰富的素材,确保模型能够在多种 UI 场景下学习和泛化。团队采用了三种不同的方法来构建数据集:
重新格式化 Spotlight:将 Spotlight 任务中的 screen2words、widgetcaptions 和 taperception 格式化成对话式 QA 对。使用 GPT-3.5 Turbo 从基础提示生成多样化的提示,并将这些提示与原始图像和正确答案配对。
基础任务:除了 Spotlight 任务外,团队还使用配对屏幕和 UI 元素生成了依赖于定位和引用能力的新 UI 任务数据。这包括为 Android 和 iPhone 屏幕分别引入了 7 个任务:OCR、图标识别和控件分类作为引用任务;以及控件列表、查找文本、查找图标和查找控件作为定位任务。每种任务都使用 GPT-3.5 Turbo 来扩展基础提示,引入任务问题的不同变体。

高级任务:为了将推理能力整合到模型中,团队遵循 LLaVA 的方法,并使用 GPT-4 收集了 4 种更多格式的数据。这部分数据收集专注于 iPhone 屏幕,并筛选出具有 2 到 15 个检测结果的示例。这些示例连同提示一起发送给 GPT-4,以创建所需格式的数据。高级任务包括详细描述、对话感知、对话交互和功能推断。对于这些任务,团队扩展了基础提示,并将它们与 GPT-4 的响应配对作为模型训练的输入数据。

实验
Ferret-UI-anyres(集成了任意分辨率功能的版本)和Ferret-UI-base(直接遵循Ferret架构的版本)在训练时对解码器和投影层进行了更新,而视觉编码器保持冻结。所有训练数据被格式化为遵循指令的格式,并且训练目标与Ferret中的相同。训练混合数据集包含250K样本,Ferret-UI-base在8个A100 GPU上训练需要1天,而Ferret-UI-anyres需要大约3天。
实验结果显示,Ferret-UI 在多个任务上均优于基线模型,包括公共基准测试(Spotlight 任务)以及基础和高级 UI 任务。特别是在 iPhone 和 Android 平台上的高级任务中,Ferret-UI 显示出了卓越的性能,这表明了模型在不同操作系统上的良好迁移能力。



消融研究部分探讨了不同因素对模型性能的影响。首先是对高级任务的消融研究,研究了基础任务数据对模型处理高级任务能力的影响。结果显示,基础任务数据的加入显著提升了模型在高级任务上的表现,这支持了基础任务有助于增强模型视觉和空间理解的假设。其次,对 Spotlight 任务的消融研究显示,将高级任务数据与所有基础任务数据结合使用时,能够获得最佳性能。

在基础 UI 任务的分析中,Ferret-UI 在 OCR 和控件分类预测方面表现出色。OCR 分析揭示了模型在处理小文本和接近其他文本的文本时的挑战,以及模型倾向于预测实际单词而非仅仅是屏幕上显示的字符。而且Ferret-UI 能够准确预测部分被切断的文本。控件分类分析显示,模型在理解控件间关系时存在困难,例如,大型按钮由多个子元素组成时,模型可能将其错误分类为占据空间最大的子元素。



在高级 UI 任务的分析中,Ferret-UI 在进行基于上下文的对话时,其输出的边界框在正确性和相关性方面表现良好。手动评估了 Ferret-UI 和 GPT-4V 的对话交互输出中的所有输出框,Ferret-UI 的准确度达到了 91.7%,而 GPT-4V 为 93.4%。尽管 Ferret-UI 在评估得分上略低于 GPT-4V,但观察预测结果表明,GPT-4V 倾向于提供可能与问题不相关的额外信息,而 Ferret-UI 的简洁答案在某些情况下可能更为准确。
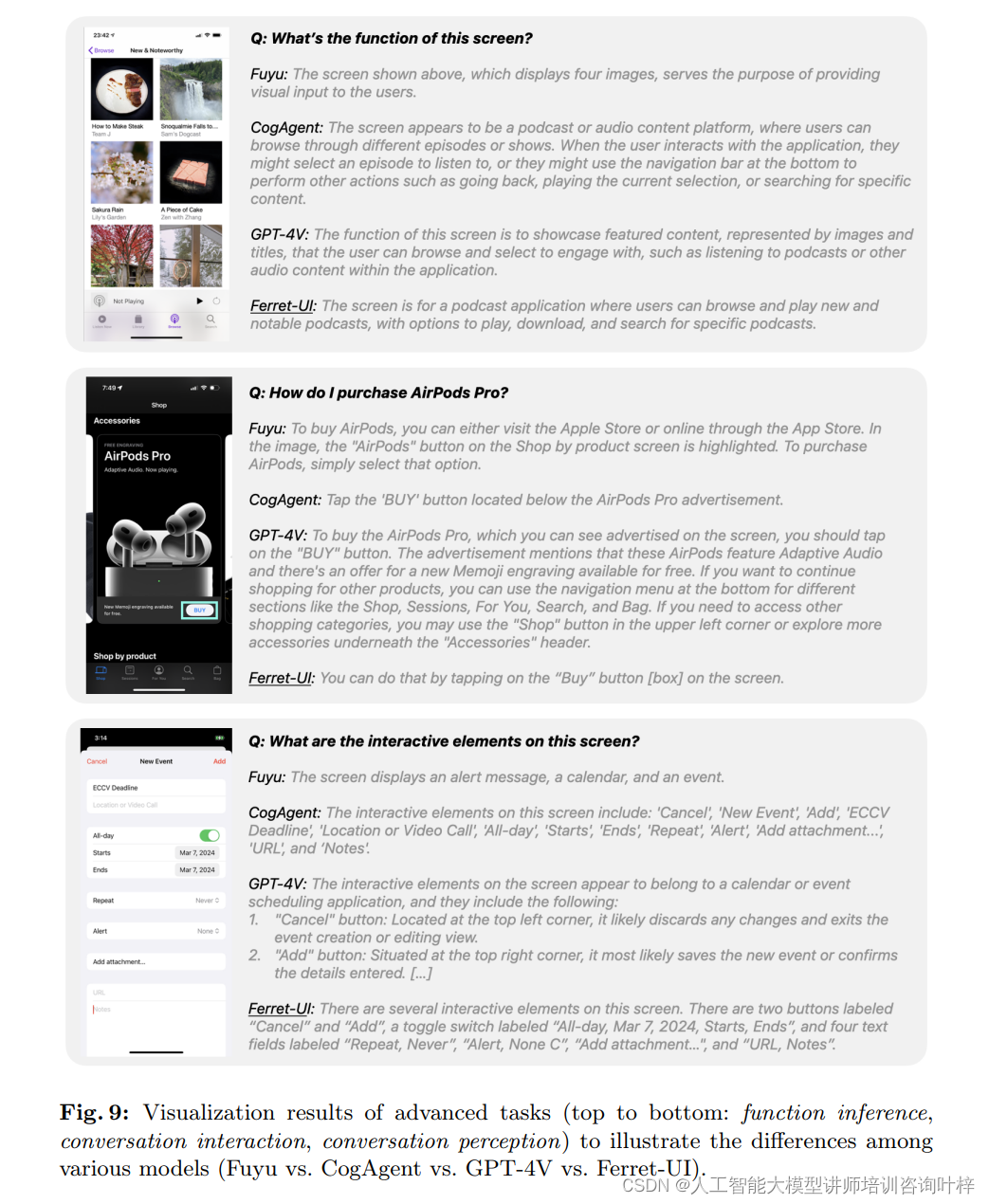
通过这些实验,Ferret-UI 证明了其在理解和交互移动 UI 屏幕方面的先进能力,特别是在处理复杂和开放式任务时的优越性能。这些结果不仅展示了 Ferret-UI 的技术实力,也为未来的 UI 自动化和智能化提供了有力的支持。
论文链接:https://arxiv.org/abs/2404.05719