文章目录
- 前言
- part0 资源准备
- 基本功能
- 语料
- 停用词
- 问答
- 闲聊语料
- 获取
- part01句的表达
- 表达
- one-hot编码
- 词嵌入
- 大致原理
- 实现
- 简单版
- 复杂版
- 如何训练
- 转换后的形状
- part02 循环神经网络
- RNN
- RNN投影图
- RNN是三维立体的
- LSTM&GRU
- part03意图识别
- 分词
- FastText分类
- FastText网络结构
- 优化点
- 构造FastText数据集
- 训练
- part04 闲聊对话
- Seq2Seq
- 网络结构
- 输入与输出(编/解码器)
- 数据准备
- 构造词典
- 数据加载
- 网络搭建
- 编码器
- 解码器
- 注意力机制
- 训练
- 搭建seq网络
- 训练
- 推理
- BeamSearch
- 完整过程
- Part05 问答处理
- 简单思路
- 难点
- 上文分割线
前言
okey,许久不见甚是想念,那么今天的话也是来开启一个新的一个章节吧。当然承认最近是有在划水,但是问题不大。那么今天的话咱们就是来填一填以前的坑,吹过的牛皮总还是要实现的。那么在这边咱们的目的是实现出一个简单一点的AI助手,通过我们的文本来实现一些对话,问答之类的一些处理。从基础部分,一步一步实现一个这样的小AI,在未来你还可以打造属于自己的一个数据集,同时在这个架构的基础上不断优化,在未来的某一天也许是有机会得到一个专属于你的一个AI对象的。
所以咱们今天给出的还是一个baseline。同时本文的风格也是慢慢来递进的,从最基础的尺度表达,到搭建一个网络,再到基本的优化,最后是一个封装。
项目开源地址:
https://github.com/Huterox/xiaojiejieBoot.git
咱们的这个机器人就叫叫作“小姐姐”。是的非常的直接:Although I have been rejected, I will not give up.
对应语料资源:
https://github.com/codemayq/chinese_chatbot_corpus
基本要求,阅读本篇文章需要一定的门槛:
- 熟练掌握python
- 了解基本的深度学习知识
- 会使用pytorch搭建神经网络
- 具备一定的抽象能力(受限于篇幅问题,本博文在原理部分只能做简化,因此重点还是实战(或者说,都在代码里面了),但是对应相应内容都会进行一个介绍,和我认为比较容易不太好理解的点,所以如果想要完善理论部分的话,建议自行深入,这里更多是科普,之后是代码实现,你将这部分作为灰盒子就好了,因为你还是可以调参,准备自己的数据集的)
part0 资源准备
ok,在开始之前呢,咱们先来说说在咱们本篇博文当中,咱们是怎么设计的,需要使用到哪些资源。
基本功能
先来看到咱们的这个基本功能的一个样例图吧:
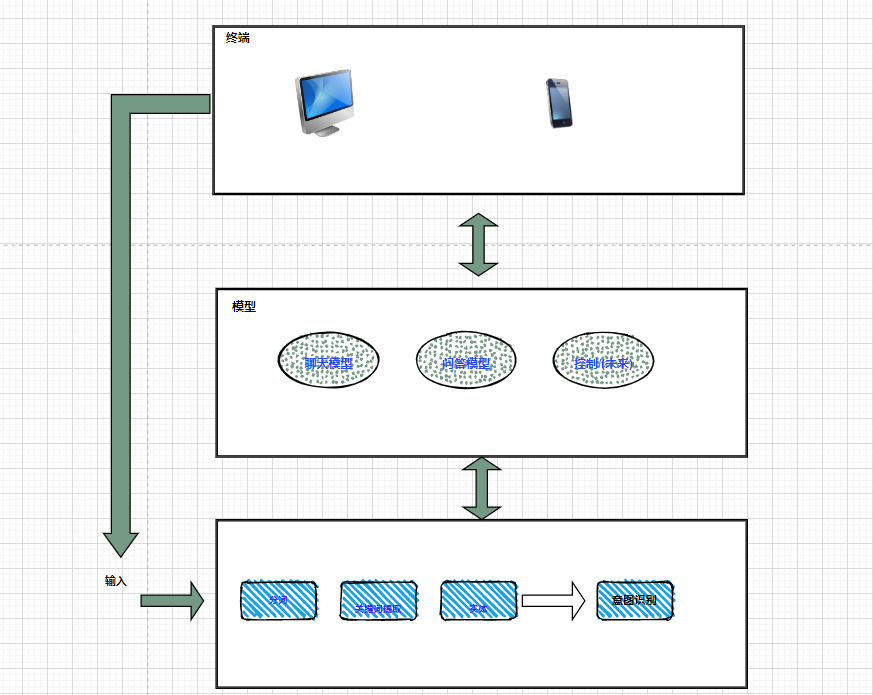
所以的话,咱们这边有问答功能,和闲聊功能,现在的话,那么闲聊的话其实顾名思义,其实就是说如果你想要让这个AI能够就是说像情侣一样对话的话,那么这个闲聊就是咱们的这个恋爱聊天功能,也就是所谓的AI女友的最基本的一个对话雏形。
语料
ok,看到了咱们的一个具体的大致的功能,那么咱们接下来要做的就是说,我们需要使用到哪些东西。首先的话,由于咱们只是先做一个baseline级别的dome,加上咱们的这个算力确实比较那啥。所以的话,咱们的这个语料都是做了一个简要的删减,因为确实是太多了。
那么首先咱们这边使用的主要是这四个东西:
首先第一个是百度问答的问答对一共是5W,还有小黄鸡的一个语料库,大概是50W条问答。
之后第百度停用词和汉语词库。大概就这几个。那么如果你是想要做AI情侣的话,那么就需要把小黄鸡的一个语料库,换成这个对应的恋爱对话的一个语料(你可以尝试把你和你对象的对话搞过来,但是量得足够大,那么咱们这边就不去搞这种,一方面是我搞不到这个数据集,也没有没有办法从自己身上收集,另一方面确实不太合适,但是方法我还是会说的)
之后的话,咱们来看看一看咱们的这个格式:
停用词
打开之后的话,格式大概是这样的:

词库的格式也是类似的。
问答
之后的是问答的一个语料,这个是百度的一个问答,通过数据处理之后的一个格式。这边整理好了。格式是这样的:

问答对。
闲聊语料
这个闲聊也简单,是这样的:

E 是开始标志
M 对话
这个到时候怎么用,咱们在后面再说。
获取
之后的话是咱们的一个资源的获取。
这块的资源的话都已经打包好了在这:
链接:https://pan.baidu.com/s/1Bb0sWcITQLrkibDqIT8Qvg
提取码:6666
part01句的表达
表达
计算机和我们人类是不一样的,他只能进行基本的数字运算,在咱们先前的图像处理当中,图像的表达依然还是通过数值矩阵的,但是一个句子或者单纯是如何表示的呢。所以为了能够让计算机可以处理到咱们的文本数据,咱们需要对文本做一点点处理。
那么在这里是如何做的呢,其实很简单,既然计算机只能处理数字,对数字进行运算,那么我们只需要把我们的一个句子转化为一种向量就好了。那么这个是如何做的呢?
其实非常简单。
看下面一组图就明白了:
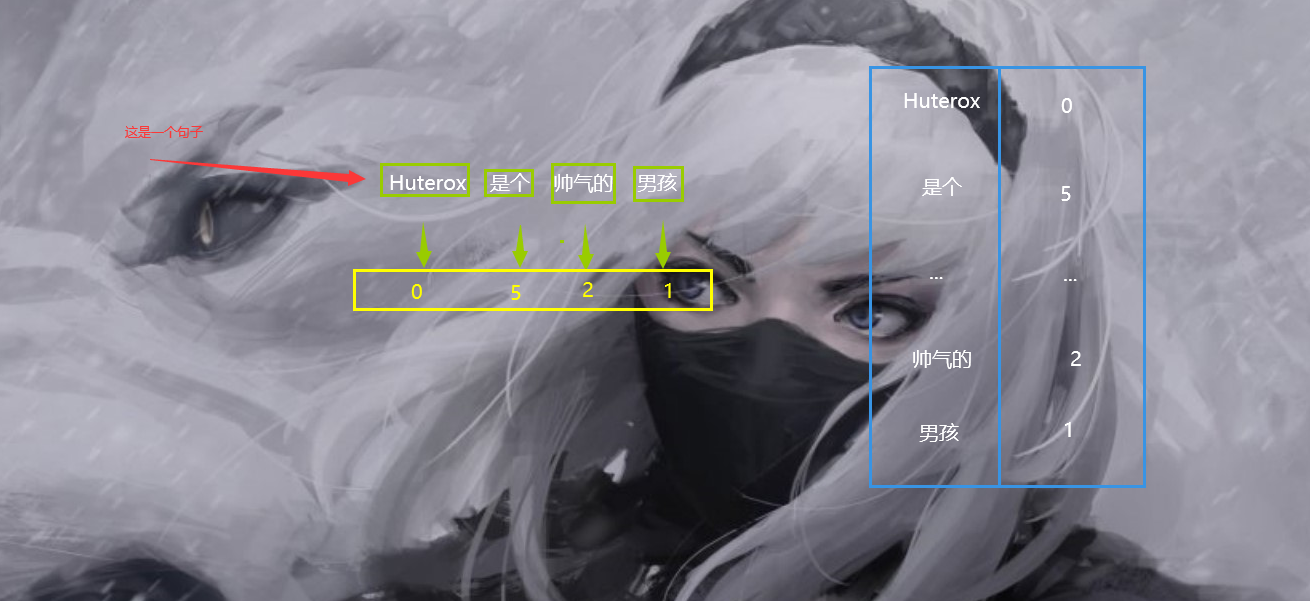
我们通过一个词典其实就可以完成一个向量的映射。
看到了吧,我们这个时候我们只需要对一个句子进行分词,之后将每一个词进行标号,这样一来就可以实现把一个句子转化为一个向量。
one-hot编码
此时我们得到了一组序列,但是这个序列的表达能力是在是太弱了,只能表示出一个标号,不能表示出其他的特点。或者说,只有一个数字表示一个词语实在是太单调了,1个词语也应该由一个序列组成。那么这个时候one-hot编码就出来了。他是这样做的:

首先一个词,一个字,我们叫做token,那么编码的很简单。其实就是这样:

但是这样是有问题的,那就是说,我们虽然实现了一个词到向量的表示。但是这个表示方法显然是太大了,假设有10000个词语,那么按照这种方式进行标号的话,那么1个词就是10000个维度。这样显然是不行的。所以这块需要优化一下。
词嵌入
这个原来解释起来稍微复杂一点。你只需要需要知道他们的本质其实就是这样的:
词 ——> 向量空间1 ——> 向量空间2
现在向量空间1不合适,所以我们要想办法能不能往空间2进行靠拢。
于是乎这里大概就有了两个方案:
1)尝试将词向量映射到一个更低维的空间;
2)同时保持词向量在该低维空间中具备语义相似性,如此,越相关的词,它们的向量在这个低维空间里就能靠得越近。
对于第一个,咱们可以参考原来咱们做协同过滤推荐dome的时候,使用SVD矩阵分解来做。(关于这篇博文的话也是有优化的,优化方案将在本篇博文中查看到,先插个眼)
那么缺点的话也很明显嘛,用咱们的这个方案:
1)亲和矩阵的维度可能经常变,因为总有新的单词加进来,每加进来一次就要重新做SVD分解,因此这个方法不太通用;
2)亲和矩阵可能很稀疏,因为很多单词并不会成对出现。
大致原理
ok,回到咱们的这个(这部分可以选择跳过,知道这个玩意最后得到的是啥就好了),这个该怎么做,首先的话,实现这个东西,大概是有两种方案去做:Continuous Bag Of Words (CBOW)方法和n-gram方法。第一个方案的话,这个比较复杂,咱们这里就不介绍了。
咱们来说说第二个方案。
首先咱们来说说啥是N-gram,首先原理的话也是比较复杂的,具体参考这个:https://blog.csdn.net/songbinxu/article/details/80209197
那么我们这边就是简单说一下这个在咱们这边N-gram实际是咋用的。
[cuted[i:i+2]for i in range(len(cuted))]
其实就是这个,用代码表示,cuted是一个分好词的句子。i+2表示跨越几个。
这样做的好处是,通过N-gram可以考虑到词语之间的一个关系,如果我们使用这个方案来实现一个词向量的话,那么我们必然是可以能够实现:“同时保持词向量在该低维空间中具备语义相似性,如此,越相关的词,它们的向量在这个低维空间里就能靠得越近。”的。因为确实考虑到了之间的一个关系,那么现在我们已经知道了大概N-garm是怎么样的了,其实就是一种方式,将一个句子相近的词语进行连接,或者说是对句子进行一个切割,上面那个只是一种方式只有,这个我们在后面还会有说明,总之它是非常好用的一种方式。
ok,知道了这个我们再来介绍几个名词:
1.跳词模型
跳词模型,它是通过文本中某个单词来推测前后几个单词。例如,根据‘rabbit’来推断前后的单词可能为‘a’,‘is’,‘eating’,‘carrot’。在训练模型时我们在文本中选取若干连续的固定长度的单词序列,把前后的一些单词作为输出,中间的某个位置的单词作为输入。
2.连续词袋模型
连续词袋模型与跳词模型恰好相反,它是根据文本序列中周围单词来预测中心词。在训练模型时,把序列中周围单词作为输入,中心词作为输出。
这个的话其实和我们的这个关系不大,因为N-gram其实是句子–>词 的一种方式,但是对我训练的时候的输入还是有帮助的,因为这样输入的话,我们是可以得到词在句子当中的一种关联关系的。
而embedding是词到one-hot然后one-hot到低纬向量的变化过程。
实现
ok,扯了那么多,那么接下来看看我们如何实现这个东西。
我们需要一个词向量,同时我们有很多词语,因此我们将得到一个矩阵,这个矩阵叫做embedding矩阵。
我们首先随机初始化embeddings矩阵,构建一个简单的网络。初始化weights和biases,计算隐藏层的输出。然后计算输出和target结果的交叉熵,之后使用优化器完成一次反向传递,更新可训练的参数,包括embeddings变量。并且我们将词之间的相似度可以看作概率。
ok,我们直接看到代码,那么咱们也是有两个版本的。简单版,复杂版。
简单版
简单版本的话,在pytorch当中有实现:
embed=nn.Embedding(word_num,embedding_dim)
复杂版
那么我们显然是不满足这个的,那么我们还有复杂版本。就是自己动手,丰衣足食!
首先我们定义这个:
class embedding(nn.Module):def __init__(self,in_dim,embed_dim):super().__init__()self.embed=nn.Sequential(nn.Linear(in_dim,200),nn.ReLU(),nn.Linear(200,embed_dim),nn.Sigmoid())def forward(self,input):b,c,_=input.shapeoutput=[]for i in range(c):out=self.embed(input[:,i])output.append(out.detach().numpy())return torch.tensor(np.array(output),dtype=torch.float32).permute(1,0,2)
很简单的一个结构。
那么我们输入是上面,首先其实是我们one-hot编码的一个矩阵。
我们其实流程就是这样的:词—>one-hot—>embedding/svd
ok,那么我们的N-gram如何表示呢,其实这个更多的还是在于对句子的分解上,输入的句子的词向量如何表示的。
如何训练
如何训练的话,首先还是要在one-hot处理的时候再加一个处理,这个过程可能比较绕。就是说我们按照上面提到的词袋模型进行构造我们的数据,我们举个例子吧。
现在有这样的一个文本,分词之后,词的个数是content_size。有num_word个词。
import torch
import re
import numpy as nptxt=[] #文本数据
with open('peter_rabbit.txt',encoding='utf-8') as f:for line in f.readlines():l=line.strip()spilted_sentence=re.split(" |;|-|,|!|\'",l)for w in spilted_sentence:if w !='':txt.append(w.lower())
vol=list(set(txt)) #单词表
n=len(vol) #单词表单词数
vol_dict=dict(zip(vol,np.arange(n))) #单词索引'''
这里使用词袋模型
每次从文本中选取序列长度为9,输入单词数为,8,输出单词数为1,
中心词位于序列中间位置。并且采用pytorch中的emdedding和自己设计embedding两种方法
词嵌入维度为100。
'''
data=[]
label=[]for i in range(content_size):in_words=txt[i:i+4]in_words.extend(txt[i+6:i+10])out_word=txt[i+5]in_one_hot=np.zeros((8,n))out_one_hot=np.zeros((1,n))out_one_hot[0,vol_dict[out_word]]=1for j in range(8):in_one_hot[j,vol_dict[in_words[j]]]=1data.append(in_one_hot)label.append(out_one_hot)class dataset:def __init__(self):self.n=ci=config.content_size def __len__(self):return self.ndef __getitem__(self, item):traindata=torch.tensor(np.array(data),dtype=torch.float32) trainlabel=torch.tensor(np.array(label),dtype=torch.float32)return traindata[item],trainlabel[item]
我们只是在投喂数据的时候按照词袋模型进行投喂,或者连续模型也可以。
当然我们这里所说的都只是说预训练出一个模型出来,实际上,我们直接使用这个结构,然后进行正常的训练完成我们的一个模型也是可以的。她是很灵活的,不是固定的!
那么继续预训练的话就是按照词袋模型来就好了(看不懂没关系,跳过就好了)
import torch
from torch import nn
from torch.utils.data import DataLoader
from dataset import dataset
import numpy as npclass model(nn.Module):def __init__(self):super().__init__()self.embed=embedding(num_word,100)self.fc1=nn.Linear(num_word,1000)self.act1=nn.ReLU()self.fc2=nn.Linear(1000,num_word)self.act2=nn.Sigmoid()def forward(self,input):b,_,_=input.shapeout=self.embed (input).view(b,-1)out=self.fc1 (out)out=self.act1(out)out=self.fc2(out)out=self.act2(out)out=out.view(b,1,-1)return out
if __name__=='__main__':pre_model=model()optim=torch.optim.Adam(params=pre_model.parameters())Loss=nn.MSELoss()traindata=DataLoader(dataset(),batch_size=5,shuffle=True)for i in range(100):print('the {} epoch'.format(i))for d in traindata:p=model(d[0])loss=Loss(p,d[1])optim.zero_grad()loss.backward()optim.step()
这样一来就可以初步完成预训练,你只需要加载好embeding部分的权重就好了,这个只是加快收敛的一种方式。
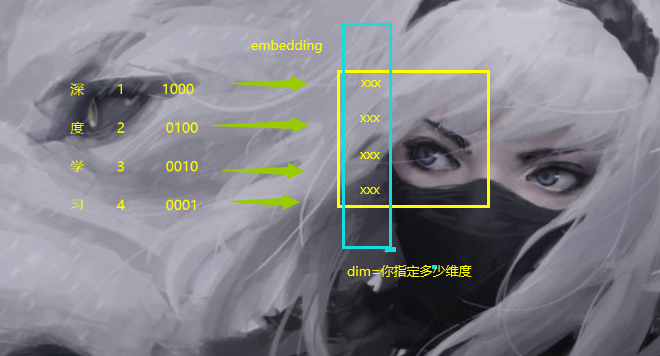
转换后的形状
最终,词嵌入的话,得到的矩阵是将one-hot变化为了这样的矩阵
ok,词的表达已经🆗了,那么接下来我们在简单介绍一下RNN。
(当然对于这一部分,实际上的话其实还有别的方法,但是咱们这边只是用到这些东西,所以只是介绍这个)
part02 循环神经网络
RNN
这个RNN的话,咋说呢,其实挺简单的,但是有几个点可能是比较容易误导人的,搞清楚这个结构的话,对于我们后面对于LSTM,GRU这种网络的架构可能会更好了解,其实包括LSTM,GRU的话其实本质上还是挺简单的。当然能够直接提出这个东西的人是非常厉害的,不过不管怎么说他们都是属于循环神经网络的一个大家族的,只是在数据处理上面多了一点点东西。那么理解了RNN之后的话,对于我后面理解LSTM,GRU里面它的一个数据的变幻,传递,原理。因为后面的话,我们还是要手写实现这个GRU的(LSTM也是一样的,但是GRU少了点参数,消耗的计算资源少一点点)。所以对于这一部分还是有必要好好唠一唠的。
首先我们来看到基本的神经网络:
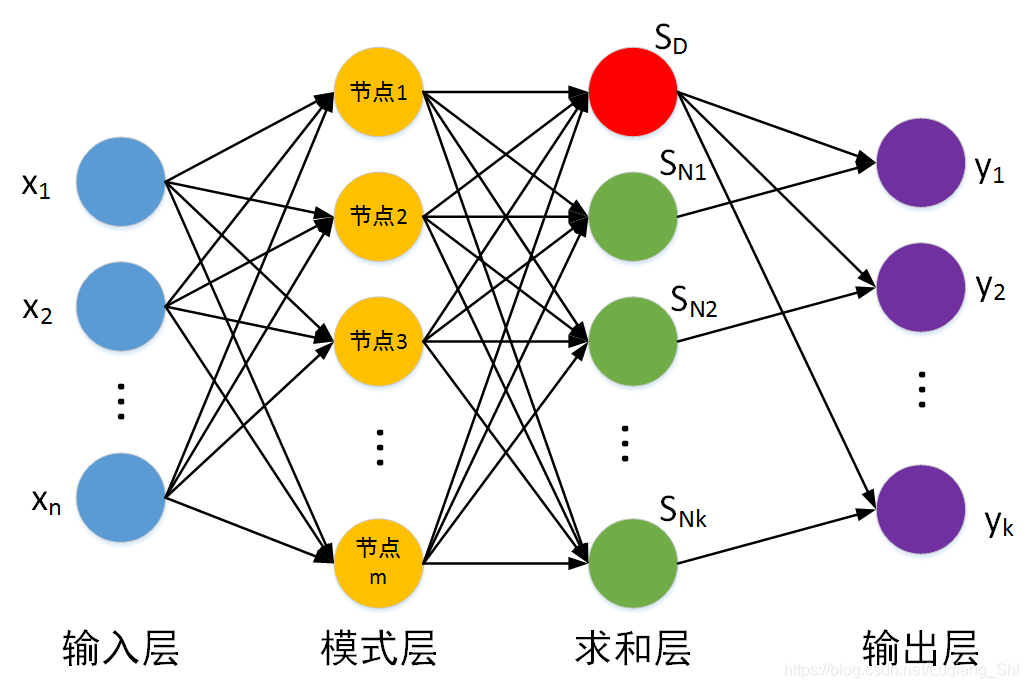
这是一个简单的前馈神经网络,也是我们最常见的神经网络。
接下来是我们的RNN神经网络,在大多数情况下,我们经常会提到这几个名词:时间步,最后一层输出等等。
那么在这里的话,我们需要理解展开的其实只有一个东西,那就是对应时间步的理解,什么是上一层网络的输出,他们之间的参数是如何传递的。
RNN投影图
那么在此之前,我们先来看看RNN的网络结构大概是什么样子的。
大多数情况下,你搜索到的图片可能是这样的:
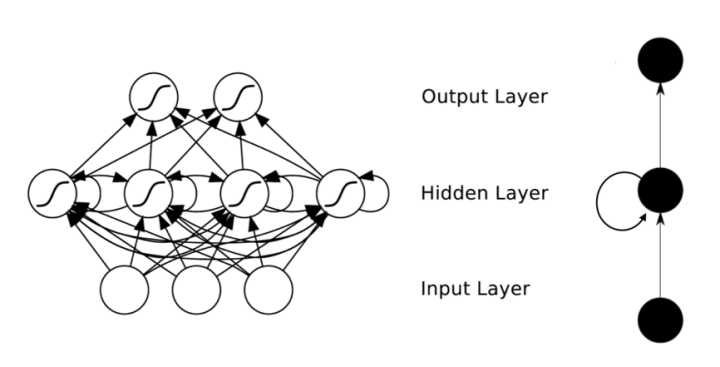
首先承认这张图非常的简洁,以至于你可能一开始没有反应过来,什么体现循环,体现时间步的地方在哪。其实这里的话,这种图其实只是一个缩略平面图。
RNN是三维立体的
但是实际上,如果需要用画图来表示的话,RNN其实是立体的一个样子。大概长这个样子:
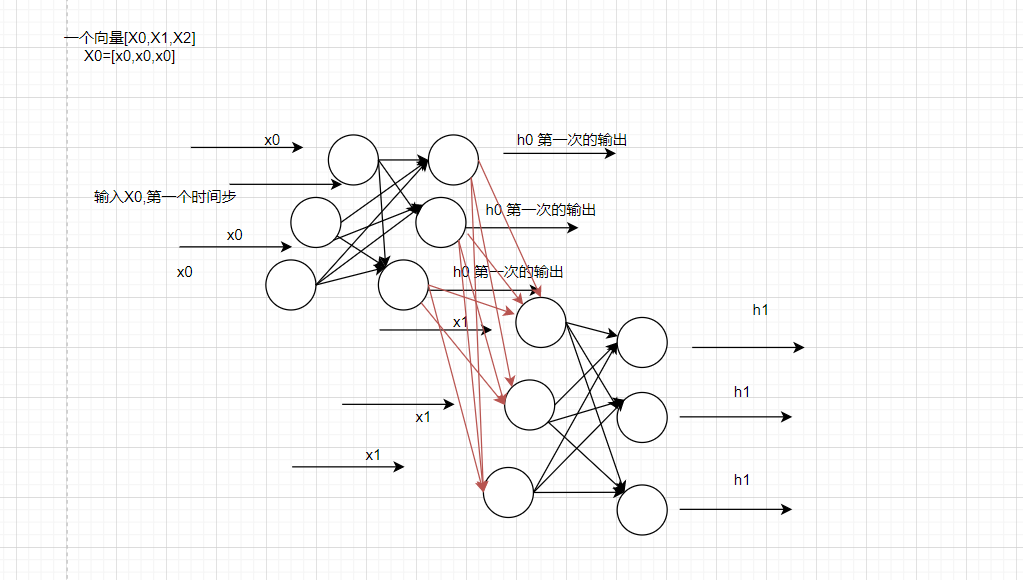
可能有点抽象,但是它的意思其实就是这样的,这个其实是RNN真正的样子,之后通过对不同的时间步的输出进行不同的处理,最终我们还可以将RNN进行分类。
OK,这个就是我们在RNN里面需要注意的点,它的真实结构是这样的,是一个三维度的结构。同样的接下来要提到的LSTM,GRU都是。
OK,接下来还没完,我们现在需要不目光放长远一点,首先是在RNN里面对于层的概念,我们接下来会说什么什么层,搭建几层的一个LSTM,GRU之类的,或者说几层的RNN,这个层其实是指,一个时间步上有几个立体的层,而不是说先前平面的那种网络,说几层几层。因为实际上,咱们这里图画的就一层全连接(输入层不算),但是在时间步上,它是N层,你有几个X就有几个层。
我们拿一个句子为例,假设一句话有5个单词,或者说处理之后有5个词语。那么RNN就是把每一个词的词向量作为输入,按照顺序,按照上面图的顺序进行输入。此时需要做的就是循环5次。
LSTM&GRU
那么之后的话,咱们再来说说LSTM和GRU,他们呢叫做长短期记忆网络,其实就是最low的RNN的一个升级版,对信息进一步处理。我们对于模型的调优,优化说白了,除了性能的优化,就是对信息的最大利用(增加信息,或者对重点信息进行提取)。所以基本上为什么大模型的效果很好,其实不考虑对信息的利用率,单单是对信息的使用就已经达到了超大的规模,这效果肯定是比小模型好一点的。
那么这里的话,我们就简单过一下这个结构图吧。
首先是LSTM,其实的话他这里主要是引入了一个东西,叫做记忆。
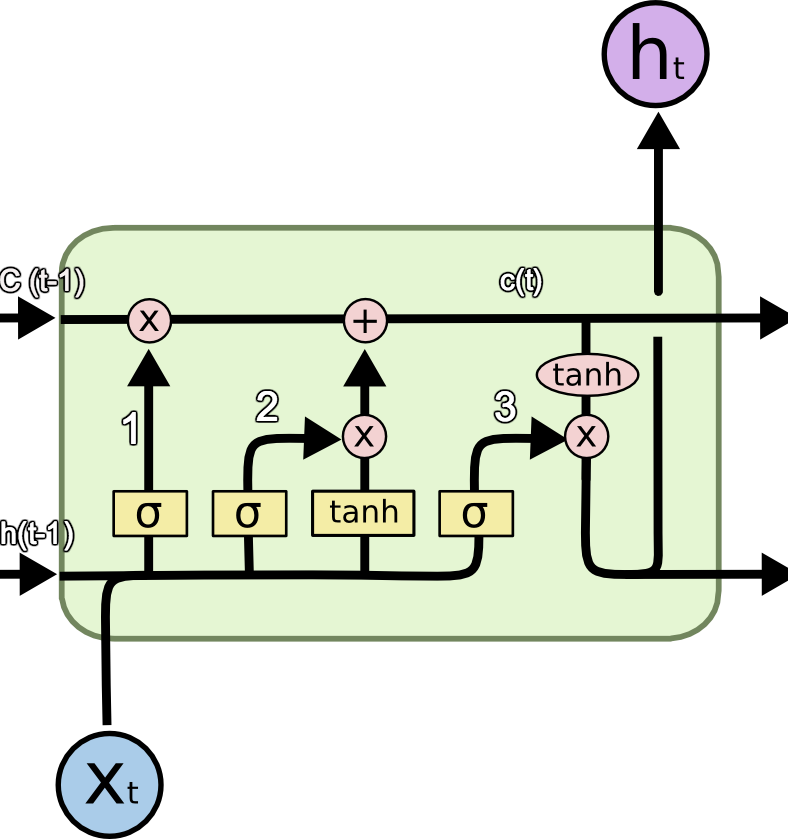
c就是记忆,因为刚刚的RNN,的话其实更像是一个一阶的马尔科夫,那么导入这个的话,就相当于日记,你不仅仅知道了昨天做了什么,还知道了前天做了什么,这样的话对于信息的利用坑定是上去了的。那么这个是它的一个单元。
宏观上还是这样的:

同理GRU也是一样的
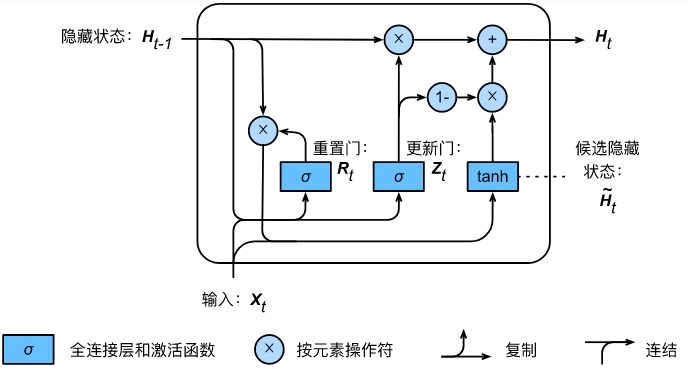
但是这里的话少了一个c 其实还是说把Ht和c合在了一起,他们效果是差不多的,各有各的好处,你用LSTM还能多得到一个日记本,用GRU的话其实相当于,你把日记写在了脑子里面。好处是省钱,坏处是有时候要你女朋友可能需要检查日记(虽然我知道你有95%以上的概率是没有的,一般设置0.05 作为阈值,低于这个概率,基本上我们认为G了)
part03意图识别
OK,我们终于到了写代码的地方了,首先我们这边有三个任务,第一个我们要知道,用户输入的想法意图是什么。所以我们这边需要搞一个文本分类的网络。之后的话,我们就是对话和问答。这里比较难的其实就是闲聊部分。在这部分的话我们还需要学会如何手写GRU的循环过程,为什么用GRU前面说了哈(省点资源,也木有女朋友查“日记”的需求,因为没有)。
分词
那么我们首先要做的就是分词
重点是为了后面能够对这两个家伙实现分词:
ok,那么我们先进行分词,首先是要加载咱们的词典以及咱们的这个停用词,这样的话方便提高效果。
那么在这边的话在这:

这里先进行初始化,加载对应的词典之类的
import jieba
import jieba.posseg as pseg
from tqdm import tqdm, trange
from config.config import jieba_config
import stringjieba.load_userdict(jieba_config.get("word_dict"))
jieba = jieba
pseg = pseg
string = string
with open(file=jieba_config.get("stop_dict"),encoding='utf-8') as f:lines = tqdm(f.readlines(),desc="loading stop word")StopWords = {}.fromkeys([line.rstrip() for line in lines ])print("\033[0;32;40m all loading is finished!\033[0m")__all__ = ['string','jieba','StopWords','pseg']
之后的话分词就好了:
"""
this model just for cutting words
"""
import utilsclass Cut(object):def __init__(self,other_letters=None):self.letters = utils.string.ascii_lettersself.stopword = utils.StopWordsdef __stop_not_sign(self,result):result_rel = []for res in result:if (res not in self.stopword):result_rel.append(res)return result_reldef __stop_with_sign(self, result):result_rel = []for res in result:if (res.word not in self.stopword):result_rel.append((res.word,res.flag))return result_reldef cut(self,sentence,by_word=False,use_stop_word=False,with_sg=False):""":param sentence::param by_word::param use_stop_word::param with_sg::return:"""if(by_word):return self.cut_sentence_by_word(sentece)else:'''without by word,so there will be cutting by jieba'''if (with_sg):result = utils.pseg.lcut(sentece)if(use_stop_word):result = self.__stop_with_sign(result)else:result = utils.jieba.lcut(sentece)if (use_stop_word):result = self.__stop_not_sign(result)return resultdef cut_sentence_by_word(self,sentence):"""it can cut English sentences and Chinese:param sentence::return:"""result = []temp = ""for word in sentence:if word.lower() in self.letters:temp+=wordelse:if(temp!=""):result.append(temp)temp = ""else:result.append(word.strip())if(temp!=""):result.append(temp.lower())return resultif __name__ == '__main__':sentece = "你好呀Hello Word?"cut = Cut()print(cut.cut(sentece,by_word=False,use_stop_word=True,with_sg=False))在这里的话就实现了一个简单的句子分词,之后我们还需要使用到这个工具类。
FastText分类
OK,我们快步进入到咱们的FastText,这个东西呢,其实是FaceBook推出的一个能够快速训练文本分类的一个工具模型。我们只需要按照它的格式来输入创建数据集就好了,就可以实现出一个分类效果,这样的话对于我们后面的作用是非常大的。
直接:
pip install fasttext
即可完成安装。
那么同样的在使用之前的话,我简要介绍一下FastText。
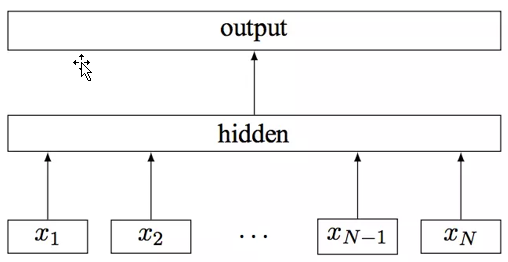
FastText网络结构
首先FastText的话其实是非常简单的一个模型
优化点
就是这样的一个结构,其实和很多手写LSTM文本分类的例子很像。但是它的优化点在于:
在使用方面,支持并行计算,可以节省训练时间。
在算法方面:
- 使用N-gram 的方式进行处理(当然我们这边其实也是,只是我们这边N=1)
- 通过哈夫曼树进行层次化softmax 优化最后计算概率
那么我们这里简单说一下这个层次化softmax。其实这玩意的本质其实就是在玩概率组合。
首先我们通过哈夫曼树,将对应的标签构造出一棵树。

每次,把多分类的softmax变成了二分类的,此时你甚至可以直接使用sigmod代替softmax函数。
ok,这个做一个了解即可。我们继续我们的编码。
构造FastText数据集
那么接下来我们需要构建FastText需要的数据。
我们需要的数据的集合的格式是这样的:
当然这个格式其实也是可以进行修改的,
这个的话在fastText源码当中可以看到
那么这个的话我这里就不解释了,我们直接上代码:
"""
this mode for preparing data which fasttext need
"""
from tqdm import tqdm, trange
from config import config
from utils.cut_word import Cut
import json
class process_classfiy(object):def __init__(self):self.cut = Cut()self.count_QA = 0self.count_Chat = 0self.classfiy_save = open(config.process_save.get("classfiy"),'a+',encoding='utf-8')self.xiaohuangji_save = open(config.process_save.get("xiaohuangji"),'a+',encoding='utf-8')self.QA_save = open(config.process_save.get("QA"),'a+',encoding='utf-8')def process_xiaohuangji(self):flag = 0for line in tqdm(open(config.data_path.get("xiaohuangji"),'r',encoding='UTF-8').readlines(),desc="process_xiaohuangji"):if (line.startswith("E")):flag = 0continueelif(line.startswith("M")):if(flag==0):line = line[1:].strip()flag = 1else:continueline_cuted = " ".join(self.cut.cut(line))+"\t"+"__label__chat"self.xiaohuangji_save.write(line_cuted+"\n")self.classfiy_save.write(line_cuted+"\n")self.count_Chat+=1self.xiaohuangji_save.close()def process_qa(self):"""this is for qa processing:return:"""for line in tqdm(open(config.data_path.get("QA"), 'r', encoding='utf8'),desc="process_qa"):data_line = json.loads(line)line_cuted = self.cut.cut(data_line.get("Q"))line_cuted = " ".join(line_cuted)+"\t"+"__label__QA"self.QA_save.write(line_cuted+"\n")self.classfiy_save.write(line_cuted + "\n")self.count_QA+=1self.QA_save.close()def process(self):#load xiaohuangjiself.process_xiaohuangji()#load qaself.process_qa()self.classfiy_save.close()print("\033[0;32;40m all processing is finished in classfiy!\033[0m")print("All data is:",self.count_QA+self.count_Chat,"\n The Chat numbers is:",self.count_Chat,"\n The QA numbers is:",self.count_QA)if __name__ == '__main__':process_classfiy = process_classfiy()process_classfiy.process()
这样一来就可以完成一个构造,那么最终的话我们的数据是:
45W的闲聊数据
5W 的问答数据。
运行结果如下:
loading stop word: 100%|██████████| 1395/1395 [00:00<00:00, 1398101.33it/s]all loading is finished!
process_xiaohuangji: 100%|██████████| 1363683/1363683 [00:21<00:00, 62936.02it/s]
process_qa: 50000it [00:04, 10152.58it/s]all processing is finished in classfiy!
All data is: 505421 The Chat numbers is: 455421 The QA numbers is: 50000
这个问答的数据相对少了好多,可能效果会比较差,这个可以自己后面再去收集一些数据,那么我们这边就先这样了。
训练
之后的话就是使用我们的FastText进行训练了,这个训练其实还是非常简单的。
这块的话我把验证的代码也给出来:
import fasttext
from config import config
import osclass train_fasttext(object):"""there are just some params for fastText you can seethe source code for design more params in there!"""def __init__(self):fasttext.FastText.eprint = lambda x: Noneself.current_last_path = os.path.abspath(os.path.join(os.getcwd(), "./"))def build_classify(self,wordNgrams=1,epoch = 100,minCount=5):self.ft_model = fasttext.train_supervised(self.current_last_path+"\\"+config.process_save_classfiy.get("classfiy"),wordNgrams=wordNgrams,epoch=epoch,minCount = minCount)self.ft_model.save_model(self.current_last_path + "\\"+config.process_save_classfiy.get("classfiy_model"))def get_classfiy_model(self,path):if(os.path.exists(path=path)):model = fasttext.load_model(path)return modelelse:raise Exception("there is no model in there")def train():train_fastetxt = train_fasttext()train_fastetxt.build_classify()def eval(data):"""for eval:return:"""train_fastetxt = train_fasttext()mode_path = config.process_save_classfiy.get("classfiy_model")model = train_fastetxt.get_classfiy_model(mode_path)res = model.predict(data)return resif __name__ == '__main__':# train()data = ["开心 点哈, 一切 都会 好 起来","我 还 喜欢 她, 怎么办","你 知道 谁 么",]res = eval(data)print(res)
这几个测试数据的话是直接把那个训练集里面的拿过来的,这里的话就不去做评测了,要做的话也很简单,所以这里的的话不去搞了,重点是咱们后面的东西。
([['__label__chat'], ['__label__chat'], ['__label__chat']], [array([0.99958235], dtype=float32), array([0.99872446], dtype=float32), array([1.000009], dtype=float32)])运行效果就是返回两个列表嘛,一个是标签名,还有一个是概率。这个的概率的话有些是大于1的,这里的话应该是精度的一个问题。
part04 闲聊对话
这里我们假装是你的AI女友吧。这里的话还是老规矩,首先还是咱们用到的数据集。它是怎么样的一个情况,那么这里的话,咱们使用到的还是说这个小黄鸡的语料,但是也正是由于这个问题,所以的话,我们最后训练出来的闲聊机器人可能对话是偏向那个语料的。因此如果说我们期望能够训练出AI女友的话,那么首先在语料的准备上,最好准备情侣对话的这种。如果说你想要训练出合适的或者符合你的审美的AI,那么我们建议在数据集的准备阶段,如果有条件的话,可以考虑把你和你的女朋友的对话给搞进去,越多越好。但是这个可能违背了一定的规则吧。当然这个不是唯一的方案,我们也可以在日后不断通过你们之间的对话进行重新训练。目前我能够想到的方案是Attention+RL。不过鉴于这个是baseline,所以的话这里不会去实现,同时我也需要去文献来进行验证,不过我们最终的目的一定是这样的,那就是我们期望可以得到一个独一无二的AI,并且随着你们深入的交流对话,她将更加了解你。我们期望赋予AI与人“相识”的过程,以便完成更加复杂的任务。
考虑到我的PC那可怜的算力,以及项目的难度,我们这边将通过GRU搭建一个最简单的seq2seq模型。
Seq2Seq
这玩意咋说呢,首先我们先来看一看就是说这玩意的话,它大概长啥样吧,先别晕(先晕直接就输了),搞懂的输入输出就好了。等后面对它有一定了解之后,再回到这里来是可以的。那么这一部分也是我会尽可能简化,如果有需要详细讲解的话,评论区留言,当然我相信,其他的博主应该是讲的会不错吧。还是那句话,理解RNN是三维的,知道维度的变幻,知道了这些其他的都是简单。
网络结构
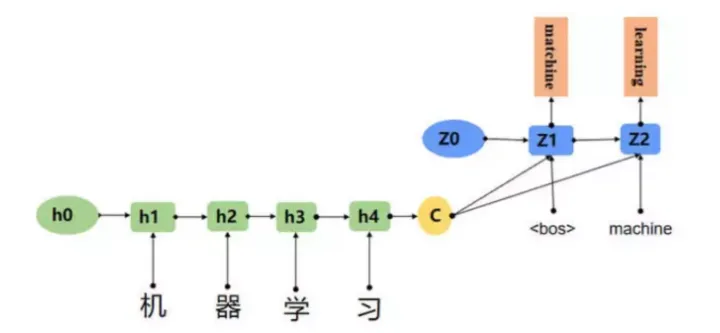
我们将上面的图简化一下那就是这样:
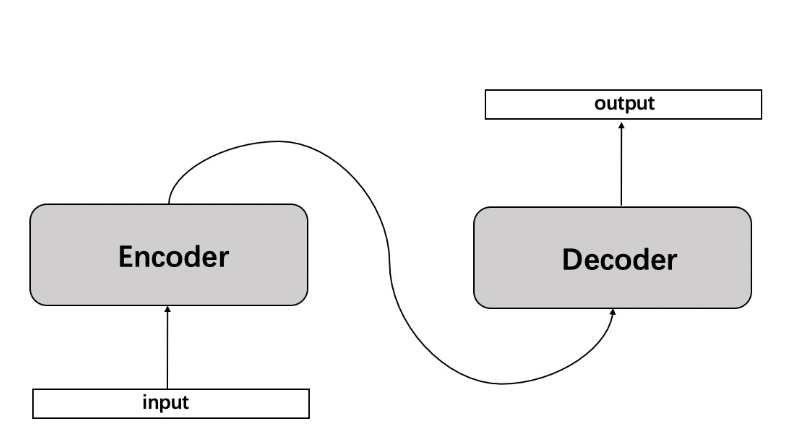
输入与输出(编/解码器)
我们先不管那个复杂的,我们就看到上面那张简单的图,编码器和解码器。首先我们知道从上上张图可以看到,Encode和Decoder其实都是一个循环神经网络,他可能是由LSTM或者GRU组成的。在我们的词语的表达当中,我们知道我们先前是将一个词进行id编号,之后我们通过id进行one-hot编码之后的话通过我们的一个词嵌入变成了一个batchsize,sentence_len,embedding_dim的情况。最后我们可以得到一个输出和最后一层的输出。
我们假设是用的GRU,那么得到的就是两个输出,一个是网络每个时间步的一个输出,还有一个是网络往前传递的时候的一个输出,分别是H,和 output。那么他们的维度的话分别是:
[number_layer1|2,batchsize,hidden]
[batch_size,sentence_len,hiddennumber_layer*1|2]
这里的假设是在pytorch当中,batchsize_first = True 的时候,具体原因的话,看官网哈,真的看人家官网,等于英语理解+新世界大门。
那么这个部分的话,那么对于编码器来说,这个其实就是他的一个输出,每错,所谓的编码器其实就是一个长短期记忆网络,可以是LSTM,也可以是GRU,但是在我这里设计到的那个“日记”是暂时没有用的,所以的话我这里就直接使用GRU了(维度的变幻真的很难调整,太累人)
那么解码器的话,同样的,他也是一个GRU/LSTM,但是最后的话,会通过一个全连接和softmax最后转化为一个大概率。没错,这个解码器其实就是再通过一个GRU/LSTM,之后将它转化为一组大概率,最终得到的概率的形状是: batchsize,out_word_number, word_size
第一个参数,就是你一次性输入多少个句子,第二个是我们实际上设定的句子的一个长度(长度是固定的,但是我们最终有一个终止符号,也就是说,这个东西的长度需要大一点,最终输出的句子最长都不会超过这个)
第三个参数就很恐怖了,就是我们的数据集合里面有多少个单词。没错就是这样暴力,直接把这个玩意变成分类问题。
没错解码器干的就是这个破事儿,因此最重要,最难的实现就是我们的解码器,提高解码器对编码器输出的信息的利用率就是提高这个网络性能的重点。所以的话我们在这边还会引入一个注意力机制,没错也是在解码器部分实现。
ok,那么这个就是seq2seql的一个简单描述,做法就是通过两个长短期网络,将输入的文本,最终转化为一组概率。然后通过概率找到下标,然后通过下标找到咱们的词,最后由词组成句子。看起来和yolo系列算法不一样,似乎不是那么“顺畅”。单从网络上看其实也算是end-to-end,只是中间做的转化多了几步,“知识的表示嘛”。
数据准备
OK,我们来先进行第一步,构造词典,也就是给个标号。
要做的事情就是:
句子—》词语—》词语的id序列 之后是embedding
我们实现的就是前面的部分。同时的话,咱们还需要实现DataLoader
构造词典
在构造词典的时候呢,咱们有两个步骤,刚刚咱们已经说了,这个网络说白了是变成了一个分类问题,那么如果是一个分类问题,那么我们就有input 和 target。也就是输入数据和对应的标签,那么在这边的话,我们可以这样做,就是说是,一个对话,我们这样:
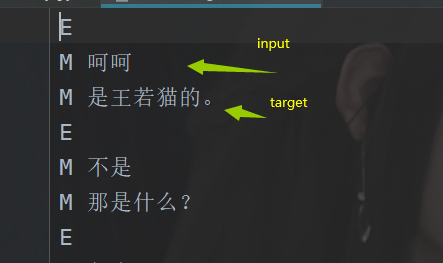
所以的话,我们要先做一个分离。然后再去构造咱们的词典。我们这边的实现思路其实非常简单,首先的话,我们需要将input 和 target分开了,然后再去构造。
完整代码如下:
"""
for building corpus for chatboot running
This will be deployed in a white-hole, possibly in version 0.7
"""
import pickle
from tqdm import tqdm
from config import config
from utils.cut_word import Cutclass Chat_corpus(object):def __init__(self):self.Cut = Cut()self.PAD = 'PAD'self.UNKNOW = 'UNKNOW'self.EOS = 'EOS'self.SOS = 'SOS'self.word2index={self.PAD: config.chatboot_config.get("padding_idx"),self.SOS: config.chatboot_config.get("sos_idx"),self.EOS: config.chatboot_config.get("eos_idx"),self.UNKNOW: config.chatboot_config.get("unk_idx"),}self.index2word = {}self.count = {}def fit(self,sentence_list):"""just for counting word:param sentence_list::return:"""for word in sentence_list:self.count[word] = self.count.get(word,0)+1def build_vocab_chat(self,min_count=None,max_count=None,max_feature=None):"""build word dict,this need to save by pickle in computer memory:return:"""temp = self.count.copy()for key in temp:cur_count = self.count.get(key,0)if(min_count !=None):if(cur_count<min_count):del self.count[key]if(max_count!=None):if(cur_count>max_count):del self.count[key]if(max_feature!=None):self.count = dict(sorted(self.count.items(),key= lambda x:x[1],reverse=True)[:max_feature])for key in self.count:self.word2index[key] = len(self.word2index)self.index2word = {item[1]:item[0] for item in self.word2index.items()}def transform(self,sentence,max_len,add_eos=False):if(len(sentence)>max_len):sentence = sentence[:max_len]sentence_len = len(sentence)if(add_eos):sentence = sentence+[self.EOS]if(sentence_len<max_len):sentence = sentence +[self.PAD]*(max_len-sentence_len)result = [self.word2index.get(i,self.word2index.get(self.UNKNOW)) for i in sentence]return resultdef inverse_transform(self,indices):"""index ---> sentence:param indices::return:"""result = []for i in indices:if(i==self.word2index.get(self.EOS)):breakresult.append(self.index2word.get(i,self.UNKNOW))return resultdef __len__(self):return len(self.word2index)def __by_word(self,data_lines):for line in data_lines:for word in self.Cut.cut(line,by_word=True):self.word2index[word] = self.word2index.get(word,0)+1def __by_not_word(self,data_lines):for line in data_lines:for word in self.Cut.cut(line,by_word=False):self.word2index[word] = self.word2index.get(word, 0) + 1def division(self,by_word=False,use_stop_word=False):"""this funcation just for dividing input and target in xiaohuangji corpus:return:"""count_input = 0count_target = 0temp_sentence = []if(by_word):middle_prx = ""else:middle_prx = "_no"target_save = open(config.chatboot_config.get("target_path"+middle_prx+"_by_word"),'a',encoding='utf-8')input_save = open(config.chatboot_config.get("input_path"+middle_prx+"_by_word"),'a',encoding='utf-8')xiaohuangji_path = config.data_path.get("xiaohuangji")with open(xiaohuangji_path,'r',encoding='utf-8') as file:file_lines = tqdm(file.readlines(),desc="division xiaohuangji")for line in file_lines:line = line.strip()if (line.startswith("E")):continueelif (line.startswith("M")):line = line[1:].strip()line = self.Cut.cut(line, by_word, use_stop_word)temp_sentence.append(line)if(len(temp_sentence)==2):"""Because the special symbol has a certain possibility, it is used as the input of the user.Therefore, retain that special kind of "symbolic dialogue" corpus"""if(len(line)==0):temp_sentence = []continueinput_save.write(" ".join(line)+'\n')count_input+=1target_save.write(" ".join(line)+'\n')count_target+=1temp_sentence=[]input_save.close()target_save.close()assert count_target==count_input,'count_target need equal count_input'print("\033[0;32;40m process is finished!\033[0m")print("The input len is:",count_input,"\nThe target len is:",count_target)def compute_build(chat_corpus,fixed=False,by_word=False,min_count=5,max_count=None,max_feature=None,is_target=True,):"""for computing fit function with input and target file:param fixed: if True when error coming will try to fix by itself:return:"""if (by_word):middle_prx = ""else:middle_prx = "_no"after_fixed = Falselines = []try:if(is_target):lines = open(config.chatboot_config.get("target_path"+middle_prx+"_by_word"), 'r', encoding='utf-8').readlines()else:lines = open(config.chatboot_config.get("input_path"+middle_prx+"_by_word"), 'r', encoding='utf-8').readlines()except Exception as e:if(fixed):chat_corpus.division(by_word=by_word)after_fixed = Trueelse:raise Exception("you need use Chat_corpus division function first! ")if(after_fixed):if (is_target):lines = open(config.chatboot_config.get("target_path" + middle_prx + "_by_word"), 'r',encoding='utf-8').readlines()else:lines = open(config.chatboot_config.get("input_path" + middle_prx + "_by_word"), 'r',encoding='utf-8').readlines()data_lines = tqdm(lines,desc="building")for line in data_lines:chat_corpus.fit(line.strip().split())chat_corpus.build_vocab_chat(min_count,max_count,max_feature)if(is_target):pickle.dump(chat_corpus,open(config.chatboot_config.get("word_corpus"+middle_prx+"_by_word_target"),'wb'))else:pickle.dump(chat_corpus, open(config.chatboot_config.get("word_corpus" + middle_prx + "_by_word_input"), 'wb'))if __name__ == '__main__':chat_corpus = Chat_corpus()compute_build(chat_corpus,fixed=True,min_count=5,by_word=False,is_target=True)通过这段代码就完成了最基本的处理。
注意的是,我们将input和target是做了区分的,一方面是为了避免词典过大,另一方面是因为,有些会话当中的词可能并不存在于input当中,所以做了一个区分。
同时的话,这里还负责将句子转化为向量,向量转化为句子的操作。
数据加载
ok,现在我们已经实现了对每一个词进行标号了,那么接下来我们要做的就是将这个词转化为一个向量,同时也要送进咱们的神经网络里面,那么咱们这边就是需要手写DataLoader。
这个的话,其实也是比较简单的,唯一要注意的就是说要手写一个函数。
"""
dataSet about chat_boot
"""
from torch.utils.data import DataLoader,Dataset
from boot.chatboot.encoder import Encoder
from config import config
import torch
class Chat_dataset(Dataset):def __init__(self,by_word=False):if (by_word):middle_prx = ""else:middle_prx = "_no"self.target_lines = open(config.chatboot_config.get("target_path" + middle_prx + "_by_word"), 'r',encoding='utf-8').readlines()self.input_lines = open(config.chatboot_config.get("input_path" + middle_prx + "_by_word"), 'r',encoding='utf-8').readlines()assert len(self.target_lines)==len(self.input_lines),"len need equal"def __getitem__(self, index):input_data = self.input_lines[index].strip().split()target_data = self.target_lines[index].strip().split()if(len(input_data)==0):raise Exception("the input_data's length is: 0")input_length = len(input_data) if len(input_data)<config.chatboot_config.get("input_max_len") else config.chatboot_config.get("input_max_len")target_lenth = len(target_data) if len(target_data)<config.chatboot_config.get("target_max_len")+1 else config.chatboot_config.get("target_max_len")+1return input_data, target_data, input_length, target_lenthdef __len__(self):return len(self.input_lines)def collate_fn(batch):if(config.chatboot_config.get("collate_fn_is_by_word")):input_ws = config.chatboot_config_load.get("word_corpus_by_word_input_load")target_ws = config.chatboot_config_load.get("word_corpus_by_word_target_load")else:input_ws = config.chatboot_config_load.get("word_corpus_no_by_word_input_load")target_ws = config.chatboot_config_load.get("word_corpus_no_by_word_target_load")batch = sorted(batch,key=lambda x:x[-2],reverse=True)input_data, target_data, input_length, target_lenth = zip(*batch)input_data = [input_ws.transform(i, max_len=config.chatboot_config.get("input_max_len")) for i in input_data]target_data = [target_ws.transform(i, max_len=config.chatboot_config.get("target_max_len"),add_eos=True) for i in target_data]input_data = torch.LongTensor(input_data)target_data = torch.LongTensor(target_data)input_length = torch.LongTensor(input_length)target_lenth = torch.LongTensor(target_lenth)return input_data, target_data, input_length, target_lenth
在这里的话我们可以看到大概的一个输出:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\31395\AppData\Local\Temp\jieba.cache
Loading model cost 0.624 seconds.
Prefix dict has been built successfully.
loading stop word: 100%|██████████| 1395/1395 [00:00<00:00, 1400443.77it/s]all loading is finished!
tensor([[ 14, 6243, 925, ..., 515, 66, 1233],[ 20, 34, 2173, ..., 710, 7, 9],[12422, 20, 42, ..., 9, 14, 236],...,[ 1636, 1, 1, ..., 1, 1, 1],[ 531, 1, 1, ..., 1, 1, 1],[ 8045, 1, 1, ..., 1, 1, 1]])
tensor([[ 165, 19617, 118, ..., 1, 1, 1],[ 249, 15, 12, ..., 1, 1, 1],[ 153, 8, 153, ..., 1, 1, 1],...,[ 329, 58, 3, ..., 1, 1, 1],[ 681, 0, 2625, ..., 1, 1, 1],[ 5245, 3641, 15, ..., 1, 1, 1]])
tensor([20, 19, 16, 15, 13, 13, 12, 12, 11, 11, 11, 11, 11, 9, 9, 9, 9, 8,8, 8, 8, 8, 8, 8, 7, 7, 7, 7, 7, 7, 6, 6, 6, 6, 6, 6,6, 6, 6, 6, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 4, 4,4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,4, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,3, 3, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1,1, 1])
tensor([ 7, 8, 3, 6, 2, 5, 2, 8, 5, 4, 2, 3, 3, 17, 3, 3, 10, 3,2, 71, 13, 1, 9, 10, 11, 10, 12, 3, 3, 8, 1, 10, 2, 11, 2, 9,2, 3, 8, 2, 3, 3, 4, 3, 3, 6, 40, 3, 8, 1, 30, 2, 7, 6,5, 74, 1, 9, 5, 5, 17, 4, 6, 5, 13, 2, 11, 3, 2, 6, 5, 2,2, 5, 3, 10, 5, 14, 3, 6, 2, 3, 18, 6, 9, 3, 4, 6, 3, 1,1, 7, 10, 6, 6, 3, 14, 2, 2, 7, 9, 6, 9, 3, 3, 9, 2, 3,7, 1, 1, 3, 4, 6, 6, 7, 1, 4, 6, 2, 6, 3, 5, 3, 2, 2,3, 6])Process finished with exit code 0那么在这边的话,我们也是自动生成了这些文件:
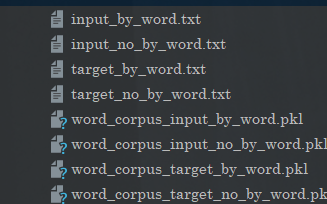
网络搭建
OK,基本前置工作OK了,那么我们接下来要做的就是说,来搭建我们的一个网络。那么在我们的网络的搭建部分的话,主要是有三个 部分,一个是我们的编码器,还有一个是我们的解码器,之后的话是我们的一个注意力机制,这个注意力机制的话有很多,这里的话我也不去介绍了,我们在这里选择的是Luong注意力机制。这个实现比较简单,毕竟是dome嘛,是一个baseline先快速搭建才是真(感兴趣的可以自己去看这篇论文,是2015年出来的:https://arxiv.org/pdf/1508.04025.pdf)这里的话咱们就不介绍了)
编码器
首先编码器的话,一个非常简单的结构,它是这样的:
import torch.nn as nn
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
from config import configclass Encoder(nn.Module):def __init__(self,by_word=False):super(Encoder,self).__init__()if(not by_word):self.input_ws = config.chatboot_config_load.get("word_corpus_by_word_input_load")else:self.input_ws = config.chatboot_config_load.get("word_corpus_no_by_word_input_load")self.embedding = nn.Embedding(num_embeddings=len(self.input_ws),embedding_dim=config.chatboot_config.get("embedding_dim"),padding_idx=config.chatboot_config.get("padding_idx"))self.gru = nn.GRU(input_size=config.chatboot_config.get("embedding_dim"),num_layers=config.chatboot_config.get("num_layers"),hidden_size=config.chatboot_config.get("hidden_size"),bidirectional=config.chatboot_config.get("bidirectional"),batch_first=config.chatboot_config.get("batch_first"))def forward(self,input_data,input_length):embeded = self.embedding(input_data)embeded = pack_padded_sequence(embeded,input_length,batch_first=True)out,hidden = self.gru(embeded)"""in there return:hidden: num_layers*2,batch_size,hidden_sizeout: batch_size,sentence_len,hidden_size"""out,hidden = pad_packed_sequence(out,batch_first=config.chatboot_config.get("batch_first"),padding_value=config.chatboot_config.get("padding_idx"))return out,hidden解码器
解码器的话也是一个GRU神经网络,但是和咱们的这个编码器的区别是啥呢,就是最后呢,我们会把输出变成一个概率。没错,解码器的作用其实就是最后做一个分类。那么这个时候你要问了,为什么要用循环神经网络呢?首先我们一句话有很多词组成,词语之间是有关联的,所以咱们使用了循环网络,保存连串的一种关系。之后呢我们生成一句话同时也是按照一个词一个词生成的(一个标点也可以是词)。所以我们这边需要一个网络理解句子,同时我们还需要逐词生成,因此也需要一个循环网络来生成句子。所以为什么我们的seq2seq需要两个网络。
之后的话我们在对其中句子信息的利用加大,例如加入注意力机制。比如我们的比较火热的transform架构。其实也是在这个基础上,加了很多注意力机制。可以理解为在seq2seq的基础上,加上注意力机制后再加上注意力机制的注意力,然后套娃,注意力的注意力的注意力。
之后就是我们最后说我们的一个输出是一个分类概率。预测每一个词的概率,也就是假设生成的句子有10个词,那么每一个位置预测全部词的概率。最后相当于一个分类,但是和分类的区别是,并不是在训练集上越准越好,太准了就容易出事,就比如有这样的对话,你说:“你好”,然后在咱们的回答是:“你好呀””。这个时候你相当于分类,网络生成了“你好呀”这句话是没问题,但是它生成了:“你也好呀”,或者是:“你吃了吗”。这种对话也是没问题的,但是单纯作为分类的话,那么如果生成的是这两句话中的其中一个的话,那么从分类的结果上来说,他是匹配句子当中每一个词的id。那么损失是相当难看的,可是实际对话效果可能又是不错的。因此这也是比较难验证的。所以虽然他也算是有监督的,但是和图像这种不一样,他不是完全对应的。也就是没有标准答案,这个也是问题,当然解决也是可以的那就是数据集,多个答案,但是这个难度比较大,咱们这里做也不现实。
OK,回到主题哈,咱们来看看编码器,这个就是一个GRU加上一个全连接,难度就是要手写循环,这里的难点是需要对它的输出的做充分了解。涉及到的维度变化比较多。那么实现的话在这:
class Decoder(nn.Module):def __init__(self,by_word=False):super(Decoder,self).__init__()self.drive = getDrive()"""attention init """if(config.chatboot_config.get("use_attention")):self.chatboot_encoder_hidden_size = config.chatboot_config.get("hidden_size")*2 if config.chatboot_config.get("bidirectional") else config.chatboot_config.get("hidden_size")self.chatboot_decoder_hidden_size = config.chatboot_config.get("hidden_size")*2 if config.chatboot_config.get("bidirectional") else config.chatboot_config.get("hidden_size")self.atte = LuongAttention()self.wa_concat = nn.Linear(self.chatboot_encoder_hidden_size+self.chatboot_decoder_hidden_size,# decoderself.chatboot_decoder_hidden_size,bias=False)if(by_word):self.target_ws = config.chatboot_config_load.get("word_corpus_by_word_target_load")else:self.target_ws = config.chatboot_config_load.get("word_corpus_no_by_word_target_load")self.embedding = nn.Embedding(num_embeddings=len(self.target_ws),embedding_dim=config.chatboot_config.get("embedding_dim"),padding_idx=config.chatboot_config.get("padding_idx"))self.gru = nn.GRU(input_size=config.chatboot_config.get("embedding_dim"),dropout=config.chatboot_config.get("dropout"),num_layers=config.chatboot_config.get("num_layers"),hidden_size=config.chatboot_config.get("hidden_size"),bidirectional=config.chatboot_config.get("bidirectional"),batch_first=config.chatboot_config.get("batch_first"))self.fc = nn.Linear(config.chatboot_config.get("hidden_size")*config.chatboot_config.get("num_layers"),len(self.target_ws))def forward(self,target_data,encoder_hidden,encoder_outputs):""":param target_data::param encoder_hidden:The hardest thing to do here is to pay attention to the dimensionalchanges in input and publication.:return:"""decoder_hidden = encoder_hiddenbatch_size = target_data.size(0)"""sos input in decoder for first time step"""decoder_input = torch.LongTensor(torch.ones([batch_size,1],dtype=torch.int64))*config.chatboot_config.get("sos_idx")decoder_input = decoder_input.to(self.drive)decoder_outputs = torch.zeros([batch_size,config.chatboot_config.get("target_max_len")+1,len(self.target_ws)]).to(self.drive)if (random.random() < config.chatboot_config.get("teacher_forcing_ratio")):for time in range(config.chatboot_config.get("target_max_len") + 1):decoder_output_t, decoder_hidden = self.forward_step(decoder_input, decoder_hidden,encoder_outputs)decoder_outputs[:, time, :] = decoder_output_tdecoder_input = target_data[:,time].unsqueeze(-1)else:for time in range(config.chatboot_config.get("target_max_len")+1):decoder_output_t,decoder_hidden = self.forward_step(decoder_input,decoder_hidden,encoder_outputs)decoder_outputs[:,time,:] = decoder_output_tvalue,index = torch.topk(decoder_output_t,1)decoder_input = indexreturn decoder_outputs,decoder_hiddendef forward_step(self,decoder_input, decoder_hidden,encoder_outputs):decoder_input_embeded = self.embedding(decoder_input)out,decoder_hidden = self.gru(decoder_input_embeded,decoder_hidden)"""there we add attention way""""""*******************************************************"""if (config.chatboot_config.get("use_attention")):attention_weight = self.atte(decoder_hidden,encoder_outputs).unsqueeze(1)context_vector = attention_weight.bmm(encoder_outputs)concated = torch.cat([out,context_vector],dim=-1).squeeze(1)out = torch.tan(self.wa_concat(concated))"""*******************************************************"""# out = out.squeeze(1)else:out = out.squeeze(1)out = self.fc(out)output = F.log_softmax(out,dim=-1)return output,decoder_hiddendef evaluate(self,encoder_hidden,encoder_outputs):decoder_hidden = encoder_hiddenbatch_size = encoder_hidden.size(1)decoder_input = torch.LongTensor(torch.ones([batch_size,1],dtype=torch.int64))*config.chatboot_config.get("sos_idx")decoder_input = decoder_input.to(self.drive)indices = []for i in range(config.chatboot_config.get("out_seq_len")):decoder_output_t,decoder_hidden = self.forward_step(decoder_input,decoder_hidden,encoder_outputs)value,index = torch.topk(decoder_output_t,1)decoder_input = indexindices.append(index.squeeze(-1).cpu().detach().numpy())return indices注意力机制
之后的话是咱们的注意力机制,咱们这里集成的Luong,这个主要是在解码器当中使用。大概的实现也是比较简单的。
"""
The luong attention in there
"""
import torch.nn as nn
import torch.nn.functional as F
from config import config
import torch
class LuongAttention(nn.Module):def __init__(self,method="general"):super(LuongAttention,self).__init__()assert method in ["dot","general","concat"],'method err just support "dot","general","concat"'self.method = methodself.chatboot_encoder_hidden_size = config.chatboot_config.get("hidden_size")*2 if config.chatboot_config.get("bidirectional") else config.chatboot_config.get("hidden_size")self.chatboot_decoder_hidden_size = config.chatboot_config.get("hidden_size")*2 if config.chatboot_config.get("bidirectional") else config.chatboot_config.get("hidden_size")self.wa_general = nn.Linear(# encoderself.chatboot_encoder_hidden_size,# decoderconfig.chatboot_config.get("hidden_size"),bias=False)self.wa_concat = nn.Linear(self.chatboot_encoder_hidden_size+self.chatboot_decoder_hidden_size,# decoderself.chatboot_decoder_hidden_size,bias=False)self.va = nn.Linear(# decoderconfig.chatboot_config.get("hidden_size"),1,)def forward(self,hidden_state,encoder_outputs):attention_weight = Noneif(self.method=='dot'):hidden_state = hidden_state[-1,:,:].permute(1,2,0)attention_weight = encoder_outputs.bmm(hidden_state).squeeze(-1)attention_weight = F.softmax(attention_weight)elif (self.method=='general'):encoder_outputs = self.wa_general(encoder_outputs)hidden_state = hidden_state[-1:,:,:].permute(1,2,0)attention_weight = encoder_outputs.bmm(hidden_state).squeeze(-1)attention_weight = F.softmax(attention_weight,dim=-1)elif self.method == 'concat':hidden_state = hidden_state[-1,:,:].squeeze(0)hidden_state = hidden_state.repeat(1,encoder_outputs.size(1),1)concated = torch.cat([hidden_state,encoder_outputs],dim=-1)batch_size = encoder_outputs.size(0)encoder_seq_len = encoder_outputs.size(1)attention_weight = self.va(F.tanh(self.wa_concat(concated.view((batch_size*encoder_seq_len,-1))))).sequeeze(-1)attention_weight = F.softmax(attention_weight.view(batch_size,encoder_seq_len))assert attention_weight!=None,"error attention_weight can't be None"return attention_weight训练
现在的话,网络搭建完毕,那么需要做的就是训练。那么训练的话其实这个是比较简单。不过在此之前的话我们需要把刚刚的这两个网络组合在一起。
搭建seq网络
这个seq网络的搭建还是比较简单的,组合在一起就好了。
from torch import nn
from boot.chatboot.decoder import Decoder
from boot.chatboot.encoder import Encoder
from utils.drive import getDrive
from config import configclass Seq2Seq(nn.Module):def __init__(self):super(Seq2Seq,self).__init__()self.drive = getDrive()self.encoder = Encoder().to(self.drive)self.decoder = Decoder().to(self.drive)def forward(self,input_data,target_data,input_length,target_length):encoder_outputs,encoder_hidden = self.encoder(input_data,input_length)decoder_outputs,decoder_hidden = self.decoder(target_data,encoder_hidden,encoder_outputs)return decoder_outputs,decoder_hiddendef evaluate(self,input_data,input_length):encoder_outputs,encoder_hidden = self.encoder(input_data,input_length)if(config.chatboot_config.get("beam_search")):indices = self.decoder.evaluate(encoder_hidden,encoder_outputs)else:indices = self.decoder.evaluate_beamsearch(encoder_hidden,encoder_outputs)return indices训练
OK,这个时候的话我们就可以使用seq去训练咯。这部分的主要代码长这样:
from boot.chatboot.chat_dataset import Chat_dataset,collate_fn
from boot.chatboot.seq2seq import Seq2Seq
from torch.optim import Adam
from torch.utils.data import DataLoader,Dataset
import torch.nn.functional as F
from config import config
from tqdm import tqdm
import torch.nn as nn
import torch
from utils.drive import getDriveclass Train_model(object):def __init__(self,by_word=False):if(config.chatboot_config.get("use_attention")):print("\033[0;32;40m using attention by {} method !\033[0m".format(config.chatboot_config.get("attention_method")))self.drive = getDrive()self.seq2seq = Seq2Seq()self.seq2seq = self.seq2seq.to(self.drive)self.optimizer = Adam(self.seq2seq.parameters(),lr=0.001)self.train_data_loader = DataLoader(Chat_dataset(),batch_size=config.chatboot_config.get("batch_size"),shuffle=True,num_workers=config.chatboot_config.get("num_workers"),collate_fn=collate_fn)if(by_word):self.save_seq2seq = config.chatboot_config.get("seq2seq_model_by_word")self.save_optimizer = config.chatboot_config.get("optimizer_model_by_word")else:self.save_seq2seq = config.chatboot_config.get("seq2seq_model_no_by_word")self.save_optimizer = config.chatboot_config.get("optimizer_model_no_by_word")def train(self,e):self.drive = getDrive()bar = tqdm(enumerate(self.train_data_loader),total=len(self.train_data_loader),desc="training",colour='green')e_loss = 0for idx, (input_data, target_data, input_length, target_length) in bar:input_data = input_data.to(self.drive)target_data = target_data.to(self.drive)input_length = input_length.to(self.drive)target_length = target_length.to(self.drive)self.optimizer.zero_grad()decoder_outputs,decoder_hidden = self.seq2seq(input_data,target_data,input_length,target_length)decoder_outputs = decoder_outputs.reshape(decoder_outputs.size(0)*decoder_outputs.size(1),-1)target_data = target_data.view(-1)loss = F.nll_loss(decoder_outputs,target_data,ignore_index=config.chatboot_config.get("padding_idx"))loss.backward()nn.utils.clip_grad_norm(self.seq2seq.parameters(),max_norm=config.chatboot_config.get("max_norm"))self.optimizer.step()e_loss+=loss.item()bar.set_description("drive:{} \t epoch:{} \t idx:{} \t current_batch_loss:{:.2f}".format(self.drive,e,idx,loss.item()))print("\n","\033[0;32;40m drive:{} \t epoch:{} \t current_epoch_loss:{:.2f}\033[0m".format(self.drive, e, e_loss))if(e%2==0):torch.save(self.seq2seq.state_dict(),self.save_seq2seq)torch.save(self.optimizer.state_dict(),self.save_optimizer)推理
当我们训练完成之后,我们将得到权重文件。我们这里搭建的是一个两个双向的2层的GRU加上全连接。得到的权重模型大概是70MB,那么在这部分的话也是有一个简单的优化的。那就是咱们seq网络输出的是概率嘛,我们在每一个位置上,找的都是概率最大的一个词,然后作为这个位置的词,直到达到了我们预定的长度,或者说这个位置概率最大的词是结束标志。然后停止,那么在这里的话就容易出现一个问题,那就是每一步最优不一定代表全局最优,比如当前选了这个词,概率是0.3,之后下一步选一个词是0.2。而如果在上一步选择0.25的概率的词,下一步的一个词的概率有0.6,那么相对来说0.3和0.25差距可能不大,但是0.6和0.2差距是很大的。因此为了解决这个问题,有一个算法叫做beamsearch。这个玩意就是说都会走一遍,最后选出看起来效果还不错的序列作为输出。
BeamSearch
那么这个实现的话,其实集成到了decoder里面,因为推理在那边做的。
def evaluate_beamsearch(self,encoder_hidden,encoder_outputs):batch_size = encoder_hidden.size(1)decoder_input = torch.LongTensor([[config.chatboot_config.get("sos_idx")]*batch_size]).to(self.drive)decoder_hidden = encoder_hiddenprev_beam = Beam()prev_beam.add(1,False,[decoder_input],decoder_input,decoder_hidden)while True:cur_beam = Beam()for _probility,_complete,_seq,_decoder_input,_decoder_hidden in prev_beam:if(_complete==True):cur_beam.add(_probility,_complete,_seq,_decoder_input,_decoder_hidden)else:decoder_output_t,decoder_hidden = self.forward_step(_decoder_input,_decoder_hidden,encoder_outputs)value,index = torch.topk(decoder_output_t,config.chatboot_config.get("beam_width"))for m,n in zip(value[0],index[0]):decoder_input = torch.LongTensor([[n]]).to(self.drive)seq = _seq+[n]probility = _probility * mif(n.item()==config.chatboot_config.get("eos_idx")):complete = Trueelse:complete = Falsecur_beam.add(probility,complete,seq,decoder_input,decoder_hidden)best_prob,best_complete,best_seq,_,_ = max(cur_beam)if(best_complete==True or len(best_seq)-1 == config.chatboot_config.get("out_seq_len")):return self.__prepar_seq(best_seq)else:prev_beam = cur_beamdef __prepar_seq(self,best_seq):if(best_seq[0].item()==config.chatboot_config.get("sos_idx")):best_seq = best_seq[1:]if(best_seq[-1].item()==config.chatboot_config.get("eos_idx")):best_seq = best_seq[:-1]best_seq = [i.item() for i in best_seq]return best_seq
完整过程
之后的话我们可以用这个来聊聊天了。
from boot.chatboot.chat_dataset import Chat_dataset,collate_fn
from boot.chatboot.seq2seq import Seq2Seq
from config import config
from utils.drive import getDrive
from utils.cut_word import Cut
import torch
import numpy as npclass Eval_model(object):def __init__(self,by_word=False):self.by_word = by_wordself.drive = getDrive()self.seq2seq = Seq2Seq()self.seq2seq = self.seq2seq.to(self.drive)self.cut = Cut()if(by_word):self.seq2seq.load_state_dict(torch.load(config.chatboot_config.get("seq2seq_model_by_word")))self.input_ws = config.chatboot_config_load.get("word_corpus_by_word_input_load")self.target_ws = config.chatboot_config_load.get("word_corpus_by_word_target_load")else:self.seq2seq.load_state_dict(torch.load(config.chatboot_config.get("seq2seq_model_no_by_word")))self.input_ws = config.chatboot_config_load.get("word_corpus_no_by_word_target_load")self.target_ws = config.chatboot_config_load.get("word_corpus_no_by_word_target_load")def while_talk(self):while True:input_data = input("please input:")input_data = self.cut.cut(input_data,by_word=self.by_word)if len(input_data) < config.chatboot_config.get( "input_max_len"):input_length = len(input_data)else:input_length = config.chatboot_config.get("input_max_len")input_data = [self.input_ws.transform(input_data, max_len=config.chatboot_config.get("input_max_len"))]input_data = torch.LongTensor(input_data).to(self.drive)input_length = torch.LongTensor([input_length]).to(self.drive)"""index-->Plural form"""indices = np.array(self.seq2seq.evaluate(input_data,input_length)).flatten()outputs = self.target_ws.inverse_transform(indices)print("xiaojiejie:","".join(outputs))if __name__ == '__main__':eval_model = Eval_model()eval_model.while_talk()之后的话我们可以来看看效果。但是先说一下,我们的配置是GTX1650 4GB,跑一次训练需要12分钟。也就是说训练10次2个小时没了。所以我这里演示的效果不是很好,没办训练的问题,当然还有参数的调优之类的,这个的话需要各位自己拿到项目之后去训练了,而且相关数据文件比较大,所以都不会上传,各位下载好开头给的资源文件后,放到指定位置,先点击训练,他自己会生成很多文件,之后完成训练。

这个看起来是有点问题的。得慢慢调参数,然后训练。
Part05 问答处理
之后就是问答了,这个还不简单。首先的话,我们先来说说最简单的实现。
简单思路
刚刚我们在做Part04的时候的话,我想对于吧词语进行向量化应该都是比较熟悉了吧。没错对于这个处理的话,我们可以先直接把问题转化为向量,把用户的输入也是转化为向量,然后计算这些问题向量和你用户输入的向量计算一个相似度。比如我们计算一个余弦相似度,然后的话,拿到概率最高的那个问题向量对应到的回答,之后的话,把回答拿出来就好了。
但是这样的话计算量就比较大了,我们可以来进行简单的简化。好吧其实也是参考人家的思路。首先的话我们可以参考原来的方案,将问题转化为序列。之后先通过聚类,将问题进行分类。当用户输入的时候,计算用户输入的序列和我们结果簇心的相似度,得到topK,将相似度最像的几个拿出来,之后再去遍历。这样的话就不用挨个遍历了,计算量也就是下来了。这里的话也是可以选择手写,或者调包,按照我们的尿性肯定是手写(才怪)。
OK,这里我介绍就到这里,方法很多,不限于这个。你甚至直接拿我们刚刚part04的来做也是可以的,这个时候就完全是一个严格符合分类的模型了,和对话不同,问答是有明确答案的。当然俺们在这块也就是口嗨一下,把严谨的过程搞出来,还是有点难度的。
难点
OK,我们这边简单分析了一下,我们处理问答的一个情况。那么其实在这里的话,你也发现了,难点其实在于计算,就是说我们都需要进行和问题之间的不断计算最终得到一个排序。其实包括我们之前的这个推荐dome也是,当时我们甚至使用了svd进行一个分解降低运算。
那么是否有更好的方案呢,有的,每次就是我们刚刚开玩笑的直接使用seq。但是当然不是直接使用seq2seq了。只是说我们会构建一个网络来做这件事情。试想一下直接有一个输入,只需要走一次forward,那么就可以得到答案是不是计算量就下去了,只是训练比较繁琐。并且我们不仅仅可以用在这里,我们还可以对我们先前的用户协同过滤进行一个优化。当然这个方案的缺点都是训练麻烦,如果有新的变动的话,但是对于这种我们确实一般都是批处理的,问题还是不大的。
上文分割线
OK,受限于文章的长度,我们做一个切分

后面的咱们还有具体的问答处理的实现,以及咱们对这个项目的简单封装。



![部署一个人工智能[AI]](https://img-blog.csdnimg.cn/img_convert/18069c93af8243aa9fc127aeee819900.jpeg)




![[day5]python网络爬虫实战:爬取Top250电影(Scrapy版)](https://img-blog.csdnimg.cn/cd6b18e198dd46c8b5903bbfb197a362.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAZGRub3No,size_17,color_FFFFFF,t_70,g_se,x_16)

