1. 引言
自ChatGPT发布至今已近半年,一路走来,我们可以清楚地看到的一个趋势是,到了下半年,每位研究者都会拥有一个类似ChatGPT的模型。这种现象与当年BERT推出后,各种BERT变体层出不穷的情况颇为相似。实际上,我认为,这次ChatGPT的浪潮依然是一次技术迭代更新,不断推动我们迈向最终的AI目标。而之所以如此轰动,则是因为OpenAI只做了一个每个人都可以访问的网页,让大众体会到了最先进的科技水平。
那么,我们能否自己再造一个大规模预训练语言模型呢?回答是肯定的。不过在给出答案之前,我们会通过三张图阐述三个部分,揭开如今复刻ChatGPT模型的真实面纱。首先,我们将梳理自ChatGPT问世以来的重大事件;其次,我们将探讨类ChatGPT模型的再造方案;最后,我们将对近期国内相关模型进行梳理。
2. ChatGPT以来的大事件
自2022年11月30日ChatGPT发布以来,关键事件和发展节奏越来越紧凑。
2023年2月1日,在ChatGPT发布三个月后,付费版的ChatGPT Plus问世。从那时起,许多免费账户会因为网站繁忙而无法登录到界面,这间接影响了ChatGPT的推广。但是,在接下来的一周后,New Bing的发布使得检索增强生成(RAG)再次成为大家关注的焦点。New Bing丰富的情感表达使其与传统的ChatGPT表现截然不同,有人猜测它们使用了完全不同的基础模型,这也不无可能。New Bing的发布为后续检索增强生成相关工作奠定了基础。
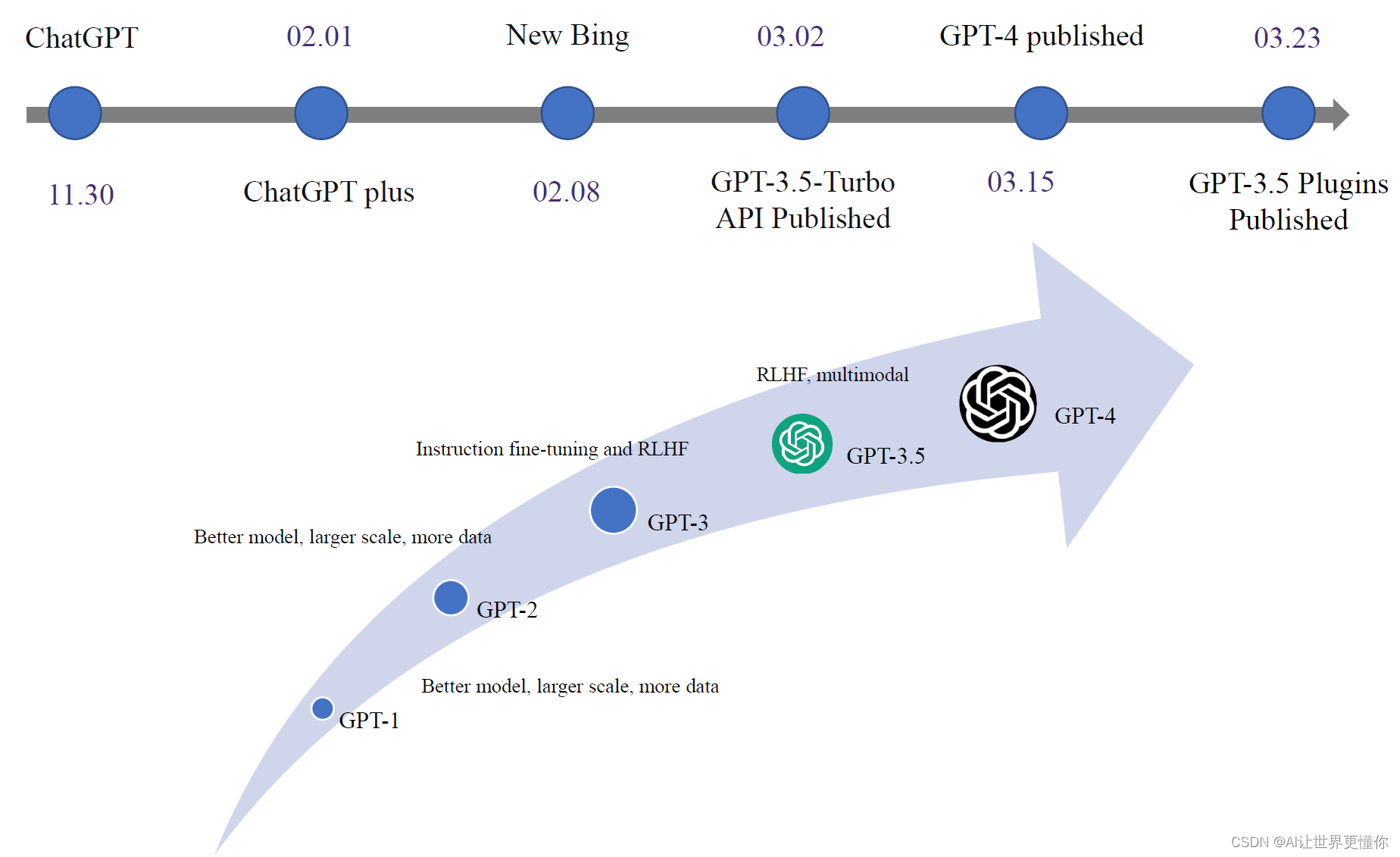
到了3月2日,也就是一个月后,GPT-3.5的API发布。从那时起,复制ChatGPT变成了一项低成本且可实现的目标。因为通过API调用,可以大规模自动化地评估ChatGPT的各种能力,同时更方便地基于ChatGPT完成一些任务。
又过了两周,GPT-4发布了,但仅付费用户才能体验。根据我本人的使用经验,GPT-4确实比GPT-3.5更强大,特别是在安全性和事实性方面都有所提升。其98页的技术报告不仅揭示了技术细节,更展示了整个GPT-4团队的组成。大家可以了解如何构建这样一个顶尖模型所需的团队。(如果只是发布模型,那么可能不需要这么多人。但如果是一个负责任的公司开发一个真正能为大众服务的产品,确实需要这样的团队。)

一周后,GPT-3.5插件发布。尽管这是一个相对罕见的功能,但它展示了如何与其他应用程序进行外部连接的方式,类似于操作系统或浏览器。它能完成一些令人惊叹的工作,但如果不能确保100%准确执行命令,将其推广到任何程序中仍具有较大挑战。与现有编程语言的确定性不同,ChatGPT的回复并不总是遵循指令。在少量使用时可能感受不到,但一旦涉及到百万次调用,就会发现有相当数量的错误率。这使得其运行过程缺乏可信度,在某些高度严格的场景下,ChatGPT系列仍然难以胜任。
3. 梳理类ChatGPT模型再造方案
如果你还不了解大羊驼(LLaMA)、小羊驼(alpaca)和小小羊驼(vicuna),那么现在是时候了解一下了。自从Meta发布了优于GPT-3的LLaMA模型后,我们才拥有了复制ChatGPT的基础材料。因为自GPT-3时代起,模型就已经不再开源,更不用说ChatGPT系列了。不过,幸运的是,作为新晋模型,LLaMA比GPT-3要优秀很多。尽管没有经过指令微调,但仍然展示出一定的指令执行能力。值得注意的是,LLaMA是今年初发布的,比GPT-3的发布晚了两年半,理论上更加出色。
因此,可以说LLaMA实际上是GPT-3的替代品,只不过它更好(13B的LLaMA强于175B的GPT-3)。有了它,就有了复制ChatGPT的可能性。当然,其他大型模型,如BLOOM等,也可以作为替代品,并且也能取得不错的效果。
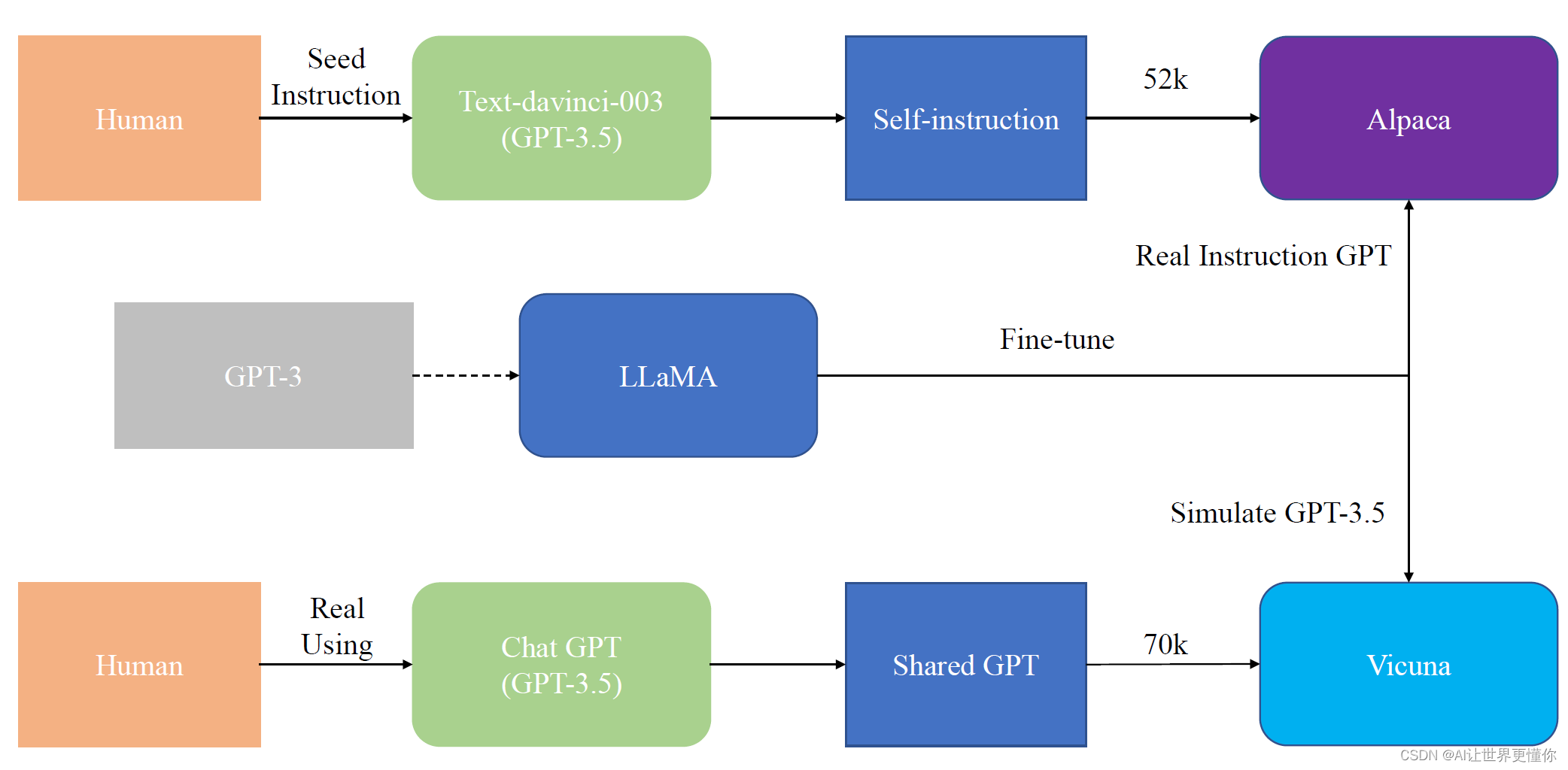
而在复刻ChatGPT的道路上,早期的设想复制ChatGPT的方法是,重新走一遍ChatGPT的发展道路。这条路既漫长又艰难,因此很难完全执行。这是最早的复制想法。
后来,斯坦福的Alpaca提供了第二条道路:既然人工指令很难收集,那么可以通过已经训练好的GPT-3.5进行自我指令学习。通过极少的人工构造模型,就可以生成大量的ChatGPT指令集,然后通过这样的指令集进行学习,是否就能训练出一个高级版的InstructGPT呢?Alpaca的成功证明了这一点。Alpaca是一个通过GPT-3.5模型进行数据增强,从而通过52K指令集训练出的真正的高阶InstructGPT。
这种方法已经成为目前的主流,可以将其称为第一代复制技术。然而,就在一周前,Vicuna模型的出现使得第二代复制技术成为可能。第二代技术的发展源于开源精神。既然ChatGPT不开源,那么为什么不众筹一个开源数据集呢?于是,基于ShareGPT众筹的真实用户与ChatGPT的70K的对话数据样本,蒸馏一个能够模拟ChatGPT表现的模型,就是Vicuna。值得注意的是,Vicuna使用的训练方法是微调方式,即在多轮对话中,只要拟合ChatGPT说的话语,将其Loss进行回传。
4. 国内的大模型发展
国内众多研究机构通过第一种或第二种方式训练了自己的中文ChatGPT。最早的一个要数复旦大学的MOSS模型,但直到现在仍在改造中。因此,我们并不清楚它究竟是基于何种基座模型训练的。不过在第一种复刻方法出现时,有人指出MOSS可能就是这样训练而来的。
紧接着,清华大学的ChatGLM亮相。根据ChatGLM博客的说法,它是经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术加持训练而成的。
随后,基于BLOOM训练的BELLE和基于LLaMA的BAIZE等模型逐渐崭露头角,它们都具有自己的特色,如BLOOM的多语言支持和BAIZE的自我聊天等。由于以上研究涉及商业许可问题,仅可用于学术交流。然而,作为公司,仍需商业化运作,因此,仍需要自己重新走一遍ChatGPT的道路。因此,像百度发布的文心一言、阿里最近发布的通义千问等,都是类ChatGPT的模型。

5. 小结
当前的发展形势下,基于大模型的研究领域仍然广阔。例如,更优秀的数据收集方法、更高效的模型训练和部署,以及如何将LLM应用到下游任务等方面。尽管有人曾声称,NLP从未真正存在过,将来也不会存在,但我并不完全认同这一观点。虽然一些现有任务已经取得了很好的成果,但人工智能整体表现水平仍未达到我们的期望,也难以完全自主地创造价值。因此,对于NLPer来说,我更倾向于认为这波LLM实际上是GPT系列模型作为主流的发展趋势,正如曾经的BERT模型引领的五年发展潮流一样。每一次技术进步都让我们更接近最初的人工智能大师们所期望的场景,为此我们不断努力奋斗。
最近每天都要熬夜到2-3点,尽管如此,也依然跟不上技术的发展步伐。我只希望能够紧跟科技发展的脚步,不至于被甩得太远。