大语言模型正在朝着两个方向发展,一个是以ChatGPT为代表的通用大模型,另一个则是行业大模型(或称为“专业大模型”)。如果大模型的演化分为阴阳两面,通用大模型更像是阳面,受众更广、更to C端,以个人助手、AI搜索为代表;行业大模型像是是阴面,受众都是行业专业人士、也更to B端,其中以各种医疗专业助手、法律专业助手为典型。

本篇文章,将带大家一起来了解大模型的另外一面,包括医疗、教育、法律、金融和科研五大专业场景。这些行业大模型的构建思路基本都是在通用大模型的基础上增加预训练行业专业数据,并构建行业SFT数据,对模型进行指令微调,从而使行业大模型既具备通用大模型的基础理解和推理能力,又具备行业专业知识,从而让行业大模型达到行业专家的水平。
一、医疗行业
医疗是与人类生活密切相关的重要领域之一。由于具有较强的通用任务解决能力,大语言模型被广泛用于辅助医生处理各种相关医疗任务,例如医疗诊断、临床报告生成、医学语言翻译、心理健康分析等。为了充分发挥大语言模型在医疗领域的作用,研发医疗相关的大语言模型非常重要。
1、医疗大模型构建
已有的医疗大语言模型主要以通用大语言模型为基础,通过继续预训练技术或者指令微调方法,让其充分适配医疗领域,从而更好地完成下游的医疗任务。在继续预训练阶段,医疗大语言模型可以利用医学领域丰富的数据资源(如医学教材、诊断报告等),学习医学领域的专业知识与相关技术,进而准确理解医学文本数据的语义信息。
为了解决复杂且多样的医疗任务,还需要进一步构建特定的指令集合对模型进行指令微调。在真实场景中,医疗相关指令数据相对较少,可以通过收集医患对话数据或医学问答数据集,在此基础上设计指令模板,来构造面向不同医疗任务的指令数据。为了增强模型回答的准确性和可信程度,还可以将医疗大语言模型和医学数据库进行结合,利用检索增强等方法来提升模型在处理复杂医疗任务时的能力。
此外,现有的医疗大语言模型通常基于英文语料进行训练,可能无法充分覆盖中医相关的知识体系。为了研发中医相关的医疗大语言模型,可以利用现有中医语料库构造预训练数据和微调指令,进而提升对于传统中医理论的理解与应用能力。进一步,在医疗领域中,影像信息具有重要的数据价值(X光片、MRI光片等),能够提供关于患者病情的直观信息。
因此,构建能够理解医疗文本和视觉信息的多模态大语言模型,有着较大的应用前景。为了实现这一目标,可能需要针对性地设计医疗图文指令。例如,可以对病灶区域进行专业标注,并设计对应的病情诊断指令。
2、医疗数据资源
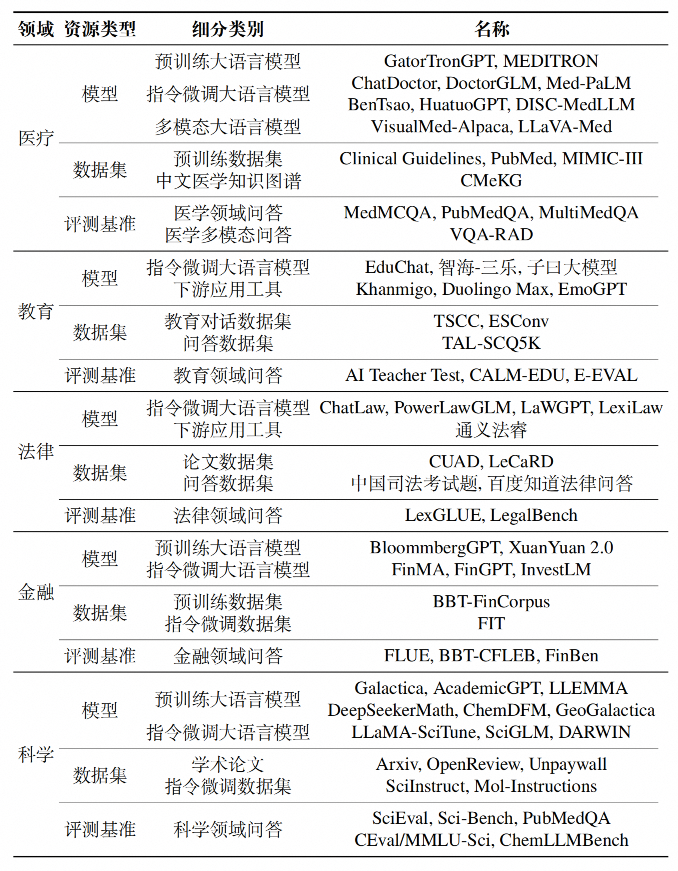
| 领域 | 资源类型 | 细分类别 | 名称 |
|---|---|---|---|
| 医疗 | 模型 | 预训练大语言模型 指令微调大语言模型 多模态大语言模型 | GatorTronGPT, MEDITRON ChatDoctor, DoctorGLM, Med-PaLM BenTsao, HuatuoGPT, DISC-MedLLM VisualMed-Alpaca, LLaVA-Med |
| 数据集 | 预训练数据集 中文医学知识图谱 | Clinical Guidelines, PubMed, MIMIC-III CMeKG | |
| 评测基准 | 医学领域问答 医学多模态问答 | MedMCQA, PubMedQA, MultiMedQA VQA-RAD |
医疗领域有许多开源的数据资源可用于模型的训练与评估。其中,预训练医疗大模型的数据来源主要包括电子病历、科学文献和医学问答等。
- 电子病历数据通常由病人的健康诊断数据构成,该类数据能够帮助大语言模型理解医疗领域术语,并学习医疗诊断和分析方法。
- MIMIC-III是目前被广泛使用的电子病历数据集,共包括40K余名病人的健康数据,覆盖医生诊断、生命体征测量、医学影像、生理数据、治疗方案、药物记录等信息。
- 作为另一种重要预训练数据源,科学文献中包含了许多与医疗领域研究相关的学术研究文档,并且普遍具有较为规范的格式。此外,医疗领域还存在大量的医学问答与医患对话数据,这些数据常用来构建指令数据集,用于医疗大模型的指令微调。
为了对医学大语言模型进行评测,通常使用医学问答数据以自动化地评估医学文本理解以及医学知识利用的能力。其中,MultiMedQA是一个被广泛使用的医学问答评测基准,共由7个医学问答数据集组成,包含了来自多个医学领域的问答对,涵盖了临床医学、生物医学等健康相关的多种主题。此外,针对多模态医疗大模型,常使用包含医学影像和与之相关的问答对数据对其进行评测,其侧重于评测模型对医学图像的理解能力以及对图文模态信息的综合利用能力。
除了利用开源的数据资源进行自动评估,也可以通过邀请专业医生参与医疗大语言模型的评估,确保模型在实际临床应用中的安全性和有效性。该类方法通过让医学专家或临床医生审查模型生成的文本,从医学领域的准确性、临床适用性和专业性等角度,评估该模型生成内容的准确性和可靠性。
二、教育行业
教育是人类社会进步的基石,对个人和社会发展都至关重要。在教育系统中,大语言模型已经被用于多种教育相关任务,有助于增强教育场景的智能化、自动化和个性化。
1、教育大模型构建
通常来说,教育应用系统面临着多样的用户需求(如作文批改、启发式教学、试题讲解等),而且要支持与用户进行便捷的交互。为此,教育大语言模型需要基于海量的教育相关文本和专业数据对大模型进行训练,并结合大规模的对话数据进行指令微调,从而适配教育应用场景下的多种需求。
考虑到教育领域不同学科往往具有显著的知识差异,还可以针对各学科设计专用的教育大模型。例如,可以构建专门面向数学学科的垂域大模型,强化数学学科特有的定理公式等专业知识,并能提供具有启发性的结题过程,以适应数学辅导的实际应用需求。
在此基础上,也可以将各学科的垂类模型集成为一个综合教育系统,从而为多学科提供全方位的教学支持和服务。此外,也可以通过集成网络检索增强和本地知识库等功能,在实际应用时提升在特定场景下教育大模型的效果。然而,由于教学数据可能包含用户隐私,使用其训练后的大语言模型可能存在隐私泄露的风险。因此,目前的开源教育大模型较少,已有的模型普遍通过向用户提供API的方式对外服务。
2、教育数据资源
| 领域 | 资源类型 | 细分类别 | 名称 |
|---|---|---|---|
| 教育 | 模型 | 指令微调大语言模型 下游应用工具 | EduChat, 智海-三乐, 子曰大模型 Khanmigo,Duolingo Max, EmoGPT |
| 数据集 | 教育对话数据集 问答数据集 | TSCC, ESConv TAL-SCQ5K | |
| 评测基准 | 教育领域问答 | AI Teacher Test, CALM-EDU, E-EVAL |
教育领域大模型相关的数据资源主要包括两类,即适配教育场景的训练数据和衡量大模型教育能力的评测数据。
其中,教育大模型所用的预训练数据通常来源于学科教材、领域论文与教学题库,这些数据能够在预训练阶段为大语言模型注入学科领域的专业知识。进一步,也可以邀请人类专家或使用大语言模型将其改写为指令数据,用于对大语言模型进行指令微调。例如,邀请专家标注题目解析指令数据,或使用ChatGPT仿真教学场景下的师生对话。
此外,也可以从真实教育场景或在线教学平台中,利用录音、录像等形式采集真实学生数据,用于构造指令数据,例如教师和学生之间的真实对话。师生聊天室语料库(Teacher-Student Chatroom Corpus,TSCC)收录了102个不同教室内匿名师生的真实对话,总计十万多个对话轮次。在每轮对话中,教师和学生进行语言练习并评估学生的英语能力,同时提供个性化的练习和纠正,故该数据集可以用于教育场景下的指令微调。
对教育领域大模型的评估主要关注于以下两个方面:在辅助学习过程中的教学能力和对教育领域知识的理解能力。对前者的评测需要收集现实世界中教师与学生的对话,然后利用大语言模型模拟人类教师对学生进行教学指导,从表达方式、理解能力、辅助教学等方面分别进行评估。进一步,对后者的评测可以直接针对知识层次和学科特点,选择合适的已有教学题库进行测评。
三、法律行业
在法律领域,相关从业人员需要参与合同咨询、审查、案件判决等日常重复性任务。这些任务需要耗费大量的人力成本,亟需面向法律领域的人工智能技术辅助完成这些工作,从而减轻从业人员的工作负担。大语言模型具有优秀的模型能力,经过领域适配以后,能够助力完成多种法律任务,如合同信息抽取、法律文书撰写和案件判决生成,具有较好的应用场景。
1、法律大模型构建
为了构建法律大语言模型,可以采集大量的法律相关的文本数据,进而针对通用大语言模型进行继续预训练或指令微调,使其掌握法律领域的专业知识。Chat-Law是一个面向中文的法律大语言模型,其训练数据主要来源于法条、司法解释、法考题、判决文书、法律相关论坛和新闻等。ChatLaw目前主要有两个版本,即ChatLaw(13B)和ChatLaw(33B),分别基于Ziya-LLaMA(13B)和Anima(33B)基座模型训练获得,具有较好的法律文本理解与任务处理能力。
由于法律领域具有高度的专业性、且不同国家法律存在差异,在训练法律大模型时需要考虑其适用范围。例如,在中文法律场景下,需要在构造训练数据时去除不符合中国法律的相关训练数据,并且针对常见的法律案例、咨询需求等构造指令数据集,从而更准确地理解中国用户的法律需求。
2、法律数据资源
| 领域 | 资源类型 | 细分类别 | 名称 |
|---|---|---|---|
| 法律 | 模型 | 指令微调大语言模型 下游应用工具 | ChatLaw, PowerLawGLM, LaWGPT, LexiLaw 通义法睿 |
| 数据集 | 论文数据集 问答数据集 | CUAD, LeCaRD 中国司法考试题, 百度知道法律问答 | |
| 评测基准 | 法律领域问答 | LexGLUE, LegalBench |
法律领域有许多可用于模型训练与评估的数据资源。其中,可用于训练法律大模型的数据资源主要包括法律法规、裁判文书等法律数据。这些数据通常可以从相关官方网站下载获得,且数据规模较大,能够为大模型提供大量的法律专业知识。
进一步,还可以收集司法考试题目、法律咨询、法律问答等相关数据,此类数据涉及了真实用户的法律需求与基于法律专业知识的解答,通常可以用于指令数据的构造,进而对于模型微调。Cuad是一个包含510个商业法律合同、超过13K个标注的合同审查数据集,由数十名法律专业人士和机器学习研究人员共同创建。通过法律专业人士对这些合同数据进行扩充和详细标注,可以得到高质量的法律相关指令数据,从而提升法律专用垂直大模型的微调效果。
此外,上述数据也可以用来构建法律领域的评测基准,用于全面评估法律专用的大语言模型的性能。其中,司法考试题目常用于对模型进行评测,相较于传统问答数据集,司法考试题目的问答依赖于对大量专业知识的理解,以及对大量相关资料的参考结合,因此具有较高的难度与专业度,可用于法律大模型的综合能力评估。
四、金融行业
随着金融科技的快速发展,金融领域对于自动化的数据处理和分析技术日益增长。在这一背景下,大语言模型技术开始逐步应用于金融领域的多种相关任务(如投资倾向预测、投资组合设计、欺诈行为识别等),展现出了较大的应用潜力。
1、金融大模型构建
与前述垂域模型的研发方法相似,可以将通用大语言模型在金融领域数据上进行继续预训练或指令微调,进而构建金融大语言模型,提高其在金融相关任务上的表现。
为了训练金融大语言模型,需要收集大量的金融领域文本数据,通常还可以再添加通用文本数据以补充广泛的语义信息。其中,可供使用的金融领域数据主要包括公开的公司文件、金融新闻、财务分析报告等,可以为大语言模型补充金融领域的专业知识。
其中,一个具有代表性的金融大语言模型是BloombergGPT,该模型采用自回归Transformer模型的架构,包含50B参数,使用了363B token的金融领域语料和345B token的通用训练语料从头开始预训练。其中,金融领域数据主要来自于彭博社在过去二十年业务中所涉及到的英文金融文档,包括从互联网中抓取的金融文档、金融出版物、彭博社编写的金融新闻以及社交媒体等。BloombergGPT在金融评测基准上的表现优于OPT、BLOOM等通用开源大语言模型,并且在通用自然语言评测基准上能达到这些通用大语言模型相近的性能。
2、金融数据资源
| 领域 | 资源类型 | 细分类别 | 名称 |
|---|---|---|---|
| 金融 | 模型 | 预训练大语言模型 指令微调大语言模型 | BloommbergGPT, XuanYuan 2.0 FinMA, FinGPT, InvestLM |
| 数据集 | 预训练数据集 指令微调数据集 | BBT-FinCorpus FIT | |
| 评测基准 | 金融领域问答 | FLUE, BBT-CFLEB, FinBen |
金融领域的预训练数据通常包含公司与个人的专有信息,可能会涉及到隐私问题,因此开源数据相对较少。目前研究社区公开的金融领域数据资源主要为指令和评测数据集。
已有的指令数据集通过整合金融领域的各类任务数据(例如新闻标题分类、命名实体识别、股票趋势预测)和现实应用场景中的问答或对话数据(例如注册金融分析师考试、在线平台上金融讨论帖等),并将其整理为统一形式的指令数据,用于提升模型对金融领域文本的理解能力和在现实金融场景中的实用性。
FIT是一个较具代表性的金融指令数据集,共包含136K条指令。其原始数据来源于9个金融领域自然语言数据集,涵盖了5类金融自然语言任务。
为了对金融大语言模型进行评测,已有的金融领域评测基准涵盖了多种金融领域的任务。其中,FinBen收集了35个金融相关数据集,共涉及23类不同任务。这些任务根据难度被分为3个级别:
五、科研
科学研究是研究人员探索科学问题的学术活动,对于人类社会的发展与进步有重要意义。在科研过程中,研究人员往往需要面对复杂的科学问题,处理与分析大量的实验数据,并需要及时学习最新的科学进展。在这一过程中,可以使用大模型技术来辅助人类的科研探索工作,进而推动科学研究的快速进展。
1、科研大模型构建
通过使用科学领域相关的数据对大语言模型进行预训练或微调,可以使其适配于科学研究场景下的各类任务。
Galactica是MetaAI公司于2022年11月推出的科学大模型,该模型通过在48M篇论文、教科书和讲义、数百万个化合物和蛋白质、科学网站、百科全书等大量科学相关数据上预训练得到的。
实验结果表明,Galactica可以解决许多很多复杂科研任务,包括辅助论文撰写、物理问题求解、化学反应预测任务等。此外,对于特定的科学领域(如数学、化学、生物等),也可以通过收集领域特定的数据集合,针对性训练特定的大语言模型。
在研发科学领域的大语言模型时,需要选择合适的基座模型和高质量的训练数据。例如,对于数学等理工学科,可以采用基于代码的大语言模型作为基座模型,并需要收集大量包含形式化的文本(如包含有公式、定理证明等)作为预训练数据。
此外,在设计面向科学研究场景的指令数据时,需要尽量覆盖相关任务场景下的基础任务(如科学概念理解和问答)与特殊的应用需求(如数值计算和定理证明),还可以针对性地适配特殊的数据形式(如化学表达式),从而更为精准地解决领域内的应用需求。
2、科研数据资源
| 领域 | 资源类型 | 细分类别 | 名称 |
|---|---|---|---|
| 科学 | 模型 | 预训练大语言模型 指令微调大语言模型 | Galactica, AcademicGPT, LLEMMA DeepSeekerMath, ChemDFM, GeoGalactica LLaMA-SciTune, SciGLM, DARWIN |
| 数据集 | 学术论文 指令微调数据集 | Arxiv, OpenReview, Unpaywall SciInstruct, Mol-Instructions | |
| 评测基准 | 科学领域问答 | SciEval, Sci-Bench, PubMedQA CEval/MMLU-Sci, ChemLLMBench |
目前有很多开放的数据资源可用于研发科研大语言模型。其中,公开的学术论文被广泛用作预训练数据。
arXiv作为全世界最大的论文预印本收集平台,其收录了近2.4M篇学术文章,涵盖物理学、数学、计算机科学、定量生物学等领域,提供了非常高质量的科研文本数据。除此之外,研究人员还可以通过其他科研论文平台进行数据的收集,如PubMed和Semantic Scholar,进一步扩充学术论文的范围与规模。
由于科学领域数据可能包含特殊格式的数据(如蛋白质序列等),通常需要对其进行专门的处理,使其转换为统一的文本表示形式(如转成Markdown格式)。此外,科学领域还存在大量的开源问答数据集,如专业考试习题、社区问答数据等,这些数据经常用于构造指令数据集,以帮助大模型进行指令微调。
为了评测大语言模型对于科学知识的掌握程度,科学领域的问答数据也被广泛用于大模型的能力评测。这些任务不仅需要模型理解基本的科学概念与理论知识,还需要具有多步推理与复杂计算的能力。其中,Sci-Bench是一个代表性的科学知识评测基准,该评测基准构造了一个大学程度的科学问题数据集,涵盖了从化学、物理和数学教科书中收集的789个开放性的问题。进一步,该评测基准还包括了一个多模态子集,可以用于评估多模态大语言模型解决科学问题的能力。
【推广时间】
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台,目前注册送20元测试金,可以畅享7小时4090算力,预装了主流的大模型和环境的镜像,开箱即用,非常方便。