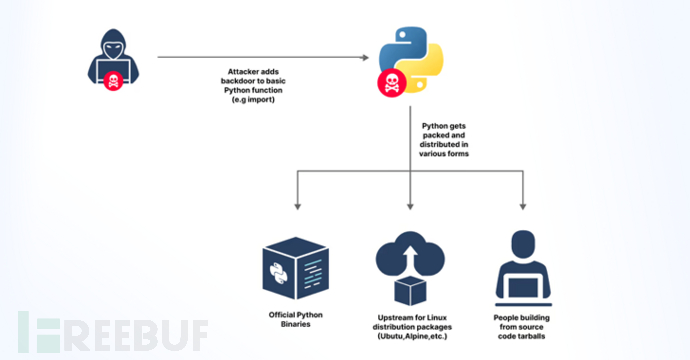
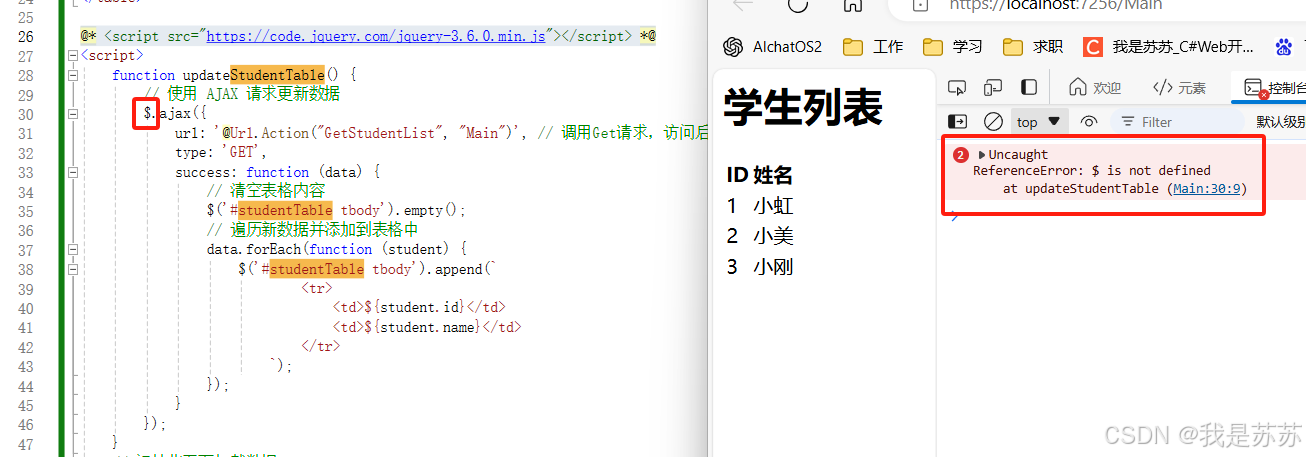
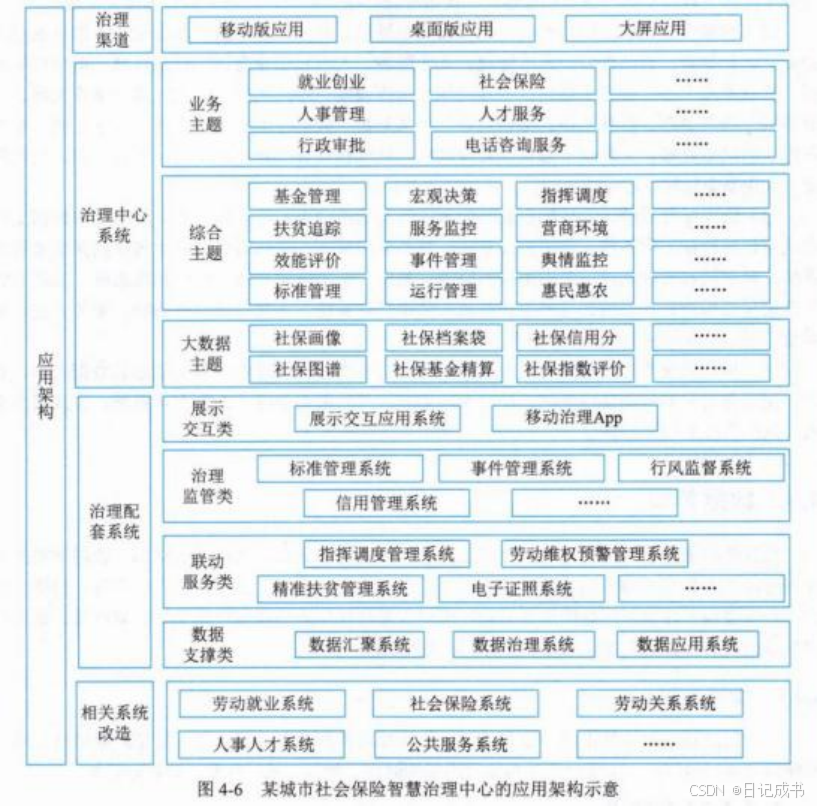
人工智能咨询培训老师叶梓 转载标明出处
现有的大模型(LLMs)在处理长文本时受限于固定的最大上下文长度,并且当输入文本越来越长时,性能往往会下降,即使在没有超出明确上下文窗口的情况下,LLMs 的性能也会随着输入文本长度的增加而下降。为了克服这些限制,Google DeepMind 和 Google Research 的研究团队提出了一种新颖的解决方案——ReadAgent,一种能够显著扩展上下文理解能力的人工智能阅读代理。
ReadAgent 的设计理念受到人类如何互动阅读长文档的启发。人类在阅读时往往会快速忘记具体信息,而对大意或主旨(gist)的记忆则更为持久。此外,人类的阅读是一个互动过程,当我们需要提醒自己完成任务(例如回答问题)的相关细节时,我们会回顾原文。基于这些观察,ReadAgent 通过三个主要步骤来模拟人类的阅读过程:分段(episode pagination)、要点压缩(memory gisting)和交互式查找(interactive look-up)。
在实验评估中,ReadAgent 在 QuALITY、NarrativeQA 和 QMSum 三个长文档阅读理解任务上的表现超越了基线方法。特别是在 NarrativeQA Gutenberg 测试集上,ReadAgent 将 LLM 的评分提高了 12.97%,ROUGE-L 提高了 31.98%,并将有效上下文长度增加了约 20 倍。
ReadAgent介绍

Figure 1 展示了 ReadAgent 的工作流程,这是一个模仿人类阅读习惯设计的系统,旨在有效处理和理解长文本。ReadAgent 通过三个主要步骤来实现这一目标:
-
分页(Episode Pagination):系统将长文本分解为一系列较小的、逻辑上连贯的文本块,即“剧集”,类似于将一本书分成多个章节。
-
要点压缩(Gisting):对每个文本块进行压缩,提取其核心要点,形成简洁的要点记忆,这有助于快速把握文本的主旨。
-
交互式查找(Interactive Look-Up):在需要详细回顾特定信息时,系统会根据任务需求和已有的要点记忆,选择性地查看原始文本的相关部分,以获取更详尽的细节。
在 ReadAgent 系统中,要点记忆(Gist Memory)扮演着至关重要的角色。它的核心思想是将长篇文本的信息压缩成易于管理和理解的要点集合。这种压缩不仅减少了处理文本所需的工作量,而且使得关键信息更加突出,便于后续的查找和使用。
构建要点记忆的过程涉及两个主要步骤:
-
分页(Pagination):这一步骤中,ReadAgent 将长文本分解为一系列的文本块,这些文本块被称为“剧集”或“页”。通过提示(prompting)大型语言模型(LLM),ReadAgent 决定在文本的自然断点处进行分页,如场景转换、对话结束或叙述的逻辑分界点。这种方法模仿了人类在阅读时自然停顿的习惯,有助于将文本组织成更易于处理的部分。
-
记忆要点化(Memory Gisting):在分页完成后,ReadAgent 对每一页的内容进行压缩,提取出关键信息并形成要点。这个过程类似于人类在阅读后对文本主旨的记忆,强调了文本的核心内容而非具体细节。通过这种方式,ReadAgent 能够将每一页的文本转化为简短、精炼的要点,便于存储和快速回顾。

并行和顺序交互式查找是 ReadAgent 系统的另一个关键特性。这一功能使得 ReadAgent 能够在需要时,查找原始文本中的相关细节,从而补充和丰富其要点记忆。
并行查找(Parallel Look-Up):在这种模式下,ReadAgent 可以同时请求查看多个页面或文本块。这种方法允许模型快速获取广泛的上下文信息,适合于需要同时考虑多个信息源的任务。
顺序查找(Sequential Look-Up):与并行查找不同,顺序查找是一种逐步的过程,ReadAgent 一次只请求查看一个页面或文本块,并在查看前一个页面后再决定查看下一个页面。这种方法更适合于需要深入理解文本发展脉络的任务。

计算开销和可扩展性是两个核心考量因素。尽管 ReadAgent 依赖于迭代推理,但设计上确保了这种推理的计算成本是可控的,并且随着处理文本长度的增加,系统能够良好地扩展。
分页(Pagination)是 ReadAgent 处理长文本的第一步。理想情况下,一个大型语言模型(LLM)可以一次性阅读整个文档并进行分页。然而,ReadAgent 采用了一种算法,将文档分解为长度不超过 max_words 的块,并确保每个处理步骤至少处理 min_words 的文本。这种方法不仅提高了处理效率,而且使得 LLM 在面对长文档时的计算负担变得可管理。
要点压缩(Gisting)是随后的一个步骤,它涉及将每一页的文本压缩成更简洁的要点。这种压缩是对原始文本的额外处理,但与处理完整文本相比,它显著减少了需要处理的信息量。这种方法使得并行查找可以基于要点而不是完整的文本,从而减少了处理时间。
在响应(Response)阶段,模型生成最终答案的过程类似于并行查找。尽管提示模板可能会增加一些额外的计算开销,但这种方法允许模型在生成答案时更加精确和高效。
ReadAgent 变体提供了不同的配置选项,以适应不同的应用场景。这包括无条件 ReadAgent 和条件 ReadAgent。
无条件 ReadAgent:在这种设置中,要点压缩时不包含特定任务的描述。这种方法适用于任务未知或要点需要用于多个任务的情况。虽然这可能会牺牲一些压缩率,并增加一些干扰信息,但它确保了生成的要点具有更广泛的适用性。
条件 ReadAgent:当任务在阅读长文档之前已知时,可以在要点压缩步骤中包含任务描述。这种方法使得 LLM 能够更有效地压缩与任务无关的信息,从而提高效率并减少干扰。
通过这些设计,ReadAgent 能够灵活地适应不同的任务需求,同时保持计算效率和可扩展性。这种方法不仅提高了处理长文本的能力,还使得系统在面对不断变化的任务和文档长度时,能够持续提供高质量的服务。
实验
作者采用了两种自动评估方法,旨在模拟人类评估者对模型生成答案的评判。这两种方法分别是严格的 LLM Rater 和宽容的 LLM Rater。
严格的 LLM Rater:
这种方法要求模型生成的答案与参考答案完全一致,才能被判定为正确。评估时,模型会接收到一个提示,提示中包含了问题和模型的答案,然后模型需要判断这个答案是否与参考答案完全匹配。例如,如果问题要求解释某个概念,而模型生成的答案与专家提供的参考答案完全一致,那么这个答案就会被严格 LLM Rater 判定为正确。
宽容的 LLM Rater:
与严格 LLM Rater 不同,宽容的 LLM Rater 允许一定程度的偏差。即便模型生成的答案不完全与参考答案一致,只要答案中包含正确的关键信息或部分匹配,也会被判定为正确或部分正确。这种方法更加灵活,允许模型在理解问题的基础上,提供与参考答案不同的但仍然合理的回答。
在比较 ReadAgent 与其他基线方法时,作者考虑了几种不同的方法:
Retrieval-Augmented Generation (RAG):这种方法结合了检索和生成,通过检索长文本中相关的“页面”或文本片段,然后将这些片段作为上下文,辅助生成答案。这种方法的优势在于能够利用大量文本信息来辅助回答,但可能在整合信息时面临挑战。
Full or Truncated Text Content:在这种方法中,模型直接使用完整的或截断的原始文本作为上下文来生成答案。这种方法简单直接,但可能会因为文本过长而导致模型难以捕捉到所有相关信息。
Gist Memory:这种方法利用压缩后的要点记忆来回答问题。通过将长文本压缩成简短的要点,模型能够更快速地理解和回应问题,但可能会丢失一些细节信息。

作者探讨了 ReadAgent 在处理长文本阅读理解任务时的表现,特别是在 QuALITY、NarrativeQA 和 QMSum 三个不同的数据集上。这些数据集提供了多样化的挑战,涉及不同长度和类型的文本,从而全面评估 ReadAgent 的能力。
QuALITY 数据集:
QuALITY 挑战是一个典型的多项选择题问答任务,要求模型从四个选项中选择正确答案。在这项任务中,ReadAgent 的表现通过准确性来衡量。
作者特别关注了压缩率(CR)和查找次数(LU)对 ReadAgent 性能的影响。压缩率衡量了文本在压缩成要点记忆后保留信息的能力,而查找次数则反映了模型在回答问题时需要回顾的原始文本量。
实验结果显示,ReadAgent 在压缩文本的同时,能够有效地查找相关信息,从而在保持高准确性的同时减少了对原始文本的依赖。

NarrativeQA 数据集:
NarrativeQA 包含了书籍和电影剧本,文本长度更长,上下文更复杂。这个数据集对模型的理解和推理能力提出了更高的要求。
作者使用 ROUGE 分数和 LLM Ratings 来评估 ReadAgent 的表现。ROUGE 分数衡量了模型生成的文本与参考答案的相似度,而 LLM Ratings 则通过模型自身来评估答案的质量。
在 NarrativeQA 上,不同压缩率和查找策略对 ReadAgent 的表现有显著影响。作者发现,适当的压缩和有效的查找策略可以提高模型在长文本任务中的表现。

QMSum 数据集:
QMSum 由会议记录组成,任务通常是生成摘要而非回答具体问题。这要求模型不仅要理解文本,还要能够提炼关键信息。
与 QuALITY 和 NarrativeQA 不同,QMSum 更注重模型的摘要生成能力。作者通过 ROUGE 分数和 LLM Ratings 来评估 ReadAgent 在生成摘要方面的表现。
实验结果表明,ReadAgent 能够有效地处理长文本,并生成高质量的摘要,同时通过不同的查找策略来优化其表现。

在消融研究中,作者进一步分析了 ReadAgent 不同组件对整体性能的贡献。特别是,他们比较了使用 GistMem 结合神经检索与使用 ReadAgent 查找单页的效果。
研究发现,ReadAgent 的检索策略在准确性上优于传统的 GistMem 结合神经检索方法。这表明 ReadAgent 在处理长文本时,能够更有效地利用压缩后的要点记忆和原始文本,从而提高任务完成的准确性。

ReadAgent 的成功展示了通过模仿人类的阅读和记忆策略,可以显著提升 AI 在处理长文本时的能力。这项工作不仅为长文本理解提供了新的解决方案,也为未来 AI 的发展开辟了新的可能性。
论文链接:https://arxiv.org/abs/2402.09727