过去一周,可谓是小模型战场最疯狂的一周,商业巨头改变赛道,向大模型say byebye~。
OpenAI、Apple、Mistral等“百花齐放”,纷纷带着自家性能优越的轻量化小模型入场。
小模型(SLM),是相对于大语言模型(LLM)而言的,它们一般来说具有较少的参数和较低的计算资源需求。
前OpenAI和特斯拉AI研究员Andrej Karpathy更是直言LLM大小竞争会出现逆转的趋势,预测模型将向着更小更智能的方向发展。

为了快速理解,中文翻译如下:
大语言模型的尺寸竞争正在倒退...
我打赌我们会看到非常非常小的模型“思考”得非常好且可靠。很可能存在一个GPT-2参数的设置,大多数人会认为GPT-2是“聪明的”。当前模型如此大的原因是因为我们在训练期间仍然非常浪费——我们要求它们记住互联网,令人惊讶的是,它们确实做到了,并且可以例如背诵常见数字的SHA哈希值,或回忆非常深奥的事实。(实际上,大语言模型在记忆方面非常出色,质量上远胜于人类,有时只需要一次更新就能记住大量细节,并且长时间记住)。但想象一下,如果你要在闭卷考试中背诵互联网的任意段落,给出前几个词。这是当今模型的标准(预)训练目标。更难的是,因为思考的演示在训练数据中是与知识“纠缠”的。
因此,模型必须先变大,然后才能变小,因为我们需要它们(自动化)的帮助将训练数据重构和模塑成理想的、合成的格式。
这是一个改进的阶梯——一个模型帮助生成下一个模型的训练数据,直到我们获得“完美的训练集”。当你在这个训练集上训练GPT-2时,它将是一个非常强大且聪明的模型,以今天的标准来看。也许MMLU会低一些,因为它不会完美记住所有的化学知识。也许它需要偶尔查找一些东西以确保准确。
GPT-5迟迟没有到来,GPT-4o mini的发布仿佛给大模型的狂飙速度踩了一脚刹车。过去一周,小模型的诞生发布可谓疯狂。
-
7月18日,OpenAI 发布了 GPT-4o mini:在MMLU(文本智能和推理基准测试)中得分为82.0%
-
7月18日,Apple发布了 DCLM 7B :真正的开源,性能碾压 Mistral 7B
-
7月18日,Mistral & Nvidia 发布了 NeMo 12B:性能优于 Llama 3 8B, Gemma 2 9B
-
7月16日,HuggingFace 发布了SmolLM - 135M、360M 和 1.7B:仅使用 650B 个 token 进行训练,击败Qwen 1.5B、Phi 1.5B
-
7月17日,Groq 发布了 Llama 3 8B 和 70B 工具使用和函数调用模型:在 Berkely 函数调用排行榜 (BFCL) 上实现了 90.76% 的准确率
-
7月19日,Salesforce 发布了 xLAM 1.35B 和 7B 大型动作模型:7B 模型在 BFCL 上的得分为 88.24%, 2B为78.94%
让我们一起看看这些小模型各自都有什么特点?性能如何?
OpenAI 发布 GPT-4o mini,主打实惠
当地时间 7 月 18 号,OpenAI 正式发布了 GPT-4o Mini。OpenAI称,GPT-4o mini是OpenAI最智能和最实惠的小模型。

GPT-4o Mini主打的就是一个经济实惠,甚至比曾被认为OpenAI最轻量级且高性价比的GPT-3.5 Turbo还要便宜60%以上。
不仅便宜,GPT-4o Mini性能也十分优越。
在MMLU(文本和推理能力)测试中,GPT-4o mini能拿到82%的得分。
在LMSYS(指聊天机器人对战)排行榜上还超过GPT-4。
不仅如此,GPT-4o mini在数学和编码任务、多模态推理任务方面,也都超过了GPT-3.5 Turbo和其他小型模型。
Apple发布DCLM,数据、模型权重、训练代码全开源!
苹果公司的人工智能团队和华盛顿大学等多家机构合作,推出一款名叫 DCLM的开源语言模型。
DCLM包含两种参数规模--70亿和14亿。其中70亿参数基础模型,在开放数据集上使用2.5T tokens进行训练,拥有2048tokens上下文窗口。
众所周知,优质的数据集在模型训练过程必不可少,而数据集的获取却并不容易,需要过滤到无关和有害的数据,并且去除重复信息。
针对数据集获取的挑战,苹果研究团队提出了DataComp for Language Models(简称 DCLM),用于语言模型的数据集优化。
其使用一个标准化的框架来进行实验,包括固定的模型架构、训练代码、超参数和评估,最终找出哪种数据整理策略最适合训练出高性能的模型。
基于上述思路,团队构建了一个高质量数据集DCLM-BASELINE,并用它从头训练了一个7B参数模型——DCLM-7B。
该模型性能已经超越了 Mistral-7B,并且正在逼近其他领先的开源模型,包括 Llama 3 和 Gemma。
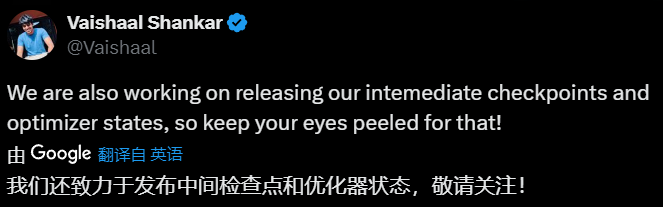
苹果ML小组研究科学家Vaishaal Shankar表示:这是迄今为止表现最好的真正开源大模型,做到了数据、模型权重、训练代码全开源!

同时Vaishaal Shankar还补充道:苹果后续还会发布模型的中间检查点和优化器状态。
谁听了不道一声赞,堪称开源界的模范标杆。

模型:
https://huggingface.co/apple/DCLM-7B
数据集:
https://huggingface.co/datasets/mlfoundations/dclm-baseline-1.0
仓库:
https://github.com/mlfoundations/dclm
Mistral&Nvidia 发布NeMo 12B,企业级人工智能!
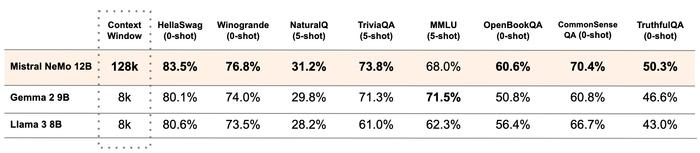
英伟达和法国初创公司 Mistral AI联手发布Mistral-NeMo AI大语言模型,其拥有 120 亿个参数,上下文窗口(AI 模型一次能够处理的最大 Token 数量)为 12.8 万个 token。

Mistral-NeMo AI 大模型主要面向企业环境,旨在让企业不需要使用大量云资源的情况下,实施人工智能解决方案。
Mistral NeMo,根据Apache 2.0许可证发布,允许商业使用,任何人皆可下载使用。开发人员可以轻松定制和部署支持聊天机器人、多语言任务、编码和摘要的企业应用程序。
与同等参数规模模型相比,它的推理、世界知识和编码准确性都处于领先地位。
在与Gemma 2 9B和Llama 3 8B的多项对比中,Mistral NeMo在多项基准测试中表现优异。
链接:
https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407 https://huggingface.co/mistralai/Mistral-Nemo-Base-2407
HuggingFace 发布SmolLM - 135M、360M 和 1.7B,可在手机运行!
SmolLM系列专为移动设备上运行设计,意味着一部手机就可以运行!且不会影响到设备端性能与用户隐私。其具有三种规模,分别是1.35亿、3.6亿和17亿个参数,目的是为了适应各种计算资源。

Hugging Face在训练这些模型时,精心构造了一个叫做SmolLM-Corpus的优质数据集,这个数据集包含了丰富的教育和合成数据,确保模型能够学习到各种知识。
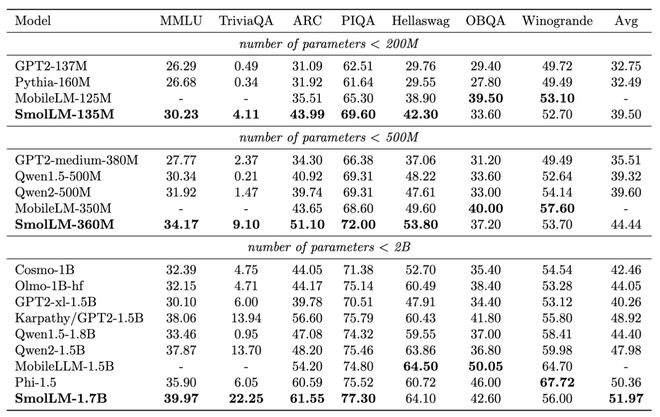
尽管占用空间小,但这些模型在测试常识推理和世界知识的基准测试中表现出了优异的成绩。
最小的模型SmolLM-135M在训练的标记数量更少的情况下,性能超过了Meta的MobileLM-125M。SmolLM-360M超越了所有5亿参数以下的模型,包括Meta和Qwen的产品。SmolLM-1.7B在多项基准测试中击败了微软的Phi-1.5、Meta的MobileLM-1.5B和Qwen2-1.5B。
Hugging Face将整个开发过程开源,从数据管理到训练步骤。这种透明度符合该公司对开源价值观和可重复研究的承诺。
产品入口:
https://top.aibase.com/tool/smollm
模型:
https://huggingface.co/blog/smollm
Groq发布Llama3函数调用专用模型,BFCL排名第一
Grop发布了一款专为工具使用设计的新开源模型--Llama3函数调用专用模型,其具有两种规模,分别是8B和70B,均是基于Llama 3开发。

模型是Groq与 Glaive 合作开发的,代表了开源 AI 在工具使用/函数调用能力方面的重要进步。
大家可以通过Groq API以1050 tok/s的超快速度获取 8B 模型和330 tok/s的70B模型,也可以从Hugging Face下载开源权重,进行自定义训练。
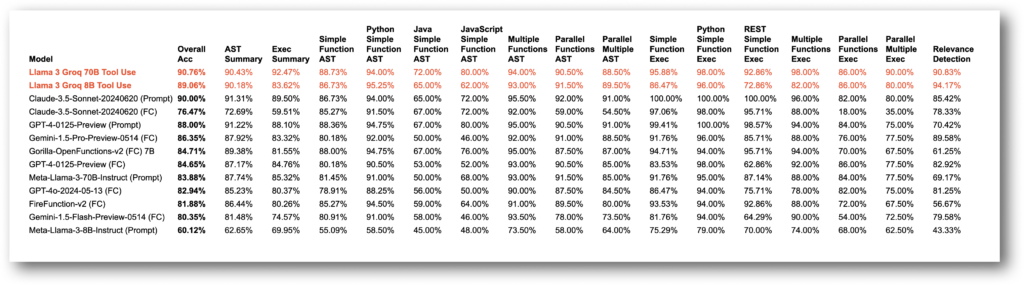
Llama-3-Groq-70B-Tool-Use模型在伯克利函数调用排行榜(BFCL)上排名第一,总体准确率为 90.76%,优于所有其他开源和专有模型,击败了包括 Claude Sonnet 3.5、GPT-4 Turbo、GPT-4o 和 Gemini 1.5 Pro 在内的所有模型。
模型:
https://huggingface.co/Groq/Llama-3-Groq-70B-Tool-Use
https://huggingface.co/Groq/Llama-3-Groq-8B-Tool-Use
Salesforce 发布xLAM,自主计划并执行任务以实现特定目标!
大型动作模型 (LAMs) 是先进的大型语言模型,旨在增强决策能力并将用户意图转化为可执行的操作,与现实世界进行交互。
Salesforce提供了一系列不同规模的 xLAMs,以满足各种应用需求,包括那些优化用于函数调用和通用代理应用的模型:fc 系列模型针对函数调用能力进行了优化,能够根据输入查询和可用的 API 提供快速、准确和结构化的响应。

本次发布的xLAM fc系列包含两种参数规模--13.5亿和70亿。
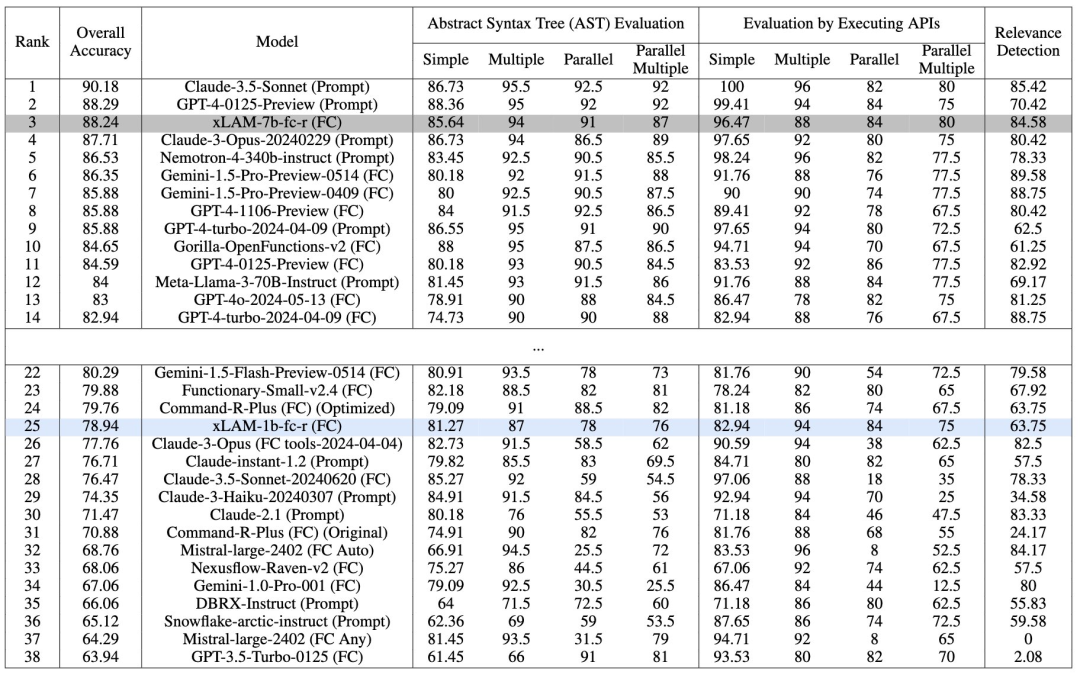
在 BFCL(函数调用排行榜)上与 GPT4 和 Claude 3.5 竞争击败几乎所有开放访问模型(command r plus、Mixtral 8x22B等)。
7B 得分为 88.24%,而2B在 BFCL 上的得分为 78.94%
Salesforce在Hugging Face上开源了模型和 DeepSeek 编码器生成的数据集。
模型:
https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4
数据集:
https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k
AI未来:向多元化方向发展
虽然小模型在效率方面具有其独特的优势,但由于参数量限制,它们在许多的任务上的处理能力可能无法与大语言模型匹敌。
各种规模的模型都有其优势和劣势所在,在未来的AI发展格局中,无论是大模型还是小模型,少了谁都不行。关键在于找到模型规模、性能和具体应用要求之间的平衡,才能发挥其最大价值。












![[网络通信原理]——TCP/IP模型—网络层](https://i-blog.csdnimg.cn/direct/9cde917539814956bd372988ffc0c2b8.png#pic_center)