目前,爬虫已经成为互联网数据获取最主流的方式。但为了保证爬虫顺利采集数据,需要防范网站的反爬虫机制,降低IP被限制的风险,这样才能提高爬虫工作的效率。那么,如何防止网络爬虫被限制呢?下面介绍几种有效的方法:

1. 高度纯净的代理
高匿名纯净代理是代理IP中较为高质量的类型,可以完全隐藏用户的真实IP地址,伪装成其他IP地址进行访问,使得目标网站服务器无法检测到你正在使用代理IP,有效避免被反爬虫机制识别和限制的风险。
选择高匿名代理相较于其他类型的代理IP地址具有明显的优势。其他类型的代理IP可能在请求头中带有识别信息,例如“proxy-authorization”字段,或包含“proxy-connection”等HTTP头字段,这些字段可能会被网站服务器检测到,从而暴露真实IP地址。而纯净度高、高匿名代理不包含此类识别信息,使请求看起来更像普通用户的请求,从而提高了代理的隐蔽性和安全性。

虽然说现在非常多IP池子已经被滥用,但也不乏优质的资源,IPFoxy的动态代理池子达5000万,且用下来成功率比较高,这样爬虫可以更稳定地访问目标网站,避免被网站限制或屏蔽的情况。
这对于长期稳定的数据采集至关重要。如果爬虫使用普通代理或未优化的代理,很容易被网站检测到并限制访问,导致数据采集任务失败或效率低下。
选择代理也至关重要,好的代理服务商通常会提供稳定可靠的代理IP地址,避免代理IP频繁更换或失效,还可以提高爬虫的效率和数据获取的质量。
2.多线程收集
在大量数据采集任务中,采用多线程并发采集可以有效地同时执行多个任务,每个线程负责采集不同的内容,从而大大提高数据采集的速度和效率。
通过多线程并发采集,爬虫可以充分利用计算机的多核处理能力,将不同的任务分配给不同的线程进行处理。这样,不同的线程可以同时运行,数据采集和处理可以同时进行,而不必逐个等待完成,大大减少了采集任务的总时间。特别是在处理大规模数据时,多线程采集可以显著提高爬虫的效率,缩短数据采集周期。
多线程采集除了可以提高效率之外,还可以降低爬虫被目标网站限制访问或封杀的风险。在数据采集过程中,爬虫会频繁向目标网站发送请求,这可能会对目标网站服务器造成一定的负担,尤其是采集频率过高时。如果采用单线程采集,其访问频率相对较高,网站很容易察觉到异常行为并采取反爬取措施。而多线程采集可以将访问频率分散到多个线程中,减少单个线程的访问频率,减少目标网站的压力,从而降低被限制访问的概率。

3、时间间隔访问
合理设置时间间隔非常重要,在采集任务中,首先要知道目标网站允许的最大访问频率,接近或达到最大访问频率可能会导致IP被限制,从而无法继续采集数据。因此,需要设置合理的间隔,高效采集的同时避免堵塞公开数据的访问。
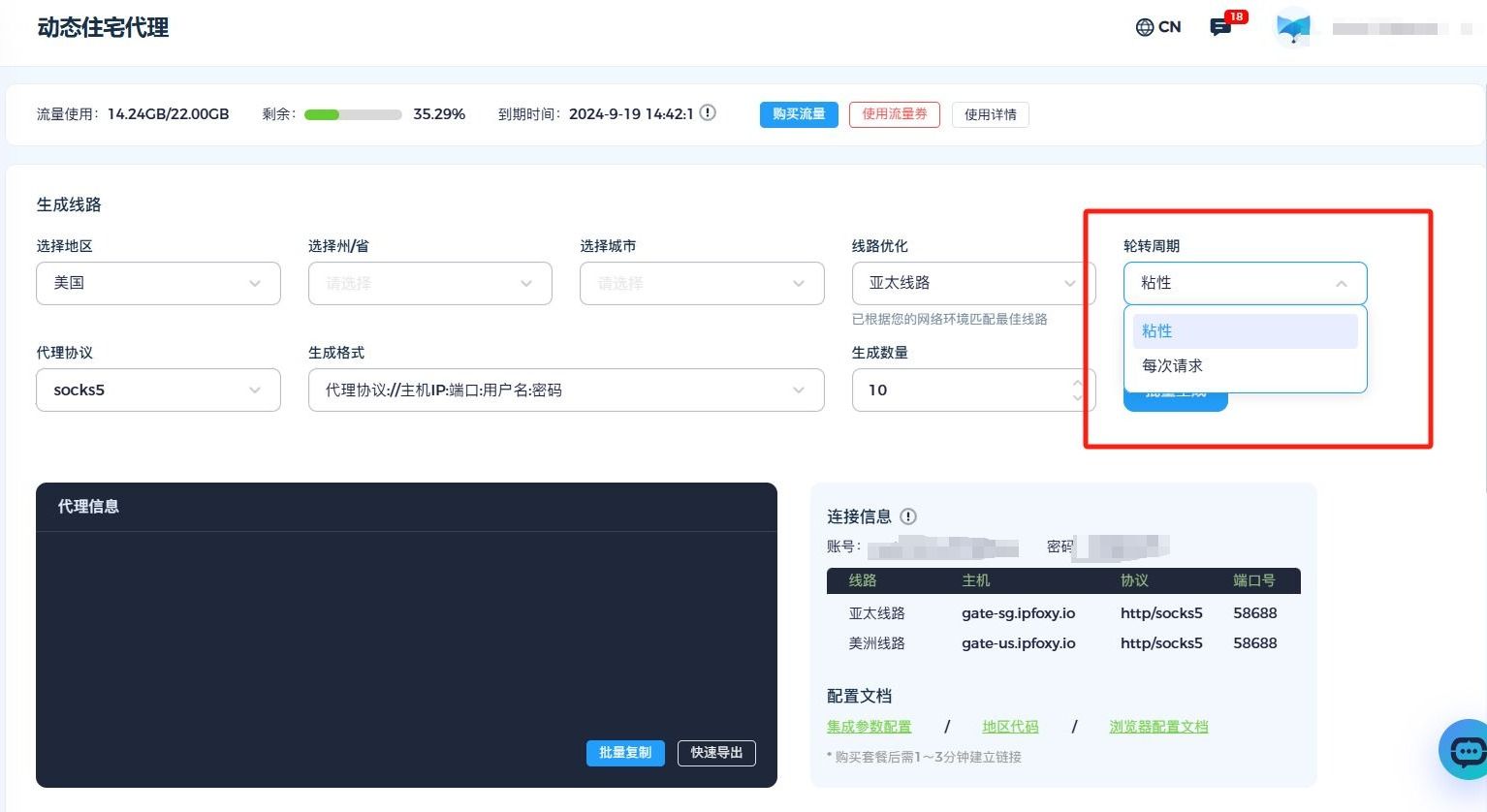
比如这个IP池子有两种轮换间隔的选择。
- 粘性:生成的每条代理信息都不一样,IP每隔10~30分钟自动更换
- 每次请求:生成的每条代理信息都一样,浏览器每次完成请求后会自动更换ip
根据自己的请求需求去选择合适的轮换周期,可以让代理轮换间隔在实际业务中保持在合理的范围内不易收到检测。
综上所述,保护网络爬虫不被限制的方法主要有使用高匿名代理、使用多线程并发采集提高效率、设置合理的时间间隔规避被限制的风险等。通过这些方法的合理运用,可以使爬虫更加顺利的获取到需要的数据,同时降低被网站限制的可能性,保证爬虫的稳定运行。