1.在本机的/root目录下,依次创建文件夹data,文本文件word.txt.
mkdir -p /root/data
vim /root/data/word.txt键入i,进入编辑模式,输入如下内容:
hello world
hadoop hdfs
qingjiao hadoop hongya
hdfs qingjiao
qingjiao
hadoop hongya键入Esc,退出编辑模式,输入:wq保存退出。
终端中执行HDFS shell命令。
# 创建目录
hadoop fs -mkdir -p /wordcount/input
# 上传数据文件:
hadoop fs -put /root/data/word.txt /wordcount/input进入$HADOOP_HOME/share/hadoop/mapreduce/目录下,使用ls指令查看文件夹内容.
cd $HADOOP_HOME/share/hadoop/mapreduce/
ll在该文件夹下自带了很多Hadoop的MapReduce示例程序。其中,hadoop-mapreduce-examples-2.7.7.jar包中包含了计算单词个数、计算PI值等功能的程序。
1.使用hadoop-mapreduce-examples-2.7.7.jar示例包,对HDFS上的word.txt文件进行单词统计,在jar包位置执行如下命令:
hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /wordcount/input/word.txt /wordcount/output指令参考:
- hadoop jar hadoop-mapreduce-examples-2.7.7.jar :表示执行一个Hadoop的jar包程序;
- wordcount:表示执行jar包程序中的单词统计功能;
/wordcount/input/word.txt:表示进行单词统计的HDFS文件路径; - /wordcount/output:表示进行单词统计后的输出HDFS结果路径。
1.执行完上述指令后,示例包中的MapReduce程序开始执行,效果图如下所示:

因为MapReduce程序分为Map端和Reduce端,当Map端和Reduce端都执行到100%,并显示job completed successfully时,才代表程序执行成功。
1.因为MapReduce程序是运行在YARN之上的,所以我们同样可以通过YARN集群的Web UI界面查看运行状态,在本机的浏览器上访问http://localhost:8088或http://本机IP地址:8088。效果图如下所示:

1.在“单词统计”示例程序执行成功后,再次刷新并查看HDFS的Web UI界面,效果如下图所示:

从上图可以看出,MapReduce程序执行成功后,在HDFS上自动创建了指定的输出目录/wordcount/output,并且输出了 _SUCCESS 和 part-r-00000 结果文件。
其中,_SUCCESS文件用于表示此次任务成功执行的标识,而part-r-00000表示单词统计的结果。
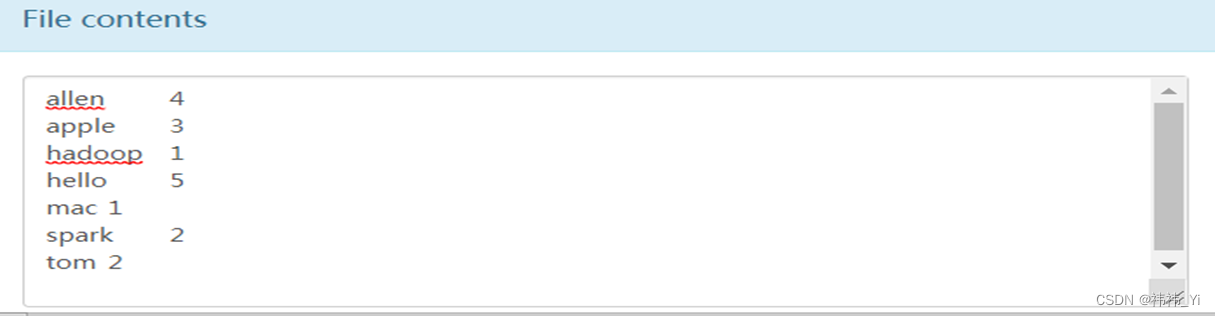
1.使用HDFS Shell的相关指令查看part-r-00000的内容,具体指令如下所示:
hadoop fs -cat /wordcount/output/part-r-00000效果图如下:

从上图可以看出,MapReduce示例程序成功统计出了/wordcount/input/word.txt文本中的单词数量,并进行了结果输出。



![[云炬python3玩转机器学习] 5-7,8 多元线性回归正规解及其实现](https://img-blog.csdnimg.cn/941dfb450a524488a8da6f8a78d05b50.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eR5aSn5LqR54Ks,size_20,color_FFFFFF,t_70,g_se,x_16)