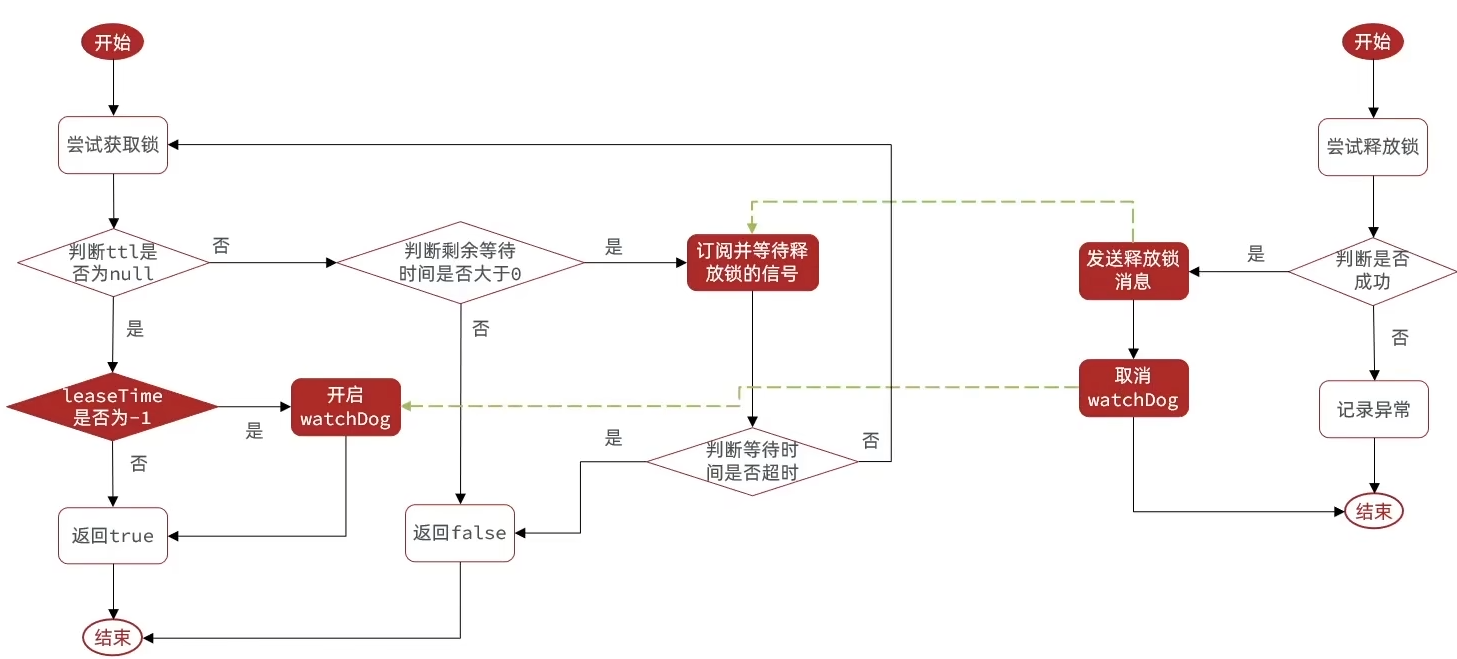
前言
随着互联网信息的爆炸性增长,如何高效地获取和处理这些数据变得越来越重要。Web爬虫作为一种自动化工具,可以帮助我们快速抓取所需的网页内容。本文将介绍如何使用Python编写一个简单的Web爬虫,并通过实例演示其基本用法。

准备工作
- Python环境:确保你的计算机上已经安装了Python 3.x版本。
- 依赖库安装:我们将使用
requests来发送HTTP请求,使用BeautifulSoup来解析HTML文档。可以通过pip安装这两个库:pip install requests beautifulsoup4
示例代码
假设我们要从一个简单的网站中抓取所有链接。以下是一个基本的Python脚本示例:
import requests
from bs4 import BeautifulSoupdef get_links(url):# 发送GET请求response = requests.get(url)# 检查请求是否成功if response.status_code == 200:# 解析HTMLsoup = BeautifulSoup(response.text, 'html.parser')# 查找所有的<a>标签links = [a['href'] for a in soup.find_all('a', href=True)]return linkselse:print("Failed to retrieve the webpage")return []if __name__ == "__main__":url = "http://example.com" # 替换为你想要爬取的网址links = get_links(url)print(links)
步骤解释
- 导入库:首先我们需要导入必要的库。
- 定义函数:
get_links函数接收一个URL作为参数,并返回该页面中的所有链接。 - 发送请求:使用
requests.get()发送GET请求到指定URL。 - 解析HTML:使用
BeautifulSoup解析返回的HTML文档。 - 提取链接:遍历所有的
<a>标签并获取href属性值。 - 打印结果:最后输出所有找到的链接。
注意事项
- 在实际开发过程中,请遵守目标网站的robots.txt文件规则,尊重网站的爬虫政策。
- 处理大规模数据时,考虑使用更高级的技术如异步IO、分布式爬虫等提高效率。
- 对于动态加载的内容,可能需要使用像Selenium这样的工具来模拟浏览器行为。
结语
通过本文,你已经学会了如何使用Python编写一个基础的Web爬虫。这只是冰山一角,随着经验的增长,你可以尝试更复杂的项目。希望这篇文章对你有所帮助!