对于大规模的有限元计算,系统的整体刚度矩阵是非常耗费内存的,以百万自由度为例,刚度矩阵K的大小为100万x100万,元素大小为双精度double,占用8 byte,那么K占用的内存为100万x100万x8 byte = 8000G,这无疑是一个天量内存,好在刚度矩阵一般是稀疏矩阵,我们可以充分利用稀疏矩阵的特性来降低空间复杂度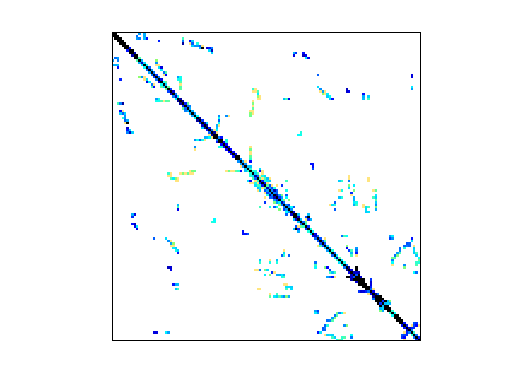
稀疏矩阵的优势
存储效率:
- 稀疏矩阵存储方式只记录非零元素及其位置,大大减少了内存消耗。例如,使用压缩稀疏行(CSR)或压缩稀疏列(CSC)格式,可以有效地存储和操作大型稀疏矩阵。
计算效率:
- 稀疏矩阵运算,如矩阵乘法、求解线性系统等,仅对非零元素进行操作,减少了计算量。使用稀疏矩阵求解器(如迭代法)可以显著提高求解大型线性系统的效率。
稀疏矩阵的常用存储格式
稀疏矩阵有很多存储格式,这些格式的核心思想是只存储非零元素,
coo_matrix
coo_matrix(coordinate list matrix)是最简单的稀疏矩阵存储方式,采用三元组(row, col, data)的形式来存储矩阵中非零元素的信息。在实际使用中,一般coo_matrix用来创建矩阵,因为coo_matrix无法对矩阵的元素进行增删改操作;创建成功之后可以转化成其他格式的稀疏矩阵(如csr_matrix、csc_matrix)进行转置、矩阵乘法等操作。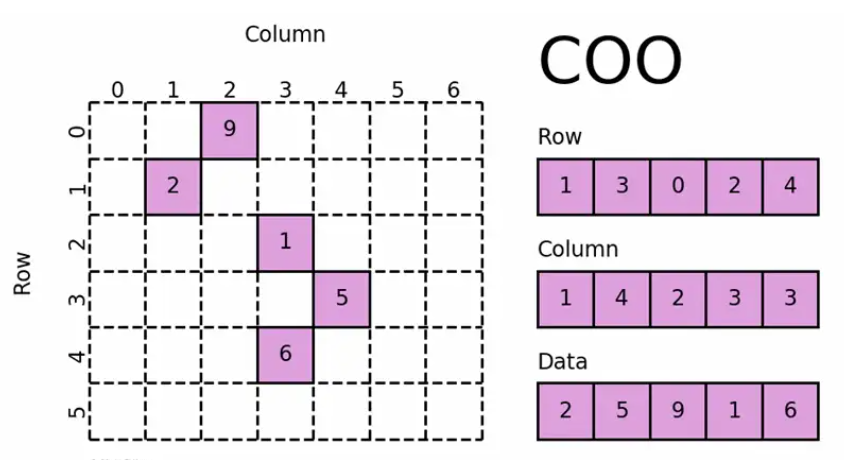
coo_matrix的优点:
· 有利于稀疏格式之间的快速转换(tobsr()、tocsr()、to_csc()、to_dia()、to_dok()、to_lil())
· 允许又重复项(格式转换的时候自动相加)
· 能与CSR / CSC格式的快速转换
coo_matrix的缺点:
· 不能直接进行算术运算
csr_matrix
上面的coo格式是否还能优化呢,我们注意到,每行都有很多元素,如下面数组,行索引row indices为[1,1,2,4,4,4,6]这里面其实是很多重复元素的,我们可以将其压缩,只需要记录重复元素的个数就可以。
csr_matrix,全称Compressed Sparse Row matrix,即按行压缩的稀疏矩阵存储方式,由三个一维数组indptr, indices, data组成。indptr存储之前行中非零值的累积计数,indices是按行顺序存储每行中数据的列号,与data中的元素一一对应。这种格式要求矩阵元按行顺序存储,每一行中的元素可以乱序存储。indptr存储的其实是每行元素个数数组的前缀和数组,这样我们就很容易知道每行有多少个元素,对于Data中的第i个数,我们可以根据indptr很容易得到他属于哪一行,然后配合列指标indices,就可以将Data和原来的行列对应起来。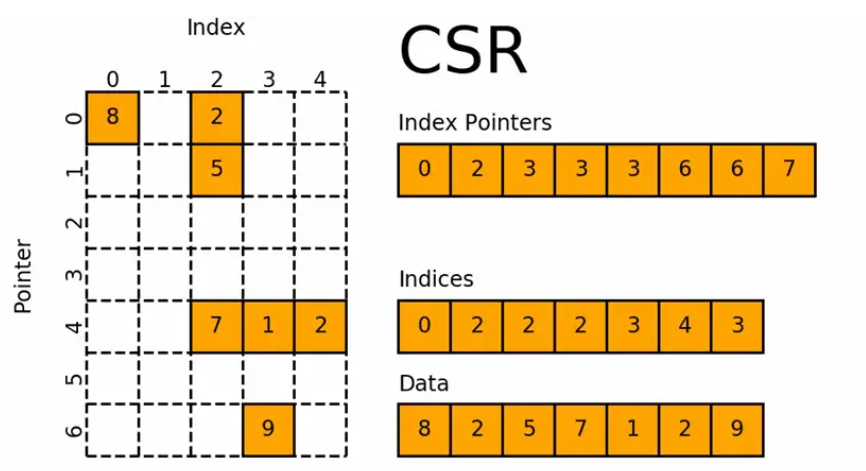
csc_matrix
csc_matrix和csr_matrix正好相反,即按列压缩的稀疏矩阵存储方式,同样由三个一维数组indptr, indices, data组成,如下图所示: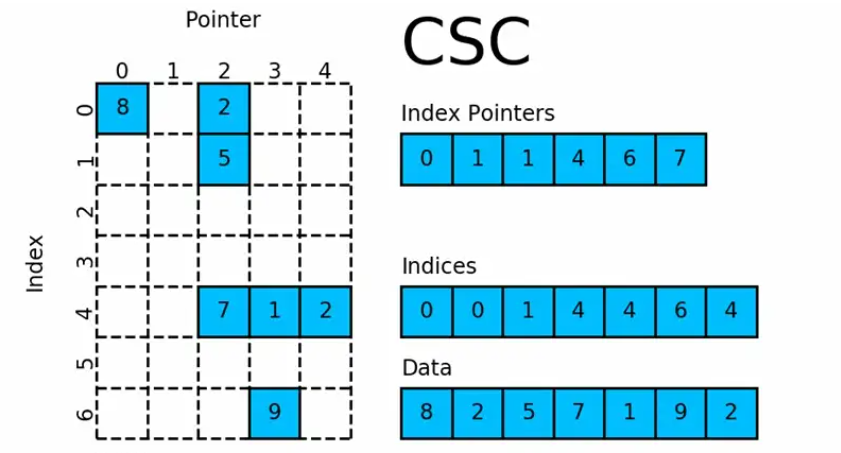
lil_matrix
lil_matrix,即List of Lists format,又称为Row-based linked list sparse matrix。它使用两个嵌套列表存储稀疏矩阵:data保存每行中的非零元素的值,rows保存每行非零元素所在的列号(列号是顺序排序的)。这种格式很适合逐个添加元素,并且能快速获取行相关的数据。其初始化方式同coo_matrix初始化的前三种方式:通过密集矩阵构建、通过其他矩阵转化以及构建一个一定shape的空矩阵。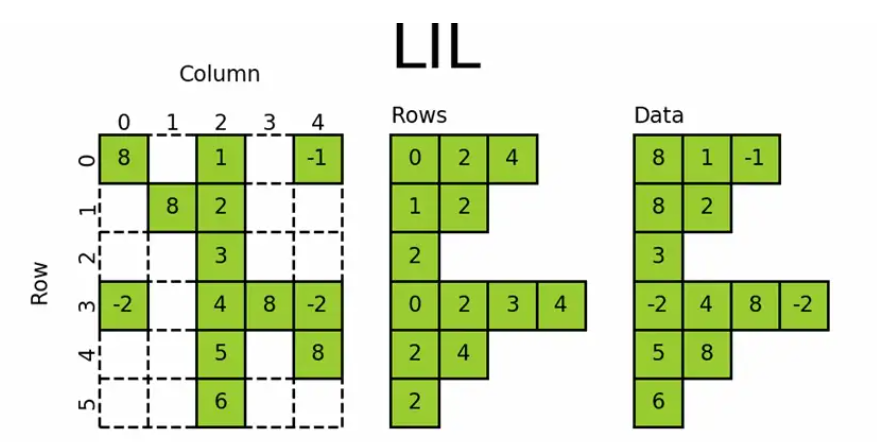
dok_matrix
dok_matrix,即Dictionary Of Keys based sparse matrix,是一种类似于coo matrix但又基于字典的稀疏矩阵存储方式,key由非零元素的的坐标值tuple(row, column)组成,value则代表数据值。dok matrix非常适合于增量构建稀疏矩阵,并一旦构建,就可以快速地转换为coo_matrix。
dia_matrix
dia_matrix,全称Sparse matrix with DIAgonal storage,是一种对角线的存储方式。如下图中,将稀疏矩阵使用offsets和data两个矩阵来表示。offsets表示data中每一行数据在原始稀疏矩阵中的对角线位置k(k>0, 对角线往右上角移动;k<0, 对角线往左下方移动;k=0,主对角线)。该格式的稀疏矩阵可用于算术运算:它们支持加法,减法,乘法,除法和矩阵幂。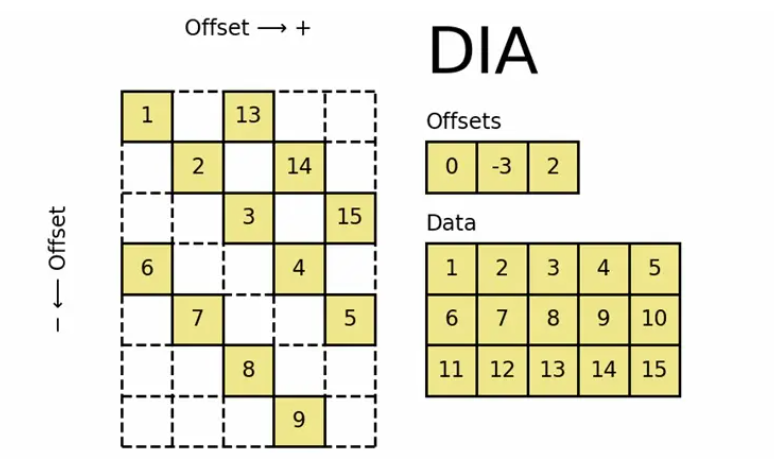
有限元法中的稀疏矩阵
有限元刚度矩阵为何是稀疏的
局部性原理:
- 在有限元法中,整体结构或域被划分成许多小的、互不相交的有限单元。每个有限单元仅与其相邻单元通过共享节点(顶点)相互作用。因此,刚度矩阵的每一行和每一列对应的节点只与其相邻的节点相互作用。远离该节点的节点不会直接影响它,从而导致矩阵中大部分元素为零。
节点的有限连接:
- 每个节点只与少数几个相邻节点相连。这意味着每个节点对应的刚度矩阵行(或列)只有少数几个非零元素,对应这些相邻节点的贡献。这种局部相互作用导致了刚度矩阵的稀疏性。
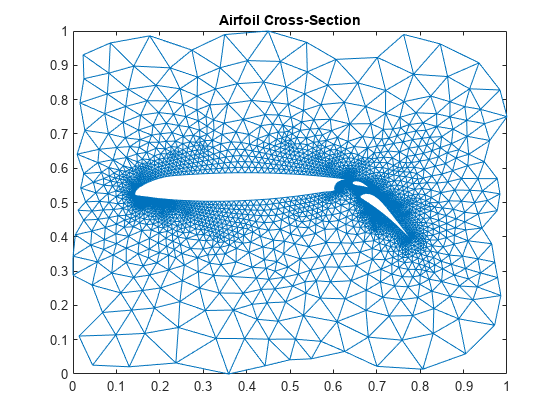
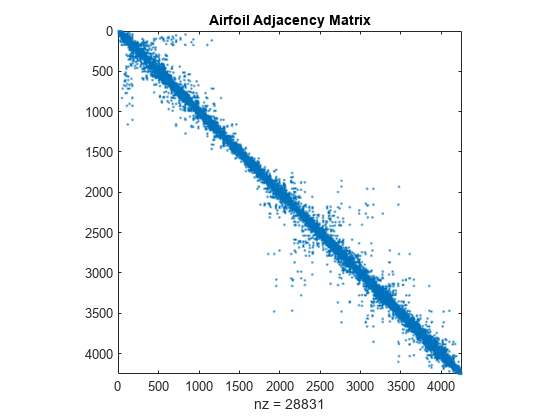
上年图片实例来自:[Graphical Representation of Sparse Matrices - MATLAB & Simulink Example (mathworks.com)]
刚度矩阵带宽估计
假设我们有一个三维问题,它的离散化通常会产生一个对称稀疏矩阵 A A A。在这个矩阵中,只有靠近主对角线的元素是非零的。矩阵 A A A 的半带宽 B W BW BW 定义为:
B W = max i , j { ∣ i − j ∣ ∣ a i j ≠ 0 } BW = \max_{i,j} \{ |i - j| \ | \ a_{ij} \neq 0 \} BW=maxi,j{∣i−j∣ ∣ aij=0}
即矩阵中所有非零元素的行索引和列索引之差的最大值,也是非零元素到所在行的对角元素之间距离的最大值。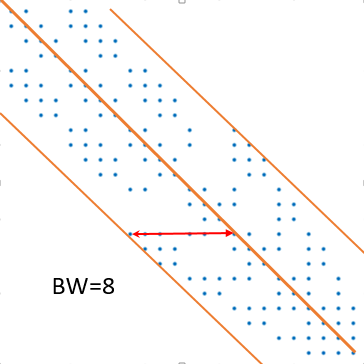
三维问题的带宽估计
对于三维问题,通常会在网格上离散化,例如 n × n × n n \times n \times n n×n×n 的网格。假设我们使用有限差分法离散化,得到的稀疏矩阵 A A A 的非零元素主要分布在主对角线附近。
对于三维问题,我们可以设想每个点与其在 x x x、 y y y 和 z z z 方向上的相邻点相连。每个点在三维网格中的索引可以表示为 ( i , j , k ) (i, j, k) (i,j,k),其中 i , j , k i, j, k i,j,k 是点在 x x x、 y y y 和 z z z 方向上的坐标。将这些坐标展平到一个一维数组中,点 ( i , j , k ) (i, j, k) (i,j,k) 的索引可以表示为:
i d x = i + j ⋅ n + k ⋅ n 2 idx = i + j \cdot n + k \cdot n^2 idx=i+j⋅n+k⋅n2
在这种情况下,如果我们考虑点 ( i , j , k ) (i, j, k) (i,j,k) 与其相邻点的关系,其非零元素的索引差值为:
∣ i d x − i d x neighbor ∣ |idx - idx_{\text{neighbor}}| ∣idx−idxneighbor∣
索引差值最大为 n 2 n^2 n2,因此带宽 BH为 n 2 n^2 n2
SkyLine存储格式
有限元的刚度矩阵,一般情况下,不仅稀疏,而且对称,对称意味着数据可以只存一半,有限元中有一种常用的稀疏矩阵存储格式SkyLine存储格式
- 一个数组A用于存储所有列从对角线到最后一个非零元素
- 一个索引数组,存储每一个对角线元素在value中的索引
A(i,j) i<= j 的值如何计算? 先找到 j列有几个非零值 num_val = index[j+1] - index[j]
如果 j-i < num_val ,则 为0 ,否则在A数组的索引为index[j] - (j-i)
Skyline存储格式可以看做是CSC的特例,由于非零元素对称的分布在对角元素附近,所以只需要存储每列有多少个元素,而每个元素的行索引,可以直接根据离对角元素的距离计算出,而不用单独的行索引数组。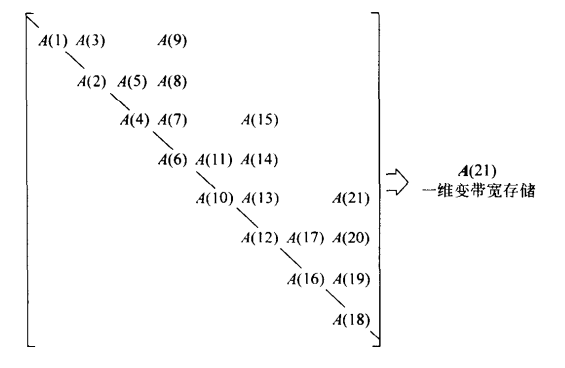
i n d e x = [ 1 、 2 、 4 、 6 、 10 、 12 、 16 、 18 、 22 ] index = [1 、 2 、 4 、 6 、10 、 12 、 16、 18、 22] index=[1、2、4、6、10、12、16、18、22]
如何在组装前知道稀疏矩阵的结构?需要遍历单元,找到每一个单元对应的自由度里面的最小的非零行,例如单元对应的刚度举证项为k[i,j], 则第j列的 第i个值非0.
有限元刚度阵带宽优化
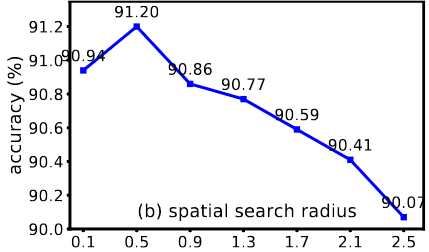
由上面可知,稀疏矩阵的带宽由单元自由度最大差值决定,而单元自由度一般根据节点编号进行编号,因而我们可以通过优化节点编号的方式来降低刚度矩阵的带宽,这是一个经典的图论问题,节点可以看做是图上的节点,节点之间的连接可以看作是图的边,现在要求两个相连的节点的最大差值最小。
网格的图表示法
在有限元分析中的矩阵一般都是稀疏的,即刚度矩阵中非零元的数目要远小于零元素的数目,如果将结点和结点的连接关系抽象为一张图,那么刚度矩阵本质上就是这张图的邻接矩阵表示。如果元素 K i j > 0 K_{ij} >0 Kij>0, 说明自由度i和j是相邻顶点, K i j K_{ij} Kij的值可以看做是边的权重。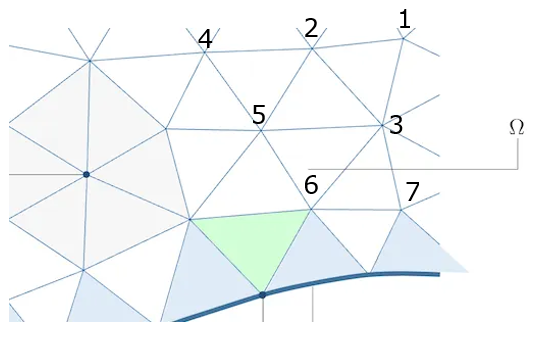
用一个二维数组A存放图G各顶点间的相邻关系,称这个二维数组为图G的邻接矩阵(Adjacency Matrix)。图G与它的邻接矩阵A呈一、一对应关系。设图G的邻接矩阵为 A = a i j A=a_{ij} A=aij,图中某两顶点 v i v_i vi和 v j v_j vj相邻,则对应于矩阵A中元素 a i j = 1 a_{ij}=1 aij=1,否则 a i j = 0 a_{ij}=0 aij=0。如果矩阵A是对称矩阵,则图G是一个无向图。此时矩阵的带宽可以表示为:
B H = max { ∣ f ( ν 1 ) − f ( ν 2 ) ∣ : { v 1 , v 2 } ∈ E ( G ) } BH=\max\left\{\left|f(\nu_{1})-f(\nu_{2})\right|:\{v_{1},v_{2}\}\in E(G)\right\} BH=max{∣f(ν1)−f(ν2)∣:{v1,v2}∈E(G)}
CM和RCM重排算法
CM算法最初由Cuthill和Mckee在1969年首先提出,用于稀疏矩阵的重排序以减小矩阵带宽。George完善改进了CM算法得到RCM(Reverse Cuthill-Mckee)算法。RCM算法和CM算法基本相同,只不过把CM排序数组逆序排列。
网格图的BFG层级结构
对于网格结构组成的图,选择一个给定顶点 V V V为根顶点 r r r,从根顶点出发,进行BFS遍历,将每层记录为 L 1 , L 2 … … L m L_1,L_2……L_m L1,L2……Lm,形成图_G_的层级结构 L L L,各层中顶点的数目被定义为该层的宽 W i W_i Wi,层级结构 L L L总的宽度 W ( L ) = m a x W i W(L)= max { W_i} W(L)=maxWi。我们可以知道, L m − 1 L_{m-1} Lm−1和 L m L_{m} Lm层之间相互连接的节点最大编号差不大于 L m − 1 L_{m-1} Lm−1和 L m L_{m} Lm层节点数之和。如果按照层级顺序由根顶点始按从小到大顺序对各个顶点依次分配新节点编号,那么由此构造的新矩阵带宽 B H BH BH与层级结构的宽度 W ( L ) W(L) W(L)有如下关系:
B H < = 2 W ( L ) BH <= 2W(L) BH<=2W(L)
降低矩阵的带宽和轮廓的问题可被转化为降低以矩阵所生成的层级结构 L L L的宽度问题。
RCM算法
RCM算法基于无向图的BFS算法,以生成最长层次结构为目标,具体实现方法:
- (1)生成矩阵_A_的无向图_G_(A),找出_G_中度最小的顶点,并分别以这些顶点为根顶点生成各自的层级结构,找出各层级结构中宽度最小的层级结构。
- (2)按层的递增顺序分配新的编号:
- 根顶点分配为1
- 由第二层开始,将每一层中顶点的各个顶点按照度从小到大排列并分配编号
- 重复(2)中的步骤,直至所有顶点均被分配到新的编号,按照新的编号生成CM排序数组。
- (3)对于步骤2中生成的各个CM排序数组,计算新得到的矩阵的带宽,保留带宽最小的CM排序数组;
- (4)将CM排序数组反转,得到RCM排序数组。
下图为前文机翼结构网格邻接矩阵在经过RCM重排序后的优化效果,可以看到,优化效果比较显著。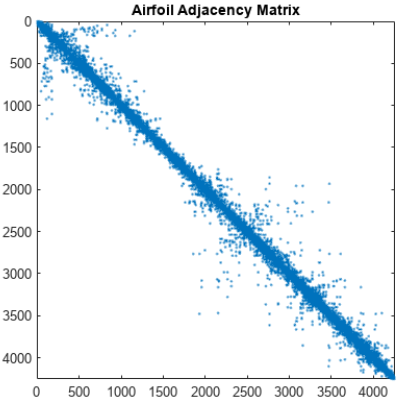
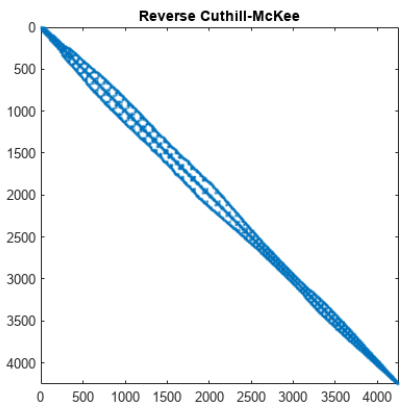
有限元刚度矩阵内存规模估计
有了前面的知识,现在我们可以对有限元刚度矩阵的内存规模进行大致的估计了,对于一个具有 N N N个自由度规模的问题,刚度矩阵的大小为 N 2 N^2 N2, 如果 采用重排序优化,可以大大减小稀疏矩阵带宽,我们考虑一个100万自由度问题,内存占用约为100万8BH(Byte) = 8 * BH(M),假设x,y,x三个方向网格数量比较均匀,则三个方向自由度为100100100,BH约等于10000,则内存占用约为80G, 如果进一步能够降低BH到100, 则内存占用为0.8G,我们可以参考下图中的数据,对于传热问题,每百万自由度占用的内存约为1.25G。对于不同类型的物理场问题,相同规模自由度占用的内存差异较大。
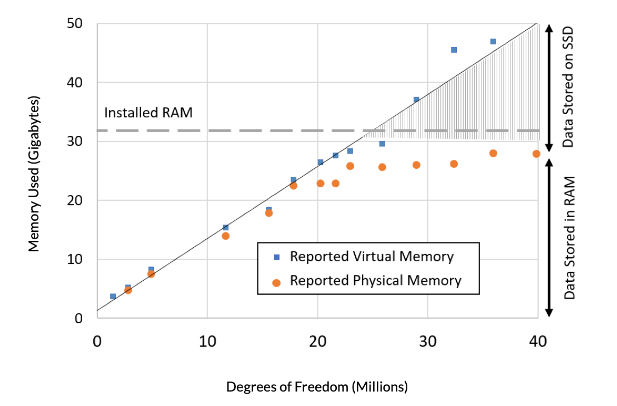
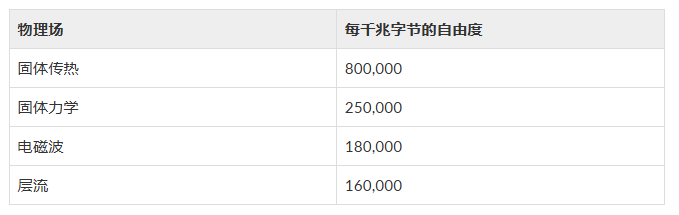
上图引自:[ 求解大型 COMSOL 模型需要多少内存? | COMSOL 博客]