1. 前言
数据可视化能够将复杂的数据集转化为易于理解的图形、图表或图像。这种直观的表现形式使得人们能够更快地理解数据的分布、趋势、异常值以及数据之间的关系,从而更深入地洞察数据背后的信息。
数据可视化在数据分析和决策制定过程中具有不可替代的作用。它不仅能够帮助人们更好地理解数据、识别模式和趋势、增强沟通效果,还能够辅助决策制定、提升数据质量、激发创新思维和提高工作效率。因此,掌握数据可视化技能对于数据分析师、数据科学家以及任何需要处理和分析数据的人员来说都至关重要。
2. 基础作图
2.1 折线图
在使用python进行可视化操作最离不开的就是我们的matplotlib库
import matplotlib.pyplot as plt
在这个库中有着多种工具帮助我们对数据作出相应的绘图。
#可视化matplotlib
import matplotlib.pyplot as plt
train = pd.DataFrame({'code':[1,2,3,4,5],'price':[222,333,444,555,666]})
train.plot()
plt.plot(train)自定义一个数据集train,包含code与price,让我们对此简单的作一个图。
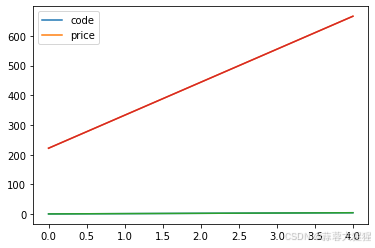
直接选用train数据集作图我们可以看出系统自动画了两条折线,plot会默认样本数量为x轴的刻度,y轴就是对应标签属性数。在未指明的情况下,plot会默认创建相应的坐标轴。
2.2 plot参数
如上图所示,这是一个十分简陋的折线统计图,plot函数为我们提供了许多参数可以对图进行进一步调整:
-
x:指定x轴的数据,可以是一个数组、列表或者NumPy数组。这是绘制图形时横坐标的数据。
-
y:指定y轴的数据,可以是一个数组、列表或者NumPy数组。这是绘制图形时纵坐标的数据。
-
linestyle(或简写为ls):指定线条的样式,如实线('-')、虚线('--')、点划线('-.')等。默认为实线。
-
linewidth(或简写为lw):指定线条的宽度,可以是整数或浮点数。默认为1。
-
color(或简写为c):指定线条的颜色。可以是字符串(如'red'、'blue'等)、缩写(如'r'、'b'等)或者十六进制颜色代码(如'#FF0000')。默认为蓝色。
-
marker:指定数据点的标记样式,如'o'(圆圈)、'+'(加号)等。默认为不使用标记('None')。
-
markersize(或简写为ms):指定数据点标记的大小,可以是整数或浮点数。默认为6。
-
markeredgecolor(或简写为mec):指定数据点边缘的颜色。可以是字符串、缩写或者十六进制颜色代码。默认为与线条颜色相同。
-
markerfacecolor(或简写为mfc):指定数据点填充的颜色。可以是字符串、缩写或者十六进制颜色代码。默认为无填充颜色('none')。
-
label:指定线条的标签,用于图例显示。默认为不显示图例('None')。注意,虽然plot()函数提供了图例标签信息,但需要配合legend()函数才能显示图例。
-
alpha:指定线条和数据点的透明度,取值范围为0(完全透明)到1(完全不透明)。默认为1。
-
zorder:指定图层顺序,数值越大,图层越靠前。默认为0。
-
data = pd.DataFrame([1,4,5,7,9,11,20]) data.plot(color='red',alpha=0.9,legend=True,marker='o',linestyle='--',markeredgecolor='blue',label=2) -

-
其他常见参数:
-
xlabel:指定x轴的标签。
-
ylabel:指定y轴的标签。
-
title:指定图表的标题。
-
xlim、ylim:分别指定x轴和y轴的显示范围。
-
grid:是否显示网格线,可以设置为True或False。
-
legend:虽然作为参数传入时通常用于控制图例的显示(但更常见的做法是使用legend()函数),但注意plot函数本身不接受legend作为直接控制图例显示的参数。
-
figsize:指定图表的大小,以英寸为单位,格式为(width, height)。
2.3 图像调整
在图中看到最下面的一个直线趋近于直线,是因为我们的y轴刻度范围给的太大,这就需要我们进一步对图进行刻画。
作图
plt.plot(color='red')坐标轴刻度范围
plt.xlim([0,4])
plt.ylim([0,300])坐标轴刻度
plt.xticks([1,2,10],labels=['a','b','c'],rotation=0)坐标轴标签
plt.xlabel('sample')
plt.ylabel('amount')图的标题
plt.title('easy')请记住,DataFrame的行表示图的横坐标,列为纵坐标
3. 可视化图像
以wine数据集为例
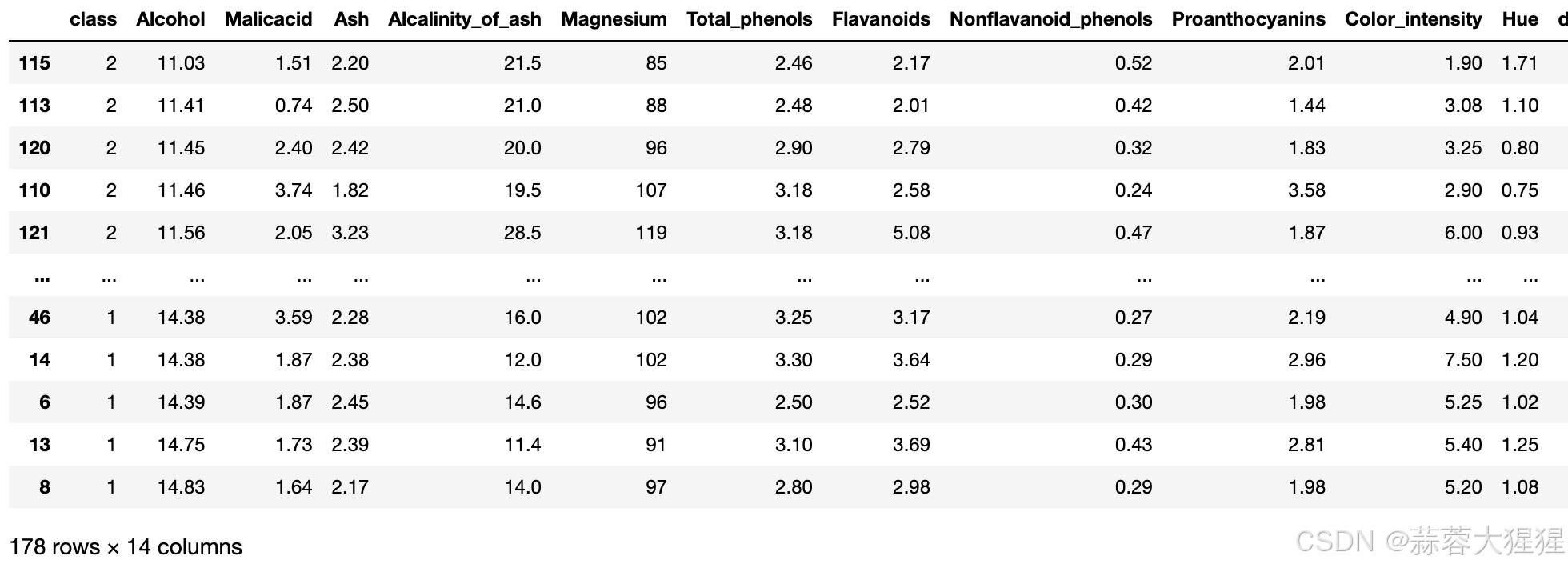
获取到如此庞大的数据集我们一脸懵逼,但通过使用作图的方式我们可以很好的去找到每一个类别中相比较下独特的属性。
例如柱状统计图直观反映各个数据项的比较关系。
3.1 柱状图
3.1.1 离散柱状图
柱状图特别适合用来展示分类变量的数据,所以一般横坐标表示分类变量,柱的高度代表其对应数值。
df1 = data['class'][data['Alcohol'] >13].value.counts() #统计这一列中出现元素的个数
df2 = data['class'][data['Alcohol'] <= 13].value_counts()
train = pd.DataFrame({'>13':df1,'<=13':df2}) #每一个类别有两个柱
train.plot(kind=bar)上述代码统计每一个类别中酒精度超过13以及不超过13的数量。
离散柱状图作为最常见的柱状统计图,能够一眼看出各个数据的大小,便于比较数据之间的差别。
运行结果如下:
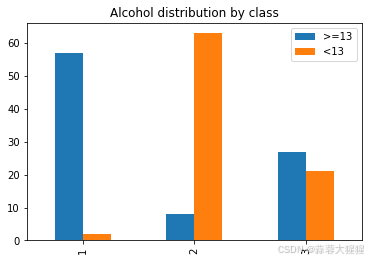
上图可以发现类别为1的样本大多数酒精含量超过13,相比之下偏高,类别2则大部分低于13;类别3的样本则是较为均匀,一半一半。
3.1.2 堆叠柱状图
train.plot(kind='bar',stacked=True) #堆叠柱状图 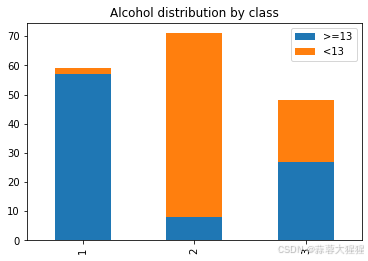
堆叠柱状图可以更加直观看出每一类别的组成成分,以及不同类别之间总量的大小关系。
- 同类数据对比:在同一根柱子内,不同分类的数据可以直接进行对比,观察者可以清楚地看到哪些分类占据主导地位,哪些分类贡献较小。
- 跨类别数据对比:通过对比不同柱子(即不同分类或时间点)的高度和构成,观察者可以分析不同分类或时间点之间的数据变化趋势和差异。
3.2 直方图
直方图通过连续变量的区间分布来展示数据的分布情况。它主要用于描述数值变量的分布。
注意区分柱状图bar主要用于描述分类(categorical)变量的数据,统计分类变量的大小。所以为了区分每一类别,bar图不同类别柱都是相隔开的。
data = {'A': [2, 2, 2, 2, 1], 'B': [5, 4, 3, 2, 1], 'C': [2.5, 2.7, 3.0, 3.2, 3.5]}
df1 = pd.DataFrame(data)
df1
df1['A'].plot(kind='hist',bins=10,alpha=0.7,align='mid') #alpha控制透明度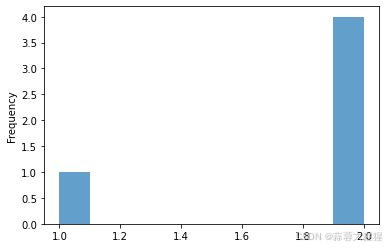
调节hist标签位置
上图看出,柱子的中心并没有与x轴标签对齐
调节hist标签位置通常是一个两步过程:首先绘制直方图,然后(可选地)调整x轴的刻度标签位置。
import pandas as pd
import numpy as np # 示例数据
#手动调节对齐
data = {'A': [2, 2, 2, 2, 1], 'B': [5, 4, 3, 2, 1], 'C': [2.5, 2.7, 3.0, 3.2, 3.5]}
df1 = pd.DataFrame(data)
df1
#hist默认上下界限为count第一个与最后一个,想要更改x轴标签,需要选中上下限位置中柱体的居中位置的标签修改labels
# 计算直方图的柱子和中心
counts, bin_edges = np.histogram(df1['A'], bins=11, density=False) #bins代表柱子个数,一般为间距+1,与计数点一样多
bin_centers = (bin_edges[:-1] + bin_edges[1:]) / 2
print(counts,bin_edges)
print(bin_centers)
# 绘制直方图
df1['A'].plot(kind='hist', bins=11, alpha=0.7,density=Flase) #density是否应该被归一化为概率密度# 手动设置x轴的刻度标签(可选)
plt.xticks(bin_centers,labels=[1.0,1.1,1.2,1.3,1.4,1.5,1.6,1.7,1.8,1.9,2.0]) # 显示图形
plt.show()hist默认上下界限为count第一个与最后一个,想要更改x轴标签,需要选中上下限位置中柱体的居中位置的标签修改labels。换句话来讲想要通过修改标签位置,实际上是找到柱子中心底座的标签,再将其标签的label进行修改,柱子是不会移动的。

这样就是手动对齐直方图与其标签。
3.3 散点图
3.3.1 分组散点图
plt.scatter(data['class'],data['Total_phenols'],color='red')
plt.xticks(ticks=[1,2,3],labels=['A','B','C'],rotation=-45) #负数为逆时针旋转
plt.xlabel('class')
plt.ylabel('Total phenols')
#plt.grid() 显示网格scatter(x,y),上述代码中class类别代表横坐标,Total_phenols代表纵坐标。通过散点图,可以直观看出每一个类别中的phenols的分布情况。
如下图所示:
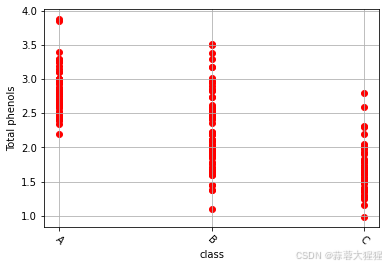
上述散点图得知,class1中phenols含量相对较高,离散程度较小;class2离散程度大,phenols含量每一个样本浮动程度也大;而class3含量相对较低。
通过散点图,可以直观的对数据进行统计分析,较为基础的发现每一类别中数据离散程度,极值的相对大小,数据集中内部关系;但仍然需要进一步计算各个指标得出更精准的结论。
4. 可视化进阶
4.1 子图
#子图
import pandas as pd
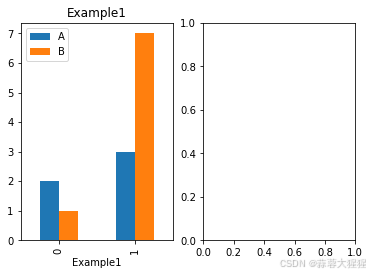
data = pd.DataFrame({'A':[2,3],'B':[1,7]})import matplotlib.pyplot as plt
fig = plt.figure() #创建一张图
ax1 = plt.subplot(1,2,1) #在行为1,列为2(及列方向创建)2个子图
data.plot(kind='bar',ax=ax1) #指定坐标轴
ax1.set_xlabel('Example1')
ax1.set_title('Example1')ax2 = plt.subplot(1,2,2)单个图形窗口中创建多个子图(即多个图表),允许用户在一个视图内展示多个数据集或数据维度的对比和关联,从而提高数据分析的效率和深度。
创建子图的作用主要是以下三点:
1. 多角度展示数据
-
数据对比:subplot允许将不同数据集或同一数据集的不同方面在同一图形界面中展示,便于用户直接对比各数据集或数据维度的差异。
-
多维度分析:在数据分析中,经常需要从多个角度观察数据,subplot提供了一种直观的方式来同时展示这些不同角度的视图。
2. 提高空间利用率
-
节省空间:相比于分别创建多个独立的图表,subplot能够在有限的图形界面空间内展示更多信息,减少了图表之间的切换需求。
-
优化布局:通过合理的布局设计,subplot可以使得整个图形界面看起来更加整洁、有序,提高了数据的可读性。
3. 便于故事讲述
-
连贯性:在数据报告或演示中,subplot可以帮助构建一个连贯的故事线,通过多个子图的相互呼应和补充,使得数据的呈现更加生动、有力。
-
引导性:通过合理的子图排列和顺序,可以引导观众或读者的注意力,按照特定的逻辑顺序来理解和分析数据。