Sharding Sphere 官方文档地址:
- https://shardingsphere.apache.org/document/current/cn/overview/
- maven仓库:https://mvnrepository.com/artifact/org.apache.shardingsphere/shardingsphere-jdbc
官方的文档写的很详尽到位,这里会截取部分文档内容便于理解和快速上手,强烈推荐阅读官方文档原文
什么是 ShardingSphere
一、介绍ShardingSphere
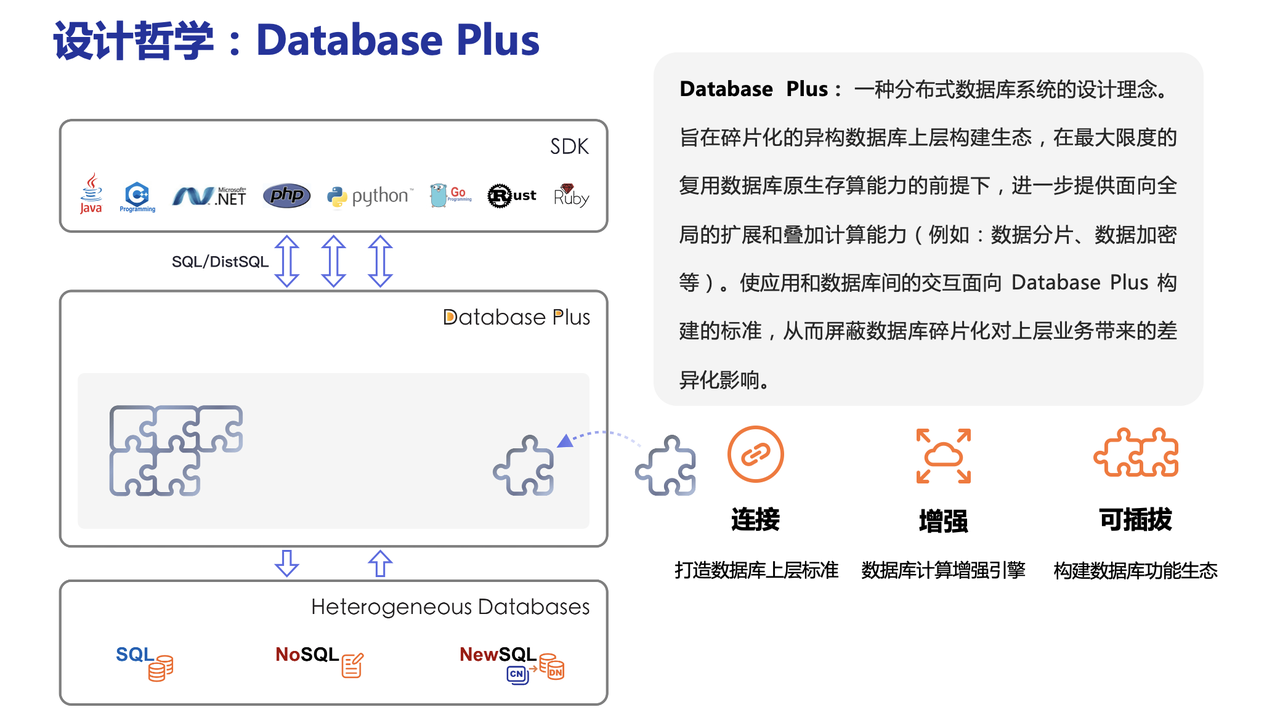
Apache ShardingSphere (本文后续简称“SS”)是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
ShardingSphere一般指代的是以下两个产品:
- ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。
- ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。
关于 《Database Plus 设计哲学》
二、部署形态
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅 Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
| 直观理解 | 引入服务内部使用,配置后实现多数据源管理 | 代理数据库,对服务相当于直连数据库 |
ShardingSphere-JDBC 独立部署
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC;
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等;
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库。
ShardingSphere-Proxy 独立部署
ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。 目前提供 MySQL 和 PostgreSQL 协议,透明化数据库操作,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用;
- 兼容 MariaDB 等基于 MySQL 协议的数据库,以及 openGauss 等基于 PostgreSQL 协议的数据库;
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端,如:MySQL Command Client, MySQL Workbench, Navicat 等。
混合部署架构
进阶,暂不考虑
三、快速开始选项
采用ShardingSphere-JDBC单机部署,结合springboot,管理postgresql数据库
快速开始
最新的5.5.0配置手册不够详致,这里找到历史的的使用手册(SPRING BOOT STARTER)
- https://shardingsphere.apache.org/document/5.0.0/cn/user-manual/
- https://shardingsphere.apache.org/document/5.2.1/cn/user-manual/
关于版本选择:
这里使用5.0.0版本,5.0.0的spring-boot-starter的版本存在一些bug和官方文档对不起来,改用5.2.1
一、环境准备
必备的依赖
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>${shardingsphere.version}</version>
</dependency>
搭配一些环境基础的依赖
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.2</version>
</dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional>
</dependency><dependency><groupId>org.postgis</groupId><artifactId>postgis-jdbc</artifactId><version>1.3.3</version><scope>compile</scope>
</dependency>
yaml读取错误问题和解决方案
解决方案:https://blog.csdn.net/weixin_47899191/article/details/130743334
报错信息如下:
***************************
APPLICATION FAILED TO START
***************************Description:
An attempt was made to call a method that does not exist. The attempt was made from the following location:org.apache.shardingsphere.infra.util.yaml.constructor.ShardingSphereYamlConstructor$1.<init>(ShardingSphereYamlConstructor.java:44)
解决方案:
覆盖springboot2.x的SnakeYAML依赖,如果你是sringboot3.x,可能不需要,作者没有尝试。
原因参考github上的Issues:https://github.com/apache/shardingsphere/issues/21476
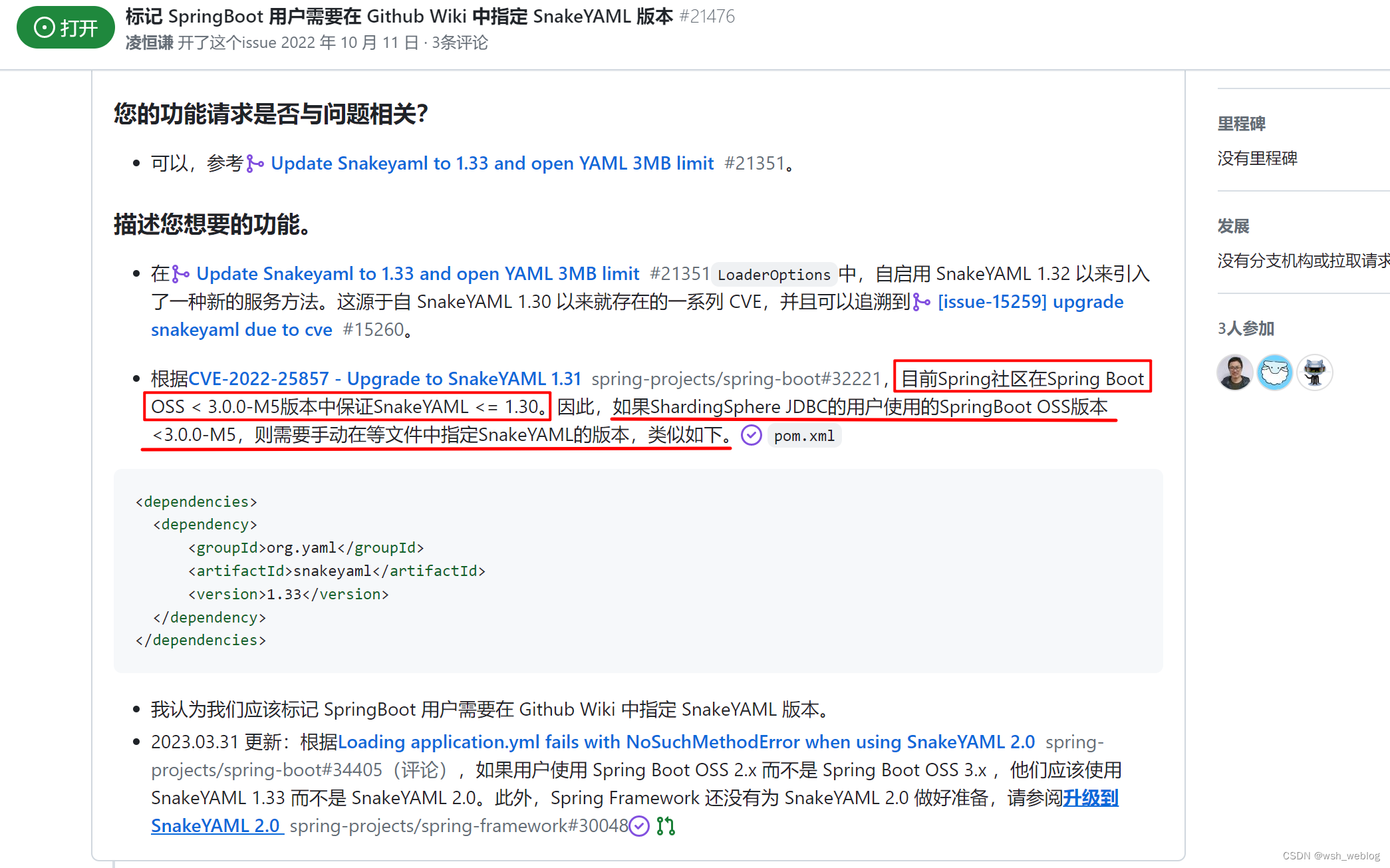
引入依赖覆盖springboot默认版本即解决
<dependency><groupId>org.yaml</groupId><artifactId>snakeyaml</artifactId><version>1.33</version>
</dependency>
二、⭐️快速配置
官方示例(参考
官方给的示例配置如下,可以转换成yml格式更具有可视化
# 配置真实数据源
spring.shardingsphere.datasource.names=ds0,ds1# 配置第 1 个数据源
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=# 配置第 2 个数据源
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=# 配置 t_order 表规则
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}# 配置分库策略
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=database_inline# 配置分表策略
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=table_inline# 省略配置 t_order_item 表规则...
# ...# 配置 分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.props.algorithm-expression=ds_${user_id % 2}
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.props.algorithm-expression=t_order_${order_id % 2}
快速配置yaml(测试可行
结合potgresql配置如下
server:port: 9696spring:shardingsphere:mode:type: Standalonerepository:type: JDBCprops:# 禁用执行SQL用于获取表元数据sql-show: true# 禁用执行SQL用于获取数据库元数据
# check-table-metadata-enabled: falsedatasource:# 配置真实数据源 相当于ds0,ds1names: ds0,ds1ds0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: org.postgresql.Driverjdbc-url: jdbc:postgresql://localhost:5432/sd0username: postgrespassword: rootds1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: org.postgresql.Driverjdbc-url: jdbc:postgresql://localhost:5432/sd1username: postgrespassword: rootrules:sharding:tables:#这里以student表为例student:# 表名的分片规则: # 由数据源名 + 表名组成(参考 Inline 语法规则)actual-data-nodes: ds$->{0..1}.student$->{0..1}# 分布式序列策略key-generate-strategy:# 自增列名称,缺省表示不使用自增主键生成器column: id# 分布式序列算法名称key-generator-name: snowflake# 配置分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一:standard/complex/hint/nonedatabase-strategy:# 用于单分片键的标准分片场景standard:# 分片列名称 这里指定age作为分库键sharding-column: age# 分片算法名称sharding-algorithm-name: student_age_inline# 配置分表策略,分库键class_id,分库策略student_class_id_inlinetable-strategy:standard:sharding-column: class_idsharding-algorithm-name: student_class_id_inline# 配置分片算法sharding-algorithms:# 分库策略:根据age取余2student_age_inline:type: INLINEprops:algorithm-expression: ds$->{age % 2}# 分表策略:根据classid取余2student_class_id_inline:type: INLINEprops:algorithm-expression: student$->{class_id % 2}key-generators:# 配置主键生成算法-雪花算法snowflake:type: SNOWFLAKE配置逻辑梳理
只抄配置不如理解配置逻辑
- 可选:手续配置SS的运行模式(不配置就默认单机
- 可选:SS的运行配置
- 必选:数据源配置 datasource:(告诉SS数据库信息
- 声明数据源别名
- 分别给每个数据源声明连接池,驱动,地址,账号密码等
- 必选:配置分库分表测试rules:
- 指定要分库分表的表名
- 配置数据节点(告诉SS哪些库哪些表中有这张表的数据
- 配置分库/分表策略(告诉SS如何分配这张表的数据
- 分库建
- 分库策略
- 必选:配置分库/分表策略
三、问题记录
① 使用 Spring Boot 2.x 集成 ShardingSphere 时,配置文件中的属性设置不生效?以及 “Inline sharding algorithm expression cannot be null”异常
解决方法来自官方FAQ:https://shardingsphere.apache.org/document/5.2.1/cn/faq/
需要特别注意,Spring Boot 2.x 环境下配置文件的属性名称约束为仅允许小写字母、数字和短横线,即
[a-z][0-9]和-。 原因如下: Spring Boot 2.x 环境下,ShardingSphere 通过 Binder 来绑定配置文件,属性名称不规范(如:驼峰或下划线等)会导致属性设置不生效从而校验属性值时抛出NullPointerException异常。参考以下错误示例:
- 下划线示例:database_inline
- 驼峰示例:databaseInline
我在配置过程中也有遇到这个问题,通过将shardingsphere-jdbc-core-spring-boot-starter依赖从版本5.0.0升级到5.2.1即可解决,遇到类似的问题两种解决方案都可以考虑。

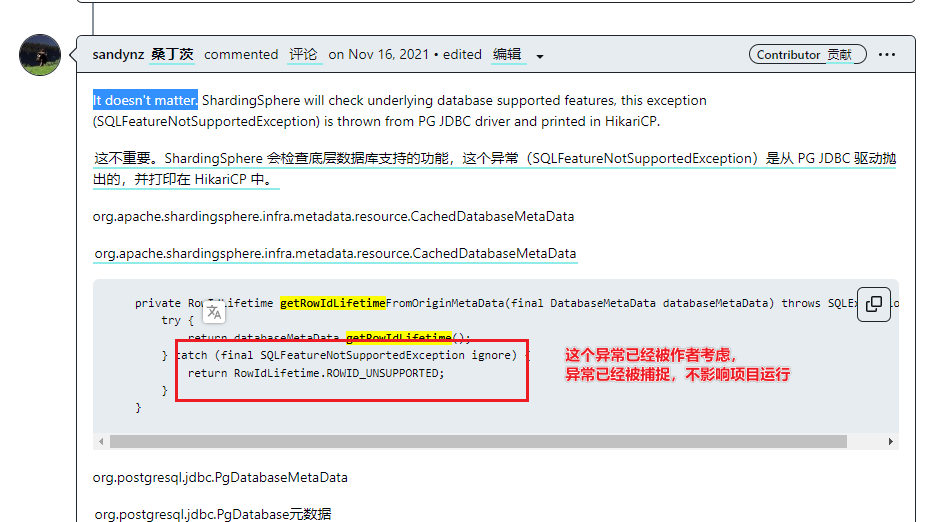
② …getRowIdLifetime() 方法尚未被实作。问题记录和解决.
报错信息如下:

AI建议:
这个错误表明你正在使用的PostgreSQL JDBC驱动版本不支持
getRowIdLifetime()方法。这个方法是在JDBC 4.1规范中引入的,如果你的驱动版本较旧,可能不会实现这个方法。
解决方案:
没找到合适的解决方案(提升pgsql驱动到最高版本也无解),阅读源码后发现这个方法没有实现已经被代码低层catch,查阅官方git的议题org.postgresql.jdbc.PgDatabaseMetaData.getRowIdLifetime() 方法尚未被实作,也可以找到作者的回复“It doesn’t matter”,也就是其实不影响使用
PS:我之前使用3.0.0版本的SS其实没有这个问题,不过不影响使用,就算了吧,反正It doesn’t matter