一、Java基础
1.ArrayList底层数据结构是什么?说一下你对它的理解
底层是一个长度可变的数组,当使用new ArrayList()的时候,底层是:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; //默认 容量(数组长度为0)
}
当第一次往集合添加元素时,即 调用add 方法
public boolean add(E e) {
//是否需要扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//计算是否需要扩容
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
//返回所需要的最小容量
calculateCapacity(elementData, minCapacity)
if (minCapacity - elementData.length > 0) //如果 所需要的最小容量大于 数组长度
grow(minCapacity); // 扩容
//扩容方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
2.你对 封装 继承 多态的理解???
符合 JavaBean 规范的 Java实体类封装标准
2.1.1Java中面向对象三大特征之一 封装
封装单说 面向对象 JavaBean 规范的封装操作是非常简单,使用工具不需要自己动手
一段代码,如果出现了三次,封装成一个方法
一组相关方法,使用了三次,封装成一个类
一个类,使用了三次,完成对应的详细文档
一个文档,参考阅读了三次,发一篇博客
【归纳,总结,封装,复用】
2.1.2JavaBean 规范封装要求
要求:1. 所有成员变量全部【私有化】2. 提供对应的构造方法,必须有一个无参数构造方法3. 所有的成员变量提供配套的 【Setter 和 Getter】 方法,用于成员变量数据获取和成员变量数据赋值
2.1.3 私有化
public:公开的,公共的,public修饰的成员变量和成员方法,可以通过该类对象,在类大括号之外直接操作。例如:person.name = "苟磊";person.sleep();
private:私有化,private 修饰的成员变量和成员方法,有且只允许在类大括号以内使用,类外没有使用的权利。tips:private 修饰成员方法,需要项目逻辑来支持,后期讲解。private 修饰成员变量1. 操作麻烦了,类大括号之外无法直接使用了,类大括号使用没有影响2. private 私有化的目标,是为了 标准化的赋值和取值操作。 ==> 【Setter 和 Getter】 方法
2.1.4 this 关键字【基础功能】
基础功能:可以在成员方法中,明确变量形式。this.变量名 ==> 表明当前操作的变量是【成员变量】,不是方法内的【局部变量】
2.1.5 Getter方法
功能:获取成员变量存储的数据内容。因为 JavaBean 规范中,成员变量 private 修饰,无法类大括号之外直接操作,需要辅助方法完成取值操作。格式:public 成员变量对应数据类型返回值 get成员变量名() {return 成员变量;}案例:// 成员变量private String name;// 配套 Getter 方法public String getName() {return name;}tips:方法名必须按照小驼峰命名法完成!!!如果不完成,后期项目中,自动化操作无法完成。
2.1.6 Setter方法
功能:设置/赋值 private 修饰私有成员变量数据,为了【规范】格式:public void set成员变量名(对应成员变量数据类型参数 参数名必须是和成员变量同名) {this.成员变量 = 参数变量;}
案例:// 私有化成员变量private String name;// 对应的 Setter 方法public void setName(String name) {this.name = name;} tips:方法名必须按照小驼峰命名法完成!!!如果不完成,后期项目中,自动化操作无法完成。
package com.qfedu.a;// 符合JavaBean规范 实体类
class SingleDog {// private 私有化修饰所有成员变量private String name;private int age;private char gender;// 根据所需完成构造方法,【必须有一个无参数构造方法】public SingleDog() {}public SingleDog(String name) {this.name = name;}public SingleDog(String name, int age, char gender) {this.name = name;this.age = age;this.gender = gender;}// 配套完成所有成员变量 Getter and Setter 方法public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public char getGender() {return gender;}public void setGender(char gender) {this.gender = gender;}
}public class Demo2 {public static void main(String[] args) {SingleDog singleDog = new SingleDog("张三 ", 20, '男');System.out.println("Name:" + singleDog.getName());System.out.println("Age:" + singleDog.getAge());System.out.println("Gender:" + singleDog.getGender());// 执行 setter 修改成员变量数据System.out.println("执行 setter 修改成员变量数据");singleDog.setName("贝贝");singleDog.setAge(16);singleDog.setGender('女');System.out.println();// Setter 方法执行完毕,展示数据修改情况System.out.println("Setter 方法执行完毕,展示数据修改情况");System.out.println("Name:" + singleDog.getName());System.out.println("Age:" + singleDog.getAge());System.out.println("Gender:" + singleDog.getGender());}
}
2.2
继承(规范、 方法统一)
2.2.1 Java中继承的语法
关键字:extends
格式:class A extends B {}A 类是 B 类的一个子类B 类是 A 类的唯一父类【单继承语言】
特征:1. 子类可以通过继承得到父类【非私有化】成员2. 子类不可以通过继承得到父类的【私有化】成员
tips:成员 ==> 成员变量和成员方法
2.2.2 有其父必有其子【难点】
package com.qfedu.a_extends;class Fu {public Fu() {System.out.println("父类无参数构造方法");}
}class Ez extends Fu {public Ez() {System.out.println("子类无参数构造方法");}
}/** 有其父必有其子* * 执行结果:* 父类无参数构造方法* 子类无参数构造方法* 问题1: * 构造方法有没有创建对象的能力???* 没有创建对象的能力。* 目前代码中,实际上没有父类对象* * 问题2:* 构造方法作用???* 1. 提供数据类型* 2. 初始化对应空间的数据内容* * 问题3:* 创建子类对象,为什么会自动执行父类构造方法???* 理论解释:* 1. 子类对象可以使用父类的非私有化成员,证明父类非私有化成员* 是占用子类对象数据空间的。* 2. 父类的成员应该通过该父类的方式来决定,父类的构造方法,在* 创建子类的过程中,被JVM自动调用,实际上就是来初始化父类空间,* 提供给子类使用。父类数据空间内容实际上是包含在子类对象中。** 原则:* 继承语法中,创建子类对象,会自动调用父类的无参构造方法。* 首先执行父类构造方法,在来执行子类构造方法。*/
public class Demo2 {public static void main(String[] args) {Ez ez = new Ez();System.out.println(ez);}
}
2.2.3 super 关键字【非重要知识点】
可以通过super关键字在子类中调用父类成员变量和成员方法。
3.类加载器有哪些?
JDK自带有三个类加载器:
BootStrapClassLoader: 是ExtClassLoader的父类加载器,默认负责加载%JAVA_HOME%lib下jar包和class文件。
ExtClassLoader:是AppClassLoader的父类加载器,负责加载%JAVA_HOME%/lib/ext 文件夹下的jar包和class类。
AppClassLoader:是自定义加载器的父类,负责加载classpath下的类文件。(系统默认类加载器,平常开发中所写的java文件以及引入的jar包都由此加载器加载,不仅仅是系统类加载器,还是线程上下文加载器)。
自定义类加载器:继承ClassLoader实现自定义类加载器。
4. 多类合作
1.HashMap 底层数据结构
HashMap 就是以 Key-Value 的方式进行数据存储的一种数据结构嘛,在我们平常开发中非常常用,它在 JDK 1.7 和 JDK 1.8 中底层数据结构是有些不一样的。总体来说,JDK 1.7 中 HashMap 的底层数据结构是数组 + 链表,使用 Entry 类存储 Key 和 Value;JDK 1.8 中 HashMap 的底层数据结构是数组 + 链表/红黑树,使用 Node 类存储 Key 和 Value。当然,这里的 Entry 和 Node 并没有什么不同。
2.你在开发过程中,常用的集合有哪些?
Java集合大致可分为四种。Set、LIst、Queue和Map,其中 Set 表示无序、不可重复的集合(由于没有顺序,如果还有元素重复的就无法区分了);List 代表有序、可重复的集合(和数组较像,但长度可变);而 Map 代表具有映射关系的集合(键值对中的 key 不能重复);Queue代表用来实现队列的集合。所有集合类均位于 java.util 包下。Java常见集合分为两大类 Collection 和 Map。
3.基本数据类型与封装类的区别
1.基本数据类型是值传递,封装类是引用传递
2.基本数据类型是存放在栈中的,而封装类是存放于堆中的
3.基本数据类型初始值如:int=0,而封装类Integer=null
4.集合中添加的元素一定是封装类引用数据类型
5.声明基本数据类型不需要实例化可直接赋值,而封装类必须申请一个存储空间实例化才可赋值。
4.多线程的实现方式
1.继承Thread类,重写run方法;
2.实现Runnable接口,重写run方法;
3.实现Callable接口,重写call方法;
4.通过线程池实现多线程(实现Runnable接口+Executors创建线程池);
(前2种方法无返回值,后2种方法有返回值。)
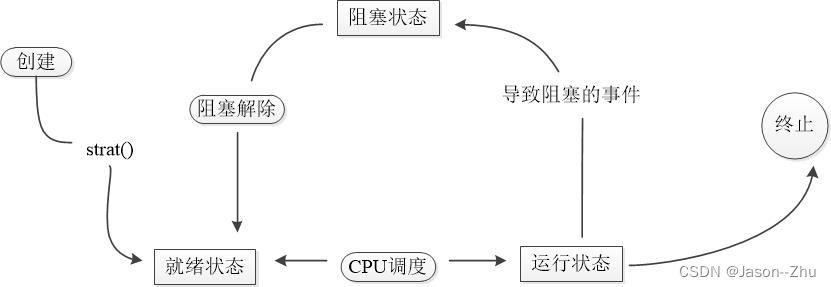
5.线程生命周期
线程的生命周期一共分为五个部分分别是:新建,就绪,运行,阻塞以及死亡。由于cpu需要在多条线程中切换因此线程状态也会在多次运行和阻塞之间切换。
6.线程控制相关方法
【注】不是 start 之后就立刻开始执行,只是就绪了(CPU可能正在运行其他的线程)。只有被 CPU) 调度之后,线程才开始执行,当 CPU 分配给的时间片到了,又回到就绪状态,继续排队等候。
线程控制的基本方法:
isAlive():判断线程是否还活着。start 之后,终止之前都是活的。
getPriority():获得线程的优先级数值。
setPriority():设置线程的优先级数值(线程是有优先级别的)。
Thread.sleep():将当前线程睡眠指定毫秒数。
join():调用某线程的该方法,将当前线程与该线程合并,也即等待该线程结束后,再恢复当前线程的运行状态(比如在线程B中调用了线程A的 join(),直到线程A执行完毕后,才会继续执行线程B)。
yield():当前线程让出 CPU,进入就绪状态,等待 CPU 的再次调度。
wait():当前线程进入对象的 wait pool。
notify()/notifyAll():唤醒对象的 wait pool 中的一个/所有的等待线程。
7.线程同步
同步就是协同步调,按预定的先后次序进行运行。如:你说完,我再说。这里的同步千万不要理解成那个同时进行,应是指协同、协助、互相配合。线程同步是指多线程通过特定的设置(如互斥量,事件对象,临界区)来控制线程之间的执行顺序(即所谓的同步)也可以说是在线程之间通过同步建立起执行顺序的关系,如果没有同步,那线程之间是各自运行各自的!
线程互斥是指对于共享的进程系统资源,在各单个线程访问时的排它性。当有若干个线程都要使用某一共享资源时,任何时刻最多只允许一个线程去使用,其它要使用该资源的线程必须等待,直到占用资源者释放该资源。线程互斥可以看成是一种特殊的线程同步(下文统称为同步)。
8.线程通信
由于一个进程通常包括多个线程,这多个线程之间因资源共享自然地就存在一种合作关系。这种合作关系虽然可以表现为相互独立,但更多地时候是互相交互,这就是通信。
线程之间的交互我们就称之为线程通信。线程通信是从进程通信演变而来的,进程通信有个专有缩写,叫IPC( Inter-Process Communication)。由于每个进程至少有一个线程,进程的通信就是进程里面的线程通信。
9.Lambda表达式
lambda 表达式的语法格式如下:
(parameters) -> expression或
(parameters) ->{ statements; }
以下是lambda表达式的重要特征:
可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定表达式返回了一个数值。
10.Stream 流
stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果;
stream不会改变数据源,通常情况下会产生一个新的集合;
stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
对stream操作分为终端操作和中间操作,那么这两者分别代表什么呢?
终端操作:会消费流,这种操作会产生一个结果的,如果一个流被消费过了,那它就不能被重用的。
中间操作:中间操作会产生另一个流。因此中间操作可以用来创建执行一系列动作的管道。一个特别需要注意的点是:中间操作不是立即发生的。相反,当在中间操作创建的新流上执行完终端操作后,中间操作指定的操作才会发生。所以中间操作是延迟发生的,中间操作的延迟行为主要是让流API能够更加高效地执行。
stream不可复用,对一个已经进行过终端操作的流再次调用,会抛出异常。
11.反射
new 是静态编译,只能用于编译期就能确定的类型, 而反射可以在运行时才确定类型并创建其对象。Java的反射机制就是动态编译,增加程序的灵活性,解耦。 具体来说就是静态编译是在编译的时候把你所有的模块都编译到程序中,当你启动这个程序的时候所有模块都加载进来了。当程序比较大时,加载的过程(就是当你运行程序时初始化的过程)就比较慢了。动态编译就不一样了,你编译的时候那些模块都没有编译进去,一般情况下你可以把那些模块都编译成dll,这样你启动程序(初始化)的时候这些模块不会被加载,而是在运行的时候,用到那个模块就调用哪个模块。比如:Spring中的 IOC(工厂模式)
和 new 创建对象 的区别:
(1)new只有在知道类名之后才能new,而反射有时候不需要。
知道类名的情况:
Class<?> c1 = Class.forName(“cn.classes.OneClass”); Class<?> c2 = new OneClass.getClass();
Class<?> c3 = OneClass.class();
不知道类名的情况:
首先jvm在其内部通过函数ProxyGenerator.generateProxyClass()方法来生成代理对象的字节码文件(其实 就没有具体文件,一切都是在内存中,暂时就这么叫吧),然后defineClass0()函数利用之前生成的二进制字节码文件来创建类Class对象,并顺便为代理类命名(proxyName是在字节码文件生成之前自己命名的),经过这个过程我们就可以在不知道类名的情况下得到了类Class对象了,然后就可以使用反射来获取对象实例了(这其中牵扯到类加载的加载过程
(2)new出来的对象中,我们是无法反问她的私有属性,而反射可以(通过setAccessible()取访问)
(3)new属于静态编译,而反射属于动态编译。静态编译就是在编译的时候把你所有的模块都编译进exe里去,当你启动这个exe的时候所有模块都加载进来了。当程序比较大时,加载的过程(就是当你运行程序时初始化的过程)就比较费力了。动态编译就不一样了,你编译的时候那些模块都没有编译进去,一般情况下你可以把那些模块都编译成dll,这样你启动程序(初始化)的时候这些模块不会被加载,而是在运行的时候,用到那个模块就调用哪个模块。
5 .ArrayList和 LinkList 以及Vector的区别?
1、从初始化、扩容、线程安全三方面对比ArrayList与Vector
ArrayList采用懒加载策略(第一次add时才初始化内部数组,默认初始化大小为10) 扩容为原先数组大小的1.5倍。采用异步处理,线程不安全,性能较高。ArrayList在大部分场合(80%,频繁查找、在集合末端插入与删除)都采用ArrayList。
Vector在实例化对象时就初始化内部数组(大小为10),capacityIncrement默认为0,扩容为原先数组大小的2倍。采用synchronized修饰增删改查方法,线程安全,性能较低(锁的粒度太粗,将当前集合对象锁住,读读都互斥),即使要用性能安全的集合,也不推荐使用Vector
LinkedList采用异步处理,线程不安全 频繁在任意位置的插入与删除考虑使用LinkedList LinkedList是Queue接口的常用子类。如果你的程序更多的是进行元素的随机访问或者从集合末端插入或删除元素,建议使ArrayList;如果更多的是进行随机插入和删除操作,LinkedList会更优。
6.Hashtable 和 Hashmap 的区别?
1.Hashtable是Dictionary的子类,HashMap是Map接口的一个实现类;
2.Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。即是说,在多线程应用程序中,不用专门的操作就安全地可以使用Hashtable了;而对于HashMap,则需要额外的同步机制。但HashMap的同步问题可通过Collections的一个静态方法得到解决:
Map Collections.synchronizedMap(Map m)
这个方法返回一个同步的Map,这个Map封装了底层的HashMap的所有方法,使得底层的HashMap即使是在多线程的环境中也是安全的。
3.在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键,而应该用containsKey()方法来判断。
7.HashMap 底层数据结构
HashMap底层实现JDK<=1.7数组+链表,JDK>=1.8数组+链表+红黑树;HashMap这一个类型底层涉及到3中数据类型,数组、链表、红黑树,其中查询速度最快的是数组,时间复杂度是O(1),链表数据量少的时候还行,数据量过大性能就一般了,它的时间复杂度是O(N),红黑树在数据量打的时候性能会比链表要好,他的时间复杂度是O(logn),这里在链表和红黑树这里性能对比其实在HashMap的扩容时,已经体现出来了,Hash值产生碰撞后,链表长度>8时会由链表转换为红黑树,而当红黑树的节点<6时,会由红黑树转换为链表,这就是二者的性能临界点。
8.你在开发过程中,常用的集合有哪些?
首先呢,java分为单列集合和双列集合,单列集合的顶级接口是Collection,双列集合的顶级接口是Map。
一、Collection的子接口有两个List和Set:
1.list接口的特点:元素可重复,有序(存取顺序)。
list接口的实现类:
ArrayList:底层实现是数组,查询快,增删慢,线程不安全,效率高;
Vector:底层实现是数组,查询快,增删慢,线程安全,效率低;【淘汰】
LinkedList:底层实现是链表,增删快,查询慢,线程不安全,效率高;
2.Set 接口的特点:元素唯一,不可重复,无序。
Set 接口实现类:
HashSet:底层实现 hashMap,数组+链表实现,不允许元素重复,无序。
TreeSet:底层实现红黑二叉树,实现元素排序
二、Map 接口的特点:key-value 键值对形式存储数据
Map 接口实现类:
HashMap:底层数组+链表实现,线程不安全效率高;
TreeMap:底层红黑二叉树实现,可实现元素的排序;
LinkedHashMap:底层 hashmap+linkedList 实现,通过 hashmap 实现 key-value 键值对存储,通过链表实现元素有 序
9.基本数据类型与封装类的区别
1.基本数据类型是值传递,封装类是引用传递
2.基本数据类型是存放在栈中的,而封装类是存放于堆中的
3.基本数据类型初始值如:int=0,而封装类Integer=null
4.集合中添加的元素一定是封装类引用数据类型
5.声明基本数据类型不需要实例化可直接赋值,而封装类必须申请一个存储空间实例化才可赋值。
10.多线程的实现方式
点这里
11.线程生命周期
1.线程的生命周期(5种状态)
在线程的生命周期中,它会经过新建(New)、就绪(Running)、阻塞(Blocked)和死亡(Dead)五种状态。由于CPU在多条线程之间切换,于是线程状态会多次在就绪和运行之间切换
新建状态:当程序使用 new 关键字创建一个线程后,该线程就处于新建状态,此时它仅仅由Java虚拟机分配内存,并初始化其成员变量的值。程序只能对新建状态的线程调用一次 start() 方法。
就绪状态:当线程对象调用 start() 方法后,该线程并没有马上执行而是进入就绪状态,Java虚拟机会为其创建方法调用栈和程序计数器,等待获取CPU资源后才会真正处于运行状态。
运行状态:处于就绪状态的线程获得CPU后,开始执行 run() 方法的线程执行体,进入运行状态。
阻塞状态:线程调用sleep()方法、调用阻塞式IO方法、试图获得同步监视器但该同步监视器正被其他线程持有、在等待某个通知(notify) 时会进入阻塞状态。阻塞状态解除后会重新进入就绪状态,重新等待线程调度器再次调度它。
死亡状态:线程 run()或call()方法执行完成、线程抛出一个未捕获的Exception或Error、直接调用线程的stop()方法 时会进入死亡状态。
2. 线程有哪些状态?如何切换?
①初始(NEW):新创建了一个线程对象,但还没有调用start()方法。
②运行(RUNNABLE):Java线程中将就绪(ready)和运行中(running)两种状态笼统的成为“运行”。
③阻塞(BLOCKED):表示线程阻塞于锁。
④等待(WAITING):进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
⑤超时等待(TIME_WAITING):该状态不同于WAITING,它可以在指定的时间内自行返回。
⑥终止(TERMINATED):表示该线程已经执行完毕。
线程切换新建一个线程,还未开始执行时,线程处于NEW状态。等到线程的start()调用时,线程开始执行,线程处于RUNNABLE状态。如果线程在执行过程中遇到了synchronized同步块,就会进入BLOCKED阻塞状态。如果运行中的线程调用wait方法,此线程进入WAITING等待状态。如果运行中的线程调用有时间参数的wait(long)方法,此线程进入TIME_WAITING超时等待状态。当线程执行完毕后,则进入TERMINATED状态。
12.线程控制相关方法
isAlive():判断线程是否还活着。start 之后,终止之前都是活的。
getPriority():获得线程的优先级数值。
setPriority():设置线程的优先级数值(线程是有优先级别的)。
Thread.sleep():将当前线程睡眠指定毫秒数。
join():调用某线程的该方法,将当前线程与该线程合并,也即等待该线程结束后,再恢复当前线程的运行状态(比如在线程B中调用了线程A的 join(),直到线程A执行完毕后,才会继续执行线程B)。
yield():当前线程让出 CPU,进入就绪状态,等待 CPU 的再次调度。
wait():当前线程进入对象的 wait pool。
notify()/notifyAll():唤醒对象的 wait pool 中的一个/所有的等待线程。
13.线程同步
线程同步主要包括四种方式:
互斥量pthread_mutex_
读写锁pthread_rwlock_
条件变量pthread_cond_
信号量sem_
14.线程通信
如果进程之间不进行任何通信,那么进程所能完成的任务就要大打折扣。 例如,父进程在创建子进程后,通常须要监督子进程的状态,以便在子进程没有完成给定的任务时,可以再创建一个子进程来继续。这就需要父子进程间通信。
而线程间的通信则需要更多。由于一个进程通常包括多个线程,这多个线程之间因资源共享自然地就存在一种合作关系。这种合作关系虽然可以表现为相互独立,但更多地时候是互相交互。这就是通信。就像舞台上的多个演员,他们之间是一种合作关系,共同将戏演好。虽然这些演员在舞台上的时候可以各自演各自的,不说话,也没有肢体接触,即没有交互,但他们更多的时候会进行对白和拥抱等交互操作。
线程之间的交互我们就称之为线程通信。线程通信是从进程通信演变而来的,进程通信有个专有缩写,叫IPC( Inter-Process Communication)。由于每个进程至少有一个线程,进程的通信就是进程里面的线程通信。
15.Lambda表达式和Stream 流
点这里
二、 EE
1.G1 垃圾回收器工作流程
1.初始标记:这阶段仅仅只是标记GC Roots能直接关联到的对象并修改TAMS的值。
2.并发标记:从GC roots使用可达性算法,对堆内存中对象进行标记(三色标记法),递归扫描整个堆。该步骤耗时过长,是与用户业务程序并发执行。
3.最终标记:对用户线程做另一个短暂的暂停,用于处理并发阶段结束后仍遗留下来的最后那少量的 SATB 记录。
4.筛选回收:负责更新 Region 的统计数据,对各个 Region 的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划。把回收的那一部分Region中的存活对象复制到空的Region中,在对那些Region进行清空。
ps:除了并发标记外,其余过程都要 STW
2.Volatile的特点
volatile修饰符适用于某个属性被多个线程共享,其中有⼀个线程修改了此属性,其他线程可以立即得到修改后的值。比如作为触发器,实现轻量级同步。
volatile属性的读写操作都是无锁的,它不能替代synchronized。因为它没有提供原子性和互斥性。因为无锁,不需要花费时间在获取锁和释放锁上,所以说它是低成本的。
volatile只能作用于属性,用volatile修饰属性,这样compilers就不会对这个属性做指令重排序。
volatile提供了可见性,任何⼀个线程对其的修改将立马对其他线程可见,volatile属性不会被线程缓存,始终从主存中读取。
volatile可以在单例双重检查中实现可见性和禁止指令重排序,从而保证安全性。
三、框架相关
1.谈谈你对框架的理解以及什么是ORM?
1、框架就是你在实际开发中,可以让使用者减少很多重复的代码、让代码的结构更加清晰,耦合度更低,后期维护方便。
- 在javaSE中你可以使用JDBC实现数据库的操作,在不使用框架的情况下,sql语句都是写在java代码中的。而使用框架的情况下,sql语句可以写在配置文件中,甚至可以通过一些组件进行自动生成。
2)同时,在实现了servlet、jsp这个前端展示的时候,请求地址都是写在web.xml这个配置文件中的,比较反锁,在使用springmvc框架时,定义一个url相对简单,只需要你配置一个注解
2、java现在流行的框架有Spring、struts2、hibnate,springmvc等技术。
最受欢迎的是spring框架,spring是一个轻量级的框架,轻量级的意思是在使用的这个框架时,完全感受不到这个框架的存在,不需要实现这个框架的任何接口,只需在执行的时候,加载这个框架的配置文件即可。在学习java的同时,会接触到javaSE(java的企业级开发,涉及到JDBC、SERVLET、网络编程)。在你解除了Spring框架后,你会很快的喜欢上它。功能强大,代码简洁,能实行几乎所有的javaSE的功能。
2.简述Maven打包方式以及使用?
打包的本质是压缩,而jar包和war包都是zip包。
1、pom是maven依赖文件
可以作为其他项目的maven依赖,用来做jar包的版本控制。
2、jar是java普通项目打包文件
通常是开发时需要应用的类,当需要某些功能时就导入相应的jar包;以zip包的形式供调用(用命令java -jar xxx.jar执行)。
3、war常用于java web项目工程;
用来发布服务,打成war包后部署到服务器访问。可以用zip包的形式使用(java -jar xxx.war执行,前提是配置了main函数入口),也可以用解压缩的形式使用(通常情况下是解压后的war包)。
3.简述MyBatis中的缓存
点这里
4.简述MyBatis中实现一对一,和多对多关系的不同点?
5.简述@RequestMapping,@RequestParam,@PathVariable的用法
点这里
6.谈谈你对Spring中IOC的理解以及实现DI的几种方式
点这里
7.SpringBean的生命周期
1.如果是单例 bean , 随着容器的创建而创建 即 实例化,多例bean 是 获取的时候 实例化
2.属性注入
3.后处理器前置过程 即在初始化方法之前执行的 方法 postProcessBeforeInitialization
4.初始化方法
5.后处理器后置过程 即在初始化方法之后执行的 方法 postProcessAfterInitialization aop动态代理就在这一步
6.得到最终的 bean
7.销毁
8.git的常用命令以及作用?
点这里
9.linux基础
9.1请介绍Linux 以及它和Windows的区别
Linux是开源且安全的,主要是基于命令行交互的方式操作。
Windows是收费的,基于图形化界面进操作。
9.2简述ls和ll命令的区别
ls是查看指定目录下有哪些内容
ll是列出详细信息。
9.3简述vi和vim的使用方式
vi是早期的编辑器,编辑文字没有彩色标识。
vim比vi强大,提供一些快捷命令,和文字彩色标识。
9.4 简述grep 的作用以及使用
grep主要用于在指定文件中检索关键字,可以在一个或者多个文件中进行检索,可以进行条件的设置。
9.5列举操作文件相关的命令(创建,拷贝,移动,删除)
touch a.txt vi a.txt vim a.txt
copy a.txt /a/b/c
mv a.txt /a/b/c
rm -rvf a.txt
rmdir xxx 删除空目录
9.6简述cat more less tail 四个命令的用法和区别
cat a.txt查看文件内容
more a.txt查看文件详细内容
less a.txt查看文件主要内容
tail a.txt追踪查看文件内容变化
9.7列举linux中对服务启动,停止,重启,查看状态的命令
systemctl start xxx.service
systemctl stop xxx.service
systemctl restart xxx.service
systemctl status xxx.service
9.8列举解压缩文件和压缩文件的命令
tar zcvf xxx.tar.gz xxx.txt
tar zxvf xxx.tar.gz
9.9查看系统中进程的命令和关闭进程的命令
ps -aux
ps -aux | grep xxx
kill pid
kill -9 pid
9.10 简述权限命令的用法以及含义
文件权限管理:执行ls -l(ll)
第0位:文件类型(d 目录,- 普通文件,l 链接文件)
第1-3位:所属用户(所有者)权限,用u(user)表示
第4-6位:所属组权限,用g(group)表示
第7-9位:其他用户(其他人)权限,用o(other)表示
r:代表权限是可读,r也可以用数字4表示
w:代表权限是可写,w也可以用数字2表示
x:代表权限是可执行,x也可以用数字1表示
修改文件/目录的权限的命令:chmod
示例:
修改a.txt的权限为属主有全部权限,属主所在的组有读写权限,其他用户只有读的权限
chmod u=rwx,g=rw,o=r a.txt 或者 chmod 764 a.txt(常用)
10.springboot
1.简述SpringBoot的优点
创建独立的 Spring 应用程序。
直接嵌入Tomcat、Jetty或Undertow(无需部署WAR文件)。
提供自以为是的“入门”依赖项以简化您的构建配置。
尽可能自动配置 Spring 和 3rd 方库。
提供生产就绪功能,例如指标、运行状况检查和外部化配置。
完全不需要代码生成,也不需要 XML 配置。
2.简述SpringBoot自动装配流程
点这里
3.简述SpringBoot多环境配置
点这里
4.简述SpringBoot中AOP的使用
点这里
5.简述WebMvcConfigurer接口的作用
点这里
6.简述@RestController Advice和@Except ionHandler的作用
点这里
7.简述如何使用Redis做MyBatis的二级缓存
点这里
8.简述@Async和@Scheduled的使用
点这里
9.简述Cron表达式的用法
点这里
10.简述@ApiModel, @ApiModelProperty, @Api, @ApiOperation 的作用
点这里
11.vue
1.简述对MVVM的理解
点这里
2.列举vue中的一些指令以及用法
点这里
3.简述vue的生命周期
点这里
4.简述vue组件间的参数传递
点这里
5.简述vue中路由的使用
点这里
6.简述vue中的路由守卫
点这里
7.什么是axios. js
点这里
8.什么是vuex
点这里
四、分布式相关
1.nginx
1简述nginx的作用
点这里
2简述正向代理和反向代理
点这里
3简述nginx中的负载均衡
点这里
4简述nginx中动态资源和静态资源的配置
点这里
5如何在不停服务器的情况下,对项目进行迭代
点这里