OCR调研
一、介绍
OCR(Optical Character Recognition,光学字符识别)是一种将图像中的文字转换为计算机可处理格式的技术。OCR技术经历了从传统OCR到基于深度学习的OCR的转变。深度学习OCR技术通过模拟人脑神经元结构处理文本和图像数据,相较于传统OCR,在复杂场景下的识别性能和速度有显著提升。它在金融、保险、医疗、交通、教育等多个行业中有广泛应用,并随着人工智能技术的发展,OCR技术的性能不断提升,应用场景也日益复杂化。
二、开源项目
1 PaddleOCR
项目地址:https://github.com/PaddlePaddle/PaddleOCR
PaddleOCR文档:https://paddlepaddle.github.io/PaddleOCR/
百度开源项目,文档完善。PaddleOCR 旨在打造一套丰富、领先、且实用的 OCR 工具库,助力使用者训练出更好的模型,并应用落地。
优点:准确率高,支持多语言,支持多种 OCR 相关前沿算法,支持自训练,支持倾斜、竖排等多种方向文字识别
缺点:偏向中文识别,语言支持有限
部署:本地部署、云端部署、docker

2 Tesseract
项目地址:https://github.com/tesseract-ocr/tesseract
优点:由Google维护,支持超过100种语言的识别,并且能够处理多种图像格式,如PNG、JPEG和TIFF等。提供了丰富的API接口和文档,支持多种操作系统。
缺点:速度慢
部署:安装Tesseract OCR(Windows/Linux)、配置环境变量
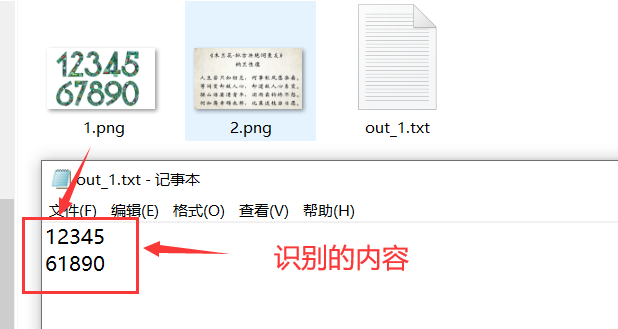
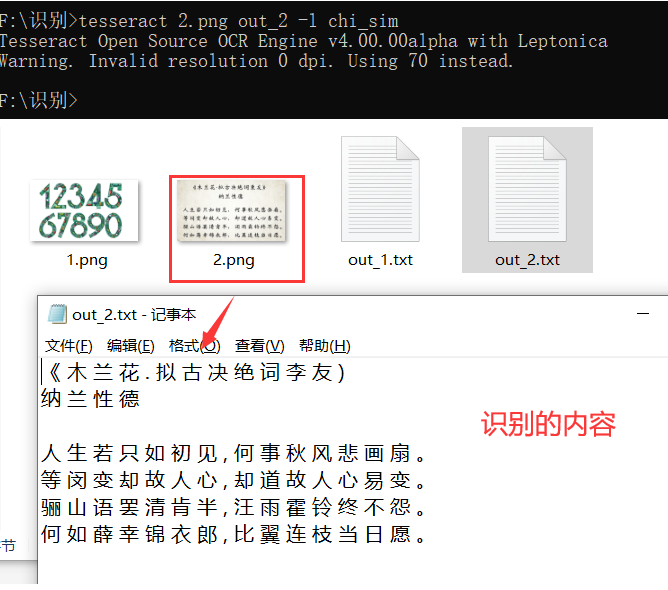
3 EasyOCR
项目地址:https://github.com/JaidedAI/EasyOCR
优点:全语种的(包括70+门外语识别),不单单针对中文
缺点:速度慢,官方推荐支持CUDA的独立显卡可以提高运行效率。
部署:pip安装,只能linux/windows下运行。


4 chineseocr
基于yolo3 与crnn 实现中文自然场景文字检测及识别
项目地址:https://github.com/chineseocr/chineseocr
优点:支持补充训练,有多版本优化模型
缺点:使用的三方库较老,部分三方库已废弃,环境配置困难,效果一般,且很少维护

5 chineseocr_lite
超轻量级中文ocr,支持竖排文字识别, 支持ncnn、mnn、tnn推理 ( dbnet(1.8M) + crnn(2.5M) + anglenet(378KB)) 总模型仅4.7M
项目地址:https://github.com/DayBreak-u/chineseocr_lite
优点:轻量模型,执行速度快,准确率高
缺点:不支持pip安装,不支持补充训练,不支持自定义训练;不支持复杂、不常见字符,比如德语、法语;竖向文本识别错误。
部署:源码下载运行
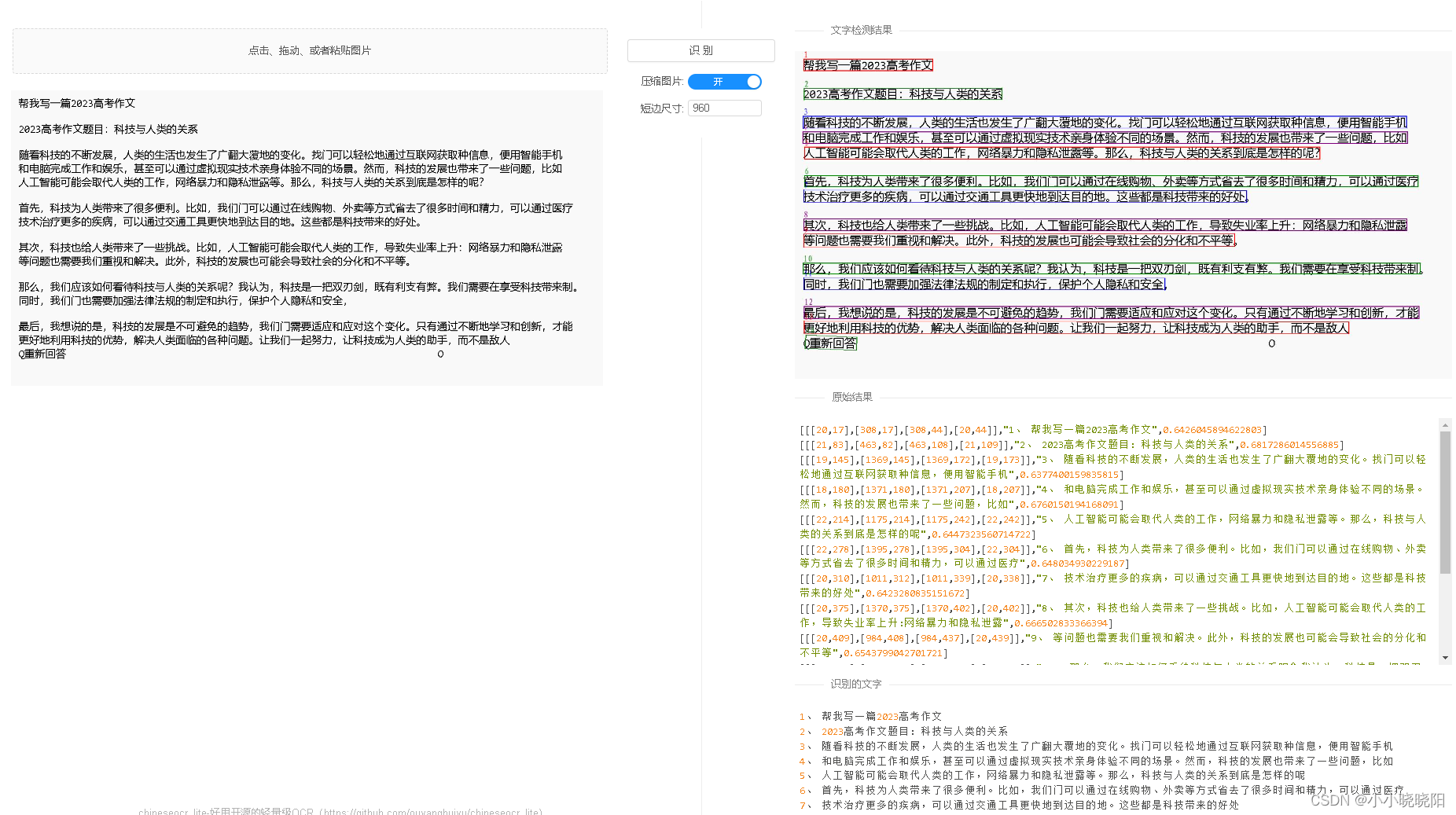
6 CnOCR
CnOCR 是 Python 3 下的文字识别(Optical Character Recognition,简称OCR)工具包,支持简体中文、繁体中文(部分模型)、英文和数字的常见字符识别,支持竖排文字的识别。自带了20+个训练好的识别模型,适用于不同应用场景,安装后即可直接使用。同时,CnOCR也提供简单的训练命令供使用者训练自己的模型。
项目地址:https://github.com/breezedeus/cnocr
文档:https://cnocr.readthedocs.io/zh-cn/stable/
优点:轻量模型,执行速度快,效果好,支持训练自己的模型
缺点:部分符号识别效果差,部分场景下会出现空格丢失情况
部署:pip


7 RapidOCR
目前已知运行速度最快、支持最广,完全开源免费并支持离线快速部署的多平台多语言OCR。主打ONNXRuntime推理引擎推理,比Paddle推理引擎速度有4~5倍提升,且没有内存泄露问题。
项目地址:https://github.com/RapidAI/RapidOCR
部署:pip


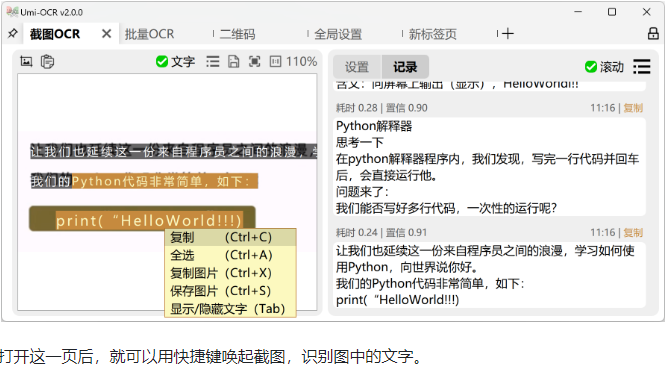
8 Umi-OCR
开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。
项目地址:https://github.com/hiroi-sora/Umi-OCR
9 SwiftOCR
项目地址:https://github.com/NMAC427/SwiftOCR
已被弃用,不再维护。