作者:Kai Shu and Huan Liu from Arizona State University
翻译:窦英通
本文长度为2000字,建议阅读5分钟
本文为你介绍社交媒体假新闻的描述和检测及未来研究方向。
社交媒体对新闻传播是一把双刃剑。一方面,它成本低廉,容易获取,而且通过快速的传播,它允许用户消费和分享新闻。另一方面,它可以产生有害的假新闻,即一些有意含有错误信息的低质量新闻。假新闻的快速传播对社会和个人有着巨大的潜在危害。
举个例子,在2016年美国总统大选中,最受欢迎的假新闻在 Facebook 上的传播范围要比主流媒体的新闻还要大。因此,社交媒体中的假新闻检测引起了研究者和政治家们的注意。
社交媒体的假新闻检测有着独特的特性而且呈现出新的挑战。
首先,假新闻的内容是被有意制造用来误导读者,这使得我们很难根据其新闻的内容来判断是否是假新闻。因此,我们需要类似用户在社交媒体上的活跃度等辅助信息来将假新闻从真新闻中区分出来。
第二,用户基于假新闻的社交活动产生了大量不完整、非结构化和充满噪声的数据,这使得利用这些数据变得非常困难。这篇快速指南是基于最近的一篇关于目前社交媒体假新闻检测最新研究成果、数据集和未来研究方向的综述。
Shu, Kai, et al. "Fake News Detection on Social Media: A Data Mining Perspective." ACM SIGKDD Explorations Newsletter 19.1 (2017): 22-36.
接下来,我们将强调这篇综述的主要内容。
描述和检测

图1 社交媒体假新闻检测:从描述到检测
图1是社交媒体假新闻检测的流程概览,包括了两个方面:描述和检测。随着时间的变化,不论报纸还是电台电视再到最近的在线新闻和社交媒体,假新闻其本身并不是一个新的问题。假新闻在传统媒介中的影响力可以用心理学和社会学的理论来解释。
举个例子,有两大心理学因素使得用户天生地倾向于相信假新闻。
-
朴素现实论(Naïve Realism):人们更倾向于将自己对现实的感知作为唯一的正确观点。
-
确认偏差(Confirmation Bias):人们更倾向于接收那些认同他们自己观点的信息。
另外一个例子,社会认同理论(Social Identity Theory)和规范影响理论(Normative Influence Theory)认为社交接受偏好对一个人的身份至关重要,这使得人们选择消费那些“社交安全的”新闻,即使这些被分享的新闻是假新闻。
社交媒体上的假新闻有其独特的特征。有害账户可以轻而易举得生产假新闻并促使其传播,例如聊天机器人,机器人账户和网络喷子。此外,由于社交媒体主页上新闻展示的方式,人们总是有选择性地看到特定种类的新闻。
因此,社交媒体上的用户倾向于和自己观点相同的人形成群组,这样他们的观点更容易极化,产生一种回声室效应(echo chamber effect)。(笔者注:回声室效应是指人际交流过程中,只承认或接受与自己的观点相近的回应)
上述理论在指导假新闻检测研究方面具有重要意义。
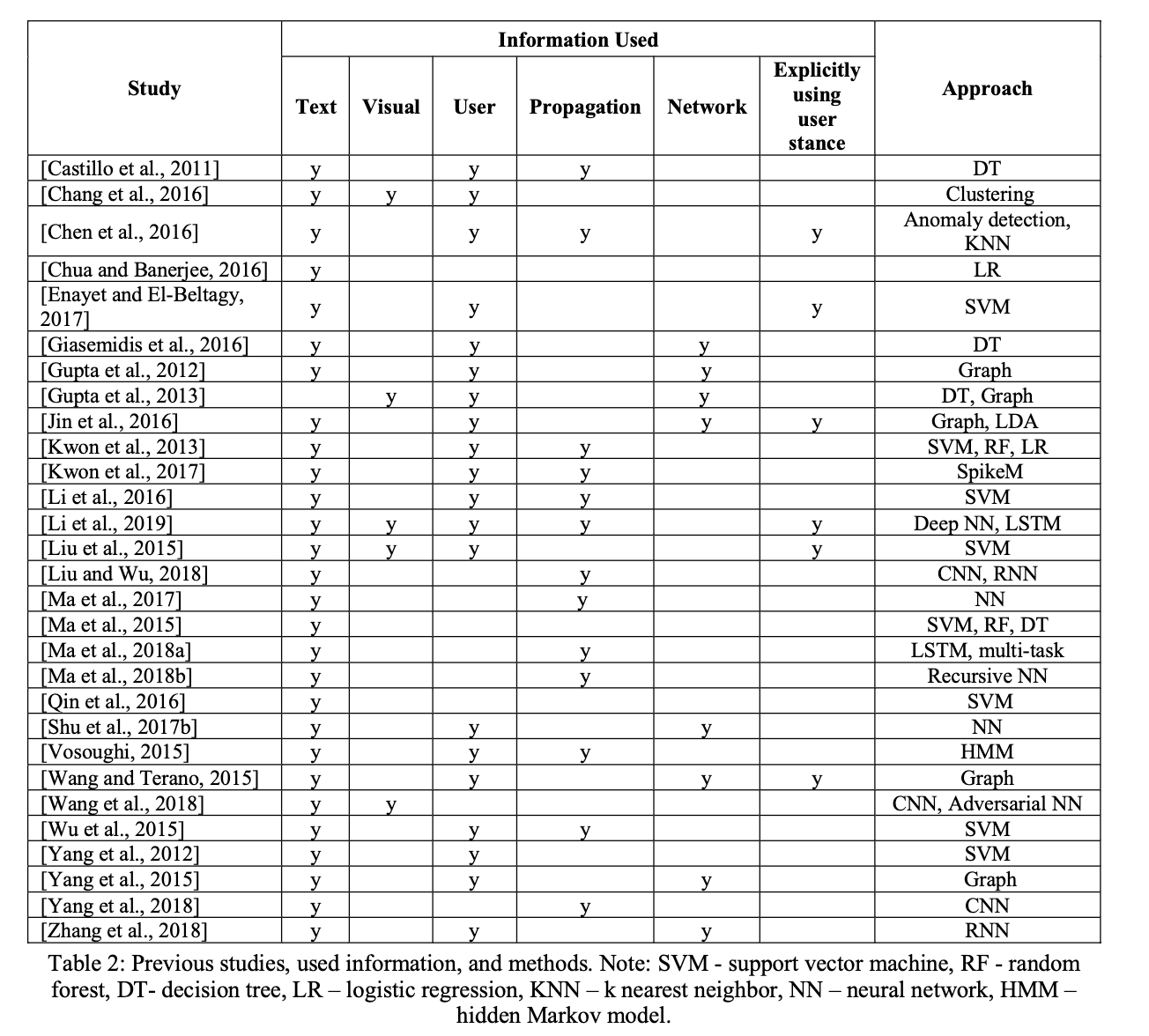
现有的假新闻检测算法一般可分为:基于新闻内容的和基于社会语境的。
-
基于新闻内容的方法着重于提取假新闻内容的各种特征,包括基于知识的和基于风格的特征。由于假消息试图传播虚假的观点,基于知识的方法旨在使用外部来源来检查新闻内容中的观点的真实性。此外,假新闻生产者往往恶意地传播歪曲和误导的新闻,这就需要特定的书写风格来吸引和说服广泛的新闻消费者。这些书写风格在真实的新闻文章中是看不到的。基于风格的方法尝试通过检测文章写作风格来检测假消息。
-
基于社会语境的方法旨在利用用户社交活动作为辅助信息来帮助检测假新闻。基于态度的方法利用用户对相关帖子内容的观点来推断原始新闻文章的真实性。另外,基于传播的方法也通过推断相关社交媒体推文的关系来引导可信分数的学习,可信分数在用户、评论和新闻之间进行传播。新闻稿的真实性是通过合成相关社会媒体推文的可信分数来衡量的。
数据集
即使可以从不同的来源收集在线新闻,手动确定新闻的真实性是一项具有挑战性的任务,通常需要具有领域专业知识的标注器来对观点、附加的证据、上下文和来自权威来源的报告进行仔细分析。
由于存在这些挑战,现有公开的假新闻数据集相当有限。 为便于假新闻检测的研究,该综述提供了一个名为FakeNewsNet的可用数据集,其中包含新闻内容和正确标注真假新闻标签的社会语境特征。
https://github.com/KaiDMML/FakeNewsNet

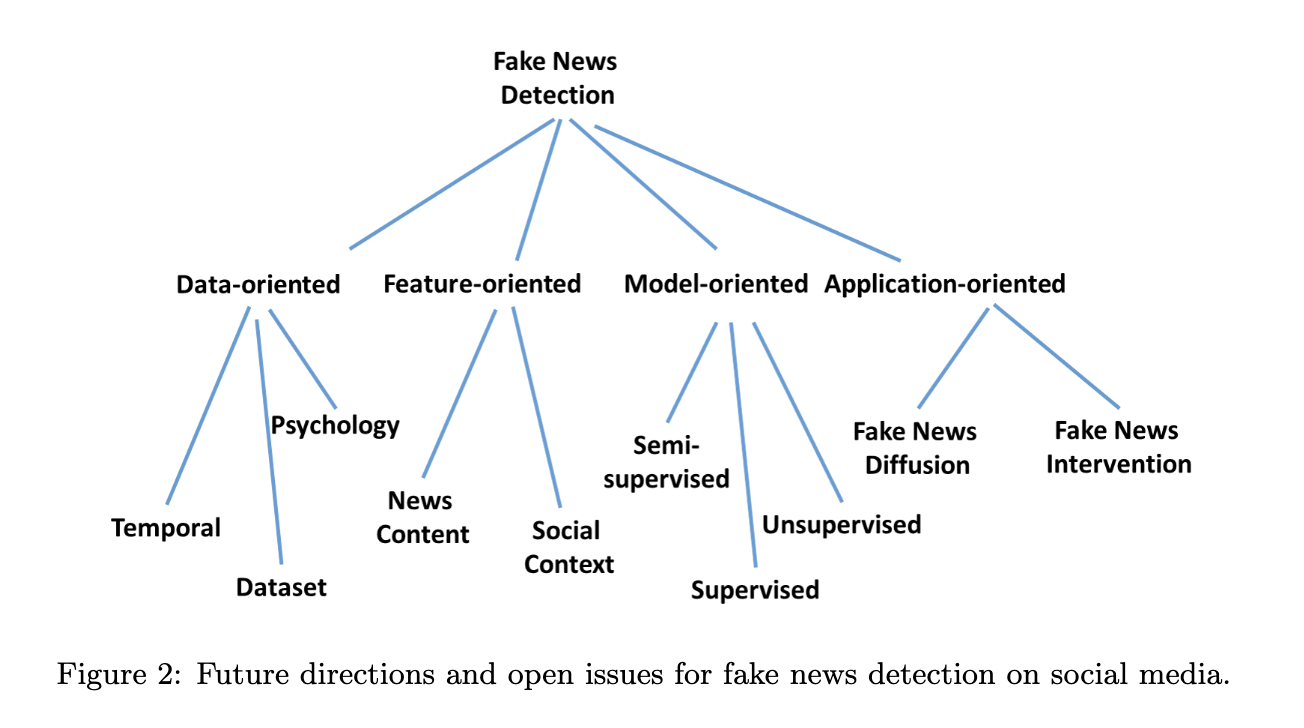
图2 社交媒体假新闻检测未来的研究方向和开放性问题
未来研究方向
社会媒体的虚假新闻检测是一个新兴的研究领域。该综述从数据挖掘的角度讨论了相关的研究领域,开放性问题和未来研究方向。如图2所示,研究方向从四个方面概述:数据导向的,特征导向的,模型导向的和应用导向的。
-
数据导向的:重点关注假新闻数据的不同方面,如基准数据收集,假新闻的心理验证和早期的假新闻检测。
-
面向特征的:旨在探索从多个数据源(如新闻内容和社会语境)中获取能检测假新闻的有效特征。
-
模型导向的:为了建立更实用和有效的假新闻检测模型,包括监督,半监督和无监督的模型。
-
面向应用的:它包含了超越假新闻检测的研究,如假新闻的扩散和干预。
原文标题:
A Quick Guide to Fake News Detection on Social Media
原文地址:
https://www.kdnuggets.com/2017/10/guide-fake-news-detection-social-media.html
编辑:黄继彦

窦英通,北京邮电大学大四学生,数据挖掘入门研究者,对社交网络分析,社交媒体挖掘,推系统感兴趣,致力于通过机器学习技术发现其余领域有价值的信息。喜欢新鲜的事物,希望在数据派中分享、交流、成长!
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载文章,请做到 1、正文前标示:转自数据派THU(ID:DatapiTHU);2、文章结尾处附上数据派二维码。
申请转载,请发送邮件至datapi@tsingdata.com


点击“阅读原文”加入组织~