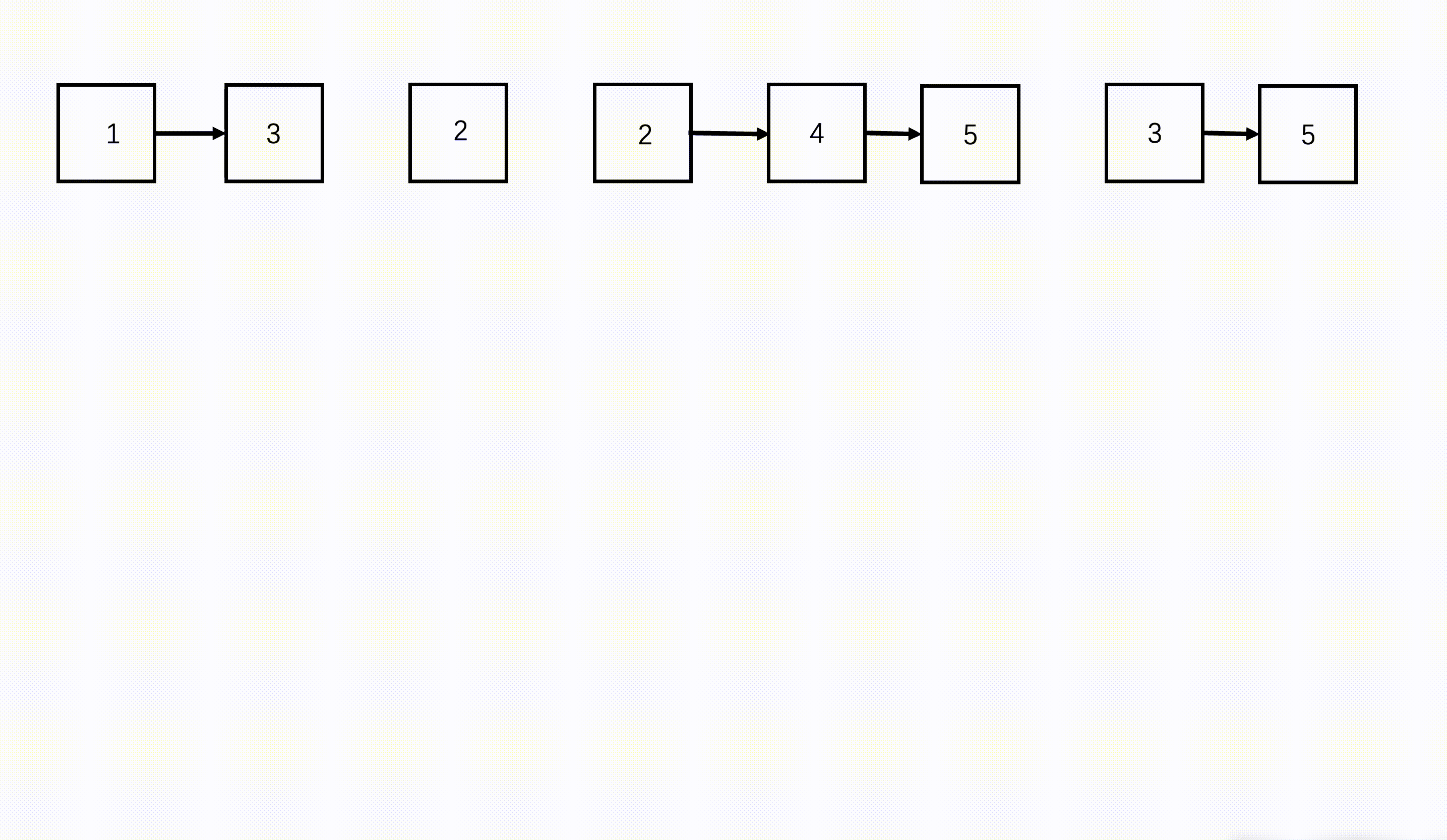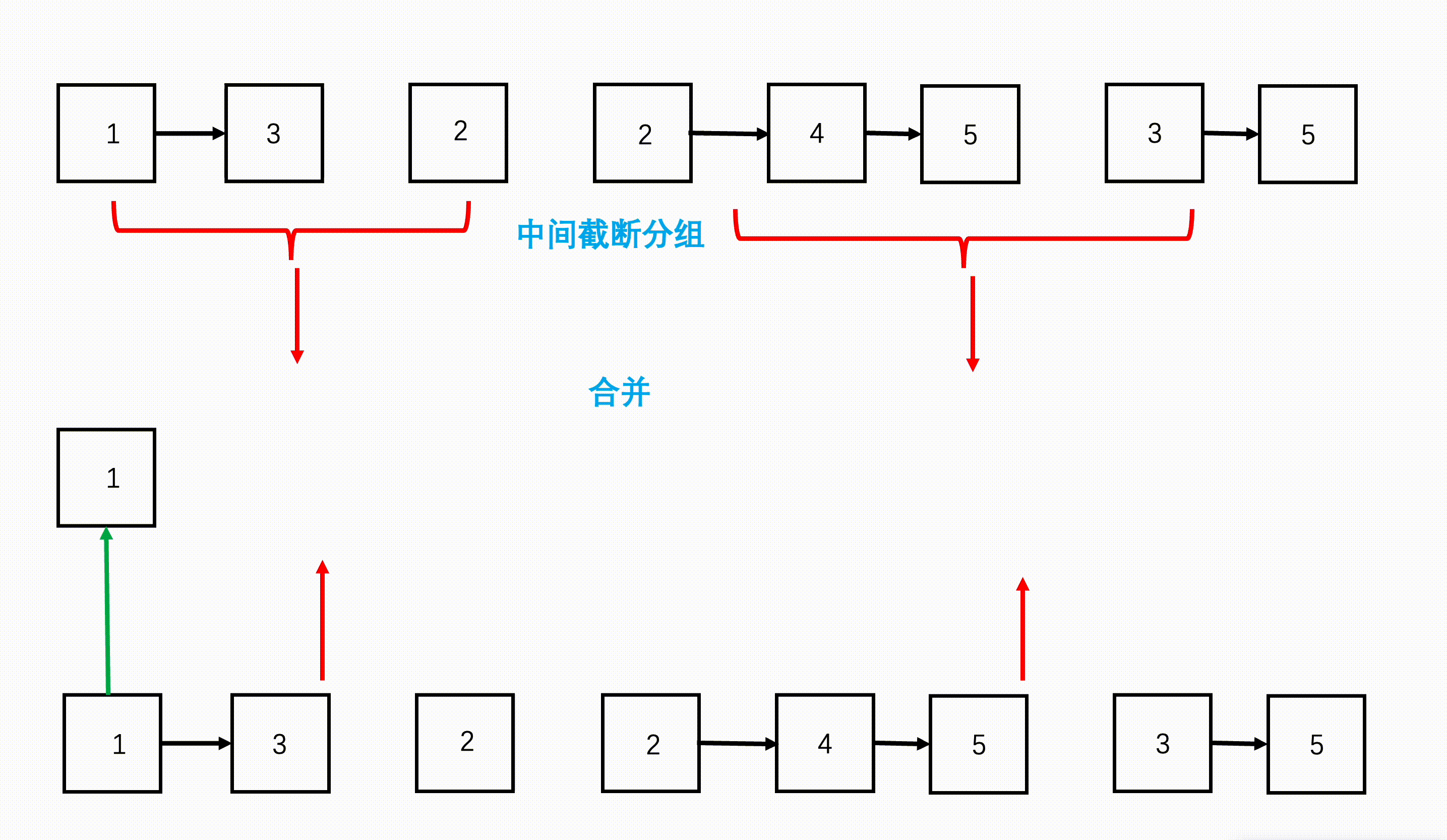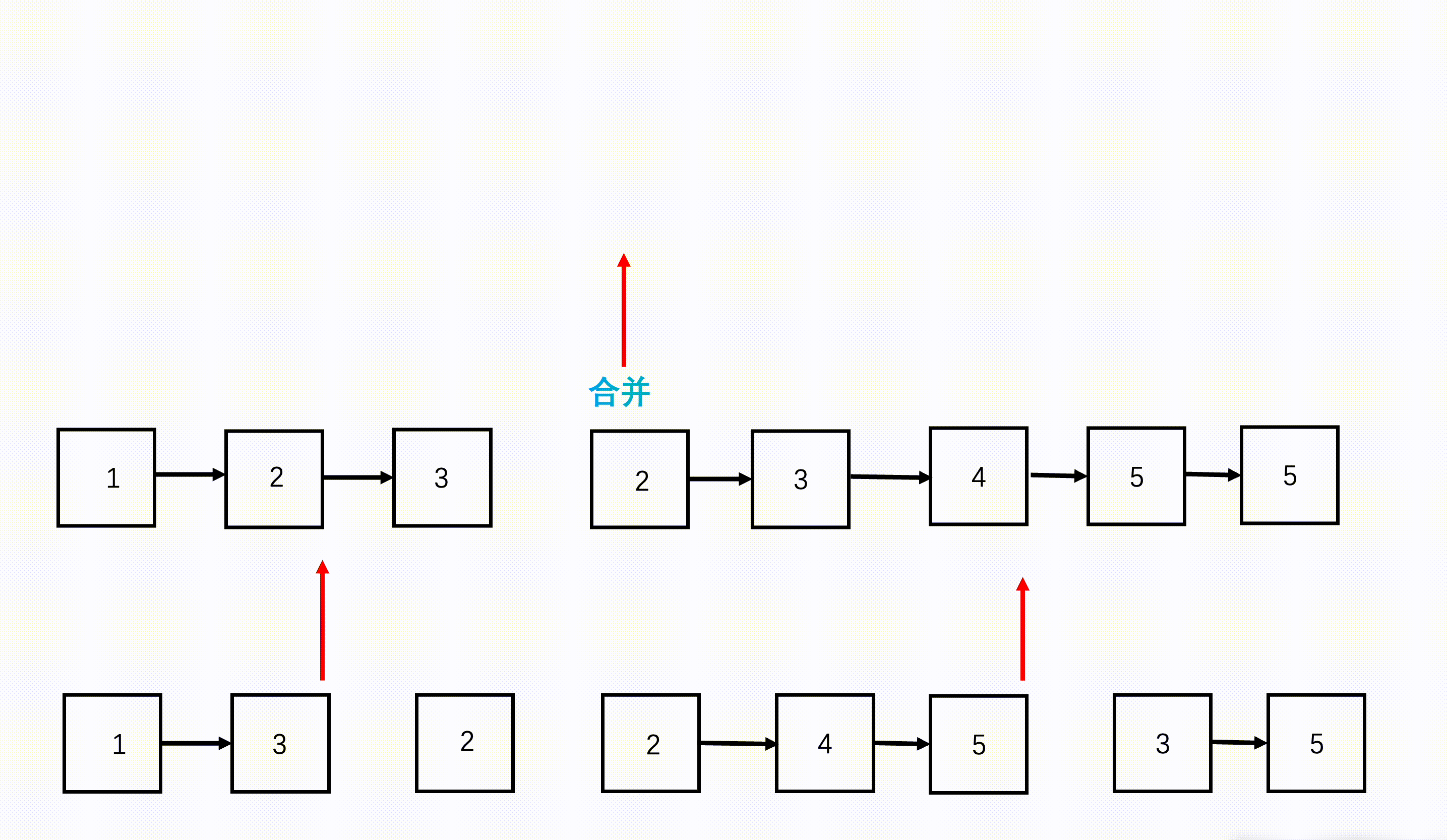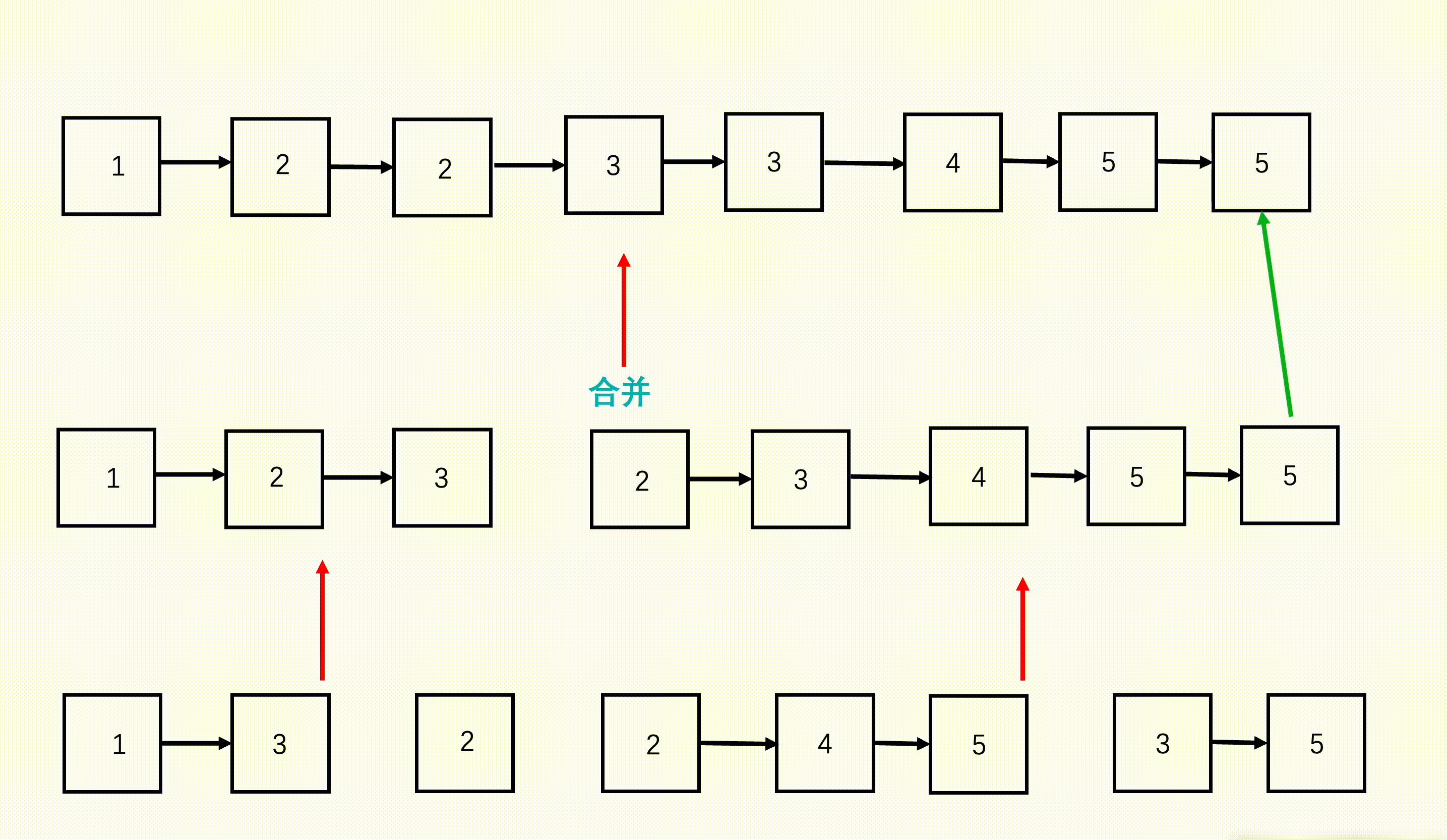摘要
现象:当前的大预言模型可以接受超过100,000个tokens的输入,但是却难以生成超过2000个token的输出。
原因:监督微调过程(SFT)中看到的样本没有足够长的样本。
解决方法:
- Agent Write,可以将长任务分解为子任务,从而实现可以生成超过20,000字的输出,它根据用户的输入编写了一个详细的写作计划,列出每个段落的结构和目标字数,之后以顺序的方式生成每个段落的内容。
- 利用管道,在GPT-4o上建立了数据集:Long Writer-6k,包含6000个长度从2k到32k的数据。使得现有模型能够输出超过10,000字。
- Longbench-Write,一个基准,用于评估超长文本的生成能力。包含一组不同的用户编写指令,输出长度规格从0-500字,500-2000字,2000-4000字,超过4000字,
结果:9B参数的模型已经可以在 benchmark上取得最佳效果,只需要在模型对齐过程中具有扩展数据。
Agent Write
- 计划
受人类作家思维过程的启发,一个作家通常会为了长时间的写作任务制作一个总体计划,通常包括每个章节的写作计划与大纲,我们利用LLM的规划能力创作了一个写作大纲,给出一个写作指令。

- 写
在生成文本的时候,我们也会将前n-1段文本的内容输入进去,这种串行输入的方式生成的内容远远优于并行文本的输出。 - 检验
检验分为两个方法,分别是LongWrite-Ruler,用于检测一个输出模型可以输出的长度可以为多少;Longbench-Writer,这是我们自己构建的benchmark,用于评估生成内容在指令方面以及和用户指令的一致性程度。
Longbench-Write
为了评估性能,我们收集了120个用户书写提示,60个中文,60个英文,每个都包含了明确的字数要求,分为4个子集,分别为0-500个字,500-2000个字,2000-4000个字,超过4000个字。此外,我们根据输出内容,将文本分为7种类型,文学和创意写作、学术和专著、大众科学、功能写作、新闻报道、社区论坛和教育和培训。
Evaluation
在评估方面,分为两个方面,一个是文章长度是否达标,另一个是文章的质量,文章的长度决定了分数所在的不同的分段函数。

在具体评价质量方面,采用先进的GPT-4o模型,分别从相关性、准确性、一致性、清晰度、广度和深度以及阅读体验几个部分对于文章进行打分,最后取平均。
结果

LongWriter:用于生成超长输出的教学数据集及训练
我们已经有了Agent Write,可以生成长文本了,现在我们好奇是否能够利用它生成数据集,从而让大模型能够自己生成长文本。
数据集构建
我们从GPT-4o的SFT中选取了3000条中文指令,从WildChat-1M中选取了3000条英文指令,我们进一步应用基于规则的匹配来过滤掉有毒指令和原本打算用于抓取的指令,经检查发现,这6000条有95%以上需要几千字的响应。再过滤和清除掉无关内容后,构建了数据集LongWriter-6k,输出长度相对均匀地分布在2k至10k之间。一般训练的时候会将LongWriter-6k和别的数据集混合,从而弥补了2k以上的稀缺性。
模型训练
- 监督微调
我们基于两个最新的开源模型,GLM-4-9B和 Llama-3.1-8B进行微调,得到了LongWriter-8B和LongWriter-9B。 - 对齐(DPO)
为了进一步提高模型质量,我们对LongWrtier-9B进行了偏好优化。DPO数据来自GLM-4聊天数据,大约5w个;我们还额外构建了四千对针对长篇书写的数据。对于每个指令,我们从LongWriter-9B中抽取四个输出,从中取得最好的一个作为正样本,从其它三个中随机选取一个作为负样本。DPO差不多能给模型提高3%到4%的效果。 - 结果