随着深度学习的不断进步,语言模型的规模越来越大,参数量级已经达到了数千亿甚至数万亿,参数规模的指数增长带来了两个巨大的挑战
1)模型参数过大,如GLM 130B模型参数需要520GB(130B*4bytes)的显存,参数梯度为520GB,优化器状态需要1040GB,共计2096GB的显存,即使显存最大的GPU也放不下大模型的模型参数;
2)即使可以将模型参数放在一张GPU上,对海量数据进行预训练也需要耗费很长时间,单卡如A100训练130B参数量的模型大约需要232年。分布式预训练技术,就是在这样的背景下应运而生,它允许模型在多个计算节点上并行训练,大幅度缩短了训练时间,本文总结了目前常见的分布式训练的常见方法。
1分布式训练
1
数据并行
数据并行指的是数据集切分为多份,每张GPU分配不同的数据进行训练,每个进程运行完整模型,在每个进程上独立运行前向和反向过程,最后通过AllReduce操作,将多张卡上的梯度进行同步。
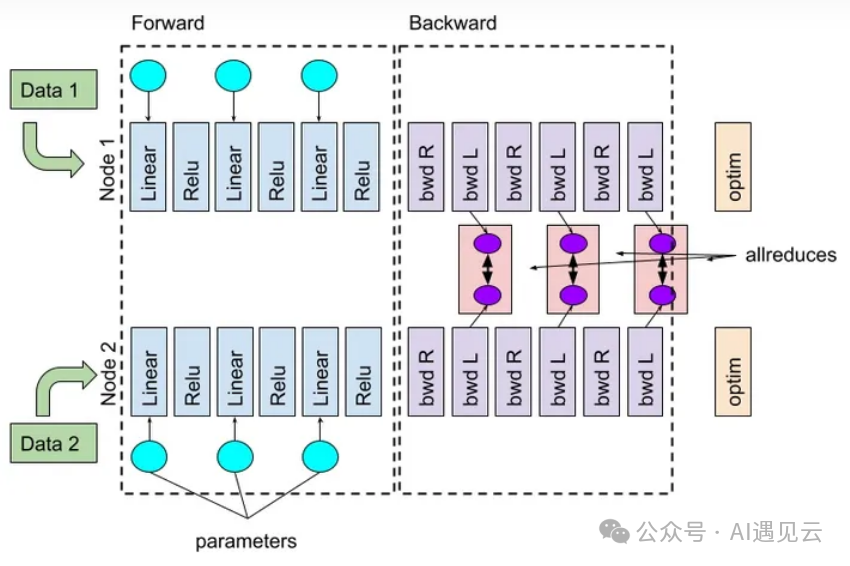
▲ 图1 数据并行
2
张量并行
张量并行是指将一个独立的层划分到不同的GPU上,例如用两块GPU实现一个并行的GEMM矩阵乘法运算Y=X*W,可以将X和W分别沿着列方向和行方向切分成两份,通过矩阵乘法的分块规则,分别在每个GPU上做子矩阵乘法,然后将两个子矩阵乘法结果相加得到最终结果
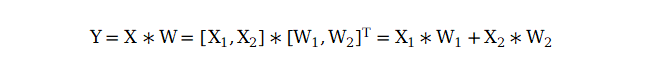
针对transformer模型MLP的张量并行实现方式图2所示,第一个GEMM输入X不做切分,直接通过f操作拷贝到两个GPU上,权重A沿列方向进行切分,每个GPU上保存一半的运算结果,通过GELU运算得到Y1和Y2。第二个GEMM由于Y1和Y2已经分别存在于两个GPU上,相当于已经做了沿列方向的切分,所以对权重B做行方向的切分,分别进行矩阵乘法得到Z1和Z2,g操作是一个AllReduce操作,用来实现公式中的加法,AllReduce之后,每个GPU上都有一份完整的Z矩阵。
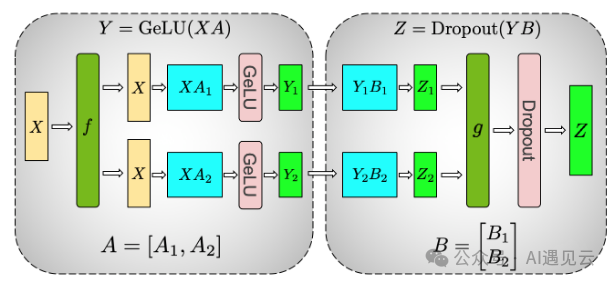
▲ 图2 MLP张量并行
针对transformer模型Atttention的张量并行如图3所示,QKV的三个矩阵的权重shape均为是[dim, head_humhead_dim],考虑到多头注意力天然的并行性,可以将三个权重沿着列方向进行切分,每张卡上权重的shape为[dim, head_humhead_dim/N],每张卡上不同部分head的softmax等计算式互相独立,分别得到Y1和Y2,再对输出的权重 B沿着行方向切分,得到计算结果Z1和Z2,再通过g做AllReduce操作得到最终的Z。可以看到,每张卡上做的仍然是一个完整的Attention运算,只是head number变为了原来的1/N。
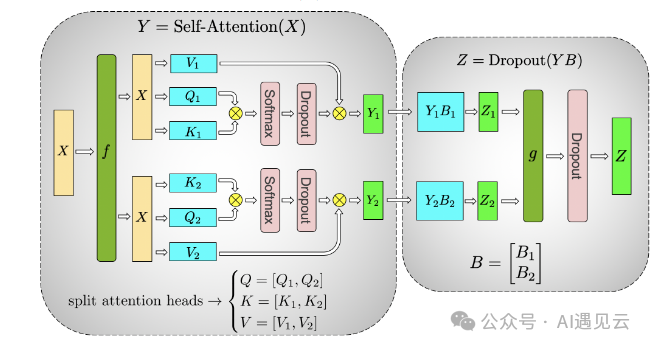
▲ 图3 Attention 张量并行
3
流水线并行
流水线并行是指将不同的layer划分到不同的GPU上,为了提升节点的利用率,将一个batch,继续拆分为 M 个micro batch,当节点1计算完第一个micro batch, 节点2开始计算后,节点 1可以继续计算第二个micro batch,对于P个节点,M个micro batch的流水线并行,流水线气泡占比为(P-1)/M,为减少气泡占比,需保证M>>P。
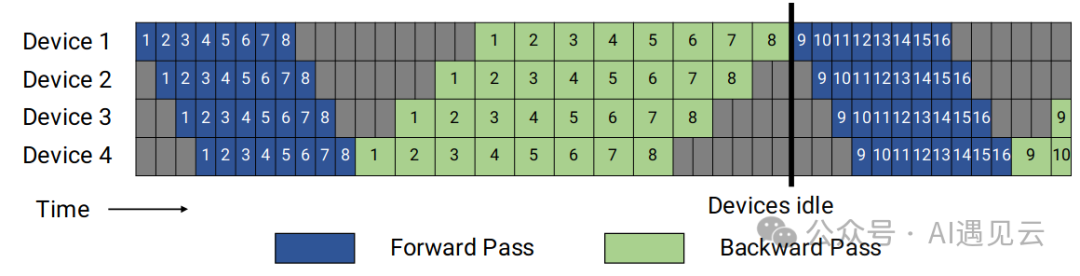
▲ 图4 流水线并行
4
序列并行
序列并行是在 张量的基础上,将 Transformer 层中的 LayerNorm 以及 Dropout 的输入按输入长度(Sequence Length)维度进行了切分,使得各个设备上面只需要做一部分的 Dropout 和 LayerNorm,LayerNorm 和 Dropout 的计算被平摊到了各个设备上,减少了计算资源的浪费,进一步降低了显存开销。
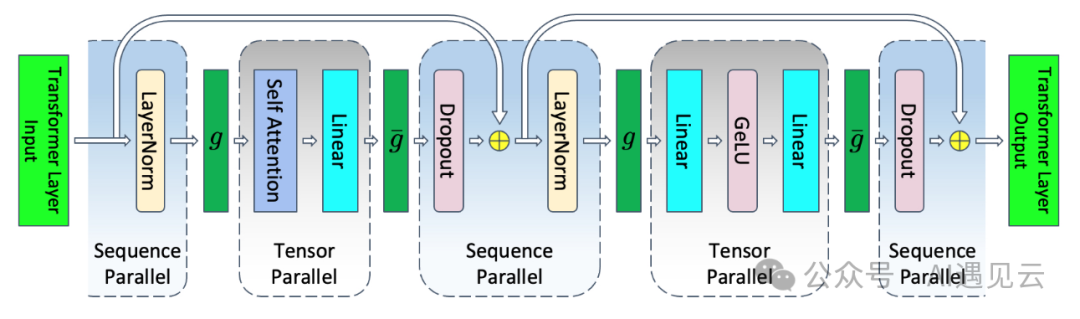
▲ 图5 序列并行
4
激活重计算
激活重计算是指在前向计算时,只把检查点节点保存在显存中,检查点以外的中间值全部被丢弃,在方向传播计算梯度时,从最近的检查点开始,其余节点重新计算一次前向,激活重计算需要额外的计算,是一个以时间换空间的策略。
5
ZeRO零冗余优化器
数据并行在通信和计算效率上表现良好,但存在内存冗余问题,ZeRO通过分区参数和状态来减少冗余,使每个GPU只保留部分数据。图6展示了启用内存优化后各设备的内存消耗,其中Ψ代表模型大小,K是优化器状态的内存乘数,Nd是数据并行度。
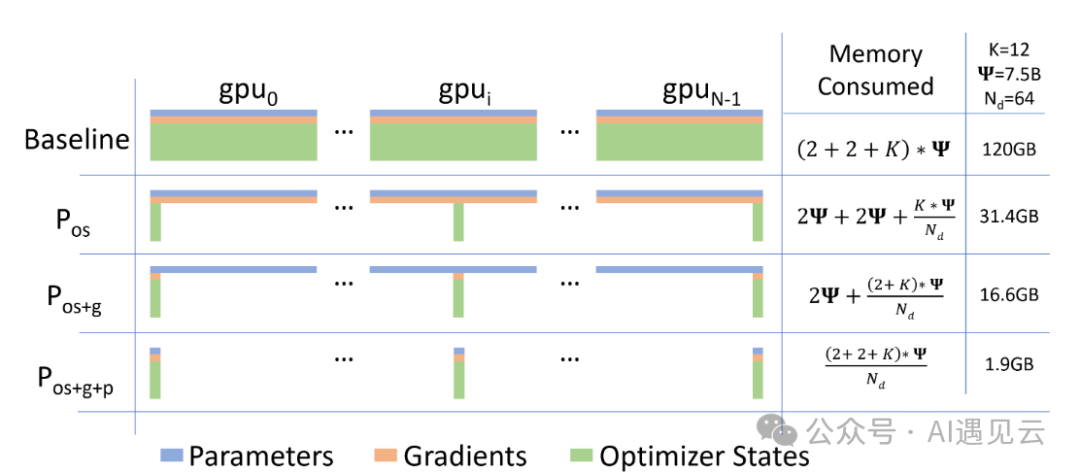
▲ 图6 ZeRO零冗余优化
假设模型大小为Ψ=75亿,基于Adam优化器的混合精度训练,数据并行度为Nd=64,K=12,我们在数据并行的基础上,分三步对显存进行优化
Pos(优化器状态优化)
我们在每个GPU中保存全部的参数和梯度,但是只保存1/Nd的优化器状态,这会导致总的显存消耗变为2Ψ+2Ψ+KΨ/Nd , 在图示假设下为显存占用31.4GB。
Pos+g(优化器状态和梯度优化)
优化器状态优化的基础上增加对梯度内存的优化,即每个GPU中只保存1/Nd的梯度,这会导致总的显存消耗变为2Ψ+(2Ψ+KΨ)/Nd , 在图示假设下为显存占用为16.6GB。
Pos+g+p(优化器状态、梯度以及参数优化)
优化器状态和梯度优化的基础上增加对参数显存的优化,即每个GPU中只保存1/Nd的参数,这将导致总的内存消耗变为(2Ψ+2Ψ+KΨ)/Nd ,在图示假设下为显存占用为1.9GB。
2
讨论与展望
未来的LLM可能会采用更先进的并行策略,以进一步减少通信开销并提高计算效率。例如探索使用分层并行策略,将模型的不同层次分布在不同的节点上进行训练,以减少节点间的通信需求。此外,还可以结合使用数据并行和模型并行的方法,根据硬件环境和模型规模灵活调整并行策略。分布式预训练技术的发展为大规模智算平台提供了有效支撑,但仍然面临非常大挑战,通过精心设计解决方案并不断探索新的并行策略,我们可以进一步提高分布式预训练的效率和可扩展性,为构建更大规模的模型提供支持。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。