本文重点介绍索引中的常见概念:回表查询、索引覆盖、索引下推
一、回表查询
我们首先理解:在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 (Clustered Index) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引 (Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引
聚集索引和二级索引的具体结构如下:
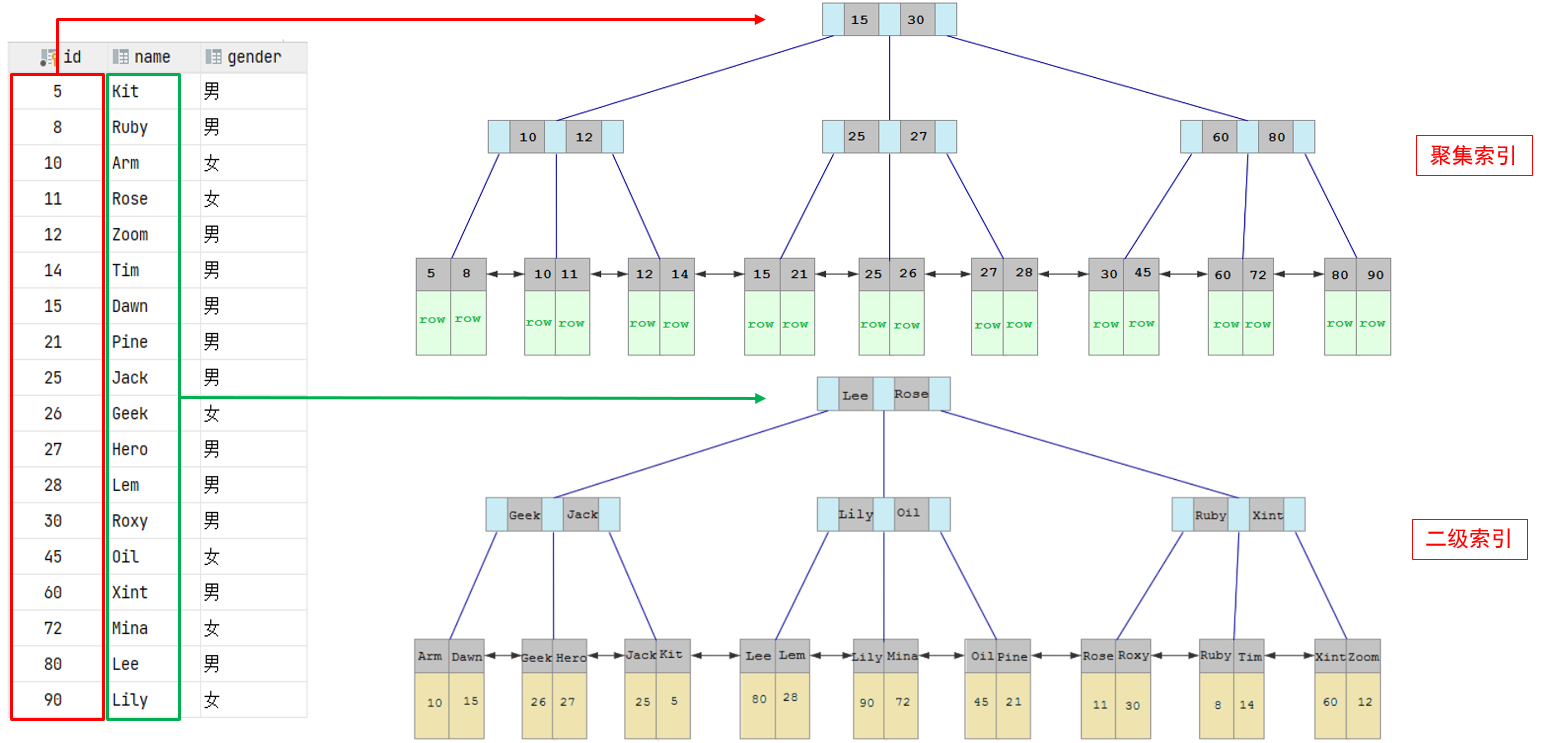
- 聚集索引的叶子节点下挂的是这一行的数据 。
- 二级索引的叶子节点下挂的是该字段值对应的主键值
接下来,我们来分析一下,当我们执行如下的SQL语句时,具体的查找过程是什么样子的。
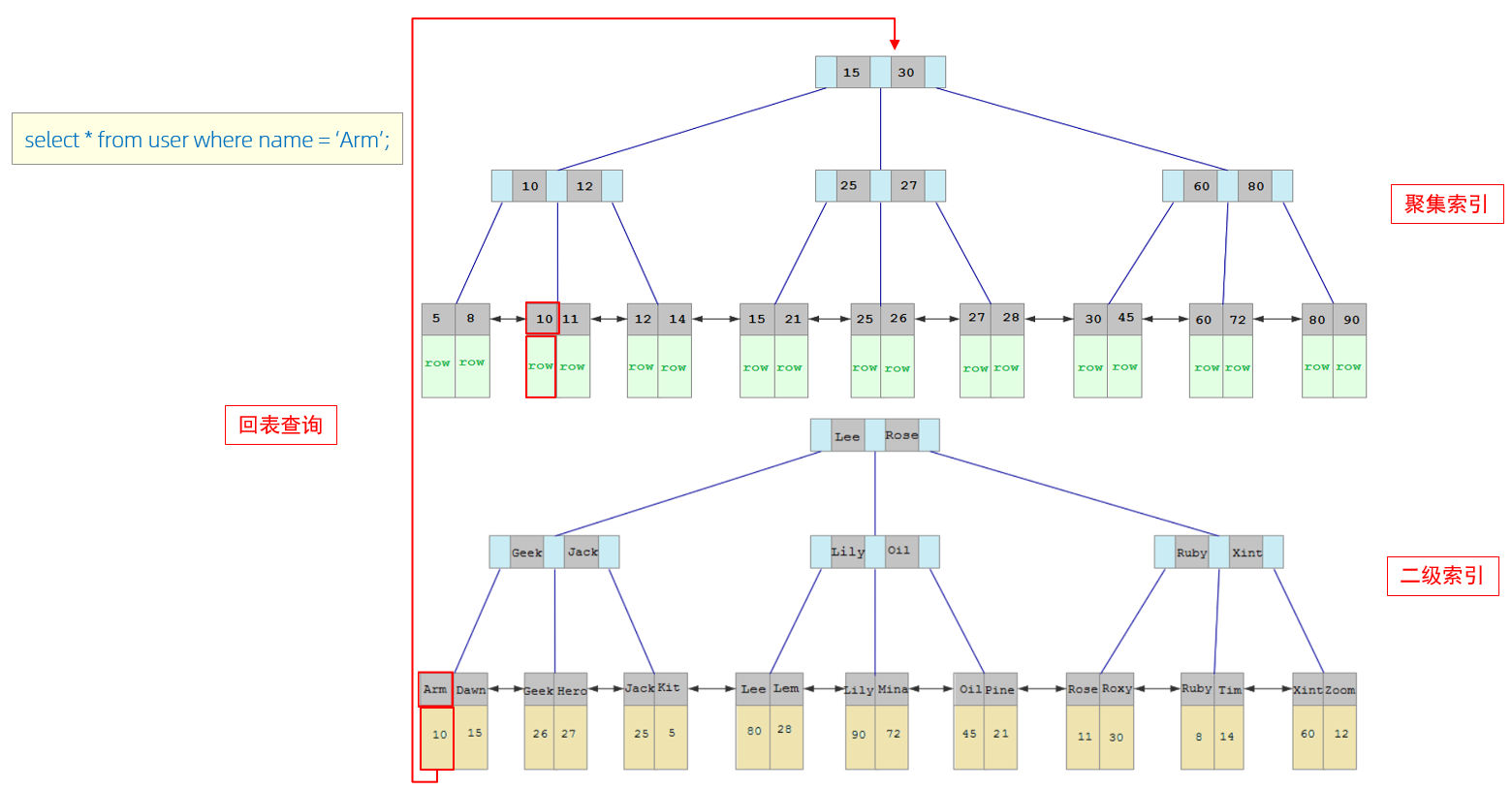
具体过程如下:
- ①. 由于是根据name字段进行查询,所以先根据name='Arm’到name字段的二级索引中进行匹配查找。但是在二级索引中只能查找到 Arm 对应的主键值 10。
- ②. 由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最终找到10对应的行row。
- ③. 最终拿到这一行的数据,直接返回即可。
得到回表查询的概念:
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取数据的方式,就称之为回表查询。
以下两条SQL语句,那个执行效率高? 为什么?
-- A语句
-- 备注: id为主键,name字段创建的有索引;
select * from user where id = 10 ;
-- B语句
select * from user where name = 'Arm' ;
A 语句的执行性能要高于B 语句。
因为A语句直接走聚集索引,直接返回数据。 而B语句需要先查询name字段的二级索引,然后再查询聚集索引,也就是需要进行回表查询。
二、索引覆盖
索引覆盖(Index Covering)是指通过在索引中包含所有查询语句中所需的列,可以避免对表中的数据进行额外的访问,从而提高查询效率。(避免了回表操作)
例如,对于一个查询语句:
SELECT col1, col2, col3 FROM table WHERE col1 = x AND col2 = y
如果在table表中建立了一个索引,包含col1、col2和col3三列,那么MySQL可以通过索引定位到符合条件的数据,并在索引中提取col1、col2和col3列的值,无需对表中的数据进行额外的访问。这种方式就叫做索引覆盖。
索引覆盖能够显著提高查询效率,因此在建立索引时应尽量考虑包含查询语句中所需的所有列。
我们实际性进行测试:
-- 创建数据库
CREATE DATABASE IndexCoveringDemo;
USE IndexCoveringDemo;-- 创建表
CREATE TABLE employees (id INT PRIMARY KEY AUTO_INCREMENT,first_name VARCHAR(50),last_name VARCHAR(50),department VARCHAR(50),salary DECIMAL(10, 2),INDEX idx_name_department_salary (first_name, department, salary)
);
-- 插入随机数据
INSERT INTO employees (first_name, last_name, department, salary)
VALUES
('John', 'Doe', 'Engineering', 75000.00),
('Jane', 'Smith', 'Marketing', 55000.00),
('Alice', 'Johnson', 'Sales', 60000.00),
('Bob', 'Brown', 'Engineering', 80000.00),
('Charlie', 'Davis', 'HR', 50000.00),
('Emily', 'Wilson', 'Sales', 65000.00),
('David', 'Clark', 'Engineering', 70000.00),
('Frank', 'Moore', 'Marketing', 52000.00),
('Grace', 'Taylor', 'HR', 48000.00),
('Henry', 'Miller', 'Sales', 72000.00);
假设我们要查询Engineering部门中first_name和salary,我们可以利用之前创建的复合索引来进行索引覆盖查询。
EXPLAIN SELECT first_name, salary FROM employees WHERE department = 'Engineering';

在这个查询中,first_name和salary两个字段都包含在索引idx_name_department_salary中,department字段是索引的一部分。这个查询将可以通过索引直接返回数据,而不需要访问实际的表数据。
如果我们查询的字段不完全包含在索引中,则MySQL将无法进行索引覆盖,需要访问表数据。
EXPLAIN SELECT first_name, last_name FROM employees WHERE department = 'Engineering';
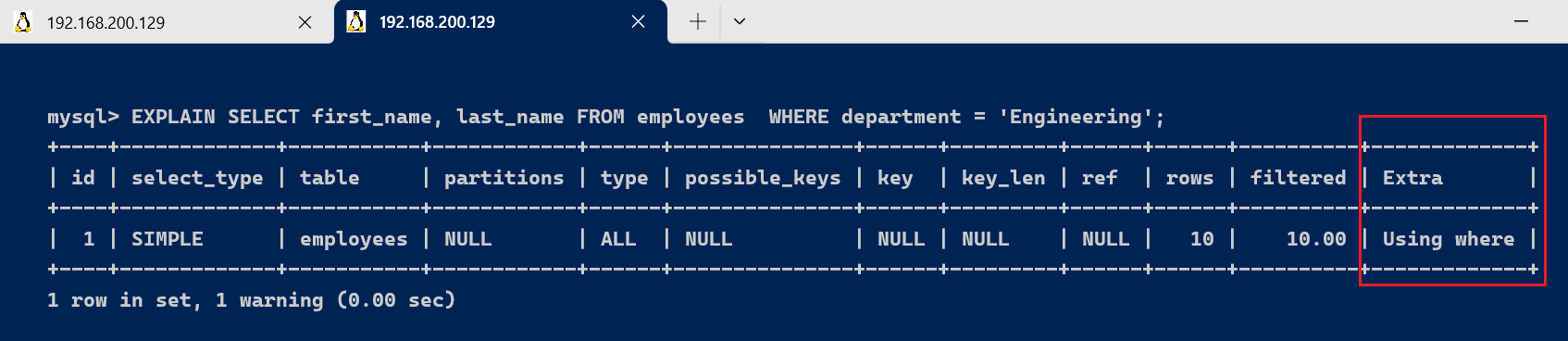
在这个查询中,last_name字段不在索引idx_name_department_salary中,因此MySQL不能使用索引覆盖查询。
索引覆盖能够显著提升查询性能,尤其是在涉及大量数据时。通过合理设计复合索引,可以使查询仅通过索引就能返回所有所需的数据,从而减少磁盘I/O并加快查询速度。在设计索引时,需要权衡字段选择,确保常用查询尽可能通过索引覆盖来优化。
三、索引下推
索引下推(INDEX CONDITION PUSHDOWN,简称 ICP)是在 MySQL 5.6 针对扫描二级索引的一项优化改进。总的来说是通过把索引过滤条件下推到存储引擎,来减少 MySQL 存储引擎访问基表的次数以及 MySQL 服务层访问存储引擎的次数。ICP 适用于 MYISAM 和 INNODB,本篇的内容只基于 INNODB。
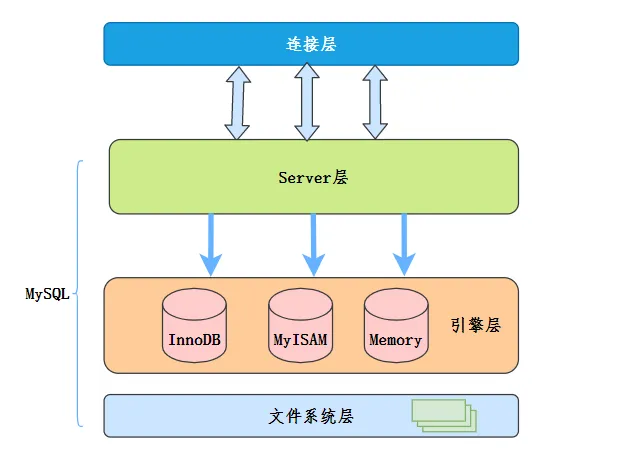
- MySQL 服务层:也就是 SERVER 层,用来解析 SQL 的语法、语义、生成查询计划、接管从 MySQL 存储引擎层上推的数据进行二次过滤等等。
- MySQL 存储引擎层:按照 MySQL 服务层下发的请求,通过索引或者全表扫描等方式把数据上传到 MySQL 服务层。
- MySQL 索引扫描:根据指定索引过滤条件,遍历索引找到索引键对应的主键值后回表过滤剩余过滤条件。
- MySQL 索引过滤:通过索引扫描并且基于索引进行二次条件过滤后再回表。

- 使用索引下推实现

索引下推的使用条件
- ICP目标是减少全行记录读取,从而减少IO 操作,只能用于非聚簇索引。聚簇索引本身包含的表数据,也就不存在下推一说。
- 只能用于range、 ref、 eq_ref、ref_or_null访问方法;
- where 条件中是用 and 而非 or 的时候。
- ICP适用于分区表。
- ICP不支持基于虚拟列上建立的索引,比如说函数索引
- ICP不支持引用子查询作为条件。
- ICP不支持存储函数作为条件,因为存储引擎无法调用存储函数。
索引下推相关语句:
# 查看索引下推是否开启
select @@optimizer_switch
# 开启索引下推
set optimizer_switch="index_condition_pushdown=on";
# 关闭索引下推
set optimizer_switch="index_condition_pushdown=off";
我们来进行具体的测试:
CREATE DATABASE icp_demo;
USE icp_demo;CREATE TABLE employees (emp_id INT AUTO_INCREMENT PRIMARY KEY,emp_name VARCHAR(255),dept_id INT,salary DECIMAL(10, 2),hire_date DATE,INDEX idx_dept_salary (dept_id, salary)
) ENGINE=InnoDB;
DELIMITER $$
CREATE PROCEDURE populate_employees()
BEGINDECLARE i INT DEFAULT 1;WHILE i <= 100000 DOINSERT INTO employees (emp_name, dept_id, salary, hire_date) VALUES (CONCAT('Employee_', i), FLOOR(RAND() * 10), ROUND(RAND() * 100000, 2), CURDATE() - INTERVAL FLOOR(RAND() * 3650) DAY);SET i = i + 1;END WHILE;
END$$
DELIMITER ;
CALL populate_employees();
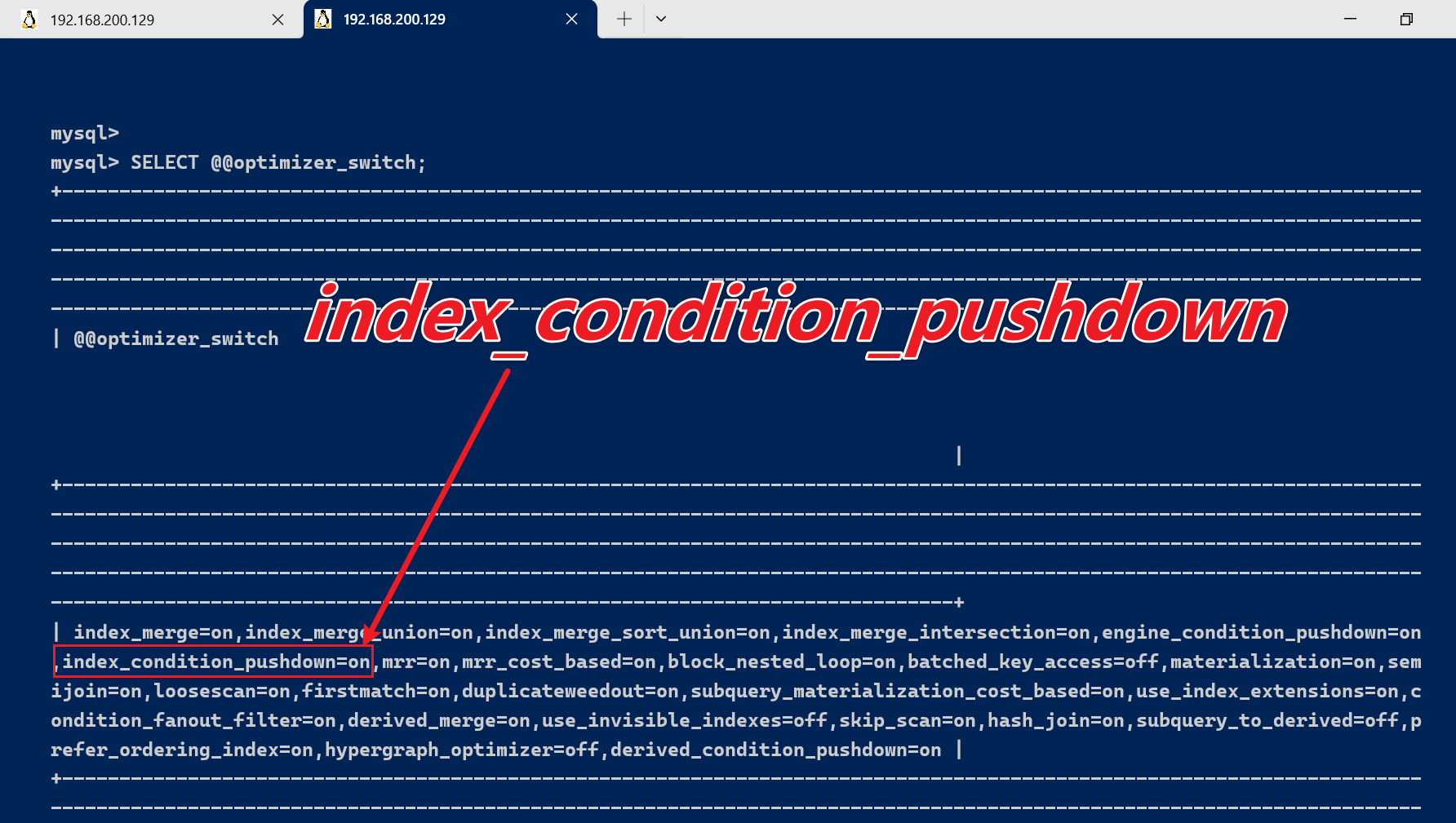
在执行查询之前,我们可以先查看索引下推是否开启。
SELECT @@optimizer_switch;
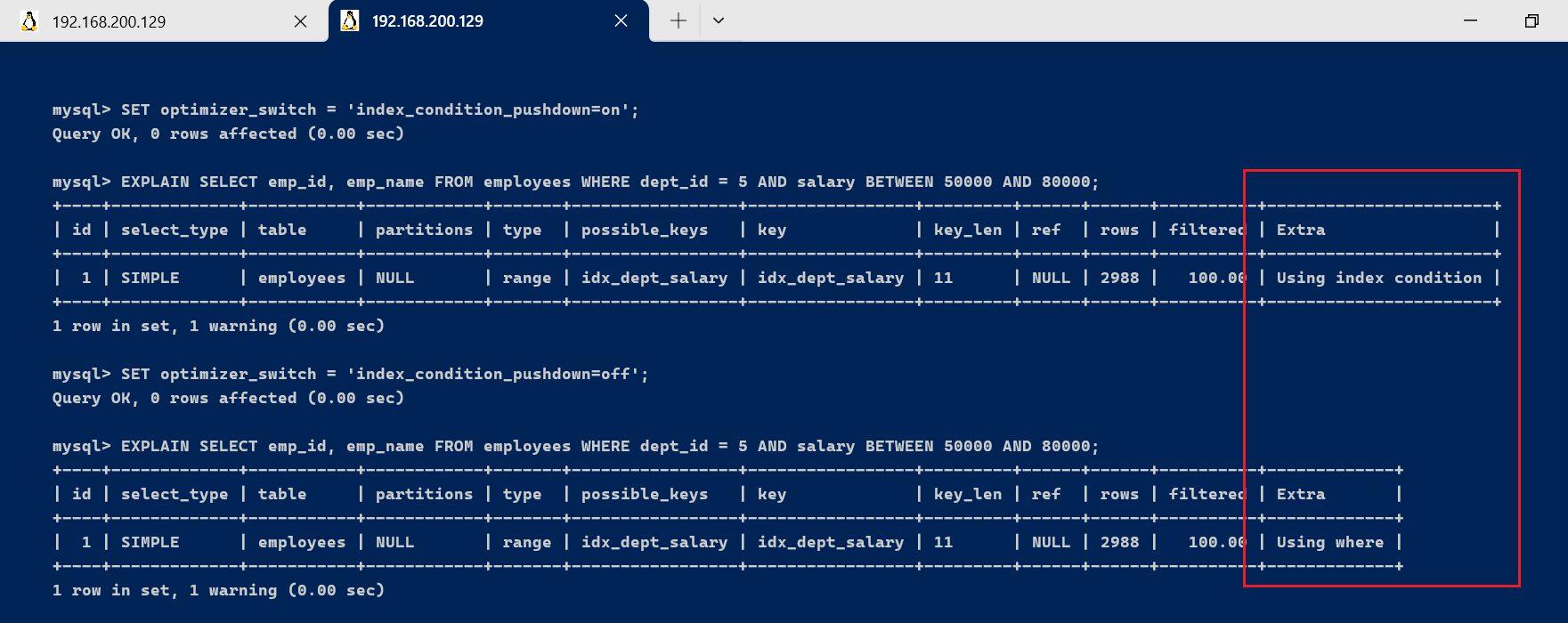
SET optimizer_switch = 'index_condition_pushdown=on';
EXPLAIN SELECT emp_id, emp_name FROM employees WHERE dept_id = 5 AND salary BETWEEN 50000 AND 80000;
SET optimizer_switch = 'index_condition_pushdown=off';
EXPLAIN SELECT emp_id, emp_name FROM employees WHERE dept_id = 5 AND salary BETWEEN 50000 AND 80000;
记得再次打开:
SET optimizer_switch = 'index_condition_pushdown=on';
https://mp.weixin.qq.com/s?__biz=MzkwOTczNzUxMQ==&mid=2247484267&idx=1&sn=be0d6295a3992d13d76dc4d6c5b34ba6&chksm=c1376823f640e135895626711aadd115d0d40ff77a3f40157130b4199e4487b894414b5795be#rd