简介
在计算机视觉和深度学习项目中,数据增强是一种常用的技术,通过对原始图像进行多种变换,可以增加数据集的多样性,从而提高模型的泛化能力。本文将介绍如何使用 Python 和 OpenCV 实现图像的亮度增强,并将增强后的图像与对应的注释文件批量复制到新目录中。
项目背景
假设你有一个数据集,包含若干图像及其对应的 XML 注释文件和标签文件。在模型训练前,你希望对这些图像进行亮度增强,并生成新的图像及其对应的注释文件和标签文件。本教程将指导你如何编写一个 Python 脚本,实现此功能。
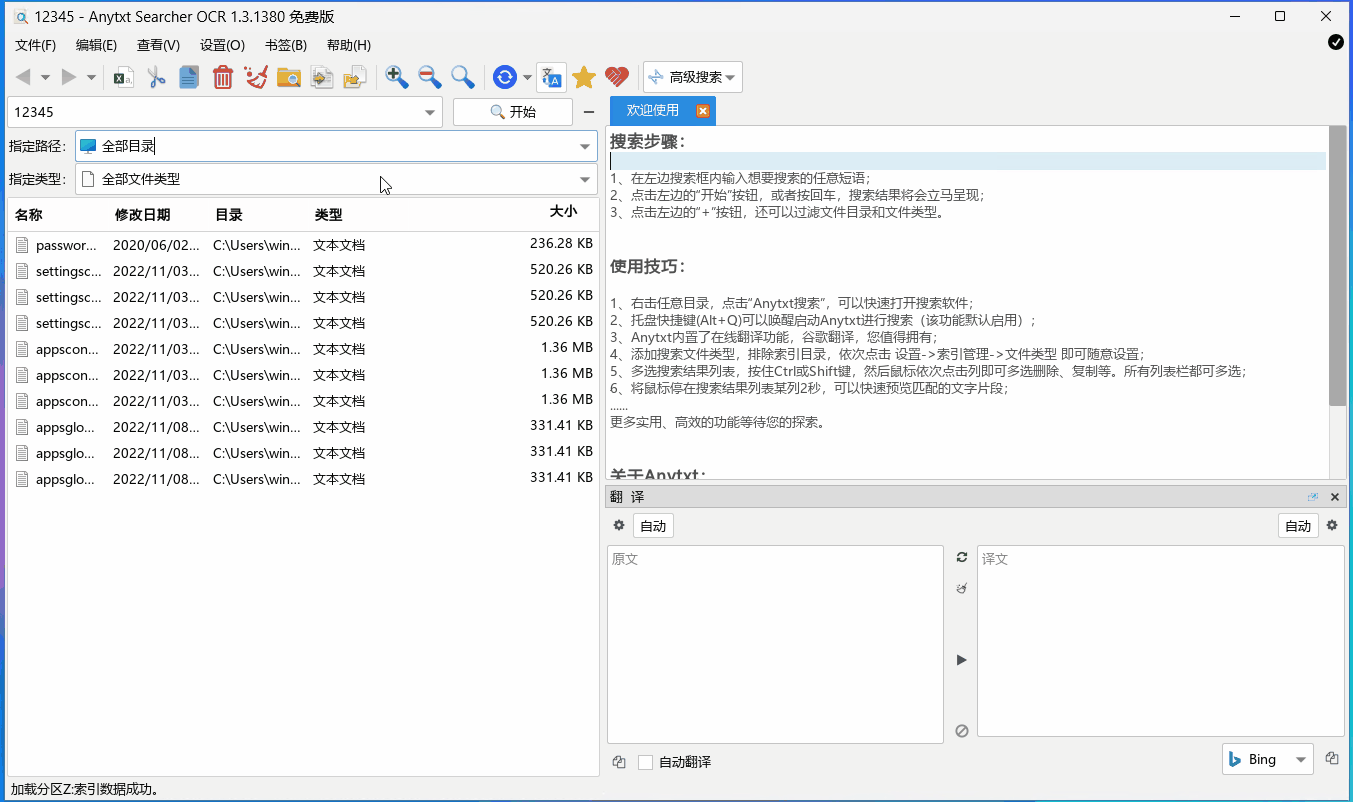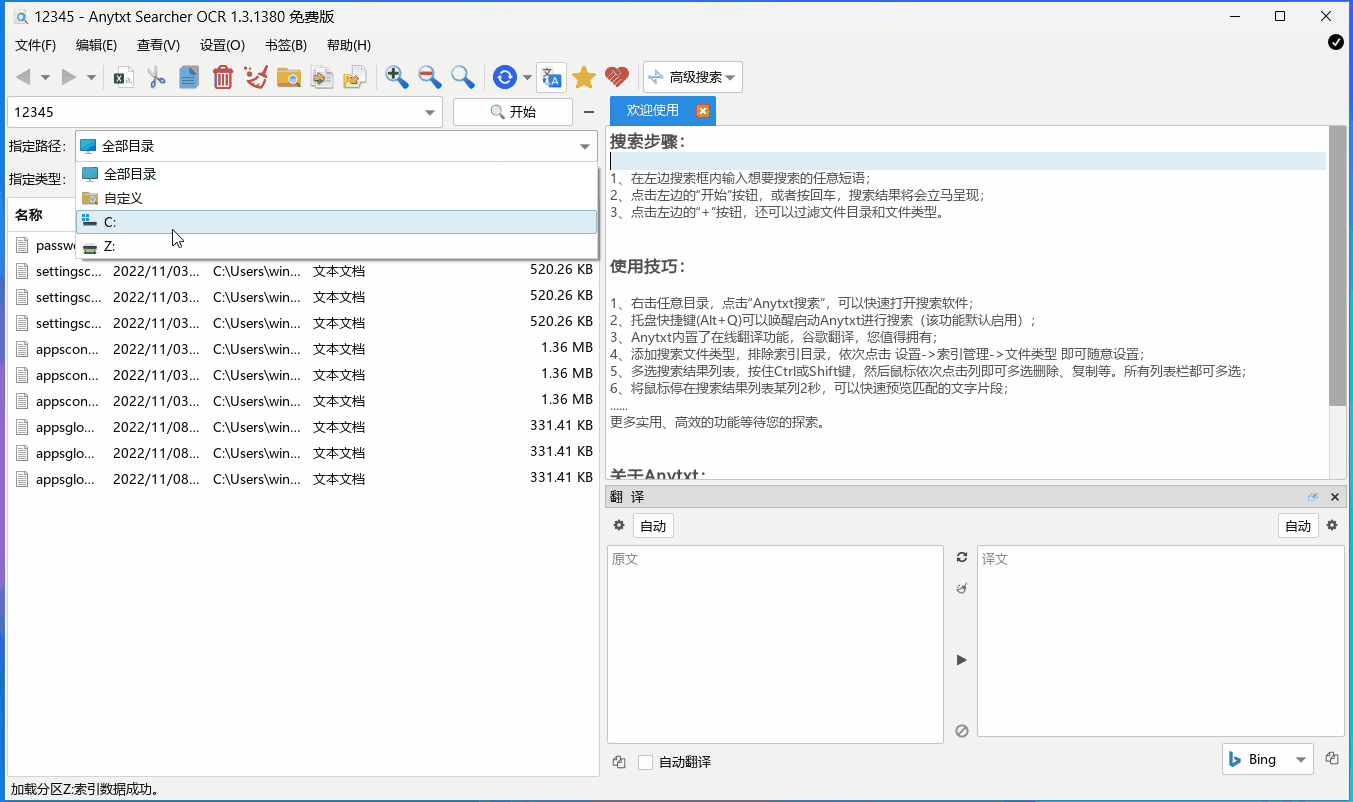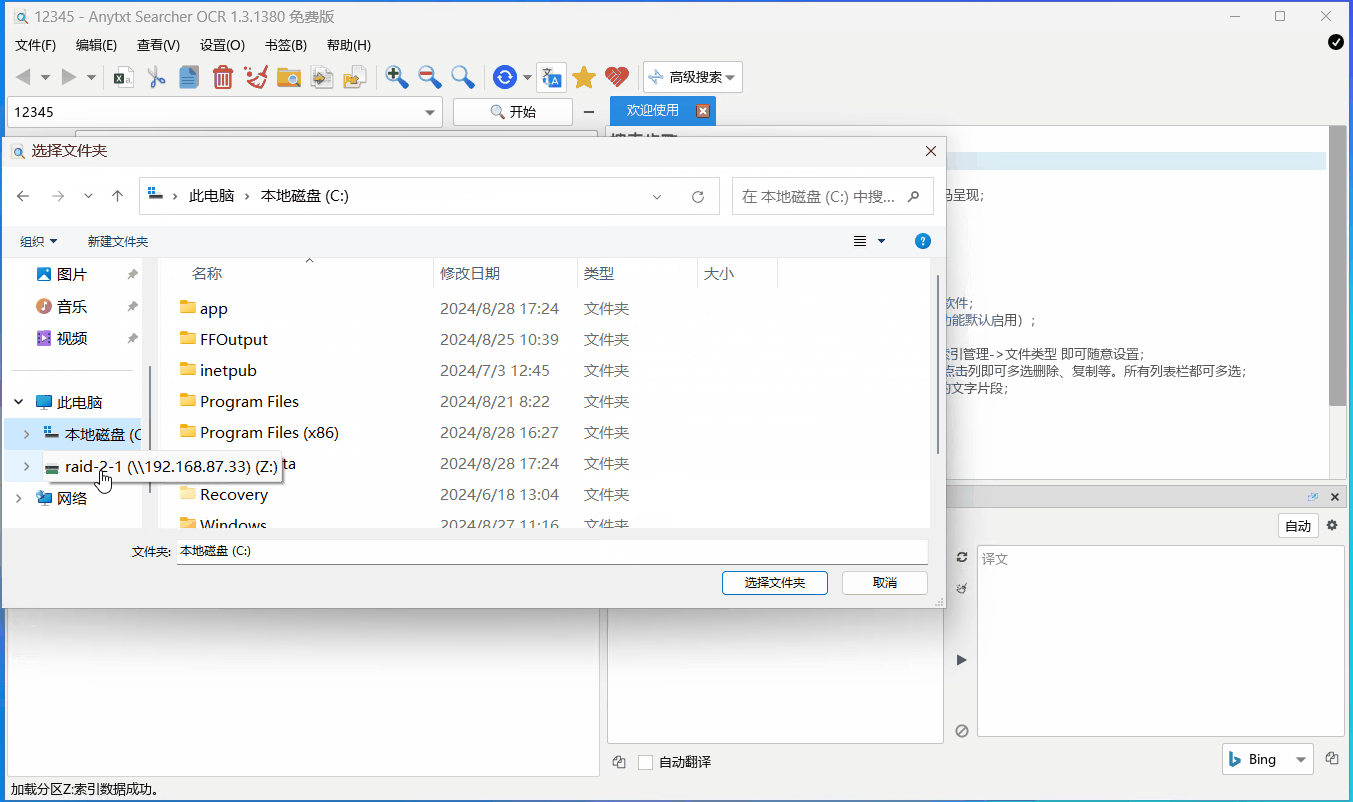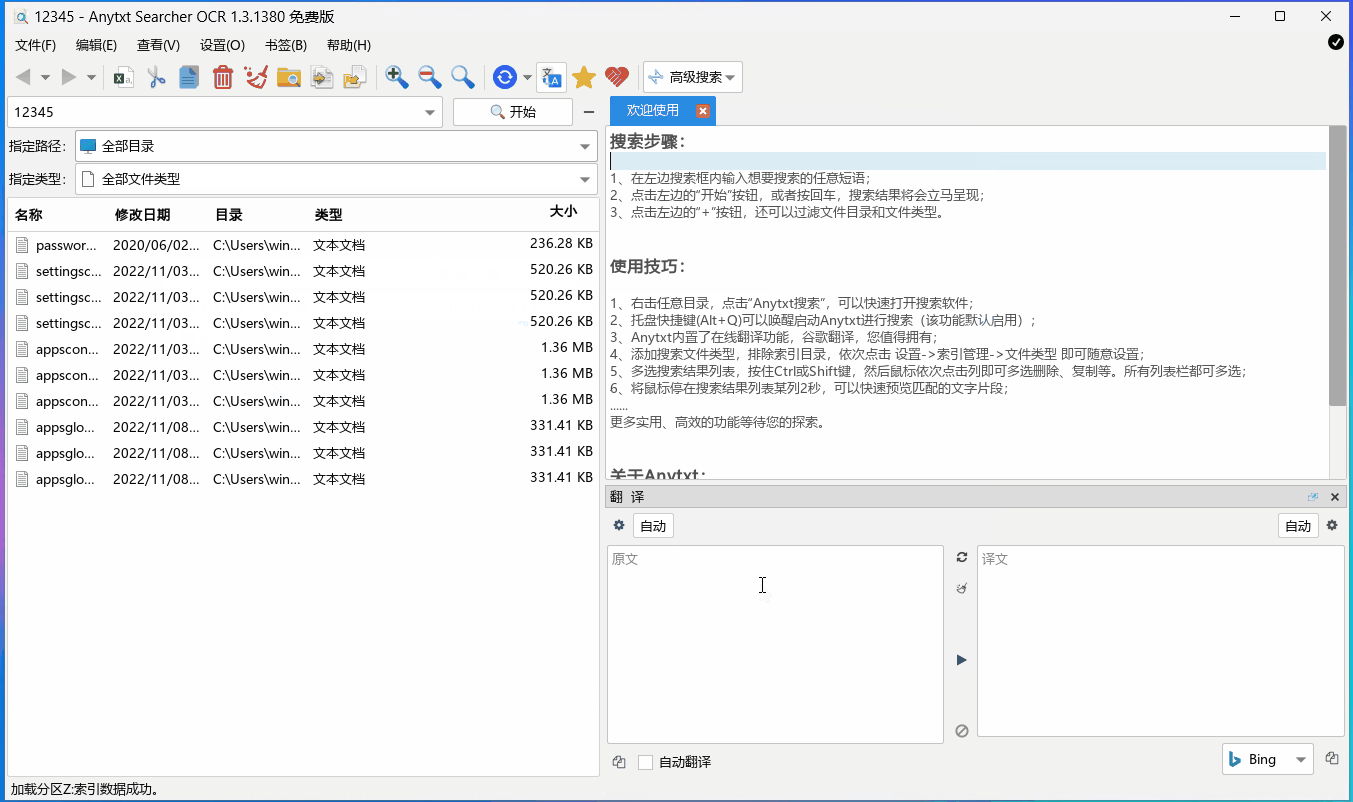
train目录如下:

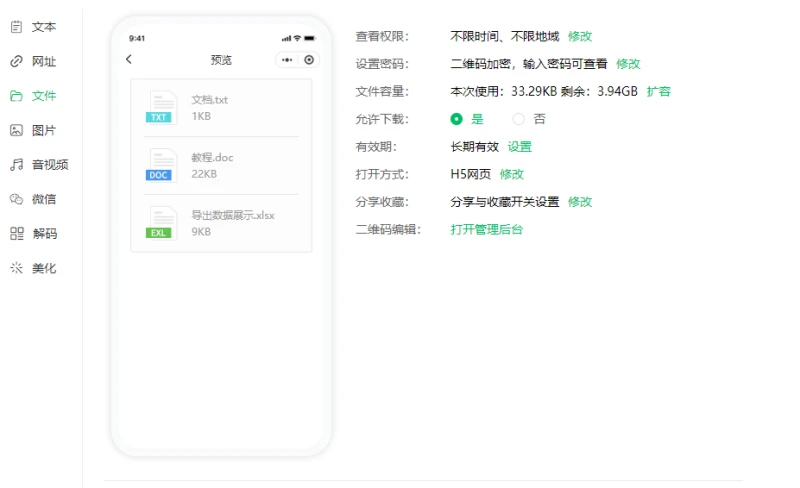
生成的augmented_data如下:

代码实现
1. 图像亮度调整函数
首先,我们需要编写一个函数,来调整图像的亮度。此处我们使用 HSV 色彩空间的 V(亮度)通道进行调整。
import cv2
import numpy as npdef adjust_brightness(im, vgain):hsv = cv2.cvtColor(im, cv2.COLOR_BGR2HSV)hue, sat, val = cv2.split(hsv)val = np.clip(val * vgain, 0, 255).astype(np.uint8)enhanced_hsv = cv2.merge((hue, sat, val))brightened_img = cv2.cvtColor(enhanced_hsv, cv2.COLOR_HSV2BGR)return brightened_img
2. 创建输出目录
在进行文件操作前,我们需要为增强后的文件创建一个新的输出目录。
import osdef create_output_folders(base_folder):new_base_folder = os.path.join(os.path.dirname(base_folder), "augmented_data")output_folders = {"images": os.path.join(new_base_folder, "images"),"annotations": os.path.join(new_base_folder, "annotations"),"labels": os.path.join(new_base_folder, "labels")}for folder in output_folders.values():os.makedirs(folder, exist_ok=True)return output_folders
3. 文件复制函数
为了复制原始图像和对应的注释文件,我们编写一个通用的文件复制函数。该函数可以根据需要在文件名后添加后缀。
import shutildef copy_file(src_path, dst_folder, filename_suffix, preserve_ext=True):base_filename, ext = os.path.splitext(os.path.basename(src_path))if preserve_ext:new_filename = f"{base_filename}{filename_suffix}{ext}"else:new_filename = f"{base_filename}{filename_suffix}"dst_path = os.path.join(dst_folder, new_filename)shutil.copy(src_path, dst_path)return dst_path
4. 图像增强与文件复制
该函数实现了图像的亮度增强,同时将增强后的图像和对应的注释文件保存到新的目录中。
def augment_and_copy_files(base_folder, image_filename, num_augmentations=2, vgain_range=(1, 1.5)):base_filename, image_ext = os.path.splitext(image_filename)# 构建原始文件路径file_paths = {"images": os.path.join(base_folder, "images", image_filename),"annotations": os.path.join(base_folder, "annotations", f"{base_filename}.xml"),"labels": os.path.join(base_folder, "labels", f"{base_filename}.txt")}# 创建输出文件夹output_folders = create_output_folders(base_folder)# 复制原始文件for key in file_paths:copy_file(file_paths[key], output_folders[key], "", preserve_ext=True)# 确保增强结果不重复unique_vgains = set()while len(unique_vgains) < num_augmentations:vgain = np.random.uniform(*vgain_range)if vgain not in unique_vgains:unique_vgains.add(vgain)brightened_img = adjust_brightness(cv2.imread(file_paths["images"]), vgain)for key in file_paths:filename_suffix = f"_enhanced_{len(unique_vgains)}"output_path = copy_file(file_paths[key], output_folders[key], filename_suffix, preserve_ext=True)if key == "images":cv2.imwrite(output_path, brightened_img)print(f"Saved: {output_path}")else:print(f"Copied {key}: {output_path}")print(f"All unique images and their annotations for {image_filename} have been enhanced and saved!")
5. 处理整个目录
最后,我们编写一个函数,用于处理指定目录中的所有图像文件,并对每张图像进行增强。
def process_all_images_in_folder(base_folder, num_augmentations=2, vgain_range=(1, 1.5)):images_folder = os.path.join(base_folder, "images")for image_filename in os.listdir(images_folder):if image_filename.lower().endswith(('.bmp', '.jpg', '.jpeg', '.png')):augment_and_copy_files(base_folder, image_filename, num_augmentations, vgain_range)
6. 运行脚本
你可以通过以下代码来运行整个图像增强与文件复制过程:
# 使用示例
base_folder = r"C:\Users\linds\Desktop\fsdownload\upgrade_algo_so\data_res_2024_08_31_10_29\train"
process_all_images_in_folder(base_folder)
7.整体代码
import cv2
import numpy as np
import os
import shutildef adjust_brightness(im, vgain):hsv = cv2.cvtColor(im, cv2.COLOR_BGR2HSV)hue, sat, val = cv2.split(hsv)val = np.clip(val * vgain, 0, 255).astype(np.uint8)enhanced_hsv = cv2.merge((hue, sat, val))brightened_img = cv2.cvtColor(enhanced_hsv, cv2.COLOR_HSV2BGR)return brightened_imgdef create_output_folders(base_folder):new_base_folder = os.path.join(os.path.dirname(base_folder), "augmented_data")output_folders = {"images": os.path.join(new_base_folder, "images"),"annotations": os.path.join(new_base_folder, "annotations"),"labels": os.path.join(new_base_folder, "labels")}for folder in output_folders.values():os.makedirs(folder, exist_ok=True)return output_foldersdef copy_file(src_path, dst_folder, filename_suffix, preserve_ext=True):base_filename, ext = os.path.splitext(os.path.basename(src_path))if preserve_ext:new_filename = f"{base_filename}{filename_suffix}{ext}"else:new_filename = f"{base_filename}{filename_suffix}"dst_path = os.path.join(dst_folder, new_filename)shutil.copy(src_path, dst_path)return dst_pathdef augment_and_copy_files(base_folder, image_filename, num_augmentations=2, vgain_range=(1, 1.5)):base_filename, image_ext = os.path.splitext(image_filename)# 构建原始文件路径file_paths = {"images": os.path.join(base_folder, "images", image_filename),"annotations": os.path.join(base_folder, "annotations", f"{base_filename}.xml"),"labels": os.path.join(base_folder, "labels", f"{base_filename}.txt")}# 创建输出文件夹output_folders = create_output_folders(base_folder)# 复制原始文件for key in file_paths:copy_file(file_paths[key], output_folders[key], "", preserve_ext=True)# 确保增强结果不重复unique_vgains = set()while len(unique_vgains) < num_augmentations:vgain = np.random.uniform(*vgain_range)if vgain not in unique_vgains:unique_vgains.add(vgain)brightened_img = adjust_brightness(cv2.imread(file_paths["images"]), vgain)for key in file_paths:filename_suffix = f"_enhanced_{len(unique_vgains)}"output_path = copy_file(file_paths[key], output_folders[key], filename_suffix, preserve_ext=True)if key == "images":cv2.imwrite(output_path, brightened_img)print(f"Saved: {output_path}")else:print(f"Copied {key}: {output_path}")print(f"All unique images and their annotations for {image_filename} have been enhanced and saved!")def process_all_images_in_folder(base_folder, num_augmentations=2, vgain_range=(1, 1.5)):images_folder = os.path.join(base_folder, "images")for image_filename in os.listdir(images_folder):if image_filename.lower().endswith(('.bmp', '.jpg', '.jpeg', '.png')):augment_and_copy_files(base_folder, image_filename, num_augmentations, vgain_range)# 使用示例
base_folder = r"C:\Users\linds\Desktop\fsdownload\upgrade_algo_so\data_res_2024_08_31_10_29\train"
process_all_images_in_folder(base_folder)