导读:
StarRocks Lakehouse 快速入门旨在帮助大家快速了解湖仓相关技术,内容涵盖关键特性介绍、独特的优势、使用场景和如何与 StarRocks 快速构建一套解决方案。最后大家也可以通过用户真实的使用场景来了解 StarRocks Lakehouse 的最佳实践!
Apache Iceberg 介绍
Apache Iceberg 是一种为大规模、复杂数据集设计的开源表格式,这些数据集跨越了 PB 级别的数据。最初作为 Netflix 管理海量表的解决方案,于 2018 年在 Apache 孵化器下开源,并在 2020 年毕业。
Apache Iceberg 作为一种复杂的开放表格式,位于计算引擎(如 Flink 和 Spark)和存储格式(如 ORC、Parquet 和 Avro)之间。它作为一个中间件层,抽象了底层数据存储格式的复杂性,并向计算框架上层提供了统一的表格语义。这种设计允许在不同的计算环境中灵活进行数据操作和模式管理,而不受任何特定存储引擎的约束,从而实现在 HDFS、S3、OSS 等环境中的扩展。
Apache Iceberg 架构和关键特性

架构设计
由三个主要层次构成:
-
数据层 :包含实际数据文件,如 Parquet 和 ORC。
-
元数据层 :多级结构,存储表结构和数据文件索引。
-
Catalog 层 :存储元数据文件位置的指针,提供多种实现如 HadoopCatalog 和 HiveCatalog。
元数据管理进一步分为三个关键组件:
-
元数据文件(Metadata File):存储当前版本的元数据,包括所有快照信息。
-
快照(Snapshot):代表特定操作的快照,每次提交都会生成一个新快照,其中包含多个清单,详细说明生成的数据文件的地址。
-
清单(Manifest):列出与快照关联的数据文件,提供数据组织的全面视图,并促进高效的数据检索和修改。
Iceberg 的核心目标是通过快照跟踪表随时间的所有变化,这些快照代表了任意时刻表数据文件的完整集合。每次更新操作都会生成一个新快照,确保数据一致性,并促进历史数据分析和增量读取。
关键特性
-
隐藏分区 :允许基于时间戳的自动数据分区,用户无需了解分区细节。
-
Schema 演化 :灵活变更表结构,不影响数据文件,变更历史可追踪。
-
分区演化 :修改分区策略不影响旧数据,新数据遵循新策略。
-
MVCC :多版本控制,写入操作不影响读取,通过 Manifest 文件管理。
-
数据一致性 :乐观锁机制处理并发写入,保证操作原子性。
-
行级更新 :V1 支持 COW,V2 支持 MOR,包括位置删除和等值删除,实现数据的逻辑更新。
Apache Iceberg 的优势
全面的计算引擎支持
Iceberg 的优越内核抽象确保它不依赖于任何特定的计算引擎,广泛支持 Spark、Flink 和 Hive 等流行的处理框架。这种灵活性使用户能够将 Iceberg 无缝集成到现有的数据基础设施中,利用本地 Java API 直接访问 Iceberg 表,而不受计算引擎选择的限制。
灵活的文件组织
Iceberg 引入了创新的数据组织策略,支持基于流的增量和批量全表计算模型。这种多功能性确保批处理任务和流处理任务可以在同一存储模型(如 HDFS 或 OZONE——Hadoop 社区开发的下一代存储引擎)上运行。通过启用隐藏分区和分区布局演进,Iceberg 促进了数据分区策略的轻松更新,支持包括 Parquet、ORC 和 Avro 在内的多种存储格式。这种方法不仅消除了数据孤岛,还有助于构建高效、轻量的数据湖存储服务。
优化的数据摄取工作流程
凭借其 ACID 事务能力,Iceberg 确保新摄入的数据立即可见,大大简化了 ETL 过程,消除了对当前数据处理任务的影响。平台对行级 upsert 和合并操作的支持进一步减少了数据摄取的延迟,简化了数据流入数据湖的整体流程。
增量读取能力
Iceberg 的一大亮点是其支持以流式方式读取增量数据,能够与主流开源计算引擎紧密集成进行数据摄取和分析。此功能通过对 Spark Structured Streaming 和 Flink Table Source 的内置支持得到了补充,允许复杂的数据分析工作流程。此外,Iceberg 执行历史版本回溯的能力增强了数据的可靠性和可审计性,提供了关于数据演变的宝贵洞察。
Iceberg 使用场景
-
实时数据导入和查询 : 数据实时从上游流向 Iceberg 数据湖,可以立即进行查询。例如,在日志记录场景中,可以使用 Iceberg 或 Spark 流处理作业实时将日志数据导入到 Iceberg 表中。然后可以使用 Hive、Spark、Iceberg 或 Presto 实时查询这些数据。此外,Iceberg 对 ACID 事务的支持确保了数据流入和查询的隔离,防止脏数据的出现。
-
数据删除或更新 : 大多数数据仓库在执行行级数据删除或更新时效率低下,通常需要离线作业提取整个表的原始数据,修改后再写回原始表中。然而,Iceberg 将变更范围从表级缩小到文件级,允许在数据修改或删除时执行业务逻辑的局部化变更。在 Iceberg 数据湖中,可以直接执行类似于
DELETE FROM test_table WHERE id > 10的命令,以修改表中的数据。 -
数据质量控制 : 借助 Iceberg Schema 的验证功能,在数据导入时排除异常数据,或对异常数据进行进一步处理。数据模式变更 数据的模式不是固定的,可以随时变更;Iceberg 支持使用 Spark SQL 的 DDL 语句对表结构进行更改。在 Iceberg 中更改表结构时,无需根据新模式重新导出所有历史数据,这大大加快了模式更改的过程。此外,Iceberg 对 ACID 事务的支持有效地将模式更改与影响现有读取任务的分离,使您能够访问一致准确的数据。
-
实时 机器学习 : 在机器学习场景中,通常需要大量时间来处理数据,如清理、转换和提取特征,以及处理历史和实时数据。Iceberg 简化了这一工作流程,将整个数据处理过程转化为完整可靠的实时流。数据清理、转换和特征工程等操作都是流上的节点动作,消除了分别处理历史数据和实时数据的需求。此外,Iceberg 还支持本地 Python SDK,对机器学习算法开发者非常友好。
StarRocks x Iceberg 查询加速
StarRocks 能高效地分析本地和数据湖中的数据,支持 Iceberg External Catalog,无需数据迁移即可查询 Iceberg 数据。StarRocks 支持 Iceberg v1、v2 读写,并通过以下方式优化查询性能:
-
元数据管理 :通过元数据缓存减少 I/O 浪费,分布式 Job Plan 加速 Manifest 文件的并行读取与过滤,以及 Manifest Cache 降低解析开销。
-
执行计划优化 :CBO 利用统计信息生成高效查询计划,StarRocks 收集外部表统计信息,包括直方图和复杂类型。
-
文件格式优化 :StarRocks 针对 Parquet、ORC 等格式进行优化,减少数据扫描量和 I/O 开销。
-
内外表差异消除 :Data Cache 技术缓存热数据,减少远程 I/O;智能物化视图提供性能保障,支持查询改写和增量刷新。
-
生态融合 :StarRocks 支持 Iceberg 读写,便于数据回湖和轻量级加工,提供更好的查询体验和数据统一管理。
快速开始
当前教程包含以下内容:
-
使用 Docker Compose 部署对象存储、Apache Spark、Iceberg Catalog 和 StarRocks。
-
向 Iceberg 数据湖导入数据。
-
配置 StarRocks 以访问 Iceberg Catalog。
-
使用 StarRocks 查询数据湖中的数据。
详细教程请见文档:基于 Apache Iceberg 的数据湖分析 | StarRocks
Iceberg Quick Start 请参考 Iceberg 文档:Spark and Iceberg Quickstart - Apache Iceberg™
iceberg部署
Apache iceberg只需要将对应的jar包添加到Spark的提交参数中,即可加载 Iceberg 的相关类。本文中使用的 spark-iceberg 是已集成 Iceberg 的 Spark 容器,启动容器后,我们即可在 PySpark 环境中使用 Iceberg。
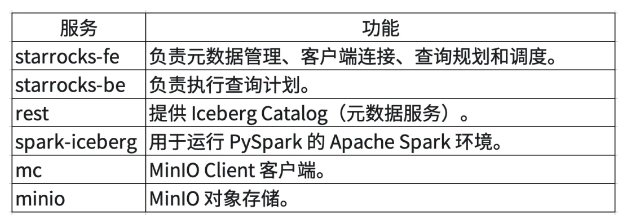
环境
本教程使用了六个 Docker 容器(服务),均使用 Docker Compose 部署。这些服务及其功能如下:
下载 Docker Compose 文件和数据集
StarRocks 提供了包含以上必要容器的环境的 Docker Compose 文件和教程中需要使用数据集。
本教程中使用的数据集为纽约市绿色出租车行程记录,为 Parquet 格式。
下载 Docker Compose 文件。
mkdir iceberg
cd iceberg
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/iceberg/docker-compose.yml下载数据集。
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/iceberg/datasets/green_tripdata_2023-05.parquet在 Docker 中启动环境
提示:所有 docker compose 命令必须从包含 docker-compose.yml 文件的目录中运行。
docker compose up -dPySpark
本教程使用 PySpark 与 Iceberg 交互。
在将数据导入至 Iceberg 之前,需要将其拷贝到 spark-iceberg 容器中。
运行以下命令将数据集文件复制到 spark-iceberg 容器中的 /opt/spark/ 路径。
docker compose \
cp green_tripdata_2023-05.parquet spark-iceberg:/opt/spark/启动 PySpark
运行以下命令连接 spark-iceberg 服务并启动 PySpark。
docker compose exec -it spark-iceberg pyspark导入数据集至 DataFrame 中
DataFrame 是 Spark SQL 的一部分,提供类似于数据库表的数据结构。
您需要从 /opt/spark 路径导入数据集文件至 DataFrame 中,并通过查询其中部分数据检查数据导入是否成功。
在 PySpark Session 运行以下命令:
# 读取数据集文件到名为 `df` 的 DataFrame 中。
df = spark.read.parquet("/opt/spark/green_tripdata_2023-05.parquet")
# 显示数据集文件的 Schema。
df.printSchema()通过查询 DataFrame 中的部分数据验证导入是否成功。
# 检查前三行数据的前七列
df.select(df.columns[:7]).show(3)创建 Iceberg 表并导入数据
根据以下信息创建 Iceberg 表并将上一步中的数据导入表中:
-
Catalog 名:
demo -
数据库名:
nyc -
表名:
greentaxis
df.writeTo("demo.nyc.greentaxis").create()在此步骤中创建的 Iceberg 表将在下一步中用于 StarRocks External Catalog。
配置 StarRocks 访问 Iceberg Catalog
现在您可以退出 PySpark,并通过您的 SQL 客户端运行 SQL 命令。
使用 SQL 客户端连接到 StarRocks
SQL 客户端
MySQL CLI:您可以从 Docker 环境或您的本机运行此客户端。
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "- 如果您使用 StarRocks 容器中的 MySQL Client,需要从包含
docker-compose.yml文件的路径运行以下命令。
docker compose exec starrocks-fe \mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "StarRocks >创建 External Catalog
您可以通过创建 External Catalog 将 StarRocks 连接至您的数据湖。以下示例基于以上 Iceberg 数据源创建 External Catalog。
CREATE EXTERNAL CATALOG 'iceberg'
PROPERTIES
("type"="iceberg","iceberg.catalog.type"="rest","iceberg.catalog.uri"="http://iceberg-rest:8181","iceberg.catalog.warehouse"="warehouse","aws.s3.access_key"="admin","aws.s3.secret_key"="password","aws.s3.endpoint"="http://minio:9000","aws.s3.enable_path_style_access"="true","client.factory"="com.starrocks.connector.iceberg.IcebergAwsClientFactory"
);创建成功后,运行以下命令查看创建的 Catalog。
SHOW CATALOGS;其中 default_catalog 为 StarRocks 的 Internal Catalog,用于存储内部数据。
设置当前使用的 Catalog 为 iceberg 。
SET CATALOG iceberg;查看 iceberg 中的数据库。
SHOW DATABASES;使用 StarRocks 查询 Iceberg
查询接单时间
以下语句查询出租车接单时间,仅返回前十行数据。
SELECT lpep_pickup_datetime FROM greentaxis LIMIT 10;查询接单高峰时期
以下查询按每小时聚合行程数据,计算每小时接单的数量。
SELECT COUNT(*) AS trips,hour(lpep_pickup_datetime) AS hour_of_day
FROM greentaxis
GROUP BY hour_of_day
ORDER BY trips DESC;【英文Demo】StarRocks+Iceberg+MinIO_哔哩哔哩_bilibili
用户案例:
腾讯实验平台基于 StarRocks 构建湖仓底座
微信基于 StarRocks 的湖仓一体实践
StarRocks 在小红书自助分析场景的应用与实践
进阶指南:
如果你已经成功搭建 StarRocks + Iceberg,如果你还想知道 Iceberg 如何与 Hive、Flink、Spark 集成,你可以阅读:
Iceberg介绍及集成Hive、Flink、Spark(上):Iceberg介绍及集成Hive、Flink、Spark(上篇) - 📚 StarRocks 最佳实践 - StarRocks中文社区论坛
Iceberg介绍及集成Hive、Flink、Spark(下):Iceberg介绍及集成Hive、Flink、Spark(下篇) - 📚 StarRocks 最佳实践 - StarRocks中文社区论坛
更多交流,联系我们:StarRocks