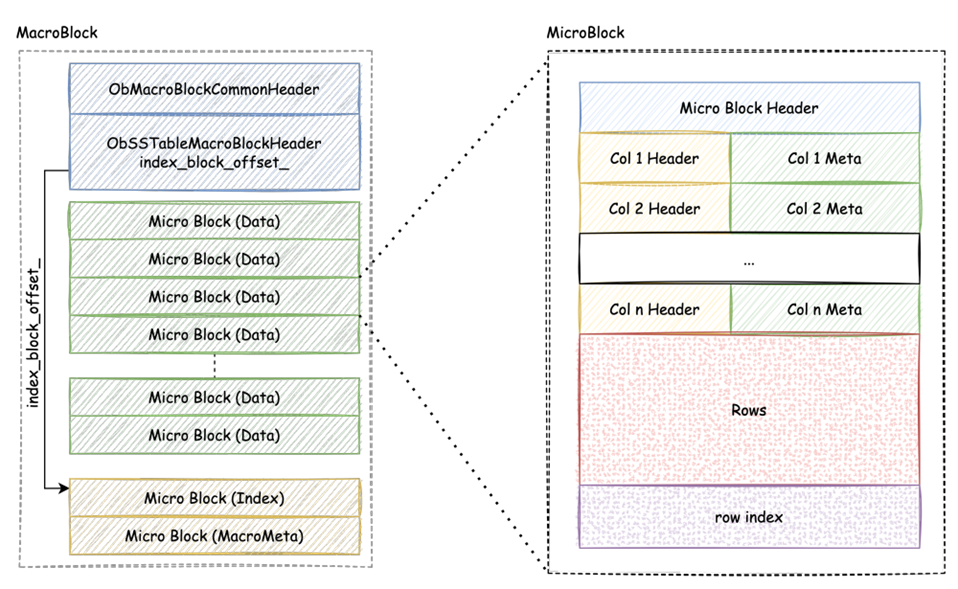
文章目录
- 摘要
- 1 引言
- 2 相关工作
- 3 任务:可提示视觉分割
- 4 模型
- 5 数据
- 5.1 数据引擎
- 5.2 SA-V数据集
- 6 零样本实验
- 6.1 视频任务
- 6.1.1 提示视频分割
- 6.1.2 半监督视频对象分割
- 6.1.3 公平性评估
- 6.2 图像任务
- 7 与半监督VOS的最新技术的比较
- 8 数据和模型消融
- 8.1 数据消融
- 8.2 模型架构消融
- 8.2.1 容量消融
- 8.2.2 相对位置编码
- 8.2.3 记忆架构消融
- 9 结论
- 10 致谢
- 附录
- A PVS任务的细节
- B 局限性
- C SAM 2细节
- C. 1 架构
- C. 2 训练
- C.2.1 预训练
- C.2.2 全面训练
- C. 3 速度基准测试
- D 数据细节
- D. 1 SA-V数据集细节
- D.2 数据引擎细节
- D.2.1 注释协议
- D.2.2 数据引擎阶段比较
- E 关于零样本转移实验的更多细节
- E.1 零样本视频任务
- E.1.1 视频数据集细节
- E.1.2 交互式离线和在线评估细节
- E.1.3 半监督VOS评估细节
- E.1.4 SAM+XMem++和SAM+Cutie基线细节
- E.2 DAVIS交互式基准测试
- E.3 零样本图像任务
- E.3.1 数据集细节
- E.3.2 详细的零样本实验
- F 在半监督VOS中与最新技术的比较的更多细节
- G 模型、数据和注释卡片
- G. 1 模型卡片
- G. 2 SA-V数据集卡片
- G.3 数据注释卡片
摘要
我们提出了“Segment Anything Model 2”(SAM 2),这是一种基础模型,旨在解决图像和视频中的可提示视觉分割问题。我们构建了一个数据引擎,该引擎通过用户交互改进模型和数据,以收集迄今为止最大的视频分割数据集。我们的模型采用带有流式内存的简单变换器架构,适用于实时视频处理。使用我们的数据进行训练的SAM 2在广泛的任务中表现出色。在视频分割方面,我们观察到比先前方法更高的准确性,同时所需的交互次数减少了 3 3 3倍。在图像分割方面,我们的模型比“Segment Anything Model”(SAM)更准确,速度快了 6 6 6倍。我们相信,我们的数据、模型和见解将成为视频分割和相关感知任务的重要里程碑。我们正在发布我们模型的版本、数据集和交互式演示。
1 引言
Segment Anything(SA)引入了一种用于图像中可提示分割的基础模型(Kirillov等人,2023)。然而,图像只是现实世界的一个静态快照,其中的视觉片段可能展现出复杂的运动,并且随着多媒体内容的快速增长,现在很大一部分内容都带有时间维度,尤其是在视频数据中。在增强现实/虚拟现实(AR/VR)、机器人、自动驾驶汽车和视频编辑等许多重要应用中,除了图像级别的分割外,还需要进行时间定位。我们认为,一个通用的视觉分割系统应该同时适用于图像和视频。
视频分割旨在确定实体的时空范围,这除了图像分割中的挑战外,还带来了独特的挑战。由于运动、变形、遮挡、光照变化和其他因素,实体的外观可能会发生重大变化。由于相机运动、模糊和分辨率较低,视频的质量通常低于图像。此外,大量帧的高效处理是一个关键挑战。虽然SA成功解决了图像分割问题,但现有的视频分割模型和数据集在提供“分割视频中任何内容”的能力方面仍有不足。
我们介绍了Segment Anything Model 2(SAM 2),这是一个用于视频和图像分割的统一模型(我们将图像视为单帧视频)。我们的工作包括任务、模型和数据集(见图1)。

我们专注于Promptable Visual Segmentation(PVS)任务,该任务将图像分割推广到视频领域。该任务将视频任何帧上的点、框或掩码作为输入,以定义要预测其时空掩码(即“掩码片”)的感兴趣段。一旦预测出掩码片,就可以通过在额外帧中提供提示来迭代细化它。
我们的模型(第4节)能够在单个图像和视频帧中生成感兴趣对象的分割掩码。SAM 2配备了一个存储对象信息和先前交互信息的内存,这使得它能够在整个视频中生成掩码片预测,并根据先前观察到的帧中对象的存储内存上下文有效地对其进行校正。我们的流式架构是SAM向视频领域的自然推广,它一次处理一个视频帧,并配备了一个内存注意模块来关注目标对象的先前记忆。当应用于图像时,内存为空,模型的行为与SAM相同。
我们采用了一个数据引擎(第5节)来通过在我们的模型与注释者之间的循环中使用我们的模型来生成训练数据,从而交互式地注释新的和具有挑战性的数据。与大多数现有的视频分割数据集不同,我们的数据引擎不限于特定类别的对象,而是旨在提供用于分割具有有效边界的任何对象(包括部分和子部分)的训练数据。与现有的模型辅助方法相比,在可比质量下,我们的带有SAM 2循环的数据引擎速度快了 8.4 8.4 8.4倍。我们的最终Segment Anything Video(SA-V)数据集(第5.2节)包含50.9万个视频中的3550万个掩码,比任何现有的视频分割数据集多 53 53 53倍。SA-V在整个视频中会出现遮挡和重新出现的小对象和部件方面具有挑战性。我们的SA-V数据集在地理上具有多样性,对SAM 2的公平性评估表明,在基于感知性别的视频分割中,性能差异最小,在我们评估的三个感知年龄段之间几乎没有差异。
我们的实验(第6节)表明,SAM 2在视频分割体验上实现了质的飞跃。SAM 2能够在比先前方法少 3 × 3 \times 3×的交互次数下产生更好的分割精度。此外,在多个评估设置下,SAM 2在已建立的视频对象分割基准测试中优于先前的工作,并且在图像分割基准测试中与SAM相比表现出更好的性能,同时速度快了 6 × 6 \times 6×。通过包括17个视频分割基准和37个单图像分割基准在内的众多零样本基准测试的观察,SAM 2被证明在各种视频和图像分布中都是有效的。
我们正在以宽松的开源许可发布我们的工作,包括SA-V数据集(CC by 4.0)、SAM 2模型的一个版本(Apache 2.0),以及一个交互式在线演示,网址为https://sam2.metademolab.com。
2 相关工作
图像分割。Segment Anything(Kirillov等人,2023)引入了一个可提示的图像分割任务,其目标是根据输入提示(如指向感兴趣对象的边界框或点)输出有效的分割掩码。在SA-1B数据集上训练的SAM允许通过灵活的提示进行零样本分割,这使其能够被广泛应用于各种下游应用。最近的工作通过提高质量来扩展SAM。例如,HQ-SAM(Ke等人,2024)通过引入高质量输出标记并在细粒度掩码上训练模型来增强SAM。另一项工作则专注于提高SAM的效率,以便在现实世界和移动应用中更广泛地使用,如EfficientSAM(Xiong等人,2023)、MobileSAM(Zhang等人,2023a)和FastSAM(Zhao等人,2023)。SAM的成功促使其被广泛应用于各种领域,如医学成像(Ma等人,2024;Deng等人,2023;Mazurowski等人,2023;Wu等人,2023a)、遥感(Chen等人,2024;Ren等人,2024)、运动分割(Xie等人,2024)和伪装对象检测(Tang等人,2023)。
交互式视频对象分割(iVOS)。交互式视频对象分割已成为一项重要任务,旨在通过用户指导(通常以涂鸦、点击或边界框的形式)高效地获取视频中的对象分割(masklets)。一些早期方法(Wang等人,2005;Bai和Sapiro,2007;Fan等人,2015)采用基于图的优化来指导分割标注过程。而最近的方法(Heo等人,2020;Cheng等人,2021b;Delatolas等人,2024)通常采用模块化设计,将用户输入转换为单个帧上的掩码表示,然后将其传播到其他帧。我们的工作与这些工作有着类似的目标,即提供良好的交互式体验以跨视频分割对象,并且为了实现这一目标,我们构建了一个强大的模型以及一个庞大且多样的数据集。
特别是,DAVIS交互式基准测试(Caelles等人,2018)允许通过在多帧上进行涂鸦输入来交互式地分割对象。受DAVIS交互式基准测试的启发,我们也在第6.1节中为可提示的视频分割任务采用了交互式评估设置。
基于点击的输入对于交互式视频分割来说更容易收集(Homayounfar等人,2021)。最近的工作已经将图像上的语义注意力机制(SAM)与基于掩码(Cheng等人,2023b;Yang等人,2023;Cheng等人,2023c)或点(Rajič等人,2023)的视频跟踪器结合起来使用。然而,这些方法存在局限性:跟踪器可能不适用于所有对象,SAM对于来自视频的图像帧可能表现不佳,并且除了从头开始使用SAM在错误帧上重新标注并从头开始跟踪外,没有其他机制可以交互式地纠正模型的错误。
半监督视频对象分割(VOS)。半监督VOS通常以第一帧中的对象掩码作为输入,并且该掩码必须在整个视频中准确跟踪(Pont-Tuset等人,2017)。由于该输入掩码可以视为仅针对第一帧可用的对象外观的监督信号,因此它被称为“半监督”。由于其在视频编辑、机器人技术和自动背景去除等各种应用中的相关性,这项任务引起了广泛关注。
早期基于神经网络的方法经常使用在线微调来适应目标对象,这包括在第一个视频帧上进行微调(Caelles等人,2016年;Perazzi等人,2016年;Yoon等人,2017年;Maninis等人,2017年;Hu等人,2018年a;Bhat等人,2020年;Robinson等人,2020年),或者在所有帧上进行微调(Voigtlaender & Leibe,2017年)。通过离线训练的模型,仅在第一帧(Hu等人,2018年b;Chen等人,2018年)或同时整合前一帧(Oh等人,2018年;Yang等人,2018年,2020年)上进行条件化,实现了更快的推理。这种多条件化已经通过RNNs(Xu等人,2018年a)和交叉注意力(Oh等人,2019年;Cheng等人,2021年a;Li等人,2022年a;Yang等人,2021年b,2024年;Cheng & Schwing,2022年;Yang & Yang,2022年;Wang等人,2022年;Cheng等人,2023年a;Goyal等人,2023年)扩展到所有帧。最近的方法(Zhang等人,2023年b;Wu等人,2023年b)将单个视觉Transformer扩展到同时处理当前帧以及所有先前帧和相关预测,从而实现了简单的架构,但推理成本过高。半监督视频对象分割(VOS)可以看作是我们的可提示视觉分割(PVS)任务的一个特例,因为它等同于仅在第一帧提供掩码提示。尽管如此,实际上在第一帧中注释所需的高质量对象掩码是具有挑战性和耗时的。
视频分割数据集。为了支持视频对象分割(VOS)任务,已经提出了许多数据集。早期的VOS数据集(Prest等人,2012年;Li等人,2013年;Ochs等人,2014年;Fan等人,2015年),如DAVIS(Pont-Tuset等人,2017年;Caelles等人,2019年),包括高质量的注释,但其有限的规模不允许训练基于深度学习的方法。YouTube-VOS(Xu等人,2018年b)是第一个大规模的VOS数据集,涵盖了94个对象类别和超过4千个视频。随着算法的改进和基准性能的饱和,研究人员开始通过特别关注遮挡(Qi等人,2022年;Ding等人,2023年)、长视频(Hong等人,2023年,2024年)、极端变换(Tokmakov等人,2022年)、对象多样性(Wang等人,2021年b,2023年)或场景多样性(Athar等人,2022年)来增加VOS任务的难度。
我们发现当前的视频分割数据集缺乏足够的覆盖面来实现“在视频中分割任何东西”的能力。它们的注释通常覆盖整个对象(而不是部分),并且数据集通常围绕特定的对象类别,如人、车辆和动物。与这些数据集相比,我们发布的SA-V数据集不仅关注整个对象,还广泛覆盖对象部分,并包含超过一个数量级更多的掩码。
3 任务:可提示视觉分割
可提示视觉分割(PVS)任务允许在视频的任何帧上向模型提供提示。提示可以是正面/负面点击、边界框或掩码,用于定义要分割的对象或细化模型预测的对象。为了提供交互式体验,在接收到特定帧上的提示后,模型应立即响应该帧上对象的有效分割掩码。在接收到初始(一个或多个)提示(在同一帧或不同帧上)后,模型应将这些提示传播以获得整个视频的对象掩码,其中包含目标对象在每个视频帧上的分割掩码。可以在任何帧上向模型提供额外的提示,以在整个视频中细化分割(图2中有示例)。有关任务的详细信息,请参见附录A。

SAM 2,在下一节(§4)中介绍,作为数据收集工具应用于PVS任务,用于构建我们的SA-V数据集(§5)。该模型在线上和线下环境中进行评估(§6),通过模拟涉及多帧注释的交互式视频分割场景,在传统的半监督VOS设置中,注释仅限于第一帧,以及在SA基准测试上进行图像分割。
4 模型
我们的模型可以看作是将SAM推广到视频(和图像)领域。SAM 2(图3)支持在单个帧上使用点、框和掩码提示,以定义视频中要分割的对象的空间范围。对于图像输入,模型的行为与SAM类似。一个可提示且轻量级的掩码解码器接受当前帧的嵌入和提示(如果有的话),并输出该帧的分割掩码。可以迭代地在帧上添加提示,以细化掩码。

与SAM不同,SAM 2解码器使用的帧嵌入不是直接来自图像编码器,而是根据过去预测和提示帧的记忆进行条件化。提示的帧也可以相对于当前帧来自“未来”。帧的记忆由记忆编码器基于当前预测创建,并放置在记忆库中,以供后续帧使用。记忆注意力操作采用图像编码器的每帧嵌入,并将其与记忆库的条件化,以产生然后传递给掩码解码器的嵌入。
我们在下面描述各个组件和训练,并在附录C中提供更多细节。
图像编码器。为了实时处理任意长度的视频,我们采取流式处理方法,随着视频帧的可用性而消费它们。图像编码器仅在整个交互过程中运行一次,其作用是提供代表每帧的未条件化令牌(特征嵌入)。我们使用预训练的Hiera(Ryali等人,2023;Bolya等人,2023)MAE(He等人,2022)图像编码器,它是分层的,允许我们在解码期间使用多尺度特征。
记忆注意力。记忆注意力的作用是对当前帧特征进行条件化,使其基于过去帧的特征和预测以及任何新的提示。我们堆叠了L个transformer块,第一个块以当前帧的图像编码作为输入。每个块执行自注意力,然后是对记忆库中存储的(提示/未提示的)帧和对象指针的记忆进行交叉注意力(见下文),然后是MLP。我们使用普通的注意力操作进行自注意力和交叉注意力,使我们能够从最近的高效注意力内核发展中受益(Dao,2023)。
提示编码器和掩码解码器。我们的提示编码器与SAM的相同,可以通过点击(正面或负面)、边界框或掩码来提示,以定义给定帧中对象的范围。稀疏提示由位置编码表示,与每种提示类型的学习嵌入相加,而掩码则使用卷积嵌入并与帧嵌入相加。
我们的解码器设计在很大程度上遵循SAM。我们堆叠了“双向”transformer块,这些块更新提示和帧嵌入。正如在SAM中一样,对于模糊的提示(即,一个单一的点击),可能存在多个兼容的目标掩码,我们预测多个掩码。这种设计对于确保模型输出有效掩码很重要。在视频中,模糊可能延伸到视频帧之间,模型在每个帧上预测多个掩码。如果没有后续提示解决模糊性,模型只传播当前帧预测IoU最高的掩码。
与SAM不同,在PVS任务中,可能有些帧上不存在有效对象(例如,由于遮挡)。为了考虑这种新的输出模式,我们增加了一个额外的头,用于预测当前帧上是否存在感兴趣的对象。与SAM的另一个区别是,我们使用来自分层图像编码器的跳跃连接(绕过记忆注意力)来合并用于掩码解码的高分辨率信息(见§C)。
记忆编码器。记忆编码器通过使用卷积模块对输出掩码进行下采样,并将其与图像编码器的未条件化帧嵌入(图3中未显示)逐元素相加,然后通过轻量级卷积层融合信息,从而生成记忆。
记忆库。记忆库通过维护一个最多包含N个最近帧的记忆的先进先出(FIFO)队列,保留有关视频中目标对象过去预测的信息,并通过一个最多包含M个提示帧的FIFO队列存储提示中的信息。例如,在初始掩码是唯一提示的VOS任务中,记忆库持续保留第一帧的记忆以及最多N个最近的(未提示的)帧的记忆。这两组记忆都存储为空间特征图。
除了空间记忆,我们还存储一个对象指针的列表,作为基于每帧掩码解码器输出令牌的要分割对象的高级语义信息的轻量级向量(Meinhardt等人,2022年)。我们的记忆注意力交叉关注空间记忆特征和这些对象指针。
我们将时间位置信息嵌入到N个最近帧的记忆,允许模型表示短期对象运动,但不嵌入到提示帧的记忆,因为提示帧的训练信号更稀疏,并且更难泛化到推理设置,其中提示帧可能来自与训练期间看到的非常不同的时间范围。
训练。模型在图像和视频数据上联合训练。类似于之前的工作(Kirillov等人,2023年;Sofiiuk等人,2022年),我们模拟模型的交互式提示。我们采样8帧序列,并随机选择最多2帧进行提示,并以概率接收校正点击,这些点击在训练期间使用真实掩码和模型预测进行采样。训练任务是顺序(和“交互式”)预测真实掩码。模型的初始提示可以是真实掩码的概率为0.5,从真实掩码中采样的正面点击的概率为0.25,或者输入边界框的概率为0.25。有关更多详细信息,请参见附录C。
5 数据
为了发展在视频中“分割任何东西”的能力,我们构建了一个数据引擎来收集一个大型且多样化的视频分割数据集。我们采用与人类注释者循环中的交互式模型设置。类似于Kirillov等人(2023年),我们不对注释掩码施加语义约束,专注于整个对象(例如,一个人)和部分(例如,一个人的帽子)。我们的数据引擎经历了三个阶段,每个阶段根据向注释者提供模型辅助的水平进行分类。接下来,我们描述每个数据引擎阶段和我们的SA-V数据集。
5.1 数据引擎
第一阶段:每帧的SAM。初始阶段使用基于图像的交互式SAM(Kirillov等人,2023年)来辅助人类注释。注释者的任务是使用SAM在每秒6帧(FPS)的速度下注释视频中每一帧的目标对象掩码,并使用像素精确的手动编辑工具,如“画笔”和“橡皮擦”。没有涉及跟踪模型来协助将掩码传播到其他帧。由于这是一种逐帧方法,所有帧都需要从头开始注释掩码,因此过程较慢,在我们的实验中,平均每帧注释时间为37.8秒。然而,这产生了每帧高质量的空间注释。在这个阶段,我们收集了1.4K视频的16K掩码。我们还使用这种方法来注释我们的SA-V验证和测试集,以减轻评估期间SAM 2的潜在偏差。
第二阶段:SAM + SAM 2掩码。第二阶段增加了SAM 2进入循环,其中SAM 2仅接受掩码作为提示。我们称这个版本为SAM 2掩码。注释者使用SAM和其他工具如第一阶段生成第一帧的空间掩码,然后使用SAM 2掩码将注释的掩码时间传播到其他帧以获得完整的时空掩码。在任何后续的视频帧中,注释者可以通过使用SAM从头开始注释掩码、“画笔”和/或“橡皮擦”来空间修改SAM 2掩码所做的预测,并重新使用SAM 2掩码进行传播,重复此过程,直到掩码正确。SAM 2掩码最初在第一阶段的数据和公开可用的数据集上进行训练。在第二阶段,我们使用收集到的数据在注释循环中两次重新训练和更新SAM 2掩码。在第二阶段,我们收集了63.5K掩码。注释时间减少到7.4秒/帧,比第一阶段提高了约5.1倍。
尽管注释时间有所提高,但这种分离的方法需要从头开始注释中间帧的掩码,没有之前的记忆。然后我们进一步开发了功能齐全的SAM 2,它能够统一执行交互式图像分割和掩码传播。
第三阶段:SAM 2。在最后阶段,我们使用功能齐全的SAM 2,它接受各种类型的提示,包括点和掩码。SAM 2利用跨时间维度的对象记忆来生成掩码预测。这意味着注释者只需要偶尔向SAM 2提供细化点击,以编辑中间帧中预测的掩码,而不是使用没有这种记忆上下文的空间SAM从头开始注释。在第三阶段,我们使用收集到的注释五次重新训练和更新SAM 2。有了SAM 2的循环,每帧的注释时间减少到4.5秒,比第一阶段提高了约8.4倍。在第三阶段,我们收集了197.0K掩码。
质量验证。为了保持注释的高标准,我们引入了一个验证步骤。一组独立的注释者负责验证每个注释掩码的质量,将其标记为“满意”(正确且一致地在所有帧中跟踪目标对象)或“不满意”(目标对象定义明确且边界清晰,但掩码不正确或不一致)。不满意的掩码会被送回注释流程进行细化。任何跟踪定义不明确的物体的掩码都会被完全拒绝。
自动掩码生成。确保注释的多样性对于实现我们模型的“任何东西”能力很重要。由于人类注释者通常会更多地关注显著的对象,我们通过自动生成的掩码(称为“自动”)来增加注释,这既增加了注释的覆盖范围,也有助于识别模型失败的案例。为了生成自动掩码,我们在第一帧中使用规则网格的点提示SAM 2并生成候选掩码。然后将这些发送到掩码验证步骤进行筛选。被标记为“满意”的自动掩码被添加到SA-V数据集中。被识别为“不满意”的掩码(即模型失败案例)会被抽样并呈现给注释者,以便在数据引擎的第三阶段使用SAM 2进行细化。这些自动掩码涵盖了大型显著的中心物体,以及背景中大小和位置各异的物体。

分析。表1通过控制实验(详情见附录D.2.2)比较了每个数据引擎阶段的注释协议。我们比较了每帧的平均注释时间、每个掩码手动编辑帧的平均百分比,以及每个点击帧的平均点击次数。为了质量评估,我们定义了第一阶段掩码对齐分数,即与第一阶段相应掩码的IoU超过0.75的掩码的百分比。选择第一阶段数据作为参考,因为它有每帧高质量的手动注释。第三阶段使用SAM 2的循环,提高了效率且质量可比:比第一阶段快8.4倍,编辑帧百分比和每帧点击次数最低,并且对齐效果更好。

在表2中,我们展示了在每个阶段结束时使用可用数据训练的SAM 2的性能比较,保持迭代次数固定,因此仅测量额外数据的影响。我们在我们自己的SA-V验证集上进行评估,并且还在9个零样本基准测试上进行评估(有关详细信息,请参见附录E.1),使用标准J&F准确度度量(越高越好)在第一帧上使用3次点击提示。我们注意到,在每个阶段的数据迭代包含后,不仅在域内SA-V验证集上,而且在9个零样本基准测试上,性能都持续提高。

5.2 SA-V数据集
我们的数据引擎收集的SA-V数据集包括50.9K视频和642.6K掩码。在表3中,我们比较了SA-V组成与常见VOS数据集在视频数量、掩码数量和掩码方面的比较。值得注意的是,注释掩码的数量比任何现有的VOS数据集大53倍(没有自动注释为15倍),为未来的工作提供了大量资源。我们将在宽松的许可下发布SA-V。

视频。我们收集了由众包工人拍摄的50.9K新视频集。视频包括54%的室内和46%的室外场景,平均时长为14秒。视频展示了“野外”多样化的环境,并涵盖了各种日常场景。我们的数据集比现有的VOS数据集拥有更多的视频,如图5所示,视频涵盖了47个国家,并由多样化的参与者(自我报告的人口统计数据)拍摄。

掩码。注释包括190.9K手动掩码注释和451.7K使用我们的数据引擎收集的自动掩码。图4显示了叠加了掩码(手动和自动)的示例视频。SA-V比最大的VOS数据集多53倍(没有自动注释为15倍)的掩码。SA-V手动(在至少一帧中消失然后重新出现的注释掩码的百分比)的消失率为42.5%,在现有数据集中具有竞争力。图5a显示了与DAVIS、MOSE和YouTubeVOS的掩码大小分布(按视频分辨率归一化)的比较。超过88%的SA-V掩码的归一化掩码面积小于0.1。
SA-V训练、验证和测试拆分。我们根据视频作者(及其地理位置)拆分SA-V,以确保类似对象的重叠最小。为了创建SA-V验证集和SA-V测试集,我们专注于选择具有挑战性场景的视频,并要求注释者识别具有快速移动、与其他物体复杂遮挡以及消失/重新出现模式的具有挑战性的目标。这些目标使用§5.1中的数据引擎第一阶段设置以6 FPS进行注释。SA-V验证拆分中有293个掩码和155个视频,SA-V测试拆分中有278个掩码和150个视频。
内部数据集。我们还使用内部可用的许可视频数据进一步增加了我们的训练集。我们的内部数据集包括62.9K视频和69.6K掩码,这些掩码在第二阶段和第三阶段(见§5.1)中注释,用于训练,以及使用第一阶段注释的96个视频和189个掩码用于测试(Internal-test)。
有关数据引擎和SA-V数据集的更多详细信息,请参见附录D。
6 零样本实验
在这里,我们将SAM 2与先前在零样本视频任务(§6.1)和图像任务(§6.2)上的研究成果进行比较。我们报告了视频任务的标准 J & F \mathcal{J} \& \mathcal{F} J&F指标(Pont-Tuset等人,2017)以及图像任务的mIoU指标。除非另有说明,本节报告的结果遵循我们使用Hiera-B+图像编码器的默认设置,分辨率为1024,并在所有数据集的完整组合上进行训练,即表7中的SAM 2(Hiera-B+)(详见§C. 2了解更多细节)。
6.1 视频任务
6.1.1 提示视频分割
我们首先评估可提示的视频分割,这涉及模拟类似于用户体验的交互式设置。我们有两种设置,离线评估,通过视频多次传递以选择基于最大模型误差的交互帧,以及在线评估,通过视频的单次前向传递进行帧注释。这些评估是在9个密集注释的零样本视频数据集上进行的,每个帧使用 N click = 3 N_{\text{click}}=3 Nclick=3次点击(详见§E.1了解更多细节)。
我们创建了两个强大的基线,SAM + XMem ++和SAM + Cutie,基于两个视频对象分割的最新模型,XMem++(Bekuzarov等人,2023)和Cutie(Cheng等人,2023a)。我们使用XMem ++基于一个或多个帧上的掩码输入生成视频分割。SAM用于提供初始掩码或通过将当前分割作为掩码提示输入到SAM来细化输出。对于SAM + Cutie基线,我们修改了Cutie,允许在多个帧上接收掩码输入。

在图6中,我们报告了在 N frame = 1 , … , 8 N_{\text{frame}}=1, \ldots, 8 Nframe=1,…,8个交互帧上的平均 J & F \mathcal{J} \& \mathcal{F} J&F准确度。SAM 2在离线和在线评估设置中均优于SAM + XMem ++和SAM + Cutie。在所有9个数据集上(详见§E.1的每个数据集结果),SAM 2在两种方法中都占主导地位,确认SAM 2能够从几次点击中生成高质量的视频分割,同时也允许通过进一步的提示继续细化结果。总体而言,SAM 2能够生成更好的分割准确度,与之前的方法相比,交互次数减少了3倍以上。
6.1.2 半监督视频对象分割
接下来,我们评估半监督视频对象分割(VOS)设置(Pont-Tuset等人,2017),仅在视频的第一帧上使用点击、框或掩码提示。当使用点击提示时,我们交互式地在第一帧视频上采样1、3或5次点击,然后基于这些点击进行对象跟踪。

类似于§6.1.1中的交互设置,我们与XMem++和Cutie进行比较,使用SAM进行点击和框提示,在默认设置下使用掩码提示。我们报告了标准的 J & F \mathcal{J} \& \mathcal{F} J&F准确度(Pont-Tuset等人,2017),除了在VOST(Tokmakov等人,2022)上,我们遵循其协议报告 J \mathcal{J} J指标。结果在表4中。SAM 2在17个数据集上超越了两个基线,使用了各种输入提示。结果强调了SAM 2在传统的非交互式VOS任务中也表现出色,这些任务是专门为这些其他工作设计的。更多细节在§E.1.3。
6.1.3 公平性评估
我们评估SAM 2在不同人群间的公平性。我们在EgoExo4D(Grauman等人,2023)数据集中收集了“人”类别的注释,该数据集包含了视频主体自报的人口统计信息。我们采用与SA-V验证和测试集相同的注释设置,并将其应用于第三人称(exo)视频的20秒片段。我们使用1次、3次点击和第一帧的真实掩码提示在这些数据上评估SAM 2。

表5显示了SAM 2在按性别和年龄分割人群方面的 J & F \mathcal{J} \& \mathcal{F} J&F准确度比较。在3次点击和真实掩码提示下,差异很小。我们手动检查了1次点击的预测,发现模型经常预测部分的掩码而不是人。当将比较限制在正确分割人的片段时,1次点击的差距大幅缩小(男性 J & F \mathcal{J} \& \mathcal{F} J&F为94.3,女性为92.7),这表明差异部分可以归因于提示的模糊性。
在附录G中,我们为SA-V提供了模型、数据和注释卡片。
6.2 图像任务
我们在37个零样本数据集上评估SAM 2在“分割任何东西”任务上的表现,包括SAM先前用于评估的23个数据集。1次点击和5次点击的mIoUs在表6中报告,我们展示了在单个A100 GPU上每秒帧数(FPS)的平均mIoU,以及每个数据集领域和模型速度。

第一列(SA-23 All)显示了在SAM的23个数据集上的准确性。SAM 2的准确性更高(1次点击时为58.9 mIoU),超过了SAM(1次点击时为58.1 mIoU),而且没有使用任何额外数据,同时速度提高了 6 \mathbf{6} 6倍。这主要归因于SAM 2中更小但更有效的Hiera图像编码器。
最后一行显示了我们如何通过在SA-1B和视频数据混合上训练,进一步提高准确性到23个数据集上的平均61.4%。我们还看到在SA-23的视频基准测试中取得了显著提升(视频数据集作为图像进行评估,与Kirillov等人(2023)相同),以及我们添加的14个新的视频数据集。
总体而言,这些发现强调了SAM 2在交互式视频和图像分割的双重能力,这种优势来自于我们多样化的训练数据,涵盖了跨视觉领域视频和静态图像。更多详细结果,包括按数据集细分的结果在§E.3中。
7 与半监督VOS的最新技术的比较
我们的主要关注点是一般的、交互式PVS任务,但我们也解决了特定的半监督VOS设置(提示是第一帧上的真实掩码),因为它是一个历史上常见的协议。我们评估了两种不同图像编码器大小的SAM 2版本(Hiera-B±L),具有不同的速度与准确性权衡。我们在单个A100 GPU上使用批量大小为一来测量每秒帧数(FPS)。基于Hiera-B+和Hiera-L的SAM 2分别以43.8和30.2 FPS的实时速度运行。

我们在表7中展示了与现有最新技术的比较,报告了使用标准协议的准确性。SAM 2在所有方面都显示出比现有最佳方法有显著改进。我们观察到使用更大的图像编码器可以在所有方面带来显著的准确性提升。
我们还在SA-V验证和测试集上评估了现有工作,这些集衡量了“任何”对象类别的开放世界分割的性能。在这一基准上进行比较时,我们发现大多数先前的方法在大约相同的准确性达到峰值。先前工作在SA-V验证和SA-V测试上的最佳性能显著较低,证明了与“在视频中分割任何东西”的能力之间的差距。最后,我们看到SAM 2在长期视频对象分割方面也带来了显著的提升,如在LVOS基准测试结果中观察到的。
8 数据和模型消融
本节介绍了为SAM 2的设计决策提供信息的消融研究。我们在MOSE开发集(“MOSE dev”)上进行评估,该集包含从MOSE训练分割中随机抽取的200个视频,并从我们的消融训练数据中排除,SA-V验证,以及9个零样本视频基准的平均值。作为比较的指标,我们在第一帧上使用3次点击报告 J & F \mathcal{J} \& \mathcal{F} J&F,作为1次点击制度和VOS风格掩码提示之间的平衡。此外,我们报告了在SAM用于SA任务的23个数据集基准上使用1次点击的平均mIoU。除非另有规定,我们以512分辨率运行我们的消融,并使用SA-V手动和SA-1B的10%子集。更多细节在§C.2中。
8.1 数据消融
数据混合消融。在表8中,我们比较了在不同数据混合上训练的SAM-2的准确性。我们先在SA-1B上预训练,然后为每个设置训练一个单独的模型。我们固定迭代次数(200k)和批量大小(128),实验之间只有训练数据发生变化。我们在SA-V验证集、MOSE、9个零样本视频基准和SA-23任务(§6.2)上报告准确性。第1行显示,仅在VOS数据集(Davis、MOSE、YouTubeVOS)上训练的模型在领域内的MOSE dev上表现良好,但在所有其他数据集上表现不佳,包括9个零样本VOS数据集(59.7 J & F \mathcal{J} \& \mathcal{F} J&F)。
我们观察到将我们的数据引擎数据添加到训练混合中带来了巨大的好处,包括在9个零样本数据集上平均性能提高了 + 12.1 \boldsymbol{+ 12.1} +12.1%(第11行与第1行相比)。这可以归因于VOS数据集的有限覆盖范围和大小。添加SA-1B图像提高了图像分割任务的性能(第3行与第4行、第5行与第6行、第9行与第10行、第11行与第12行相比),而没有降低VOS能力。仅在SA-V和SA-1B上训练(第4行)就足以在所有基准上获得强大的性能,除了MOSE。总体而言,当我们混合所有数据集:VOS、SA-1B和我们的数据引擎数据时,我们获得了最佳结果(第12行)。
数据量消融。接下来,我们研究了扩大训练数据的影响。SAM 2在SA-1B上预训练,然后在不同大小的SA-V上训练。我们在3个基准上报告平均 J & F \mathcal{J} \& \mathcal{F} J&F得分(在第一帧上提示3次点击),包括SA-V验证、零样本和MOSE开发。图7显示了训练数据量与所有基准上的视频分割准确性之间的一致幂律关系。

数据质量消融。在表9中,我们尝试了基于质量的过滤策略。我们从SA-V中抽取了50k个掩码,要么随机抽取,要么选择被注释者编辑次数最多的掩码。基于编辑帧数的过滤仅使用25%的数据就可以获得强大的性能,并且优于随机抽样。然而,它比使用所有190k SA-V掩码要差。

8.2 模型架构消融
在本节中,我们介绍了指导设计决策的模型消融,这些消融在默认情况下使用512输入分辨率的较小模型设置下进行。对于每个消融设置,我们报告了视频( J & F \mathcal{J} \& \mathcal{F} J&F)和图像(mIoU)任务的分割准确性,以及其相对于视频分割速度的视频(灰色中的最大推理吞吐量相对于消融默认设置)。我们发现图像和视频组件的设计选择在很大程度上是解耦的——这可以归因于我们的模块化设计和训练策略。
8.2.1 容量消融
输入尺寸。在训练期间,我们采样了固定分辨率和固定长度(这里表示为#帧)的帧序列。我们在表10a、10b中消融了它们的影响。更高的分辨率在图像和视频任务上都带来了显著的改进,我们在最终模型中使用1024的输入分辨率。增加帧数在视频基准测试上带来了显著的增益,我们使用默认值8来平衡速度和准确性。

内存大小。增加(最大)记忆数量 N N N,通常有助于性能,尽管可能会有一些变化,如表10c所示。我们使用默认值6个过去帧来平衡时间上下文长度和计算成本。使用较少的通道进行记忆不会引起太大的性能退化,如表10d所示,同时使存储所需的记忆缩小4倍。
模型大小。图像编码器或记忆-注意力(#自/#交叉注意力块)的容量越大,通常会导致更好的结果,如表10e、10f所示。扩展图像编码器在图像和视频指标上都带来了增益,而扩展记忆-注意力只改善了视频指标。我们默认使用B+图像编码器,它在速度和准确性之间提供了合理的平衡。
8.2.2 相对位置编码
默认情况下,我们总是在图像编码器以及记忆注意力中使用绝对位置编码。在表11中,我们研究了相对位置编码的设计选择。我们还以LVOSv2(Hong等人,2024)作为长期视频对象分割的基准进行评估,使用第一帧上的3次点击。

尽管SAM(Kirillov等人,2023)遵循Li等人(2022b)在所有图像编码器层中添加相对位置偏置(RPB),Bolya等人(2023)通过在除全局注意力层之外的所有层中移除RPB并采用“绝对赢”位置编码来提高速度。我们通过从图像编码器中移除所有RPB进一步改进这一点,没有在SA-23上引起性能退化,并且在视频基准测试上只有最小的退化(见表11),同时在1024分辨率下显著提高了速度。我们还发现在记忆注意力中使用2d-RoPE(Su等人,2021;Heo等人,2024)是有益的。
8.2.3 记忆架构消融
循环记忆。我们研究了在将记忆特征添加到记忆库之前,先将其输入GRU的有效性。类似于§8.2.2,我们还以LVOSv2作为长期对象分割的额外基准进行评估。虽然以前的工作通常采用GRU(Cho等人,2014)状态作为将记忆纳入跟踪过程的一种手段,我们在表12中的发现表明这种方法并没有提供改进(除了在LVOSv2上稍微改进)。相反,我们发现直接将记忆特征存储在记忆库中就足够了,这既简单又高效。
对象指针。我们消融了在其他帧中从掩码解码器输出的交叉注意对象指针向量的影响(见§4)。表12中呈现的结果表明,虽然在9个零样本数据集上交叉注意对象指针并没有提高平均性能,但它显著提高了SA-V验证数据集以及具有挑战性的LVOSv2基准(验证分割)的性能。因此,我们默认与记忆库一起交叉注意对象指针。

9 结论
我们提出了将“分割任何东西”自然演变到视频领域的方案,基于三个关键方面:(i) 将可提示的分割任务扩展到视频,(ii) 为应用于视频时使用记忆功能的SAM架构配备工具,以及(iii) 用于训练和基准测试视频分割的多样化SA-V数据集。我们认为SAM 2在视觉感知方面标志着一个重大进步,我们的贡猃将作为推动该领域进一步研究和应用的里程碑。
10 致谢
我们感谢Alexander Kirillov和Jitendra Malik就项目方向进行的讨论。感谢Andrew Huang、Sahir Gomez、Miguel Martin、Devansh Kukreja和Somya Jain在演示工作上的贡献,以及Aohan Lin和Meng Wang创建的数据集可视化工具。我们感谢Shoubhik Debnath和Sagar Vaze在数据集准备上的工作。还感谢William Ngan和Sasha Mitts的设计专长,以及Grant Gardner和George Orlin在产品管理上的领导。我们对Joelle Pineau、Daniel Bolya、Kate Saenko、Pengchuan Zhang和Christopher Chedeau的宝贵讨论表示感谢。感谢Rene Martinez Doehner和Baishan Guo的数据支持,以及我们的注释工程和管理合作伙伴:Robert Kuo、Rishi Godugu、Bob Kamma、Ida Cheng、Claudette Ward、Kai Brown、Jake Kinney、Jenny Truong和Karen Bergan。感谢Vispi Cassod、Parth Malani、Shiva Koduvayur、Alexander Miller和Caleb Ho在计算和基础设施方面的支持。最后,我们感谢Azita Shokrpour、Mallika Malhotra、Rodrick Shepard、Jonathan Torres、Luc Dahlin、David Soofian、Alex Bosenberg和Amanda Kallet在项目级支持上的贡献。
附录
目录:
- A:任务细节
- §B:局限性
- §C:模型细节
- §D:数据集细节
- §E:零样本实验细节
- §G:数据集、注释和模型卡片
- §D.2.1:注释指南
A PVS任务的细节
可提示的视觉分割(PVS)任务可以看作是将静态图像中的“分割任何东西”(SA)任务扩展到视频。在PVS设置中,给定一个输入视频,模型可以通过视频的任何帧上不同类型的输入(包括点击、框或掩码)进行交互式提示,目标是在视频中分割(和跟踪)一个有效对象。与视频交互时,模型对被提示的帧提供即时响应(类似于SAM在图像上的交互体验),并且还几乎实时返回整个视频对象的分割。与SAM一样,重点是有明确定义边界的有效对象,我们不考虑没有视觉边界的区域(例如Bekuzarov等人,2023)。图8说明了任务。

PVS与静态图像和视频领域的几个任务相关。在图像上,SA任务可以被认为是PVS的一个子集,将视频减少到单个帧。同样,传统的半监督和交互式VOS(Pont-Tuset等人,2017)任务是PVS的特殊情况,仅限于在第一帧上提供掩码提示,以及在多个帧上使用涂鸦来分割视频对象。在PVS中,提示可以是点击、掩码或框,重点是增强交互体验,使对象的分割能够通过最少的交互轻松细化。
B 局限性
SAM 2在静态图像和视频领域都展现出强大的性能,但在某些场景中仍会遇到困难。该模型可能无法在镜头变化中分割对象,并且在拥挤场景中、长时间遮挡后或在扩展视频中可能会丢失或混淆对象的跟踪。为了缓解这个问题,我们设计了在任何帧上提示SAM 2的能力:如果模型丢失了对象或犯了错误,额外帧上的细化点击可以在大多数情况下迅速恢复正确的预测。SAM 2在准确跟踪非常细薄或细节丰富的快速移动对象时也存在困难。另一个具有挑战性的场景是当附近有外观相似的对象时(例如,多个相同的杂耍球)。将更明确的动作建模纳入SAM 2可以减少这类情况下的错误。
尽管SAM 2可以同时在视频中跟踪多个对象,但SAM 2是分别处理每个对象的,只利用每帧共享的嵌入,没有对象间通信。虽然这种方法简单,但纳入共享的对象级上下文信息可能有助于提高效率。
我们的数据引擎依赖于人类注释者来验证掩码质量并选择需要修正的帧。未来的开发可以包括自动化这一过程以提高效率。
C SAM 2细节
C. 1 架构
在这里,我们进一步讨论架构细节,扩展了§4中对模型的描述。
图像编码器。我们使用特征金字塔网络(Lin等人,2017),融合了Hiera图像编码器的第3和第4阶段的步幅16和32特征,分别产生每帧的图像嵌入。此外,第1和第2阶段的步幅4和8特征不用于记忆注意力,但如图9所示,它们被添加到掩码解码器的上采样层中,这有助于产生高分辨率的分割细节。我们遵循Bolya等人(2023)在Hiera图像编码器中使用窗口化的绝对位置嵌入。在Bolya等人(2023)中,RPB提供了跨越图像编码器中窗口的位置信息,我们采用了一种更简单的方法,即插值全局位置嵌入以跨越窗口。我们不使用任何相对位置编码。我们训练了具有不同图像编码器大小的模型 - T、S、B+和L。我们遵循Li等人(2022b),只在图像编码器的子集中使用全局注意力(见表13)。
记忆注意力。除了正弦绝对位置嵌入外,我们还在自注意力和交叉注意力层中使用2D空间旋转位置嵌入(RoPE)(Su等人,2021;Heo等人,2024)。对象指针令牌被排除在RoPE之外,因为它们没有特定的空间对应关系。默认情况下,记忆注意力使用L=4层。
提示编码器和掩码解码器。提示编码器设计遵循SAM,接下来我们讨论掩码解码器中的设计变更细节。我们使用对应于输出掩码的掩码令牌作为帧的对象指针令牌,将其放置在记忆库中。如§4中所讨论的,我们还引入了一个遮挡预测头。这是通过在掩码和IoU输出令牌中包含一个额外的令牌来实现的。对这个新令牌应用额外的MLP头,以产生一个分数,指示当前帧中感兴趣对象的可见性概率(如图9所示)。

SAM引入了在面对图像中被分割对象的不确定性时输出多个有效掩码的能力。例如,当一个人点击自行车的轮胎时,模型可以将此点击解释为仅指轮胎或整个自行车,并输出多个预测。在视频中,这种不确定性可以延伸到视频帧。例如,如果在一个帧中只可见轮胎,对轮胎的点击可能仅与轮胎有关,或者随着后续帧中更多自行车变得可见,这个点击可能是针对整个自行车的。为了处理这种不确定性,SAM 2在视频的每个步骤预测多个掩码。如果进一步的提示没有解决不确定性,模型将选择当前帧预测IoU最高的掩码以进一步在视频中传播。
记忆编码器和记忆库。我们的记忆编码器不使用额外的图像编码器,而是重用Hiera编码器产生的图像嵌入,这些嵌入与预测的掩码信息融合,以产生记忆特征(如§4中所讨论)。这种设计允许记忆特征从图像编码器产生的强表示中受益(特别是当我们将图像编码器扩展到更大的大小时)。此外,我们将记忆库中的记忆特征投影到64维,并将256维的对象指针分割成4个64维的令牌,以便与记忆库进行交叉注意力。
C. 2 训练
C.2.1 预训练
我们首先在SA-1B数据集(Kirillov等人,2023)上对静态图像进行SAM 2的预训练。表13a详细说明了在SA-1B上预训练期间使用的设置 - 这里未提及的其他设置遵循Kirillov等人(2023)。图像编码器从MAE预训练的Hiera(Ryali等人,2023)初始化。与SAM类似,我们过滤掉覆盖超过90%图像的掩码,并将训练限制在每张图像随机抽样的64个掩码上。
与SAM不同,我们发现使用 ℓ 1 \ell_{1} ℓ1损失更有力地监督IoU预测,并应用sigmoid激活到IoU logits上,以将输出限制在0和1之间是有益的。对于多掩码预测(在第一次点击上),我们监督所有掩码的IoU预测以鼓励更好地学习何时掩码可能不好,但只监督具有最低分割损失(focal和dice损失的线性组合)的掩码logits。在SAM中,在迭代抽样点期间,插入了两次没有额外提示的迭代(只提供先前的掩码logits) - 我们在训练期间不添加这样的迭代,并使用7个修正点击(而不是SAM中的8个)。我们还在训练期间使用水平翻转增强,并将图像调整为1024×1024的正方形大小。
我们使用AdamW(Loshchilov & Hutter,2019)并对图像编码器应用层衰减(Clark等人,2020),并遵循互反平方根计划(Zhai等人,2022)。有关我们预训练阶段的超参数,请参见表13(a)。
C.2.2 全面训练
预训练后,我们在我们引入的数据集SA-V + Internal(第§5.2节)、SA-1B的10%子集,以及包括DAVIS(Pont-Tuset等人,2017;Caelles等人,2019)、MOSE(Ding等人,2023)和YouTubeVOS(Xu等人,2018b)在内的混合开源视频数据集上训练SAM 2。我们发布的模型是在SA-V手动 + Internal和SA-1B上训练的。

SAM 2旨在执行两项任务;PVS任务(在视频上)和SA任务(在图像上)。训练是在图像和视频数据上联合进行的。为了在训练期间优化我们的数据使用和计算资源,我们采用了视频数据(多帧)和静态图像(单帧)之间的交替训练策略。具体来说,在每次训练迭代中,我们从图像或视频数据集中采样一个完整批次,它们的采样概率与每个数据源的大小成比例。这种方法允许平衡地接触这两项任务,并为每个数据源使用不同的批次大小以最大化计算利用率。这里未明确提及的图像任务设置遵循预训练阶段的设置。有关我们全面训练阶段的超参数,请参见表13(b)。训练数据混合包括约15.2%的SA-1B、约70%的SA-V和约14.8%的Internal。当包括开源数据集时,使用相同的设置,变化在于包括了额外的数据(约1.3%的DAVIS、约9.4%的MOSE、约9.2%的YouTubeVOS、约15.5%的SA-1B、约49.5%的SA-V、约15.1%的Internal)。
我们通过模拟交互式设置进行训练,采样8帧序列,并随机选择最多2帧(包括第一帧)进行修正点击。在训练期间,我们使用真值掩码和模型预测来采样提示,初始提示为真值掩码(50%的概率)、真值掩码的正点击(25%)或边框输入(25%)。我们将每个8帧序列的最大掩码数量限制为随机选择的3个。我们以50%的概率逆转时间顺序,以帮助双向传播的泛化。当我们采样修正点击时 - 以10%的小概率,我们随机从真值掩码中采样点击,而不考虑模型预测,以允许在掩码细化中增加额外的灵活性。
损失和优化。我们使用焦点和dice损失的线性组合来监督模型的掩码预测,IoU预测的均方绝对误差(MAE)损失,以及对象预测的交叉熵损失,比例分别为20:1:1:1。与预训练期间一样,对于多掩码预测,我们只监督具有最低分割损失的掩码。如果真值不包含某一帧的掩码,我们不监督任何掩码输出(但总是监督预测该帧是否应该存在掩码的遮挡预测头)。
C. 3 速度基准测试
我们在单个A100 GPU上使用PyTorch 2.3.1和CUDA 12.1进行所有基准测试实验,使用自动混合精度bfloat16。我们为所有SAM 2模型编译图像编码器torch.compile,并为SAM和HQ-SAM做同样的事情,以便在SA任务上进行直接比较(表6和15)。SA任务的FPS测量使用10张图像的批次大小进行,发现这是所有三种模型类型中FPS最高的。对于视频任务,我们遵循视频分割中的常见协议,使用1的批次大小。
D 数据细节
D. 1 SA-V数据集细节
视频。分辨率从240p到4K不等,平均为1,401×1,037。时长从4秒到2.3分钟不等,平均为13.8秒,总计420万帧和196小时。
自动掩码。类似于Kirillov等人(2023)描述的方法,通过在规则网格上提示模型生成自动掩码。我们在第一帧上使用32×32网格提示模型,并在第一帧的4个缩放图像裁剪(来自2×2重叠窗口)上额外使用16×16网格,在第一帧的16个缩放图像裁剪(来自4×4重叠窗口)上使用4×4网格。我们对所有帧应用两个后处理步骤。首先,我们移除面积小于200像素的微小断开组件。其次,如果孔洞面积小于200像素,则填充分割掩码中的孔洞。通过将这些自动生成的掩码与手动创建的掩码结合,我们增强了SA-V数据集中注释的覆盖范围,如图10所示。

D.2 数据引擎细节
D.2.1 注释协议
我们数据引擎中使用的注释协议的图示如图11所示。注释任务被分为由不同注释者执行的步骤:步骤1和2专注于对象选择,步骤3和4专注于掩码跟踪,步骤5专注于质量验证。SAM 2部署在GPU上作为API并内置于注释工具中,以实现交互式使用。

与图像分割注释相比,大规模视频分割注释提出了独特的挑战,这要求在注释任务设计和协议上进行创新。为了提高我们模型“分割任何东西”的能力,专注于注释SAM 2在其中挣扎的具有挑战性的对象是很重要的。我们利用我们的在线模型在循环设置中启用此功能,要求注释者使用SAM 2交互式地识别失败模式,然后进行修正。
我们发现编辑帧的数量是对象“挑战性”的代理,如表9所示。因此,我们要求注释者注释至少需要2个编辑帧的SAM 2循环中的物体。为了专注于不太显眼和更具挑战性的情况,注释者被呈现了预先填充了经过验证的令人满意的自动掩码的视频,并被要求找到未注释的具有挑战性的对象。我们进一步将对象选择任务与注释任务解耦:在选择任务中,注释者专注于选择一帧中的具有挑战性的物体,而在注释任务中,注释者被呈现了一个具有挑战性的目标物体,并被要求在整个视频中一致地注释掩码。
D.2.2 数据引擎阶段比较
表1中显示的数据引擎阶段比较是作为一项控制实验进行的,使用了169个视频和452个掩码。我们要求三组不同的注释者使用每个阶段的注释协议对同一组对象进行注释。我们根据第一帧中的掩码区域将掩码分为三类(小:1至 3 2 2 32^2 322,中: 3 2 2 32^2 322至 9 6 2 96^2 962,和大:等于或大于 9 6 2 96^2 962)。第一阶段的数据被用作质量参考,因为通过SAM逐帧手动注释产生了高质量的掩码。
E 关于零样本转移实验的更多细节
在本节中,我们描述了我们零样本实验(§6)的更多细节。除非另有说明,本节报告的结果遵循我们使用1024分辨率的Hiera-B+图像编码器的默认设置,并在所有数据集的完整组合上进行训练,即表7中的SAM 2(Hiera-B+)。
E.1 零样本视频任务
E.1.1 视频数据集细节
我们在17个零样本数据集的多样化基准上评估SAM 2:EndoVis 2018(Allan等人,2020)包含带有机器人器械的医学手术视频。ESD(Huang等人,2023)包含来自机器人操纵器相机的视频,通常带有运动模糊。LVOSv2(Hong等人,2024)是长期视频对象分割的基准。LV-VIS(Wang等人,2023)包含来自多样化开放词汇对象类别的视频。UVO(Wang等人,2021b)包含用于开放世界对象分割的视频,VOST(Tokmakov等人,2022)包含经历巨大变化的对象的视频,如鸡蛋破裂或纸张撕裂。PUMaVOS(Bekuzarov等人,2023)包含围绕对象部分(如人脸颊)的视频片段。Virtual KITTI 2(Cabon等人,2020)是一个带有驾驶场景的合成视频数据集。VIPSeg(Miao等人,2022)在全景视频中提供对象分割。Wildfires(Toulouse等人,2017)包含不同条件下的野火视频,来自科西嘉火数据库。VISOR(Darkhalil等人,2022)包含厨房场景中的自我中心视频,围绕手和活跃对象的片段。FBMS(Brox等人,2010)在视频中提供移动对象的运动分割。Ego-Exo4D(Grauman等人,2023)是一个包含各种人类活动自我中心视频的大型数据集。Cityscapes(Cordts等人,2016)包含城市驾驶场景的视频。Lindenthal Camera(Haucke & Steinhage,2021)包含野生公园中的视频,围绕观察到的动物(如鸟类和哺乳动物)的片段。HT1080WT Cells(Gómez-de Mariscal等人,2021)包含带有细胞片段的显微镜视频。Drosophila Heart(Fishman等人,2023)包含果蝇心脏的显微镜视频。
在上述17个零样本视频数据集中,有9个(EndoVis、ESD、LVOSv2、LV-VIS、UVO、VOST、PUMaVOS、Virtual KITTI 2和VIPSeg)在每个视频帧上都有密集的对象片段注释。在其余8个数据集(Wildfires、VISOR、FBMS、Ego-Exo4D、Cityscapes、Lindenthal Camera、HT1080WT Cells和Drosophila Heart)中,对象片段仅在部分视频帧上稀疏注释,我们计算在有真值分割掩码可用的帧上的指标。在本文的大多数评估中,我们仅在9个密集注释的数据集上评估零样本性能,而在我们半监督VOS评估(§6.1.2)中,我们在上述所有17个数据集上进行评估。
E.1.2 交互式离线和在线评估细节
离线评估涉及对整个视频的多次传递。我们从第一帧上的点击提示开始,在整个视频中分割对象,然后在下一次传递中,我们选择与真值相比分割IoU最低的帧作为新的提示帧。然后,模型根据之前收到的所有提示再次在整个视频中分割对象,直到达到最大传递次数 N frame N_{\text{frame}} Nframe(每次传递中有一个新提示的帧)。
在线评估只涉及对整个视频的一次传递。我们从第一帧上的点击提示开始,并在视频中传播提示,当遇到预测质量低(与真值的IoU<0.75)的帧时暂停传播。然后我们在这暂停的帧上增加额外的点击提示来纠正该帧上的分割,并恢复向前传播,直到遇到另一个IoU<0.75的低质量帧。在提示帧的数量小于最大 N frame N_{\text{frame}} Nframe时重复此操作。与之前的离线评估不同,在这种设置中,新的提示只影响当前暂停帧之后的帧,而不会影响之前的帧。
在两种设置中,我们都在§E.1.1中的9个密集注释的数据集上进行评估(EndoVis、ESD、LVOSv2、LV-VIS、UVO、VOST、PUMaVOS、Virtual KITTI 2和VIPSeg)。如果视频的真值注释中包含多个要分割的对象,我们独立地对每个对象进行推断。我们模拟交互式视频分割,每个帧上有 N click = 3 N_{\text{click}}=3 Nclick=3次点击,假设用户会视觉上定位要标记的对象(通过初始点击)或通过修正点击来细化当前的分割预测。具体来说,在开始第一次传递时(还没有现有预测),我们在第一帧上对象真值掩码的中心放置一个初始点击,然后根据第一帧上错误区域的中心(真值掩码和预测片段之间)交互式地增加两个更多点击。然后在后续传递中(已经有预测片段),我们根据被提示帧上错误区域的中心(真值掩码和预测片段之间)交互式地增加三个点击。
我们报告了在 N frame = 1 , … , 8 N_{\text{frame}}=1, \ldots, 8 Nframe=1,…,8个交互帧上的平均 J & F \mathcal{J} \& \mathcal{F} J&F指标,以及基于以下假设在视频上不同注释时间下的 J & F \mathcal{J} \& \mathcal{F} J&F指标:
- 在每个帧上,注释者需要 T loc = 1 T_{\text{loc}}=1 Tloc=1秒来视觉上定位帧中的对象,并且 T click = 1.5 T_{\text{click}}=1.5 Tclick=1.5秒来添加每个点击,遵循Delatolas等人(2024)。
- 在离线模式下,在一个300帧的视频上,每次检查整个视频的结果需要 T exam = 30 T_{\text{exam}}=30 Texam=30秒,包括找到分割质量最差的帧以添加修正(对于更长或更短的视频,这个时间与视频长度 L L L成正比,假设注释者可以以10 FPS的速度检查结果)。
- 在在线模式下,在一个300帧的视频上,总共需要 T exam = 30 T_{\text{exam}}=30 Texam=30秒来跟踪整个视频的结果,包括在质量低的帧上暂停以进行进一步修正(这个时间与视频长度 L L L成正比,与离线模式类似)。
- 在离线模式下,一个对象的注释时间是 ( T exam ⋅ ( L / 300 ) + T loc + T click ⋅ N click ) ⋅ N frame (T_{\text{exam}} \cdot(L / 300)+T_{\text{loc}}+T_{\text{click}} \cdot N_{\text{click}}) \cdot N_{\text{frame}} (Texam⋅(L/300)+Tloc+Tclick⋅Nclick)⋅Nframe,在在线模式下是 T exam ⋅ ( L / 300 ) + ( T loc + T click ⋅ N click ) ⋅ N frame T_{\text{exam}} \cdot(L / 300)+(T_{\text{loc}}+T_{\text{click}} \cdot N_{\text{click}}) \cdot N_{\text{frame}} Texam⋅(L/300)+(Tloc+Tclick⋅Nclick)⋅Nframe,其中 L L L是视频中的总帧数, N frame = 1 , … , 8 N_{\text{frame}}=1, \ldots, 8 Nframe=1,…,8是注释的帧数(即交互轮数), N click = 3 N_{\text{click}}=3 Nclick=3是每个帧的点击数。

我们在图12和图13中展示了SAM 2和两个基线(SAM + XMem++和SAM + Cutie,见下文详细信息)在交互式离线和在线评估的每个数据集结果。SAM 2在所有数据集和设置上都以显著的优势超越了两个基线。

E.1.3 半监督VOS评估细节
在§6.1.2中,我们还在半监督VOS设置下与以往的视频跟踪方法进行比较(Pont-Tuset等人,2017),其中提示(可以是前景/背景点击、边界框或真实对象掩码)仅在视频的第一帧上提供。当使用点击提示时,我们交互式地在第一帧上采样1、3或5次点击,然后基于这些点击进行对象跟踪。遵循先前工作中基于点击的评估(Kirillov等人,2023;Sofiiu等人,2022),初始点击放置在对象中心,后续点击从错误区域中心获取。
类似于交互式设置,这里我们也使用SAM + XMem++和SAM + Cutie作为两个基线。对于点击或框提示,首先使用SAM处理点击或边界框输入,然后其输出掩码用作XMem++或Cutie的输入。对于掩码提示,第一帧上的真实对象掩码直接用作XMem++和Cutie的输入 - 这是标准的半监督VOS设置,评估XMem++和Cutie不使用SAM。
在这种设置下,我们在§E.1.1中的所有17个零样本视频数据集上进行评估。如果数据集不遵循标准VOS格式,我们将其预处理成类似于MOSE(Ding等人,2023)的格式。在处理过程中,我们确保每个视频中的所有对象在第一帧上都有一个有效非空的分割掩码,以兼容半监督VOS评估。如果对象没有出现在第一帧中,我们为其创建一个从对象出现的第一帧开始的单独视频。
我们报告这种评估的标准 J & F \mathcal{J} \& \mathcal{F} J&F指标(Pont-Tuset等人,2017)。如果数据集提供了官方评估工具包,我们使用它进行评估(在VOST数据集上,我们报告 J \mathcal{J} J指标,遵循其官方协议(Tokmakov等人,2022))。结果在表4中显示,SAM 2在大多数17个数据集上的表现优于两种基线。

我们在图14中展示了SAM 2和两个基线(SAM + XMem++和SAM + Cutie,见下文详细信息)在半监督VOS评估的每个数据集结果。SAM 2在大多数这些数据集上的表现优于两种基线。
E.1.4 SAM+XMem++和SAM+Cutie基线细节
我们采用SAM + XMem++和SAM + Cutie作为提示式视频分割的两个基线,其中点击(或框)提示首先由SAM处理以获得对象掩码,然后XMem++/Cutie模型在视频中跟踪此SAM掩码以获得最终掩码。在这两个基线中,SAM可以用来提供第一帧上的初始对象掩码,或纠正XMem++或Cutie输出的现有对象掩码。这用于交互式离线和在线评估中的后续交互帧,其中新的正和负点击作为修正提供给现有掩码。
当使用SAM对给定帧中的现有掩码预测进行修正时,我们遵循EVA-VOS(Delatolas等人,2024)的策略,首先用XMem++或Cutie输出掩码初始化SAM,然后结合新的修正点击。具体来说,我们首先通过从它们中采样点击并将它们作为输入馈送到SAM,直到SAM中重建的掩码与XMem++或Cutie输出掩码的IoU>0.8。然后,为了结合新的正和负点击进行修正,我们将这些额外的修正点击与掩码构建期间采样的初始点击连接起来,并将联合连接的列表作为输入馈送到SAM以获得最终修正的掩码。我们发现这种策略比几种替代方案效果更好(例如,将XMem++或Cutie输出掩码与新的修正点击一起作为掩码提示输入到SAM,或只将修正点击作为输入到SAM,而忽略XMem++或Cutie输出掩码)。
E.2 DAVIS交互式基准测试
我们还在DAVIS交互式基准测试(Caelles等人,2018)上进行评估,这类似于我们在§6.1.1中的交互式离线评估,其中在每次交互轮次中,评估服务器将提供在分割性能最差的帧上新的注释。官方DAVIS评估工具包在交互期间提供涂鸦提示,而其他工作如CiVOS(Vujasinović等人,2022)也已经将其扩展到覆盖点击提示。

这里我们遵循CiVOS使用正和负点击作为输入提示,并采用相同的点击采样策略。我们报告此基准测试的 J & F @ 60 \mathcal{J} \& \mathcal{F} @ 60 J&F@60秒和AUC- J & F \mathcal{J} \& \mathcal{F} J&F指标,这些指标由其评估器提供,并与两个基线进行比较:MiVOS(Cheng等人,2021b),它直接使用提供的涂鸦通过涂鸦到掩码模块(并且也在Vujasinović等人(2022)中扩展到点击提示),和CiVOS,它从提供的涂鸦中采样点击。结果在表14中显示,基于点击输入的SAM 2在点击输入下的表现优于两个基线。我们注意到,SAM 2在第一点击时往往倾向于分割对象部分(例如,一个人的手臂),而DAVIS数据集主要包含整个对象(例如,整个人),这可能会对SAM 2在该基准测试上的 J & F \mathcal{J} \& \mathcal{F} J&F性能造成惩罚。我们通过观察更早的训练在较少部分注释上的模型的更好准确性(使用点击输入的0.86 AUC- J & F \mathcal{J} \& \mathcal{F} J&F和0.89 J & F @ 60 \mathcal{J} \& \mathcal{F} @ 60 J&F@60秒)验证了这一点。
E.3 零样本图像任务
E.3.1 数据集细节
对于交互式分割任务,我们在37个数据集的全面套件上评估了SAM 2。这个套件包括SAM先前用于零样本评估的23个数据集。为了完整性,我们列出了23个数据集:LVIS(Gupta等人,2019)、ADE20K(Zhou等人,2019)、Hypersim(Roberts等人,2021)、Cityscapes(Cordts等人,2016)、BBBC038v1(Caicedo等人,2019)、DOORS(Pugliatti & Topputo,2022)、DRAM(Cohen等人,2022)、EgoHOS(Zhang等人,2022)、GTEA(Fathi等人,2011;Li等人,2015)、iShape(Yang等人,2021a)、NDD20(Trotter等人,2020)、NDISPark(Ciampi等人,2021,2022)、OVIS(Qi等人,2022)、PPDLS(Minervini等人,2016)、Plittersdorf(Haucke等人,2022)、STREETS(Snyder & Do,2019)、TimberSeg(Fortin等人,2022)、TrashCan(Hong等人,2020)、VISOR(Darkhalil等人,2022;Damen等人,2022)、WoodScape(Yogamani等人,2019)、PIDRay(Wang等人,2021a)、ZeroWaste-f(Bashkirova等人,2022)和IBD(Chen等人,2022)。有关这些数据集的更详细信息,我们请读者参考Kirillov等人(2023)。除了这23个数据集,我们还评估了从14个视频数据集采样的帧,以评估SAM 2在视频领域图像上的性能。使用的视频数据集如下所列:Lindenthal Camera Traps(LCT)(Haucke & Steinhage,2021)、VOST(Tokmakov等人,2022)、LV-VIS(Wang等人,2023)、FBMS(Brox等人,2010)、Virtual KITTI 2(Cabon等人,2020)、Corsican Fire Database(CFD)(Toulouse等人,2017)、VIPSeg(Miao等人,2022)、Drosophila Heart OCM(DH OCM)(Fishman等人,2023)、EndoVis 2018(Allan等人,2020)、ESD(Huang等人,2023)、UVO(Wang等人,2021b)、Ego-Exo4d(Grauman等人,2023)、LVOSv2(Hong等人,2024)和HT1080WT(Gómez-de Mariscal等人,2021)。表16有这些数据集的更详细描述。(其中一些数据集与§E.1.1中的零样本视频数据集来自相同的数据源。)

E.3.2 详细的零样本实验
在本节中,我们包含了§6.2中实验的更详细版本。我们在表15中比较了不同模型大小的SAM 2与SAM和HQ-SAM。我们用于评估的主要指标是1次和5次点击的mIoU,我们按数据集领域对结果进行分类。

表15首先展示了仅在图像上训练(对于SA任务)的模型与不同图像编码器大小在SA-23基准测试以及14个新引入的视频数据集上的比较。仅在SA-1B上训练的SAM 2(Hiera-B+)在1次点击准确度上超越了SAM(ViT-H),并且在5次点击准确度上超越了SAM(ViT-H)和HQ-SAM(ViT-H),同时速度提高了6倍。SAM 2(Hiera-L)进一步提高了1次点击准确度平均1个百分点,但牺牲了速度。尽管比Hiera-B+慢,但它仍然比SAM(ViT-H)快3.4倍,比SAM(ViT-B)快1.5倍。
表15中的最后两行展示了使用我们混合的图像和视频数据训练的好处,这将平均准确度提高到使用Hirea-B+图像编码器的23个数据集上的61.4%。此外,我们在SA-23的视频基准测试以及14个新引入的视频数据集上观察到了显著的改进。我们注意到我们没有扩展到Hiera-L之外,但期望更大的模型会有更好性能。

图15中展示了跨数据集的准确度细分,其中每个数据集相对于SAM的1次点击mIoU变化用颜色编码以指示数据类型(图像或视频)。值得注意的是,SAM 2(Hiera-B+)在29个数据集上超越了SAM,最高达到了53.9 mIoU,尽管使用了更小的Hiera-B+图像编码器。
F 在半监督VOS中与最新技术的比较的更多细节
我们提供了与半监督VOS中先前最新技术的比较的更多细节(§7)。我们包括了仅在SA-1B、SA-V和Internal数据上训练的SAM 2的结果,不同编码器大小的。

定性比较:在图16中,我们展示了我们的基线(Cutie-base+,顶行)和我们的模型(SAM 2,底行)在第一帧上使用掩码提示时的比较。虽然第一帧上的掩码提示只覆盖了人的衬衫,但基线预测的掩码错误地传播到了整个人。然而,我们的模型能够将掩码限制在目标对象上。

定量比较:在表17中,我们比较了我们的模型与先前方法在额外的半监督VOS指标上的性能。SAM 2在所有评估的基准测试中超越了先前的工作,在所有指标上。请注意,与这些先前的方法不同,SAM 2不是专门针对半监督VOS任务,而是能够进行更通用的提示式分割。SAM 2也不局限于特定的对象类别集。我们的模型在SA-V基准测试(表17a)上的性能展示了其分割视频中任何东西的能力。

G 模型、数据和注释卡片
G. 1 模型卡片

G. 2 SA-V数据集卡片
动机
-
数据集是出于什么目的创建的?是否有特定的任务?是否有需要填补的特定空白?请提供描述。该数据集是为PVS任务设计的。我们的数据集对视觉社区的贡献是:(1)该数据集由50.9 K个视频和642.6 K个掩码组成,是迄今为止公开可用的最大视频分割数据集(见5.2与当前VOS数据集的比较)(2)该数据集在https://ai.meta.com/datasets/segment-anything-video/下以创作共用署名4.0国际许可提供,(3)与前身相比,该数据是地理上更多样化的公开可用视频分割数据集。
-
谁创建了数据集(例如,哪个团队,研究小组)以及代表哪个实体(例如,公司,机构,组织)?数据集由Meta FAIR创建。底层视频是通过签约的第三方公司收集的。
-
谁资助了数据集的创建?数据集由Meta FAIR资助。
-
其他评论?无。
成分构成
-
数据集中的实例代表什么(例如,文档、照片、人、国家)?是否有多种类型的实例(例如,电影、用户和评分;人以及他们之间的互动;节点和边)?请提供描述。数据集中的所有实例都是视频。在视频收集过程中鼓励主题多样性,并且没有应用特定主题。视频的常见主题包括:地点、物体、场景。所有视频都是独特的,但有些视频集是拍摄相同主题的。
-
数据集中总共有多少实例(如果合适,每种类型的实例)?有50.9 K个视频。
-
数据集是否包含所有可能的实例,还是它是更大集合中实例的样本(不一定是随机的)?如果数据集是样本,那么更大的集合是什么?样本是否代表更大的集合(例如,地理覆盖范围)?如果是,描述这种代表性是如何验证/核实的。如果它不代表更大的集合,请描述为什么(例如,为了覆盖更多样化的实例范围,因为实例被保留或不可用)。虽然数据集包含了所有可能的实例,但评审员被告知要拒绝注释包含显式图像内容的内容。
-
每个实例由哪些数据组成?“原始”数据(例如,未经处理的文本或图像)还是特征?在这两种情况下,请提供描述。每个实例是一个视频。
-
是否每个实例都有一个标签或目标与之关联?如果是,请提供描述。每个视频都注释有在整个视频中跟踪对象的掩码。掩码没有与类别或文本相关联。数据以6 FPS的速度注释。平均每个视频有3.8个手动掩码和8.9个自动掩码,总共有642.6 K个掩码。
-
个别实例中是否有信息缺失?如果是,请提供描述,解释为什么这些信息缺失(例如,因为信息不可用)。这不包括故意删除的信息,但可能包括,例如,涂黑的文本。没有。
-
数据集中是否明确了个别实例之间的关系(例如,用户的电影评分,社交网络链接)?如果是,请描述这些关系是如何明确的。没有。
-
数据集中是否有任何错误、噪声来源或冗余?如果是,请提供描述。对于手动掩码,可能存在人为错误;例如,注释者可能错过需要检查或修复的帧。对于自动掩码,由于使用SAM 2生成它们,可能存在模型错误,例如掩码的不一致性。
-
数据集是自包含的,还是链接到或以其他方式依赖外部资源(例如,网站、推文、其他数据集)?如果是链接到或依赖外部资源,a) 是否有保证它们会存在,并随时间保持不变;b) 是否有完整数据集的官方归档版本(例如,包括在创建数据集时外部资源的状态);c) 是否有任何与外部资源相关的限制(例如,许可、费用)可能适用于数据集消费者?请提供所有外部资源及其相关限制的描述,以及适当的链接或其他访问点。数据集是自包含的。
-
数据集是否包含可能被视为机密的数据(例如,受到法律特权保护的数据,或医患保密的数据,包含个人非公开通信内容的数据)?如果是,请提供描述。没有。
-
如果直接查看数据集,是否可能被认为是冒犯性、侮辱性、威胁性,或可能以其他方式引起焦虑?如果是,请描述原因。我们有三项安全措施来防止不当内容:(1) 收集视频的众包工人被提供了不记录可能包含不当内容(例如,图形、裸露或不适当的内容)的视频的指导。(2) 注释视频的专家注释者被提供了如果存在不当内容则标记和拒绝视频的指导。(3) 可以向segment-anything@meta.com提交有关数据集中视频的报告。
-
数据集是否识别任何亚群体(例如,按年龄、性别)?如果是,请描述这些亚群体是如何被识别的,并提供它们在数据集中的各自分布的描述。数据集没有识别视频中人物的任何亚群体。在5.2中介绍了收集数据集中视频的众包工人的人口统计数据。
-
是否可能直接或间接(即,与其他数据结合)从数据集中识别个人(即一个或多个自然人)?如果是,请描述如何识别。视频经过了面部模糊模型的处理。可以向segment-anything@meta.com提交有关数据集中视频的报告。
-
数据集是否包含可能以任何方式被视为敏感的数据(例如,揭示种族或民族起源、性取向、宗教信仰、政治观点或工会成员资格,或位置;财务或健康数据;生物特征或遗传数据;政府识别形式,如社会安全号码;犯罪历史)?如果是,请提供描述。数据集不侧重于可能被视为敏感的数据。可以向segment-anything@meta.com提交有关数据集中视频的报告。
-
其他评论?没有。
收集过程
-
与每个实例相关的数据是如何获取的?数据是直接可观察的(例如,原始文本、电影评分),由受试者报告(例如,调查响应),还是从其他数据间接推断/衍生的(例如,词性标注,基于模型的年龄或语言猜测)?如果是受试者报告的数据或从其他数据间接推断/衍生的数据,是否对数据进行了验证/核实?如果是,请描述如何进行的。与每个视频相关的公开掩码是通过两种方法收集的。(1)SAM 2辅助的手动注释(2)由SAM 2自动生成并由注释者验证。
-
收集数据使用了哪些机制或程序(例如,硬件设备或传感器,手动人工审核,软件程序,软件API)?这些机制或程序是如何验证的?数据集中的视频是通过签约的第三方供应商收集的。它们是由使用未知设备的众包工人拍摄的视频。
-
如果数据集是更大集合的样本,那么采用了什么样的抽样策略(例如,确定性的,具有特定抽样概率的概率性的)?不适用。
-
谁参与了数据收集过程(例如,学生、众包工人、承包商),他们是如何得到补偿的(例如,众包工人支付了多少)?(1)数据集中的视频是通过签约的第三方供应商收集的。它们是由按供应商设定的小时工资补偿的众包工人拍摄的视频。(2)数据集中手动收集的掩码是由另一家第三方供应商的注释者收集的。注释者按供应商设定的小时工资得到补偿。
-
数据是在什么时间框架内收集的?这个时间框架是否与实例相关的数据的创建时间框架相匹配(例如,对旧新闻文章的最近抓取)?如果不是,请描述实例相关的数据的创建时间框架。视频是在2023年11月至2024年3月之间拍摄的。掩码注释是在2024年4月至2024年7月之间收集的。
-
是否进行了任何伦理审查过程(例如,由机构审查委员会进行)?如果是,请提供这些审查过程的描述,包括结果,以及任何支持文件的链接或其他访问点。如果数据集与人无关,您可以跳过本节的剩余问题。该项目经历了内部审查过程。
-
您是直接从相关个人那里收集数据,还是通过第三方或其他来源(例如网站)获得的?我们与第三方供应商签约收集视频和生成或审查注释。
-
相关个人是否被告知数据收集?如果是,请描述(或用屏幕截图或其他信息显示)如何提供通知,并提供链接或其他访问点,或以其他方式复制通知本身的确切语言。视频是由签约的第三方供应商收集的。众包工人同意了同意书。
-
相关个人是否同意收集和使用他们的数据?如果是,请描述(或用屏幕截图或其他信息显示)如何请求和提供同意,并提供链接或其他访问点,或以其他方式复制个人同意的确切语言。视频是通过签约的第三方收集的,该第三方提供了收集任何通知和同意所需的适当陈述。
-
如果获得了同意,是否为同意的个人提供了在未来或特定用途撤销同意的机制?如果是,请提供描述,以及机制的链接或其他访问点(如果合适)。根据合同,签约的第三方收集了同意,并提供了同意撤销的机会。
-
是否进行了对数据集及其使用对数据主体潜在影响的分析(例如,数据保护影响分析)?如果是,请提供这种分析的描述,包括结果,以及任何支持文件的链接或其他访问点。见6.1.3节的详细信息。
-
其他评论?没有。
预处理/清洗/标注
-
是否对数据进行了预处理/清洗/标注(例如,离散化或分桶,标记化,词性标注,SIFT特征提取,移除实例,处理缺失值)?如果是,请提供描述。如果没有,您可以跳过本节的剩余问题。视频被重新采样到24 fps并转换为mp4格式。
-
是否除了预处理/清洗/标注的数据之外还保存了“原始”数据(例如,支持未预见的未来使用)?如果是,请提供“原始”数据的链接或其他访问点。没有。
用途
-
数据集是否已经用于任何任务?如果是,请提供描述。数据集已用于训练和评估SAM 2。
-
数据集可以用于哪些(其他)任务?数据可用于VOS、iVOS或PVS任务。如果从视频中采样帧,数据集可用于图像分割任务。
-
数据集的组成或收集方式以及预处理/清洗/标注的方式是否有可能影响未来的使用?例如,数据集消费者是否需要知道什么,以避免可能导致个人或群体不公平待遇的使用(例如,刻板印象,服务质量问题)或其他风险或伤害(例如,法律风险,财务伤害)?如果是,请提供描述。数据集消费者可以做些什么来减轻这些风险或伤害?我们在5.2节中对我们数据集的地理和众包工人人口统计进行了分析。虽然我们认为我们的数据集在这些因素上比目前大多数公开存在的同类数据集更具代表性,但我们承认我们并没有在所有地理和人口统计群体中实现平等,我们鼓励数据集的用户注意使用此数据集时模型可能学到的任何潜在偏见。
-
数据集是否不应该用于某些任务?如果是,请提供描述。没有。数据集的完整使用条款可以在https://ai.meta.com/datasets/segment-anything-video-downloads/找到。
-
其他评论?没有。
分发
- 数据集是否会分发给实体(如公司、机构、组织)以外的第三方?如果有,请提供描述。该数据集将在许可的知识共享署名4.0国际公共许可协议下提供。
- 数据集将如何分布(例如,tarball网站,API, GitHub)?数据集是否有数字对象标识符(DOI)?该数据集可在https://ai.meta.com/datasets/segment-anything-video/上获得。
- 什么时候发布数据集?该数据集将于2024年7月发布。
- 数据集是否在版权或其他知识产权(IP)许可下分发,和/或在适用的使用条款(ToU)下分发?如果有,请描述本许可和/或使用条款,并提供链接或其他接入点,或以其他方式复制任何相关许可条款或使用条款,以及与这些限制相关的任何费用。是的,该数据集将在知识共享署名4.0国际公共许可协议下提供。该数据集的许可协议和使用条款可在https://ai.meta.com/datasets/segment-anything-video-downloads/上找到。用户在下载或使用数据集之前必须同意使用条款。
- 是否有任何第三方对与实例关联的数据施加了基于ip的限制或其他限制?如果有,请描述这些限制,并提供链接或其他接入点,或以其他方式复制任何相关许可条款,以及与这些限制相关的任何费用。SA-V数据集的完整使用条款和限制可以在https://ai.meta.com/datasets/segment-anything-video-downloads/上找到。
- 是否有任何出口控制或其他监管限制适用于数据集或单个实例?如果有,请描述这些限制,并提供链接或其他访问点,或以其他方式复制任何支持文档。使用SA-V数据集的许可和限制可以在https://ai.meta.com/datasets/segment-anything-video-downloads/上找到。
- 还有其他意见吗?不。
维护
- 数据集将由Meta FAIR在 https://ai.meta.com/datasets/segmentanything-video/ 上托管和维护。
- 可以通过电子邮件 segment-anything@meta.com 联系数据集的拥有者/策展人/管理员。
- 目前没有勘误表。
- 数据集可能会根据收到的反馈进行更新,更新将通过电子邮件通知。
- 数据集没有数据保留期限的限制。
- 不会维护旧版本的数据集。
- 鼓励对SA-V数据集进行进一步注释,但这些注释将不会由Meta验证、核实或支持。
- 没有其他评论。
G.3 数据注释卡片
任务的制定
- 选择要在视频中遮罩和跟踪的对象本质上是一个主观任务,注释者在决定遮罩对象时可能会有所不同。
- 我们假设注释者理解PVS任务,并且对视频相关任务有良好的培训。我们的注释者全职从事我们的注释任务,这使得通过定期反馈对注释者进行培训成为可能。
- 任务指令包括视觉示例(图像和视频)以提供清晰度。注释者在开始生产队列工作之前接受了良好的培训。研究团队每天分享反馈,并与注释者每周举行问答会议。
- 注释者被告知拒绝不当视频。
- 注释者的精确指令详见第11条注释指令。
选择注释
- 我们选择与具有视频注释经验的注释者合作。
- 没有排除可能有害的视角。
- 选择注释者时没有使用社会人口统计特征。
- 有关收集视频的众包工人的聚合社会人口统计数据详见5.2节。
- SA-V数据集是一个地理上多样化的公开可用视频分割数据集,如5.2节所讨论的。此外,我们分析了在数据集上训练的模型的负责任的AI轴,如6.1.3节所讨论的。
平台和基础设施选择
- 我们使用了内部注释平台。
- 研究团队每天分享反馈,并与注释者每周举行会议,以确保任务指令和期望的一致性,并举行问答会议。
- 注释者的补偿由供应商设定的小时工资决定。
数据集分析和评估
- 注释者在开始生产队列工作之前需要接受培训。研究团队和供应商的QA团队每天手动审查生产队列的注释,并每天分享反馈。
- 我们每天和每周在反馈和问答会议期间分享不同意图模式。
- 个体注释者响应与数据集中发布的最终标签之间的关系是经过数据清洗和后处理的。
数据集发布和维护
- 我们不认为数据集中的注释会随时间变化,也不计划更新数据集。
- 如果改变了任何条件或定义,可能会影响数据集的效用。
- SA-V数据集在创作共用署名4.0国际许可下发布。
- 注释者没有被告知数据如何外部化。
- 注释者无法从数据集中撤回他们的数据。