为什么要讨论这个问题
为了避免乱码和更好的跨平台
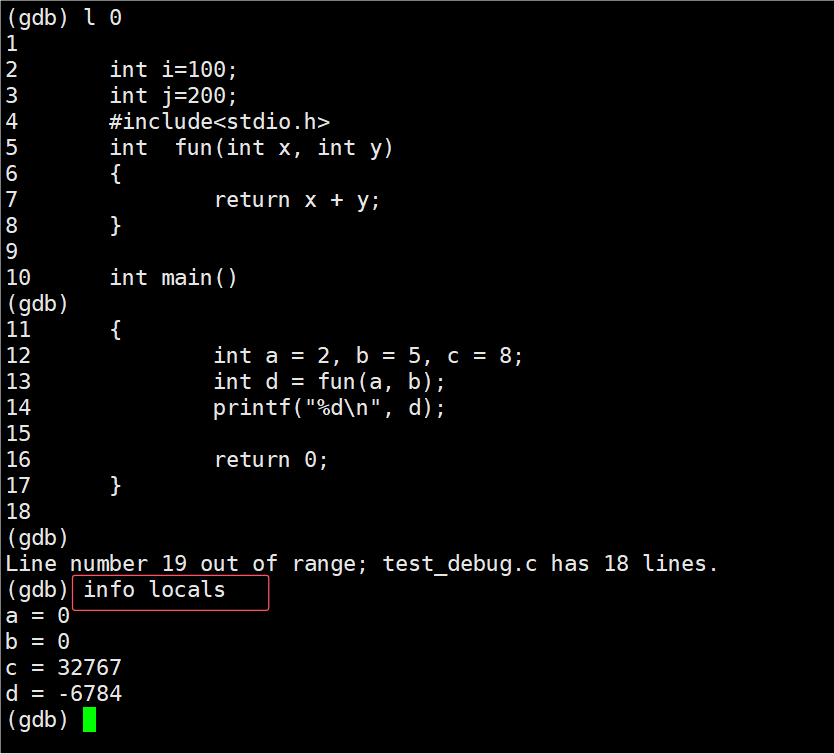
我刚开始开发时是使用VS开发,Unity自身默认使用UTF-8 without BOM格式,但是在Unity中创建一个脚本,使用VS打开,VS自身默认使用GB2312(它应该是对应了你电脑的window版本默认选取了国标编码,或者是因为一些其他的原因)读取脚本,默认是看不到在VS中的编码格式,下面我介绍一种简单快捷的办法让你查看你的编码格式.

点击扩展下的管理扩展

下载该插件,重启VS.

然后你就会发现右下角多了编码格式.
此时如果你写了一些中文注释,并通过git或svn提交了你的代码,假设你们的团队并没讨论过编码问题,而另一个人使用了rider编码(或其他的编辑器),rider默认使用utf8,你的注释到了他那里就是乱码.
如下


注意俩张图的右下角的编码,前者是国标,后者是utf8,当然rider可以很方便的转换编码,但是如果脚本多了就很麻烦,且后续仍可能出现乱码问题.

并且Unity自身也不支持国标2312,所以一个团队统一使用UTF-8是很有好处的,UTF-8给到国标也不会出乱码.
如何做?
在讲通用方法之前讲一个笨办法,刚才下载了那个FileEncoding插件后,点击右下方的编码格式选择convert to utf8,但是要注意必须在脚本中写一点中文注释,或者中文字符串,就是说这个文件需要有一点中文,然后点保存,才能成功被改变.
如果不写中文注释,当再创建一个脚本编译之后,刚才改成utf8的脚本又变回GB2312.并且这个方法需要每个脚本都改一下,有些麻烦.
下面使用一个通用办法来帮助整个团队使用统一的编码规范.
即使用.editorconfig文件
这是一个统一的规范,多数编辑器都支持这个规范.
使用办法
在Unity根目录添加一个文本文件名字为.editorconfig(注意前面有一个点,然后删掉.txt后缀),记事本打开,粘贴下列内容.此文件放在unity的项目的根目录,或者git/svn仓库的根目录让团队所有人使用.
# 顶级 EditorConfig 文件
root = true###############################
# 编码设置
################################ 所有 C# 文件使用 UTF-8 编码
[*.cs]
charset = utf-8# JSON 文件使用 UTF-8 编码
[*.json]
charset = utf-8# YAML 文件(Unity 场景和预制件)使用 UTF-8 编码
[*.yaml]
charset = utf-8# Shader 文件使用 UTF-8 编码
[*.shader]
charset = utf-8# 文本文件和其他文件使用 UTF-8 编码
[*.txt]
charset = utf-8###############################
# 缩进和空格规则
################################ C# 文件使用 4 个空格缩进
[*.cs]
indent_style = space
indent_size = 4# JSON 文件使用 2 个空格缩进
[*.json]
indent_style = space
indent_size = 2# YAML 文件使用 2 个空格缩进
[*.yaml]
indent_style = space
indent_size = 2# Shader 文件使用 4 个空格缩进
[*.shader]
indent_style = space
indent_size = 4# 文本文件使用 4 个空格缩进
[*.txt]
indent_style = space
indent_size = 4###############################
# 行尾规则
################################ 确保所有文件以换行符结尾
[*]
insert_final_newline = true# 统一使用 LF 换行符(适用于跨平台项目)
[*]
end_of_line = lf###############################
# 其他规则
################################ 删除行尾的多余空格
[*]
trim_trailing_whitespace = true
重点是[*.cs] charset = utf-8这句话,其他的别的配置,根据个人需要删改,感兴趣可以搜索这个规范研究一下,这样会强制改变的.cs文件编码为utf8 无BOM(这个格式是最通用的格式,Unity也使用这个格式).文件处理好之后保存重启Unity和编辑器就OK了.
注意
创建一个脚本用VS打开后,初始右下角还会显示GB2312,修改脚本内容并保存后自动会变为utf8,这就是editorconfig发挥了作用.
和刚才一样这个文件需要有一点中文,然后点保存,才能成功被改变,如果不存在中文,当再创建一个脚本编译之后,刚才改成utf8的脚本又变回GB2312.当然如果脚本里面没中文,假设另一个人使用rider打开了这个脚本,即便rider默认使用utf8读取,也不会出现任何问题.
最后不会修改没改变的脚本,即如果你导入一些国标脚本如果你没改动过它,也不会被自动改变格式.
.editorconfig介绍(选读)
.editorconfig 是一个用于定义和维护项目中代码风格、文件格式和编码规则的配置文件。它主要用于确保开发团队在不同的编辑器和 IDE(集成开发环境)中能够保持一致的编码风格和文件格式,避免因个人习惯或不同开发工具的默认设置而产生的格式问题。
.editorconfig 文件是一种简单的文本文件,通常放置在项目的根目录中。多个编辑器和 IDE,如 Visual Studio、Rider、VS Code 等,都支持读取并自动应用 .editorconfig 文件中的配置规则。
1 .editorconfig 的作用
统一代码风格:通过 .editorconfig,团队可以规定缩进、行尾符号、文件编码、命名规则等,确保所有开发人员使用统一的代码风格。
跨编辑器一致性:不同编辑器和 IDE 可能有不同的默认设置,.editorconfig 帮助跨平台、跨工具的团队在不同的开发环境中保持一致的格式。
代码质量提升:通过规定代码的格式规则,可以减少因代码风格不一致导致的代码冲突和审查意见,提高代码质量。
2 .editorconfig 文件的基本结构
一个 .editorconfig 文件包含多个部分,每个部分控制特定类型文件的格式和编码规则。文件的结构是按键值对方式编写的,通常包含:
文件类型定义:使用文件路径或扩展名来定义针对哪些文件应用特定规则。
格式规则:定义缩进样式、空格、换行符、最大行长度等。
编码规则:定义文件的字符编码类型(如 UTF-8)。
# 这是顶级的 EditorConfig 文件,表示它是项目的根配置
root = true# 针对所有 C# 文件的配置
[*.cs]
charset = utf-8 # 使用 UTF-8 编码
indent_style = space # 使用空格进行缩进
indent_size = 4 # 缩进为 4 个空格
end_of_line = lf # 使用 LF(换行符)作为行尾
insert_final_newline = true # 文件末尾插入换行符
trim_trailing_whitespace = true # 自动移除行尾的多余空格# 针对 JSON 文件的配置
[*.json]
indent_style = space
indent_size = 2 # JSON 文件使用 2 个空格缩进# 针对 YAML 文件的配置
[*.yaml]
indent_style = space
indent_size = 2 # YAML 文件使用 2 个空格缩进# 针对 Markdown 文件的配置
[*.md]
max_line_length = off # 对 Markdown 文件不限制行长度
trim_trailing_whitespace = false # 保留行尾空格
关键配置项说明
root:如果设置为 true,表示这是项目的顶级 .editorconfig 文件,后续子目录中的 .editorconfig 不会覆盖它。
文件类型选择器:
[*.cs]:匹配所有 .cs 文件。
[*.json]:匹配所有 .json 文件。
[src/**/*.cs]:匹配 src 目录下的所有 .cs 文件。
缩进规则:
indent_style:指定缩进使用空格还是 Tab。可选值:space 或 tab。
indent_size:指定缩进的大小(空格的数量)。
行尾规则:
end_of_line:指定行尾符号,常用值为 lf(Unix 风格换行符)或 crlf(Windows 风格换行符)。
insert_final_newline:是否在文件末尾强制添加一个换行符。
trim_trailing_whitespace:是否自动去除行尾的多余空格。
编码规则:
charset:指定文件的编码格式,常见的值有:
utf-8:无 BOM 的 UTF-8 编码。
utf-8-bom:带 BOM 的 UTF-8 编码。
utf-16be 或 utf-16le:UTF-16 编码。
latin1:Latin-1 编码。
最大行长度:
max_line_length:指定每行的最大字符长度,超出长度时可能会自动换行或提示。可以将其设置为 off,表示不限制行长度。
UTF8介绍(选读)
UTF-8 是一种字符编码方式,用于表示 Unicode 字符。虽然 UTF-8 本身是一种编码,但它可以带有或不带有 BOM(字节顺序标记,Byte Order Mark),这导致我们通常会遇到两种主要的 UTF-8 变体:
1. UTF-8 without BOM(不带 BOM 的 UTF-8)
这是标准的 UTF-8 编码,不包含 BOM 字节(即文件开头没有额外的 EF BB BF 字节)。
BOM 是可选的,因此大多数现代工具和系统(包括网络协议、编程语言、操作系统)都默认使用 UTF-8 without BOM。
Unity 默认使用的是 UTF-8 without BOM,即不带 BOM 的 UTF-8 编码。这种编码方式在大多数场景下都是最佳选择,因为它避免了 BOM 可能带来的兼容性问题,特别是在处理跨平台文件或脚本时。
2. UTF-8 with BOM(带 BOM 的 UTF-8)
这种编码方式在文件开头包含三个字节 EF BB BF,用于指示文件是以 UTF-8 编码的。这种标记的初衷是为了帮助某些系统(特别是 Windows 系统)识别文件的编码格式。
尽管 BOM 可以帮助识别编码,但它通常会导致某些问题,特别是在跨平台应用或网络传输时,因为 BOM 会被解析为实际字符,从而导致错误。
如何确认和设置 Unity 文件编码为 UTF-8 without BOM
编辑器设置:
Unity 默认会在其生成的文件(如脚本文件、文本文件等)中使用 UTF-8 without BOM,而且它的导入导出操作也依赖这种编码格式。
使用外部编辑器(如 Visual Studio、Rider 等)检查文件编码:
打开文件时,可以通过状态栏或高级保存选项检查文件的编码格式,确保使用的是 UTF-8 without BOM。
如果文件编码不符合预期,可以通过 高级保存选项 将文件转换为 UTF-8 without BOM(这里还是推荐我刚才讲的插件,配置起来很麻烦,感兴趣自行搜索)。