SAP-ABAP:SAP IDoc技术详解:架构、配置与实战
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/41944.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

【NUUO 摄像头】(弱口令登录漏洞)
漏洞简介:NUUO 是NUUO公司的一款小型网络硬盘录像机设备。 NUUO NVRMini2 3.0.8及之前版本中存在后门调试文件。远程攻击者可通过向后门文件handle_site_config.php发送特定的请求利用该漏洞执行任意命令。 1.Fofa搜索语句: 在Fofa网站,搜索&…
PyQt6实例_批量下载pdf工具_exe使用方法
目录
前置:
工具使用方法:
step one 获取工具
step two 安装
step three 使用
step four 卸载
链接 前置:
1 批量下载pdf工具是基于博文 python_巨潮年报pdf下载-CSDN博客 ,将这个需求创建成界面应用,达到可…

matlab 模拟 闪烁体探测器全能峰
clc;clear;close all
%% 参数设置
num_events 1e5; % 模拟事件数
E 662e3; % γ射线能量(eV)
Y 38000; % 光产额(photon/MeV,NaI(Tl))
eta 0.2; % 量子效率
G 1e6; …

启扬RK3568开发板已成功适配OpenHarmony4.0版本
启扬智能IAC-RK3568-Kit开发板支持Debian、Android等常见开源操作系统,目前已完成OpenHarmony4.0开源国产操作系统的适配工作,满足国产化开源操作系统客户的需求。 启扬智能IAC-RK3568-Kit开发板基于瑞芯微RK3568处理器设计,主频最高可达2.0G…

蓝桥与力扣刷题(蓝桥 山)
题目:这天小明正在学数数。
他突然发现有些止整数的形状像一挫 “山”, 比㓚 123565321、145541123565321、145541, 它 们左右对称 (回文) 且数位上的数字先单调不减, 后单调不增。
小朋数了衣久也没有数完, 他惒让你告诉他在区间 [2022,2022222022] 中有 多少个数…

WinDbg. From A to Z! 笔记(一)
原文链接: WinDbg. From A to Z! 文章目录 为什么使用WinDbg为什么通过本书学习底层原理简述Windows的调试工具一览dbghelp.dll -- Windows 调试助手dbgeng.dll -- 调试引擎接口 调试符号 (Debug Symbols)有哪些调试信息生成调试信息匹配调试信息调用堆栈 侵入式与非侵入式异常…

Axure RP 9.0教程: 基于动态面板的元件跟随来实现【音量滑块】
文章目录 引言I 音量滑块的实现步骤添加底层边框添加覆盖层基于覆盖层创建动态面板添加滑块按钮设置滑块拖动效果引言
音量滑块在播放器类APP应用场景相对较广,例如调节视频的亮度、声音等等。
I 音量滑块的实现步骤
添加底层边框
在画布中添加一个矩形框:500 x 32,圆…
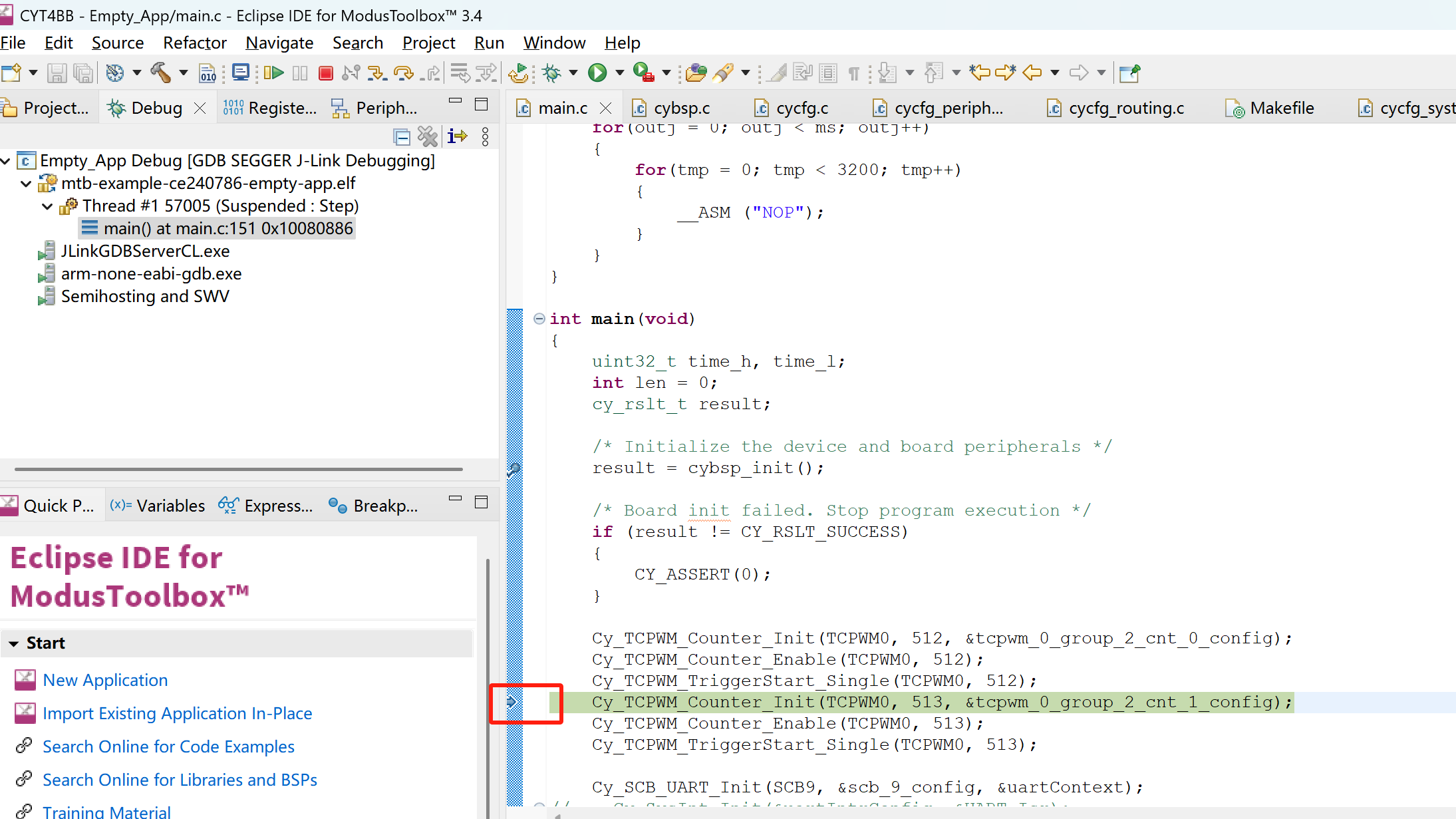
Eclipse IDE for ModusToolbox™ 3.4环境通过JLINK调试CYT4BB
使用JLINK在Eclipse IDE for ModusToolbox™ 3.4环境下调试CYT4BB,配置是难点。总结一下在IDE中配置JLINK调试中遇到的坑,以及如何一步一步解决遇到的问题。
1. JFLASH能够正常下载程序
首先要保证通过JFLASH(我使用的J-Flash V7.88c版本)能够通过JLIN…


wgcloud怎么实现服务器或者主机的远程关机、重启操作吗
可以,WGCLOUD的指令下发模块可以实现远程关机和重启
使用指令下发模块,重启主机,远程关机,重启agent程序- WGCLOUD

深度解析Spring Boot可执行JAR的构建与启动机制
一、Spring Boot应用打包架构演进
1.1 传统JAR包与Fat JAR对比
传统Java应用的JAR包在依赖管理上存在明显短板,依赖项需要单独配置classpath。Spring Boot创新的Fat JAR(又称Uber JAR)解决方案通过spring-boot-maven-plugin插件实现了"…

deepseek(2)——deepseek 关键技术
1 Multi-Head Latent Attention (MLA) MLA的核心在于通过低秩联合压缩来减少注意力键(keys)和值(values)在推理过程中的缓存,从而提高推理效率: c t K V W D K V h t c_t^{KV} W^{DKV}h_t ctKVWDKVht…

突破反爬困境:SDK架构设计,为什么选择独立服务模式(四)
声明 本文所讨论的内容及技术均纯属学术交流与技术研究目的,旨在探讨和总结互联网数据流动、前后端技术架构及安全防御中的技术演进。文中提及的各类技术手段和策略均仅供技术人员在合法与合规的前提下进行研究、学习与防御测试之用。 作者不支持亦不鼓励任何未经授…

自然语言处理,能否成为人工智能与人类语言完美交互的答案?
自然语言处理(NLP)作为人工智能关键领域,正深刻改变着人机交互模式。其发展历经从早期基于规则与统计,到如今借深度学习实现飞跃的历程。NLP 涵盖分词、词性标注、语义理解等多元基础任务,运用传统机器学习与前沿深度学…

蓝桥杯备考:八皇后问题
八皇后的意思是,每行只能有一个,每个对角线只能有一个,每一列只能有一个,我们可以dfs遍历每种情况,每行填一个,通过对角线和列的限制来进行剪枝
话不多说,我们来实现一下代码 #include <ios…

HDR(HDR10/ HLG),SDR
以下是HDR(HDR10/HLG)和SDR的详细解释: 1. SDR(Standard Dynamic Range,标准动态范围)
• 定义:SDR是传统的动态范围标准,主要用于8位色深的视频显示,动态范围较窄&…

【MySQL】验证账户权限
在用户进行验证之后,MySQL将提出以下问题验证账户权限:
1.谁是当前用户?
2.该用户有何权限?
管理权限比如:shutdown、replication slave、load data infile。数据权限比如:select、insert、update、dele…

通过TIM+DMA Burst 实现STM32输出变频且不同脉冲数量的PWM波形
Burst介绍:
DMA控制器可以生成单次传输或增量突发传输,传输的节拍数为4、8或16。
为了确保数据一致性,构成突发传输的每组传输都是不可分割的:AHB传输被锁定,AHB总线矩阵的仲裁器在突发传输序列期间不会撤销DMA主设备…

GaussDB数据库表设计与性能优化实践
GaussDB分布式数据库表设计与性能优化实践
引言
在金融、电信、物联网等大数据场景下,GaussDB作为华为推出的高性能分布式数据库,凭借其创新的架构设计和智能优化能力,已成为企业核心业务系统的重要选择。本文深入探讨GaussDB分布式架构下的…

npm install 卡在创建项目:sill idealTree buildDeps
参考:
https://blog.csdn.net/PengXing_Huang/article/details/136460133 或者再执行
npm install -g cnpm --registryhttps://registry.npm.taobao.org
或者换梯子
推荐文章
- ffmpeg -formats
- $route 和 $router 的区别是什么?
- (Arxiv-2023)HiPA: 通过高频增强自适应实现一步文本到图像扩散模型
- [ Spring ] Spring Cloud Gateway 2025 Comprehensive Overview
- [HCTF 2018]WarmUp
- [论文阅读] Knowledge Fusion of Large Language Models
- “卫星-无人机-地面”遥感数据快速使用及地物含量计算的实现方法
- 《CPython Internals》阅读笔记:p336-p352
- 【3】高并发导出场景下,服务器性能瓶颈优化方案-文件压缩
- 【6】树状数组学习笔记
- 【AI大模型】Ollama部署本地大模型DeepSeek-R1,交互界面Open-WebUI,RagFlow构建私有知识库
- 【AVRCP】深度解析蓝牙高速(AMP)在封面艺术传输中的应用:低延迟体验的工程实践