目录
引言
三维高斯飞溅(3DGS)
总体流程
SFM算法
1.特征提取:
2.特征匹配:
3.图像对优选:
4.相机位姿估计及空间点坐标获取:
5.三角化确立新图像地图点:
6.重建场景及其约束:
3DGS
1.捏雪球
2.抛雪球
3.雪球颜色
4.高斯自适应控制
5.快速光栅化
6.交叉优化
7.整体流程
引言
机器视觉领域中,新颖视图合成技术的核心目标是通过图像或视频构建可以被计算机处理和理解的3D模型。该技术被认为是机器理解真实世界复杂性的基础,催生了大量的应用,包括3D建模、虚拟现实、自动驾驶等诸多领域。回顾其发展历史,针对真实世界场景重建的研究早在深度学习诞生之前就已经兴起。
早期研究主要集中在光场和结构性数据的恢复上,受限于早期计算机对密集采样和结构化捕获的算力限制,在处理复杂光照场景和不规则结构方面出现了巨大技术瓶颈。2006年,运动结构恢复算法(Structure from Motion,后文简称SFM)和多视图立体算法(multi-view stereo,后文简称MVS)的出现打破了这一僵局,为后续新颖视图合成技术提供了强大的基础框架。2020年,ECCV 2020,隐式神经辐射场技术(NeRF)诞生,实现了这一技术的阶段性飞跃。NeRF利用深度神经网络,实现空间坐标到图像色彩及密度的直接映射,构建了连续、立体场景功能,实现了该领域中三维模型前所未有的细节和真实感,但代价也十分明显:1)计算强度极高:NeRF的场景构建方法为计算密集型,单一场景构建需要大量的算力资源和时间成本,尤其是高分辨率输出时;2)可编辑性差:单一场景的编辑需要重新训练整个流程。操纵隐式表达的场景具有较大挑战,中间环节的神经网络参数都需手动调控。
针对上述NeRF存在的困境,三维高斯飞溅技术(3D Gaussian Splatting,后文简称3DGS)应运而生。其主要思想在于使用3D Gaussian椭球表示三维模型,并通过Splatting技术渲染模型图像。该方法实现了辐射场的实时渲染,能够在较少的训练时间内,实现SOTA级别的视觉效果。3DGS针对多张图像或视频拍摄的场景时,允许以1080P分辨率进行实时(≥30FPS)的新视图渲染。
三维高斯飞溅(3DGS)
总体流程
3DGS原始的代码仅支持静态场景的重建。其大致流程包括:
1)输入一组静态场景的图像。由SFM算法,获取场景中的稀疏点云及所有图像对应的相机位姿。
2)对获取的每个稀疏点云创建初始化3D高斯椭球,其由位置(平均值)、协方差矩阵(XYZ轴缩放因子、旋转因子等)、不透明度和球谐函数系数(后文简称SH系数)所定义。该定义允许3D场景合理紧凑的表示,并通过调节参数紧凑化表示精细化场景结构。
3)基于相机位姿,选取位于相机视椎体之内的3d gaussian椭球,节省计算量
4)将3D gaussian椭球投影到2D图像空间中
5)通过固定的场景图像与原始输入图像(真值图像)进行比对优化,对初始化后的参数(位置、协方差矩阵、SH系数、高斯球密度的自适应控制)进行优化,并使用了快速GPU排序算法,受到基于tile的光栅化的启发构建光栅化实时渲染。
5)允许高斯球和高斯球之间重合,设计了跟踪快速后向通道,自适应调控高斯梯度。

SFM算法
运动结构恢复(Structure from motion),即给出多幅图像及其图像特征的一个稀疏对应集合,估计3D点的位置,这个求解过程通常涉及3D几何(结构)和摄像机姿态(运动)的同时估计。由于图像之间可能是无序的,并且图像数据量大,数据来源广而丰富。针对以上特点,出现了三种SFM策略,包括增量式、层级式以及全局式。增量式即先选出两张图像进行初始化,接着一张张图像进行配准及点的三角化;全局式即一次性将所有的影像进行配准与重建;层级式先将影像进行分组,每组进行配准,再对上一步的结果进行配准重建。其中,增量式在无序图像数据集重建中应用最广泛,其应用包括Bundler、VisualSfM、COLMAP等优秀的SFM开源软件,为SFM的应用与研究提供了基础。
3DGS的初始化流程中,严格遵循COLMAP增量式SFM的点云初始化流程。COLMAP是当今最受关注的主流SFM开源软件,其为3DGS提供稀疏点云,相机位姿以及对应图像参数。COLMAP的整体流程可简单归纳为以下环节:特征提取,特征匹配,相机位姿估计,三角测量,场景重建。
1.特征提取:
这里的特征提取环节并不是神经网络中所提到的图像特征,而是特征描述子。在该环节中,需要提取图像间的共有特征点,该特征点需具备克服跨模态、跨尺度、跨视角、跨帧的能力,同时可以有效规避非线性辐射干扰、大气辐射干扰、运动模糊干扰、形变干扰等。在COLMAP中一般会采取经典的ORB、SIFT、SURF等特征点描述获取作为优先选项。针对不同的情况,我本人推荐HOPC、SuperGlue、SuperPoint、D2-Net等全新的特征点获取方式,并加入神经网格规整特征描述子的形状及X-Y坐标。
2.特征匹配:
由于COLMAP采取的是增量式SFM算法流程,整体以视频的时间帧进行图像间的特征点匹配。匹配环节符合SIFT、SURF的暴力匹配模型。在整体匹配中,为了规避无关点和误匹配的出现,采用KNN、FLANN等优化算法进行点与点间的连线,并加入RANSAC、LMEDS进行GOOD MATCHING(最佳匹配点)提纯。
3.图像对优选:
在获取了逐帧图像间的特征匹配关系后,利用特征点间的描述向量得到重叠图像对(≥2张)。该环节的在于对时间复杂度下的多重叠图像进行优化,去除不必要的图像,寻找相似度及图像信息囊括最多的图像帧。该环节在COLMAP中仍以RANSAC作为常用手段,但其本身的优化算法非常多。
4.相机位姿估计及空间点坐标获取:
这个环节非常重要。首先,针对场景重建的问题。对于单一范围内的场景,我们选取上述操作中获取的重叠图像,并进行图像间的双目初始化。由于重叠图像的数量大多为两张以上,因此,我们获取的数据冗余非常高,这会使得重建的精度和细节更加丰富。接下来,我们进行图像的空间配准。通过特征点匹配所获取的变换矩阵,我们求解出图像与图像间特征点所在的相对三维空间坐标,并利用2D和3D关系,利用RANSAC算法及最小位姿解算器,求解计算机视觉中常见的PNP(Perspective-n-Point)问题,进而求解出多图像间的相机位姿。
5.三角化确立新图像地图点:
该环节是COLMAP的主要创新点之一。三角化过程即前方图像交汇,通过配准已有场景的强特征点,获取已存在的空间三维点(即单一场景里的相对三维坐标)并校准新的空间三维点(即选取单一场景的XY坐标为原点,校准合成三维场景的坐标)。在COLMAP中,使用了光束法平差进行该环节的优化。通过校准配准场景间的反向投影误差,提高三角化过程的准确性,并在训练过程中,增加了Huber、Tukey等损失函数。
6.重建场景及其约束:
在完成了所有的地图点获取后,此时所有的场景点云已经全部获取完毕。该场景点云全部由图与图之间的特征点所构成,点与点之间存在明确的空间对应关系。同时,单一点对应多个相机位姿和图像信息。为了进一步优化相机位姿和三维坐标点。COLMAP提出使用BA(Bundle Adjustment)算法对生成的稀疏点云和相机位姿进行监督优化。该算法可有效减少重投影误差和累积误差。BA问题是机器视觉中的经典求解问题,可选取严格方式和不严格方式进行求解。严格方式即通过相机稀疏矩阵与特征点稀疏矩阵优化参数;非严格方式即通过简单的迭代求解器,估算参数并与当前参数比对。在COLMAP中,提出了一种BA优化方法,即针对场景与场景间的图像配准关系,都只进行局部图像块的BA求解。当整体的场景重建完成后,再进行一次全局BA求解,从而减少计算代价。
3DGS
1.捏雪球
3DGS是3D Gaussian Splatting的简写,3D高斯在空间中是一个椭球形状的物体,Splatting意思是喷溅,那么如何去理解Splatting呢?

Splatting中splat是一个拟声词,译为啪叽一声,想象输入是一些雪球,图片是一面墙,图像生成的过程模拟为雪球砸向墙的过程,每扔一个雪球,墙面上会有扩散痕迹,足迹(footprint),同时会有啪叽一声,因此得名。
Splatting的核心是什么呢,分为以下三步:
- 选择[雪球]
- 抛掷雪球:从3D投影到2D,得到足迹
- 加以合成,形成最后的图像
对于第一步选择雪球,为什么需要选择雪球呢,因为我们的输入是一些点,点本质是没有体积的,也是没有能量的,所以选择一个核来对他进行膨胀,这个核可以选择高斯也可以选择圆、正方形或其他;那为什么选择高斯呢,就是因为他有很多优良的数学性质,如下。

如果一个物体在所有方向都具有相同的扩散程度,那么他就有各向同性,可以参考球形,否则具有各向异性,参考椭球形。各向同性和各向异性的差异可以理解为椭球是具有不同形状的球。
3D椭球集的创建:

可以使用协方差矩阵来控制椭球的形状。因为任意高斯都可以看做是标准高斯通过仿射变换得到,所以任意椭球都可以看作是球通过仿射变换得到。

而协方差矩阵是可以通过旋转和缩放矩阵来表达的,表示了这个3D高斯在各个坐标轴的缩放以及旋转。由于3D高斯的协方差矩阵必须满足半正定,而直接学习协方差矩阵很难满足这个条件,不能用传统梯度下降法,或者说不能将协方差矩阵作为一个优化参数直接优化。所以在之后的实现中,也是先学习高斯的旋转矩阵和缩放矩阵,再通过他们构造对应的协方差矩阵;那么不直接对协方差矩阵优化,而是将R,S作为优化参数优化,就可以保持协方差矩阵的正半定。
-
R是四元数表示的旋转矩阵(此矩阵要保持normalization)
-
S是一个对角缩放矩阵,其对角线上是协方差矩阵三个特征值的平方根
通过定义R,S以及location(也就是均值),我们可以得到三维空间中所有形式的3D Gaussian。

所以说,捏雪球的过程就是形成一个3D高斯的过程,3D高斯本身是一个椭球,可以通过协方差零矩阵来控制椭球的形状,而可以通过旋转和缩放矩阵来控制协方差矩阵。
2.抛雪球
是计算机图形学中用三维点进行渲染的方法,该方法将三维点视作雪球往图像平面上抛,雪球在图像平面上会留下扩散痕迹,这些点的扩散痕迹叠加在一起就构成了最后的图像,是一种针对点云的渲染方法)的方法进行渲染。
我们需要实现某种方式,能够将多个3D Gaussian投影到2D image上来渲染结果。
抛雪球即为从3D到像素的一个过程,这个变化主要是通过一些变换来做的,比如正交投影,是与z无关的一种投影;透视投影,是与z有关的一种投影。
![]()
![]()
具体来说,仿照渲染管线的流程,假如一个初始的3D Gaussian是在模型空间的话,协方差矩阵就相当于模型变换,将3D Gaussian转换到了世界空间。然后W是View Transform Matrix,将3D Gaussian转换到了相机空间。J是Jocobian Matrix,是用来近似Project Transfor Matrix实现Project Transform。


3.雪球颜色





4.高斯自适应控制
在 3D Gaussian Splatting (3DGS) 里,由于每个点云高斯都有可优化参数,如位置、各向异性协方差、颜色、透明度、旋转。高斯自适应控制的核心目标是动态调整高斯分布的参数,以优化 3D 表现,确保渲染效果既高效又准确。
我们从SfM的初始稀疏点集开始,然后应用我们的方法自适应地控制单位体积内的高斯数量和密度,这样就能从初始稀疏的高斯集变为更密集的高斯集,从而以正确的参数更好地表现场景。在优化预热之后,每迭代100次就会进行一次高斯致密化处理,并移除基本透明的高斯,即α小于阈值的高斯。

对于重建不足区域的小高斯,我们需要覆盖必须创建的新几何体。为此,最好通过简单地复制高斯,创建一个相同大小的副本,并沿位置梯度方向移动。
另一方面,当某个高斯过于模糊,无法细化局部细节,需要更精确的形态表示时,高方差区域的大高斯需要分割成更小的高斯。我们使用两个新的高斯来替换这些高斯,让局部区域变得更细腻。
在第一种情况下,我们检测并处理增加总体积和高斯数量的需求,在第二种情况下,我们会保留总体积并增加高斯数量。和其他体积表示法类似,我们的优化可能会陷入靠近输入相机的漂浮物上的情况;这可能会导致高斯密度的不合理增加。缓和高斯数量增加的有效方法是,每3000次迭代后,将α数值设置为接近于0。然后,优化会在需要的地方增加高斯的密度,同时允许去除α ![]() 的高斯。高斯可能会缩小或增大,并与其他高斯有重叠,但我们会定期移除世界空间中非常大的高斯和视图空间中占用较大的高斯。这种策略可以很好地控制高斯总数。我们模型中的高斯函数始终保持欧式空间中的原语;和其他方法不同,这里不需要对远距离或大型高斯进行空间压缩、扭曲或投影策略。
的高斯。高斯可能会缩小或增大,并与其他高斯有重叠,但我们会定期移除世界空间中非常大的高斯和视图空间中占用较大的高斯。这种策略可以很好地控制高斯总数。我们模型中的高斯函数始终保持欧式空间中的原语;和其他方法不同,这里不需要对远距离或大型高斯进行空间压缩、扭曲或投影策略。
5.快速光栅化
在 3DGS 渲染过程中,快速光栅化(Fast Rasterization)是核心步骤之一,负责将 3D 高斯投影到 2D 屏幕,实现高效渲染,并计算其贡献。
在 3DGS 里,每个高斯点都有一个 3×3 的协方差矩阵Σ (在世界坐标系下表示高斯分布的形状),当其经过投影后,其在屏幕空间的协方差矩阵![]() 。其中
。其中
- W是透视投影矩阵
- J 是透视投影的雅可比矩阵(用于调整尺度和方向)

这样,透视投影后的高斯点可以正确地在屏幕上渲染出符合透视缩放规律的 2D 形状。
光栅化的gpu高度并行
把屏幕空间划分为多个像素块,根据像素块与高斯的交集动态分配计算任务给不同的gpu,这样可以较少gpu间的数据传输要求,因为每个gpu只需处理与其分配的像素块相关的数据,提高了数据的局部性和并行处理的效率。基于图像块(tile)的光栅化图像渲染示意图如下:
简单解释就是,先按深度远近进行排序,比如按照从近到远的顺序分别为绿、蓝、粉色的3D高斯,将图像划为多个不重叠的图像块,每块包含16x16像素,由b图可知绿色高斯椭球投影之后占据了两个图像块,分别为Tile1和Tile2,蓝色占据四个,粉色占据一个,这也对应着c图左侧的序列,那么再按照图像块的角度进行排序,Tile1对应绿色蓝色高斯椭球,Tile2对应绿色蓝色高斯椭球,Tile3对应粉色蓝色椭球,Tile4对应蓝色椭球。到此,之后的独立绘制就是Tile1只负责Tile1的部分,各司其职,负责自己的部分即可,每个线程之间的运行就不进行打扰了。

片元着色(Fragment Shading)
-
计算每个屏幕像素的颜色:对覆盖该像素的多个高斯点进行加权平均(类似于 alpha blending)。
-
计算公式:
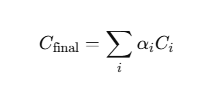
其中:
-
Ci 是第 i 个高斯点的颜色
-
αi 是它的不透明度
6.交叉优化
优化的目的是创建一组密集的 3D Gaussian 以精确地表示场景。优化的参数包括:三维位置 p、透明度 α 各向异性协方差 Σ 和球谐系数 SH (spherical harmonic coefficients) 。这些 ⌈参数的优化⌋ 和 ⌈自适应控制高斯模型⌋ 交替进行。

注意:图中的球谐系数 SH (spherical harmonic coefficients) 来表示每个高斯的颜色 ,不同视角颜色不同。
参数优化使用 SGD 连续迭代完成,每一轮迭代时都会渲染图像并将其与真实的训练视图做比较。α使用 Sigmoid 激活函数来限制 (0, 1) 的范围;Σ使用指数激活函数激活;p使用指数衰减调度技术 (exponential decay scheduling technique) 进行优化。模型的损失函数是 L1 与 D-SSIM 项的组合:

7.整体流程

场景表达通过很多个高斯球来实现,如下图所示,每个高斯球对应59个参数。

其中决定一个高斯球需要59个系数来表达,这些也是优化问题要求解的状态:
中心位置:3dof
协方差矩阵:7dof
透明度:1dof
球谐系数:48 dof(J = 3,16 * 3)
整体流程
1)Initialization: 输入为3D点云,可以 通过colmap得到,(NeRF也会用到colmap,使用位姿), 基于这些点云初始化高斯球,每个点云位置放置一个高斯球,中心点位置设置为点云位置,其他随机初始化
2) Projection: 根据相机内外参数(图像位姿),把高斯球splatting到图像上把能看到99%的所有高斯球投影到图像上(参考“将3D 高斯投影到2D像素平面”)使用下面3个公式

3)Differentiable Tile Rasterizer:在投影重叠区域进行光栅化渲染(Differentiable Tile Rasterizer),使用α \alphaα blending,这是确定的函数,不需要学习。把这些高斯球进行混合,过程可微,公式就是:

4)与gt计算loss,更新每个高斯球的59维系数

损失函数为:

其中:
- L1 loss:基于逐像素比较差异,然后取绝对值

- SSIM loss(结构相似)损失函数:考虑了亮度 (luminance)、对比度 (contrast) 和结构 (structure)指标,这就考虑了人类视觉感知,一般而言,SSIM得到的结果会比L1,L2的结果更有细节,SSIM 的取值范围为 -1 到 1,1 表示两幅图像完全一样,-1 表示两幅图像差异最大。

5)梯度回传
- 更新每个高斯球的属性(59维系数)-这是个优化问题

- Adaptive Density Control:根据梯度实现3D高斯球的clone和split,具体而言
- 学习过程中,较大梯度(59维导数,模长大)的高斯球存在under-reconstruction和over-reconstruction问题
- under-reconstruction区域的高斯球方差小,进行clone
- over-reconstruction区域高斯球方差大,进行split

4.每经过固定次数的迭代进行一次剔除操作,剔除几乎透明(透明度接近0)的高斯球以及方差过大的高斯球
参考链接:https://blog.csdn.net/m0_37604894/article/details/137864723?spm=1001.2101.3001.6650.8&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8-137864723-blog-135397265.235%5Ev43%5Epc_blog_bottom_relevance_base4&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8-137864723-blog-135397265.235%5Ev43%5Epc_blog_bottom_relevance_base4&utm_relevant_index=16