使用 Elasticsearch Reindex API 迁移数据
在 Elasticsearch 中,随着需求的变化,可能需要对索引进行重建或更新。这通常涉及创建新索引、迁移数据等步骤。本文介绍如何使用 Reindex API 将旧索引中的数据迁移到新索引中
一、步骤概述
-
创建新索引:根据需求创建一个新索引,新旧索引的字段名称和数据类型必须一致
-
数据完整性:确保在迁移过程中,旧索引不再进行写入操作,以避免数据不一致
-
迁移数据:使用 Reindex API 将旧索引中的数据重新索引到新索引中
二、reindex基本使用
- 源索引的
_source字段必须启用,才能提取文档内容 - 目标索引在执行
_reindex前应按照需求配置好,Reindex API 不会复制源索引的设置(例如映射、分片、副本等),这些需要在重新索引前手动配置
基本使用示例
POST /_reindex
{"source": {"index": "my-index-000001"},"dest": {"index": "my-new-index-000001"}
}
请求条件
如果启用了 Elasticsearch 的安全功能,执行 Reindex API 需要具备以下权限:
- 对源数据流、索引或别名的读取权限。
- 对目标数据流、索引或别名的写入权限。
- 如果希望 Reindex API 自动创建数据流或索引,还需具备
auto_configure、create_index或manage权限。 - 若从远程集群重新索引,需要配置
reindex.remote.whitelist设置,并且源集群用户需要具有monitor和read权限。
异步执行 Reindex
请求默认是异步执行的,虽然 API 会立即返回一个响应,但任务实际上在后台执行。如果希望同步执行任务,可以在 URL 中添加 wait_for_completion=true 参数,示例如下:
POST _reindex?wait_for_completion=true&refresh
{"source": {"index": "index_v1"},"dest": {"index": "index_v2"}
}
三、指定slice并行和size大小优化速度
创建好新索引后,可以使用 Reindex API 进行数据迁移。以下是迁移数据的示例:
POST _reindex?slices=20&refresh
{"source": {"index": "index_v1","size": 5000},"dest": {"index": "index_v2"}
}
slices:可以指定并发执行的切片数,帮助加快迁移速度size:每次从源索引中读取的文档数量
上面两个参数要根据服务器硬件的配置和网络传输速度等进行设置,并非越高越好
监控重建任务
在进行数据迁移时,可以使用以下命令监控重建任务的进度:
GET /_tasks?detailed=true&actions=*reindex
这个命令会返回当前所有重建任务的详细信息,包括任务的状态、已处理的文档数量、总文档数量以及任何可能的错误信息
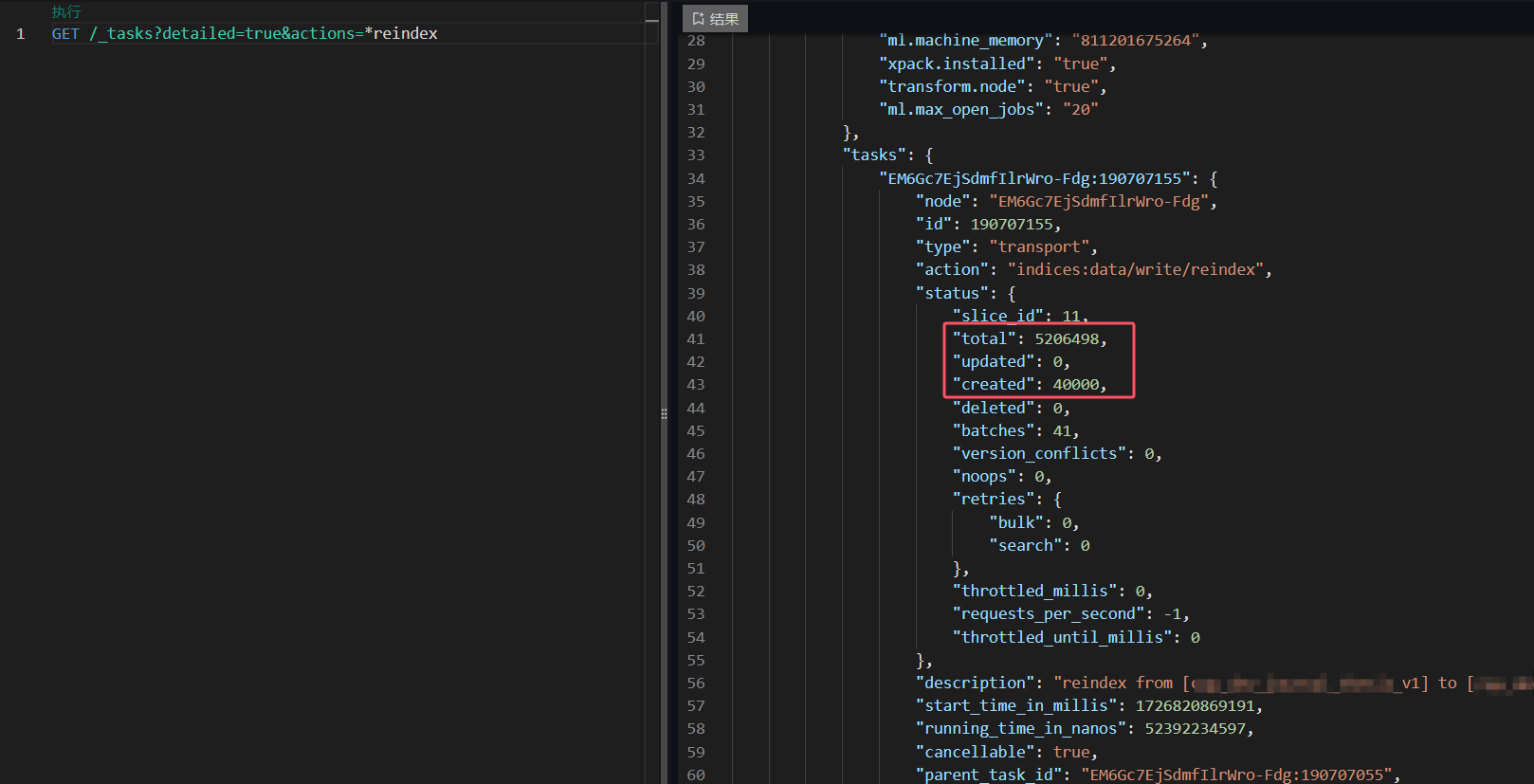
如果需要查看特定的任务信息,可以使用:
GET /_tasks/<task_id>
将 <task_id> 替换为实际的任务 ID
取消重建任务
如果在迁移过程中需要停止重建任务,可以使用以下命令取消指定任务:
POST /_tasks/<task_id>/_cancel
注意事项
- 在迁移完成后,可以对新索引进行验证,确保数据完整性和准确性
- 迁移完成后,可以删除旧索引以释放存储空间
以下为官方文档的翻译,官方文档链接:[Reindex API | Elasticsearch Guide 8.15] | Elastic
官方文档的翻译:Reindex API
Reindex API 用于将文档从一个索引复制到另一个索引。它允许你将数据从源索引、别名或数据流迁移到目标索引。但需要注意,源和目标不能相同,不能将数据流重新索引到自身。
基本要求
- 源索引的
_source字段必须启用,才能提取文档内容。 - 目标索引在执行
_reindex前应按照需求配置好,Reindex API 不会复制源索引的设置(例如映射、分片、副本等),这些需要在重新索引前手动配置。
基本使用示例
POST /_reindex
{"source": {"index": "my-index-000001"},"dest": {"index": "my-new-index-000001"}
}
请求条件
如果启用了 Elasticsearch 的安全功能,执行 Reindex API 需要具备以下权限:
- 对源数据流、索引或别名的读取权限。
- 对目标数据流、索引或别名的写入权限。
- 如果希望 Reindex API 自动创建数据流或索引,还需具备
auto_configure、create_index或manage权限。 - 若从远程集群重新索引,需要配置
reindex.remote.whitelist设置,并且源集群用户需要具有monitor和read权限。
功能描述
Reindex API 会从源索引提取文档,并将其重新索引到目标索引。支持复制全部文档或文档子集。在没有指定 version_type 或设置为 internal 时,Elasticsearch 将不考虑版本冲突,直接覆盖目标索引中已有的相同 ID 文档。如果将 version_type 设置为 external,则会保留源文档的版本信息,创建缺失文档,更新目标索引中较旧版本的文档。
异步执行 Reindex
通过将 wait_for_completion 设置为 false,可以异步执行 Reindex。此时,Elasticsearch 会执行一些预检操作,启动请求,并返回一个任务 ID,你可以用它来取消或查询任务状态。
从多个源重新索引
如果需要从多个源进行重新索引,建议一次处理一个源,而不是使用通配符进行批量处理。这样可以在出现错误时重新启动特定的索引过程。
示例 Bash 脚本
for index in i1 i2 i3 i4 i5; docurl -HContent-Type:application/json -XPOST localhost:9200/_reindex?pretty -d'{"source": {"index": "'$index'"},"dest": {"index": "'$index'-reindexed"}}'
done
限速和重新限速
Reindex 支持通过 requests_per_second 参数对批次操作进行限速。设置为任意正数可限制每秒的请求次数,设置为 -1 则禁用限速。例如,假设批次大小为 1000,requests_per_second 设置为 500:
目标时间 = 1000 / 500 = 2 秒
等待时间 = 目标时间 - 写入时间 = 2 秒 - 0.5 秒 = 1.5 秒
可以使用 _rethrottle API 动态调整正在运行的 Reindex 请求的限速:
POST _reindex/{task_id}/_rethrottle?requests_per_second=-1
分片处理(Slicing)
Reindex 支持使用切片(Sliced scroll)并行化处理。手动切片时,可以为每个请求提供一个 slice 参数:
POST /_reindex
{"source": {"index": "my-index-000001","slice": {"id": 0,"max": 2}},"dest": {"index": "my-new-index-000001"}
}
也可以使用 slices 参数让 Elasticsearch 自动选择切片数量:
POST /_reindex?slices=5&refresh
{"source": {"index": "my-index-000001"},"dest": {"index": "my-new-index-000001"}
}
如何选择切片数量
一般情况下,切片数量与索引中的分片数量相同效果最好。如果分片数量过大(例如 500),可以选择较小的切片数量,因为切片过多可能影响性能。通常建议切片数量不超过分片数量,以避免额外的开销。
路由
Reindex 默认保留文档的路由信息,但可以通过 dest.routing 参数进行更改:
POST /_reindex
{"source": {"index": "source","query": {"match": {"company": "cat"}}},"dest": {"index": "dest","routing": "=cat"}
}
批次大小
默认情况下,Reindex 使用 1000 条文档作为批次大小,可以通过 size 参数自定义批次大小:
POST /_reindex
{"source": {"index": "source","size": 100},"dest": {"index": "dest"}
}
使用 Ingest 管道进行重建索引
您可以在重建索引时通过 ingest 管道处理文档。以下是指定管道的示例:
json复制代码POST _reindex
{"source": {"index": "source"},"dest": {"index": "dest","pipeline": "some_ingest_pipeline"}
}
查询参数
- refresh(可选,布尔):如果为 true,请求会刷新受影响的分片,使此操作对搜索可见。默认值为 false。
- timeout(可选,时间单位):每个索引操作等待的时间,包括:
- 自动索引创建
- 动态映射更新
- 等待活动分片 默认值为 1 分钟。这确保 Elasticsearch 至少等待超时之前不会失败。实际等待时间可能更长,特别是在发生多次等待时。
- wait_for_active_shards(可选,字符串):必须激活的分片副本数量才能继续操作。可以设置为 “all” 或任意正整数,最大值为索引中的总分片数量(number_of_replicas+1)。默认值为 1,即主分片。
- wait_for_completion(可选,布尔):如果为 true,请求会阻塞,直到操作完成。默认值为 true。
- requests_per_second(可选,整数):此请求的速率限制,每秒的子请求数量。默认值为 -1(无速率限制)。
- require_alias(可选,布尔):如果为 true,目标必须是索引别名。默认值为 false。
- scroll(可选,时间单位):指定在滚动搜索中应保持一致的索引视图的时间。
- slices(可选,整数):将此任务分成的切片数量。默认值为 1,即任务未被切片成子任务。
- max_docs(可选,整数):处理的最大文档数量。默认处理所有文档。当设置为小于或等于 scroll_size 的值时,将不会使用滚动来检索操作的结果。
请求体
-
conflicts(可选,枚举):设置为 “proceed” 以继续重建索引,即使存在冲突。默认值为 “abort”。
-
max_docs(可选,整数):重建索引的最大文档数量。如果 conflicts 设置为 “proceed”,重建索引可能会尝试从源中重建更多文档,直到成功将 max_docs 文档索引到目标中,或者遍历完源查询中的所有文档。
-
source(必需,字符串):您要复制的数据流、索引或别名的名称。也接受以逗号分隔的列表,以从多个源重建索引。
-
query(可选,查询对象):使用查询 DSL 指定要重建的文档。
-
remote(可选,字符串):要从中索引的远程 Elasticsearch 实例的 URL。索引远程数据时需要此参数。
- username(可选,字符串):用于远程主机身份验证的用户名。
- password(可选,字符串):用于远程主机身份验证的密码。
- socket_timeout(可选,时间单位):远程套接字读取超时。默认值为 30 秒。
- connect_timeout(可选,时间单位):远程连接超时。默认值为 30 秒。
- headers(可选,对象):包含请求头的对象。
-
size(可选,整数):每批次要索引的文档数量。用于远程索引时,确保批次适合堆内缓冲区,默认最大大小为 100 MB。
-
slice(可选,整数):手动切片的切片 ID。
- max(可选,整数):切片的总数。
-
sort(可选,列表):在索引之前按字段排序的以逗号分隔的 : 对列表。与 max_docs 一起使用以控制重建的文档。
注意:在 7.6 中,重建索引时排序功能已被弃用。重建时的排序从未保证按顺序索引文档,并阻碍了重建的进一步发展,例如弹性和性能改进。如果与 max_docs 一起使用,建议使用查询过滤器。
-
_source(可选,字符串):如果为 true,重建所有源字段。设置为列表以重建特定字段。默认值为 true。
-
dest(必需,字符串):您要复制到的数据流、索引或索引别名的名称。
-
version_type(可选,枚举):索引操作使用的版本类型。有效值:internal、external、external_gt、external_gte。有关更多信息,请参见版本类型。
-
op_type(可选,枚举):设置为 “create” 以仅索引不存在的文档(如果缺失则放入)。有效值:index、create。默认值为 index。
要重建到数据流目标,必须将此参数设置为 “create”。
-
pipeline(可选,字符串):要使用的管道名称。
-
script(可选,字符串):重建文档源或元数据时运行的脚本。
- lang(可选,枚举):脚本语言:painless、expression、mustache、java。有关更多信息,请参见脚本。
响应体
- took(整数):整个操作耗时的毫秒数。
- timed_out(布尔):如果在重建期间执行的任何请求超时,则该标志设置为 true。
- total(整数):成功处理的文档数量。
- updated(整数):成功更新的文档数量,即在重建前同一 ID 的文档已存在。
- created(整数):成功创建的文档数量。
- deleted(整数):成功删除的文档数量。
- batches(整数):重建过程中提取的滚动响应的数量。
- noops(整数):由于用于重建的脚本返回了无操作值而被忽略的文档数量。
- version_conflicts(整数):重建中遇到的版本冲突数量。
- retries(整数):重建尝试的重试次数。bulk 表示重试的批量操作数量,search 表示重试的搜索操作数量。
- throttled_millis(整数):请求为符合 requests_per_second 而休眠的毫秒数。
- requests_per_second(整数):在重建过程中有效执行的每秒请求数量。
- throttled_until_millis(整数):此字段在 _reindex 响应中应始终等于零。它仅在使用任务 API 时有意义,指示下次(自纪元以来的毫秒)将在符合 requests_per_second 的情况下再次执行被限制的请求。
- failures(数组):如果在处理过程中有任何不可恢复的错误,则此数组中将包含错误。如果此数组非空,则请求因这些错误而中止。重建是通过批次实现的,任何失败都会导致整个过程中止,但当前批次中的所有失败都会收集到数组中。您可以使用 conflicts 选项防止在版本冲突时重建中止。
示例
根据查询重建选择文档
您可以通过向源添加查询来限制文档。例如,以下请求仅将 user.id 为 kimchy 的文档复制到 my-new-index-000001:
json复制代码POST _reindex
{"source": {"index": "my-index-000001","query": {"term": {"user.id": "kimchy"}}},"dest": {"index": "my-new-index-000001"}
}
使用 max_docs 限制重建的文档数量
您可以通过设置 max_docs 来限制处理的文档数量。例如,以下请求将从 my-index-000001 复制一个文档到 my-new-index-000001:
json复制代码POST _reindex
{"max_docs": 1,"source": {"index": "my-index-000001"},"dest": {"index": "my-new-index-000001"}
}
从多个源重建
源中的 index 属性可以是一个列表,从多个源复制的请求。此请求将从 my-index-000001 和 my-index-000002 索引中复制文档:
json复制代码POST _reindex
{"source": {"index": ["my-index-000001", "my-index-000002"]},"dest": {"index": "my-new-index-000002"}
}
Reindex API 不会处理 ID 冲突,因此最后写入的文档将覆盖之前的版本。如果目标索引已经存在文档,且 ID 与源相同,则它们会被替换。
从远程索引重建数据
Reindex 支持从远程 Elasticsearch 集群重建数据:
POST _reindex
{"source": {"remote": {"host": "http://otherhost:9200","username": "user","password": "pass"},"index": "my-index-000001","query": {"match": {"test": "data"}}},"dest": {"index": "my-new-index-000001"}
}
host 参数必须包含协议、主机和端口(例如 https://otherhost:9200),以及可选路径(例如 https://otherhost:9200/proxy)。username 和 password 参数是可选的,当提供时,_reindex 将使用基本认证连接到远程 Elasticsearch 节点。请确保在使用基本认证时使用 HTTPS,否则密码将以明文发送。可以配置多种设置来管理 HTTPS 连接的行为。
当使用 Elastic Cloud 时,也可以通过有效的 API 密钥对远程集群进行身份验证:
POST _reindex
{"source": {"remote": {"host": "http://otherhost:9200","headers": {"Authorization": "ApiKey API_KEY_VALUE"}},"index": "my-index-000001","query": {"match": {"test": "data"}}},"dest": {"index": "my-new-index-000001"}
}
远程主机必须在 elasticsearch.yml 中通过 reindex.remote.whitelist 属性显式允许。可以设置为允许的远程主机和端口组合的逗号分隔列表。协议被忽略,仅使用主机和端口。例如:
reindex.remote.whitelist: [otherhost:9200, another:9200, 127.0.10.*:9200, localhost:*]
允许的主机列表必须在任何将协调重建的节点上进行配置。
此功能应适用于你可能遇到的任何版本的远程 Elasticsearch 集群。这将允许你通过从旧版本集群中重建数据来升级到当前版本。
Elasticsearch 不支持主要版本之间的向前兼容。例如,不能从 7.x 集群重建到 6.x 集群。
为了启用发送到旧版本 Elasticsearch 的查询,query 参数直接发送到远程主机,不进行验证或修改。
从远程集群重建数据不支持手动或自动切片。
从远程服务器重建数据使用一个堆内存缓冲区,默认最大大小为 100MB。如果远程索引包含非常大的文档,你需要使用较小的批量大小。以下示例将批量大小设置为 10,非常小:
POST _reindex
{"source": {"remote": {"host": "http://otherhost:9200",...},"index": "source","size": 10,"query": {"match": {"test": "data"}}},"dest": {"index": "dest"}
}
还可以通过 socket_timeout 字段设置远程连接的套接字读取超时,通过 connect_timeout 字段设置连接超时。两者的默认值均为 30 秒。此示例将套接字读取超时设置为一分钟,连接超时设置为 10 秒:
POST _reindex
{"source": {"remote": {"host": "http://otherhost:9200",...,"socket_timeout": "1m","connect_timeout": "10s"},"index": "source","query": {"match": {"test": "data"}}},"dest": {"index": "dest"}
}配置 SSL 参数
从远程重建支持可配置的 SSL 设置。这些设置必须在 elasticsearch.yml 文件中指定,安全设置在 Elasticsearch 密钥库中添加。在 _reindex 请求的主体中无法配置 SSL。
以下设置是支持的:
-
reindex.ssl.certificate_authorities- 应信任的 PEM 编码证书文件的路径列表。不能同时指定
reindex.ssl.certificate_authorities和reindex.ssl.truststore.path。
- 应信任的 PEM 编码证书文件的路径列表。不能同时指定
-
reindex.ssl.truststore.path- 包含要信任的证书的 Java 密钥库文件的路径。该密钥库可以是 “JKS” 或 “PKCS#12” 格式。不能同时指定这两个设置。
-
reindex.ssl.truststore.password- 信任库的密码(
reindex.ssl.truststore.path)。[7.17.0] 在 7.17.0 中已弃用。建议使用reindex.ssl.truststore.secure_password。
- 信任库的密码(
-
reindex.ssl.truststore.secure_password(安全)- 信任库的密码(
reindex.ssl.truststore.path)。此设置不能与reindex.ssl.truststore.password一起使用。
- 信任库的密码(
-
reindex.ssl.truststore.type- 信任库的类型(
reindex.ssl.truststore.path)。必须是 jks 或 PKCS12。如果信任库路径以 “.p12”、“.pfx” 或 “pkcs12” 结尾,此设置默认为 PKCS12。否则,默认为 jks。
- 信任库的类型(
-
reindex.ssl.verification_mode- 指示保护中间人攻击和证书伪造的验证类型。可以是 full(验证主机名和证书路径)、certificate(验证证书路径,但不验证主机名)或 none(不进行验证 - 强烈建议在生产环境中不要使用)。默认为 full。
-
reindex.ssl.certificate- 指定用于 HTTP 客户端身份验证的 PEM 编码证书(或证书链)(如果远程集群需要)。此设置要求设置
reindex.ssl.key。不能同时指定这两个设置。
- 指定用于 HTTP 客户端身份验证的 PEM 编码证书(或证书链)(如果远程集群需要)。此设置要求设置
-
reindex.ssl.key- 指定与用于客户端身份验证的证书相关联的 PEM 编码私钥的路径(
reindex.ssl.certificate)。不能同时指定这两个设置。
- 指定与用于客户端身份验证的证书相关联的 PEM 编码私钥的路径(
-
reindex.ssl.key_passphrase- 如果 PEM 编码私钥被加密,指定解密其的密码(
reindex.ssl.key)。[7.17.0] 在 7.17.0 中已弃用。建议使用reindex.ssl.secure_key_passphrase。
- 如果 PEM 编码私钥被加密,指定解密其的密码(
-
reindex.ssl.secure_key_passphrase(安全)- 如果 PEM 编码私钥被加密,指定解密其的密码(
reindex.ssl.key)。不能与reindex.ssl.key_passphrase一起使用。
- 如果 PEM 编码私钥被加密,指定解密其的密码(
-
reindex.ssl.keystore.path- 指定包含用于 HTTP 客户端身份验证的私钥和证书的密钥库的路径(如果远程集群需要)。该密钥库可以是 “JKS” 或 “PKCS#12” 格式。不能同时指定这两个设置。
-
reindex.ssl.keystore.type- 密钥库的类型(
reindex.ssl.keystore.path)。必须是 jks 或 PKCS12。如果密钥库路径以 “.p12”、“.pfx” 或 “pkcs12” 结尾,此设置默认为 PKCS12。否则,默认为 jks。
- 密钥库的类型(
-
reindex.ssl.keystore.password- 密钥库的密码(
reindex.ssl.keystore.path)。[7.17.0] 在 7.17.0 中已弃用。建议使用reindex.ssl.keystore.secure_password。
- 密钥库的密码(
-
reindex.ssl.keystore.secure_password(安全)- 密钥库的密码(
reindex.ssl.keystore.path)。此设置不能与reindex.ssl.keystore.password一起使用。
- 密钥库的密码(
-
reindex.ssl.keystore.key_password- 密钥库中密钥的密码(
reindex.ssl.keystore.path)。默认为密钥库密码。[7.17.0] 在 7.17.0 中已弃用。建议使用reindex.ssl.keystore.secure_key_password。
- 密钥库中密钥的密码(
-
reindex.ssl.keystore.secure_key_password(安全)- 密钥库中密钥的密码(
reindex.ssl.keystore.path)。默认为密钥库密码。此设置不能与reindex.ssl.keystore.key_password一起使用。
- 密钥库中密钥的密码(


















