小罗碎碎念
今日顶刊:Nature
这篇文章今年6月就发表了,当时我分析的时候,还是预印本,没有排版。今天第一篇推文介绍的是Faisal Mahmood ,所以又把这篇文章拉出来详细分析一下。

| 作者角色 | 作者姓名 | 单位名称 | 单位英文名称 |
|---|---|---|---|
| 第一作者 | Ming Y. Lu | 哈佛医学院布里格姆和妇女医院病理科 | Department of Pathology, Brigham and Women’s Hospital, Harvard Medical School |
| 第一作者 | Bowen Chen | 哈佛医学院布里格姆和妇女医院病理科 | Department of Pathology, Brigham and Women’s Hospital, Harvard Medical School |
| 第一作者 | Drew F. K. Williamson | 哈佛医学院布里格姆和妇女医院病理科 | Department of Pathology, Brigham and Women’s Hospital, Harvard Medical School |
| 通讯作者 | Faisal Mahmood | 哈佛医学院布里格姆和妇女医院病理科 | Department of Pathology, Brigham and Women’s Hospital, Harvard Medical School |
这篇文章介绍了一个名为PathChat的多模态生成性人工智能(AI)助手,专为病理学设计。PathChat结合了视觉编码器和预训练的大型语言模型,通过超过456,000个视觉-语言指令进行微调,以理解和回应与病理学相关的复杂查询。
研究者们将PathChat与其他多模态视觉-语言AI助手以及商业可用的多模态通用AI助手ChatGPT-4(由GPT-4V提供支持)进行了比较。PathChat在多种组织来源和疾病模型的多选诊断问题上展现出了最先进的性能。
此外,通过开放式问题和人类专家评估,PathChat在回答与病理学相关的多样化查询时,总体上产生了更准确、病理学家更偏好的响应。
PathChat的开发包括使用一个最先进的视觉编码器(UNI3),并在1.18百万病理图像和标题对上进行视觉-语言预训练。然后将视觉编码器与一个13亿参数的预训练Llama 2大型语言模型(LLM)连接,形成一个完整的多模态大型语言模型(MLLM)架构。最终,使用超过450,000条指令对MLLM进行微调,构建了PathChat。
文章还详细描述了PathChat在多种应用中的能力,包括分析不同器官部位和实践的病理学案例。此外,研究者们还策划了一个高质量的基准测试,用于评估MLLM在病理学中的表现,包括开放式视觉病理学问题。PathChat在这些评估中与其他MLLMs相比,展现出了优越的性能。
最后,文章讨论了PathChat在病理学中的潜在应用,包括病理学教育、研究和人类参与的临床决策。随着技术的成熟,PathChat可能会在未来发挥更大的作用。
一、引言
计算病理学近年来经历了显著转变,得益于数字切片扫描的普及和机构采纳、人工智能(AI)研究的快速进展、大型数据集的易获取性以及高性能计算资源的显著增加[1,2,7]。
研究者们利用深度学习处理多样化的任务,包括癌症亚型分类[8,9]、分级[10,11]、转移检测[12]、生存预测[13-17]、治疗反应预测[18,19]、肿瘤起源部位预测[20,21]、突变预测和生物标志物筛选[22-24]等[25]。
此外,基于大规模未标记组织病理学图像数据集训练的通用视觉编码器模型[26],作为多功能、任务无关的模型基础[3,4],为计算病理学中多项任务的性能和标签效率提升铺平了道路。
然而,计算病理学的发展尚未充分体现自然语言在病理学中的重要作用,后者是解锁丰富、多样化累积人类医学知识的关键,也是模型开发的监督信号,以及强大AI模型与终端用户直观互动的统一媒介。
值得注意的是,在机器学习领域,代表性工作[27,28]表明,大规模视觉-语言表征学习可增强仅视觉的AI模型,赋予其新的能力,如零样本图像识别和文本到图像检索。
根据架构设计、训练数据和目标,预训练的视觉-语言系统通常可以针对特定任务进行微调,范围从回答视觉问题、图像字幕生成到目标检测和语义分割。在医学成像和计算病理学领域,研究者们最近开始利用配对的生物医学图像和说明或报告[29-33]等多样化来源进行视觉-语言预训练,包括开发针对特定领域(如病理学[30,33-35]和放射学[36-38])的类CLIP模型[27]。
在计算病理学领域,一些研究在选定的诊断和检索任务中展示了零样本性能的潜力[30,33,34]。其他研究者尝试了专用的模型以回答生物医学视觉问题或进行图像字幕生成[39-43]。
随着大型语言模型(LLMs)[44-47]的兴起、多模态LLMs(MLLMs)[5,48,49]的快速进步以及生成性AI[50]更广泛领域的发展,计算病理学即将迎来新的前沿,其强调自然语言和人类互动作为AI模型设计和用户体验的关键组成部分,以及强大的视觉处理能力。
多模态生成性AI产品如ChatGPT在广泛的常规、创意和专业用例[6,51]中展示了令人印象深刻的性能,包括编码、写作、摘要、数据分析、回答问题、翻译甚至图像生成,同时通过直观且互动的用户界面提供访问。尽管已有尝试探究其在回答医学相关问题方面的性能[52-57],但其协助专业人士和研究者从事解剖病理学这一高度专业化但重要子领域的能力尚相对未探索。
然而,互动多模态AI副驾驶在病理学中的潜在应用是巨大的。理论上,理解和回应自然语言中复杂查询的能力,可以使病理学AI副驾驶在临床决策制定、教育研究等各个人类参与环节中成为有益的伴侣。
例如,AI副驾驶能够摄取组织病理学图像,提供形态学外观的初步评估,并识别潜在的恶性特征。随后,病理学家或学员可以提供更多关于病例的背景信息,如患者的临床参数和组织部位,并要求模型提出鉴别诊断。
如果认为合理,用户可以请求对辅助测试和免疫组化(IHC)染色的有益建议,以缩小鉴别诊断范围。最后,这些测试结果也可以提供给模型,模型据此做出最终推断并得出诊断。
在研究中,能够总结大型组织病理学图像队列形态学特征的多模态AI副驾驶,有可能实现形态学标记物在大数据队列中的自动量化和解释。在医学教育中,一个准确、按需互动的AI伴侣可能有助于民主化地获取专家级指导和培训,从而缩小地区间医疗保健提供的差距。
二、用于人类病理学的多模态生成性人工智能(AI)副驾驶
本文中,作者开发了一种名为PathChat的多模态生成性AI副驾驶系统,专为人类病理学设计,并由定制微调的多模态大型语言模型(MLLM)驱动。
为了构建一个能够处理视觉和自然语言输入的MLLM,作者从UNI[3]开始,这是一个在超过100万张组织学图像补丁(来自超过100,000张玻片)上使用自监督学习预训练的仅视觉编码器。
作者对UNI编码器进行了进一步的视觉-语言预训练,使用了118万病理学图像和说明对,以使其图像表示空间与病理学文本对齐[34]。随后,将得到的视觉编码器通过多模态投影模块连接到一个拥有130亿参数的预训练Llama 2 LLM[46],形成了完整的MLLM架构(有关PathChat模型的设计和训练的更多细节,请参见“方法和训练PathChat模型”部分)。
最终,使用超过450,000条指令的精选数据集对MLLM进行了微调,以构建PathChat(见图1和扩展数据图1),该系统能够理解病理学图像和文本,并回应复杂的病理学相关问题。
图1提供了PathChat模型的概述,包括指令遵循数据集的策划和PathChat模型的设计。
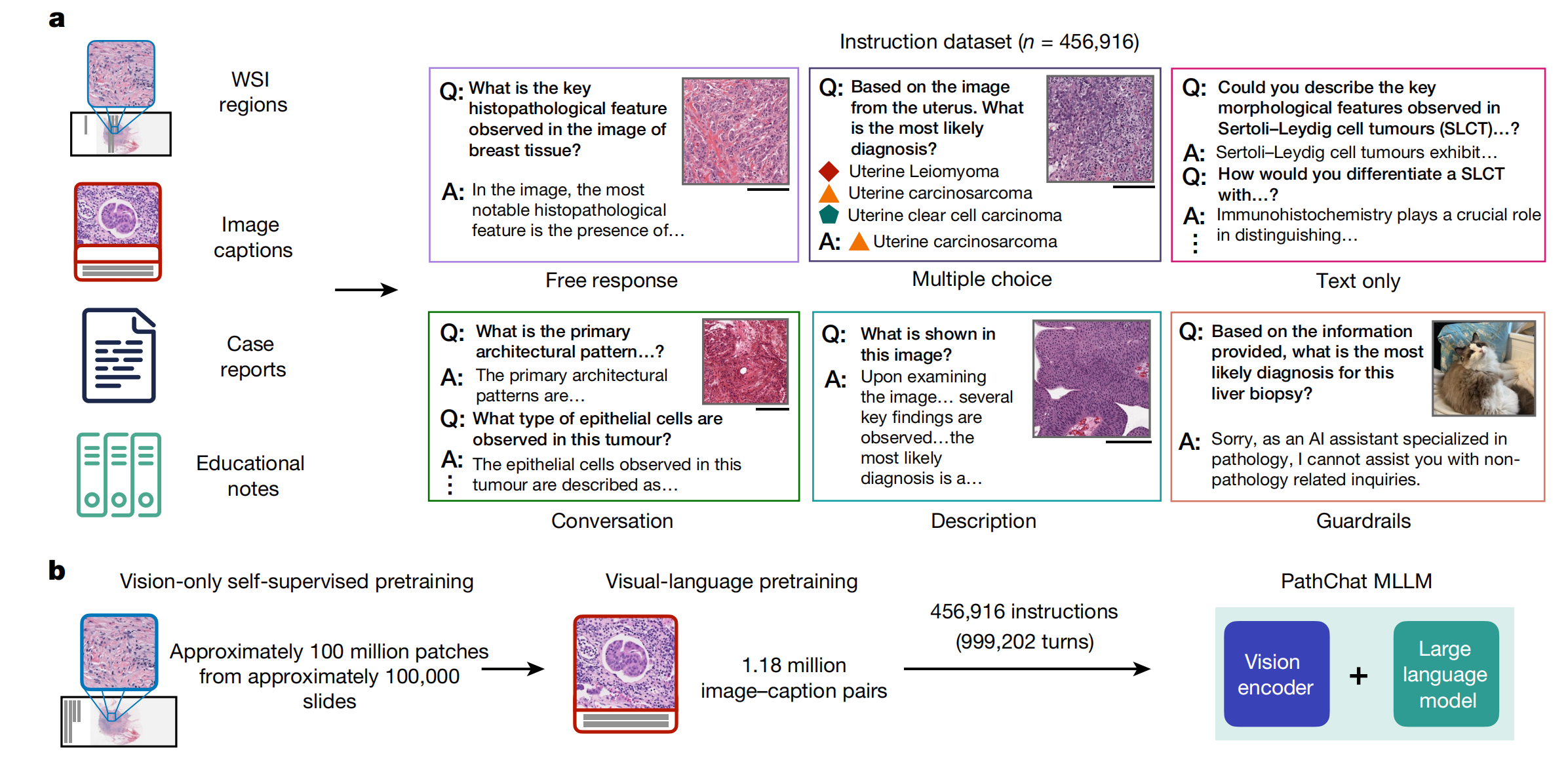
a部分描述了目前最大的专门用于病理学的指令微调数据集的策划。这个数据集包含了456,916条指令和相应的回应,涵盖了多种格式,例如多轮对话、多项选择题和简短回答。这些数据来自不同的来源,确保了模型能够理解和回应各种类型的查询。
b部分介绍了构建PathChat模型的过程。研究团队从一个最先进的(SOTA)仅视觉的、自监督预训练的基础编码器模型UNI开始,进行了进一步的视觉-语言预训练,类似于CONCH。
然后,将得到的视觉编码器通过一个多模态投影模块连接到一个预训练的、拥有130亿参数的Llama 2大型语言模型(LLM),形成了完整的多模态大型语言模型(MLLM)架构。这个MLLM在策划好的指令遵循数据集上进行了微调,以构建PathChat,这是一个专门用于人类病理学的视觉-语言AI助手。
作者展示了PathChat在各种应用中的能力,包括分析来自不同器官部位和实践的病理学案例(见图2和3)。
图2展示了PathChat在多项选择诊断问题上的表现评估。
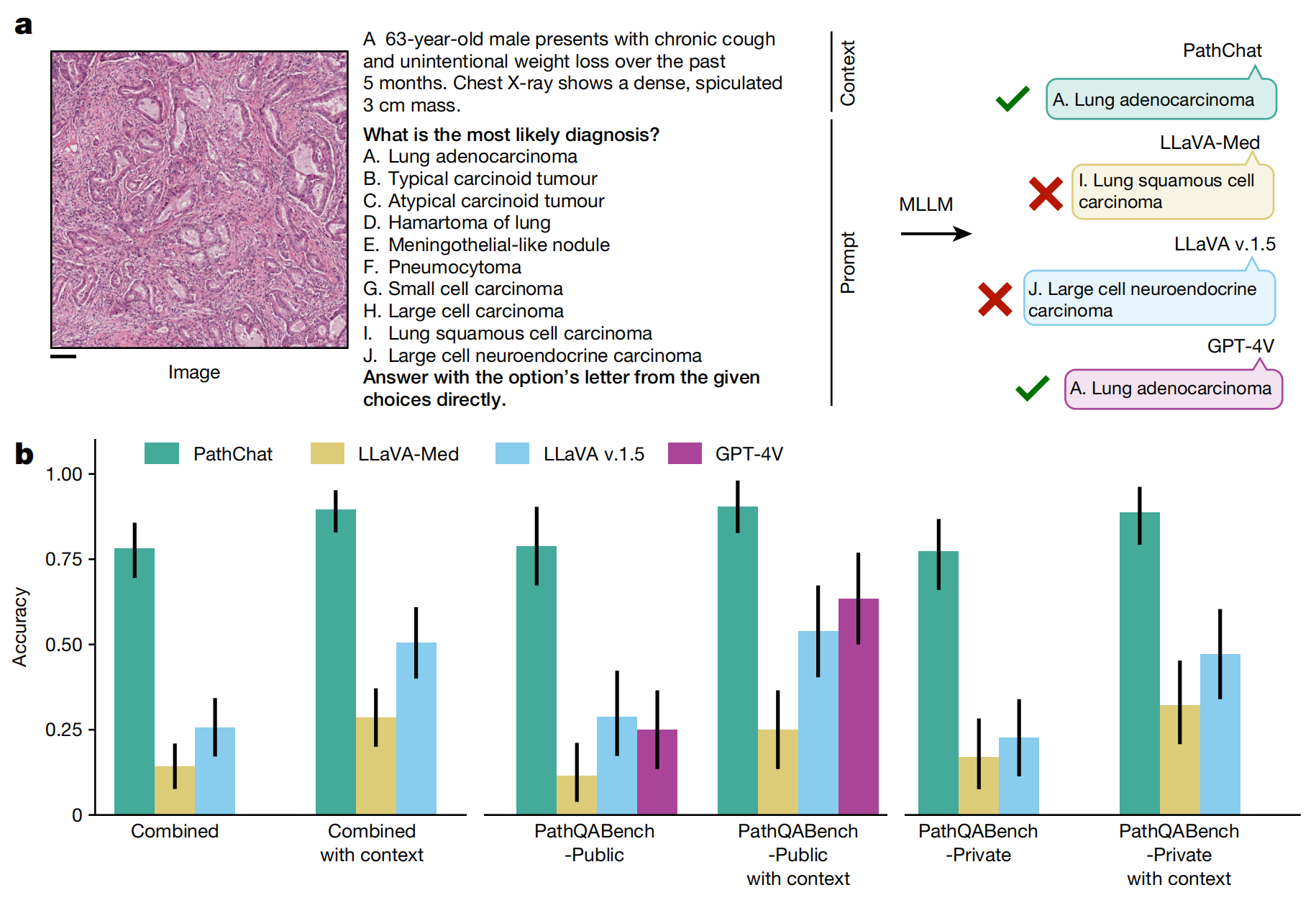
a部分提供了一个多项选择诊断问题的示例。在这个问题中,输入总是包括一个由认证病理学家选择的组织学图像的显著感兴趣区域(ROI),以及一个指令,即从一组可能的选择中选择最可能的诊断。在“图像+临床背景”评估设置中,设计得更接近现实世界的诊断工作流程,病理学家设计的相关临床背景(以蓝色显示)与组织学图像一起提供,并附加在原始问题之前。尺度条表示200微米,用于参考图像中的细节大小。
b部分展示了多模态大型语言模型(MLLMs)在多项选择诊断问题上的准确性。这些评估包括了总共105个问题,其中PathQABench-Public(基于公开可用案例的问题,n=52个问题)和PathQABench-Private(基于私人案例的问题,n=53个问题)。需要注意的是,只有对于基于公开可用案例的问题(PathQABench-Public),才会与GPT-4V进行比较。误差条代表95%的置信区间,中心点代表计算出的准确性。
从图2中可以看出,PathChat在诊断准确性方面的表现。当提供临床背景时,模型的诊断准确性可能会提高,因为额外的信息可以帮助模型更好地理解病例的上下文,从而做出更准确的诊断。这种评估方法有助于验证PathChat在模拟真实世界病理诊断中的有效性和实用性。通过与GPT-4V等其他模型的比较,可以进一步了解PathChat在病理学诊断任务中的性能水平。
图3展示了PathChat在开放式问题回答中的评估以及由七名病理学家组成的小组进行的读者研究。
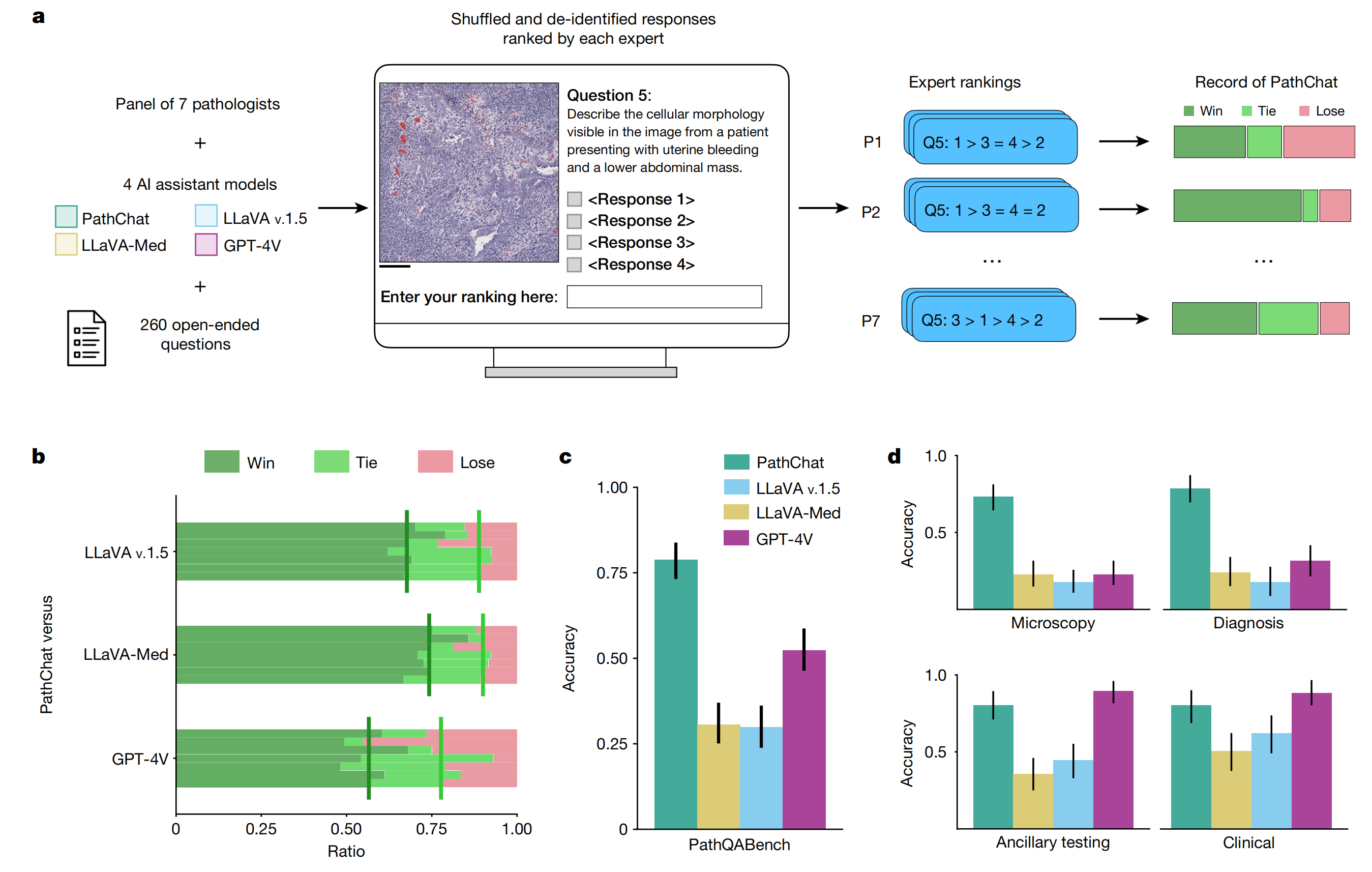
a部分描述了评估工作流程,用于对开放式问题的模型输出进行排名。七名病理学家被招募来评估四个AI助手模型对260个开放式问题的回答。每个问题的模型回答顺序都是随机打乱的,每位病理学家在不知道哪个模型产生了哪个回答的情况下,独立对所有问题的回答进行排名(更详细的信息见“MLLM评估”部分)。尺度条表示200微米,用于参考图像细节的大小。
b部分展示了PathChat与其他MLLMs在开放式问题上的头对头记录,由七名病理学家独立评估。“Win”表示PathChat的排名高于其他模型,“Tie”表示PathChat与模型排名相同,“Lose”表示其他模型的排名高于PathChat。垂直条表示所有七名病理学家的中位胜率(深绿色)和中位赢+平率(浅绿色)。
c部分展示了MLLMs在一组子集(n=235个问题)上的准确性,这些问题是两名病理学家在讨论了模型回答的独立评估后达成共识的。这表明了评估的客观性,因为只有在两位专家达成一致的情况下,问题的回答才被计入分析。
d部分展示了在共识子集上不同类别问题的准确性。这些类别包括显微检查(n=101)、诊断(n=79)、临床(n=61)和辅助检测(n=76)。每个问题可能属于多个类别。在c和d部分中,误差条代表95%的置信区间,中心点代表计算出的准确性。
总体而言,图3提供了PathChat在开放式问题回答中的详细评估,包括与其他MLLMs的比较、病理学家的独立评估以及达成共识的问题的准确性分析。这些评估有助于了解PathChat在病理学相关查询中的性能和可靠性。
此外,作者精选了一个高质量的基准,用于评估MLLM在病理学中的开放式视觉病理学问题的性能,该基准在专家监督下进行筛选(详见“专家筛选的病理学问题基准”部分)。
作者将PathChat与LLaVA[5],一个通用的开源MLLM的SOTA,以及针对生物医学领域定制的LLaVA-Med[53]进行了比较。
尽管作者的模型规模显著更小,服务成本更低,但作者还将其与SOTA商业解决方案ChatGPT-4(由GPT-4V驱动)进行了比较。
三、讨论
计算病理学近年来取得了显著的进步,例如基于图像或基因组数据的日益精确、特定任务的预测模型的开发。
对于组织学图像,最近越来越有兴趣构建基于大量未标记图像的基础任务无关视觉编码器,这些编码器可以为各种监督和无监督下游工作流程提供稳健的特征嵌入。然而,生成性AI技术的爆炸性增长,特别是多模态大型语言模型(MLLM),如ChatGPT,已经开始为计算病理学研究和实际临床病理学应用开辟了可能的新前沿。
具备自然语言理解能力的通用AI模型可以使用文本作为统一媒介,用于灵活地指定用户意图(以定制的提示形式)并产生各种表达水平的输出(从单个单词到二进制或多项选择响应,再到包含推理步骤的连贯句子)。
在进行各种任务(例如,总结、分类、字幕生成、检索、回答问题等)时,这些模型显示出巨大的潜力。对于病理学而言,这样的模型在理论上可以在教育和研究以及人机协同的临床决策制定等广泛场景中发挥作用。
使用诸如从人类反馈中进行强化学习等技术进一步与人类意图对齐,可以降低基于MLLM的AI助手模型的幻觉,并帮助它们捕捉某些特定于病理学的细微差别,例如在仅基于H&E组织学无法排除某些形态相似疾病时请求进一步的上下文信息或测试结果,或在诊断和治疗指南发生变化时寻求对机构特定指南的澄清。
对于实际部署,改进和验证可能也值得进行,以确保模型能够一致且正确地识别无效查询(例如,非病理学相关或无意义的输入)并避免产生意外或错误的输出。
未来的研究可能会进一步增强PathChat和基于MLLM的AI助手的功能,通过添加支持输入整个吉帕像素WSI或多个WSI的功能。这可能会通过提供超出预选代表性ROI的有价值上下文,来扩展它们在诊断挑战性和边缘实体中的实用性。
此外,由于这些模型是在回顾性收集的大数据集上训练的,其中不可避免地包含过时的信息,因此它们可能反映了过去的科学共识,而不是今天的共识。
例如,随着医学术语和指南的发展,引用过时术语“多形性胶质母细胞瘤”的模型响应可能会导致事实上的不准确。除了持续使用最新知识进行训练外,其他研究方向可能涉及编制特定的指令,使模型意识到术语和指南的变化,或使用检索增强生成与持续更新的知识数据库相结合。
最后,为了让这些工具对病理学家和研究更有用,考虑明确支持特定任务(例如精确计数或定位对象)可能是有价值的,并考虑将PathChat类的AI助手与数字切片查看器或电子健康记录等工具集成。