前言
在深度学习中我们需要使用自己的数据集做训练,因此需要将自定义的数据和标签加载到pytorch里面的dataloader里,也就是自实现一个dataloader。
数据集处理
以花卉识别项目为例,我们分别做出图片的训练集和测试集,训练集的标签和测试集的标签

flower_data/
├── train_filelist/
│ ├── image_0001.jpg
│ └── ...
├── val_filelist/
│ ├── image_1001.jpg
│ └── ...
├── train.txt # 格式:文件名 标签
└── val.txt
数据目录的组织方式如上所示。
首先看图片的处理。图片只要做好编号放在同一个文件夹里就好了。

再看标签的处理。标签处理我们自己规定了一种形式,就是图像文件的名称+空格+分类标签。

可以看到前面第一列数据是图像名称,第二列数据是图像的分组,同样的数字为一组。比如分组为0的图像就是同一种花朵。
自定义dataset
源码
import os.path
import numpy as np
import torch
from PIL import Image # 从PIL库导入Image类
from torch.utils.data import Datasetclass FlowerDataSet(Dataset):"""花朵分类任务数据集类,继承自torch的Dataset类"""def __init__(self, root_dir, ann_file, transform=None):"""初始化数据集实例Args:root_dir (str): 数据集根目录路径ann_file (str): 标注文件路径transform (callable, optional): 数据预处理变换函数"""self.ann_file = ann_fileself.root_dir = root_dir# 加载图片路径与标签的映射字典 {文件名: 标签}self.image_label = self.load_annotations()# 构建完整图片路径列表 [root_dir/文件名1, ...]self.image = [os.path.join(self.root_dir, img) for img in list(self.image_label.keys())]# 构建标签列表 [标签1, 标签2, ...]self.label = [lbl for lbl in list(self.image_label.values())] # 重命名为lbl避免与导入的label冲突self.transform = transformdef __len__(self):"""返回数据集样本数量"""return len(self.image)def __getitem__(self, index):"""获取单个样本数据Args:index (int): 样本索引Returns:tuple: (预处理后的图像数据, 对应的标签)"""# 打开图片文件image = Image.open(self.image[index])# 获取对应标签label = self.label[index]# 应用数据预处理if self.transform:image = self.transform(image)# 将标签转换为torch张量label = torch.from_numpy(np.array(label))return image, labeldef load_annotations(self):"""加载标注文件,解析图片文件名和标签的映射关系Returns:dict: {图片文件名: 对应标签} 的字典"""data_infos = {}with open(self.ann_file) as f:# 读取所有行并分割,每行格式应为 "文件名 标签"samples = [x.strip().split(' ') for x in f.readlines()]for filename, label in samples:# 将标签转换为int64类型的numpy数组data_infos[filename] = np.array(label, dtype=np.int64)return data_infos
解析
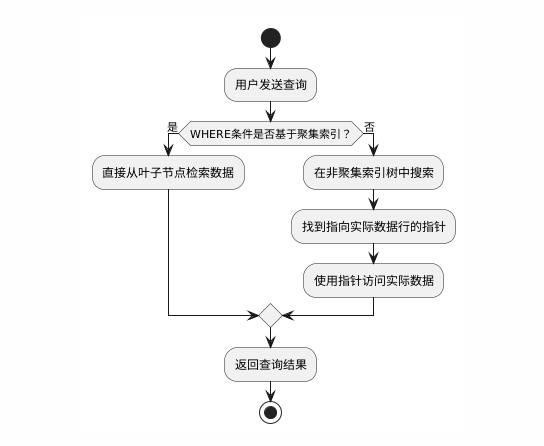
1、将标签数据进行读取,组成一个哈希表,哈希表的键是图像的文件名称,哈希表的值是分组标签。
def load_annotations(self):"""加载标注文件,解析图片文件名和标签的映射关系Returns:dict: {图片文件名: 对应标签} 的字典"""data_infos = {}with open(self.ann_file) as f:# 读取所有行并分割,每行格式应为 "文件名 标签"samples = [x.strip().split(' ') for x in f.readlines()]for filename, label in samples:# 将标签转换为int64类型的numpy数组data_infos[filename] = np.array(label, dtype=np.int64)return data_infos上面的代码里,在录入标签的时候使用数组进行记录,这是为了兼容多标签的场景。如果不考虑兼容问题,仅考虑在单标签场景下的简单实现,可以用下面的代码:
def load_annotations(self):data_infos = {}with open(self.ann_file) as f:for line in f:filename, label = line.strip().split() # 直接解包data_infos[filename] = int(label) # 存为 Python 整数return data_infos# 在 __getitem__ 中直接转为张量
label = torch.tensor(self.labels[index], dtype=torch.long)
2、遍历哈希表,将文件名和标签分别存在两个数组里。这里注意,为了方便后面dataloader按照batch去读取图片,这里要将图片的全路径加到文件名里。
# 构建完整图片路径列表 [root_dir/文件名1, ...]self.image = [os.path.join(self.root_dir, img) for img in list(self.image_label.keys())]# 构建标签列表 [标签1, 标签2, ...]self.label = [lbl for lbl in list(self.image_label.values())] # 重命名为lbl避免与导入的label冲突3、在dataloader向显卡/cpu加载数据的时候会调用getitem方法。比如一个batch里有64个数据,dataloader就会调用64次该方法,将64组图片和标签全部获取后交给运算单元去处理。
def __getitem__(self, index):"""获取单个样本数据Args:index (int): 样本索引Returns:tuple: (预处理后的图像数据, 对应的标签)"""# 打开图片文件image = Image.open(self.image[index])# 获取对应标签label = self.label[index]# 应用数据预处理if self.transform:image = self.transform(image)# 将标签转换为torch张量label = torch.from_numpy(np.array(label))return image, label测试dataloader
import os
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import DataLoader
from torchvision import transforms
from dataloader import FlowerDataSet # 假设你的数据集类在dataloader.py中def denormalize(image_tensor):"""将归一化的图像张量转换为可显示的格式"""mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])image = image_tensor.numpy().transpose((1, 2, 0)) # 转换维度顺序image = std * image + mean # 反归一化image = np.clip(image, 0, 1) # 限制像素值范围return imagedef test_dataloader():# 定义数据预处理data_transforms = {'train': transforms.Compose([transforms.Resize(64),transforms.RandomRotation(45),transforms.CenterCrop(64),transforms.RandomHorizontalFlip(p=0.5),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'valid': transforms.Compose([transforms.Resize(64),transforms.CenterCrop(64),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}# 检查文件路径是否存在print("[1/5] 检查文件路径...")required_files = {'train_txt': './flower_data/train.txt','val_txt': './flower_data/val.txt','train_dir': './flower_data/train_filelist','val_dir': './flower_data/val_filelist'}for name, path in required_files.items():if not os.path.exists(path):print(f"❌ 文件/目录不存在: {path}")returnprint(f"✅ {name}: {path} 存在")# 初始化数据集print("\n[2/5] 加载数据集...")try:train_dataset = FlowerDataSet(root_dir=required_files['train_dir'],ann_file=required_files['train_txt'],transform=data_transforms['train'])val_dataset = FlowerDataSet(root_dir=required_files['val_dir'],ann_file=required_files['val_txt'],transform=data_transforms['valid'])print("✅ 数据集加载成功")except Exception as e:print(f"❌ 数据集加载失败: {str(e)}")return# 打印数据集信息print("\n[3/5] 数据集统计:")print(f"训练集样本数: {len(train_dataset)}")print(f"验证集样本数: {len(val_dataset)}")# 检查单个样本print("\n[4/5] 检查单个样本:")sample_idx = 0try:img, label = train_dataset[sample_idx]print(f"图像张量形状: {img.shape} (应接近 torch.Size([3, 64, 64]))")print(f"标签类型: {type(label)} (应为 torch.Tensor)")print(f"标签值: {label.item()} (应为整数)")except Exception as e:print(f"❌ 样本检查失败: {str(e)}")# 可视化样本print("\n[5/5] 可视化训练集样本...")try:plt.figure(figsize=(8, 8))img_show = denormalize(img)plt.imshow(img_show)plt.title(f"Label: {label.item()}")plt.axis('off')plt.show()except Exception as e:print(f"❌ 可视化失败: {str(e)}")# 检查DataLoaderprint("\n[附加] 检查DataLoader:")train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=2, shuffle=False)for loader, name in [(train_loader, '训练集'), (val_loader, '验证集')]:print(f"\n{name} DataLoader测试:")try:batch = next(iter(loader))images, labels = batchprint(f"批次图像形状: {images.shape} (应接近 [batch, 3, 64, 64])")print(f"批次标签示例: {labels[:5].numpy()}")print(f"像素值范围: [{images.min():.3f}, {images.max():.3f}]")except Exception as e:print(f"❌ {name} DataLoader错误: {str(e)}")if __name__ == '__main__':test_dataloader()
在测试代码中,分别测试了文件路径,dataset是否正常创建,dataset样本数量,dataset样本格式,dataset数据可视化,dataloader数据样式。


在打印日志的时候需要注意,dataset和dataloader里面的变量都是张量形式的,所以需要转换成python标量再打印。比如从dataset里取出的标签label是一个一维张量,需要通过label.item()进行转换。
在遍历的时候为了简化代码,将两个dataloader放在同一个循环语句中处理,并且通过增加name变量来区分两个dataloader。
for loader, name in [(train_loader, '训练集'), (val_loader, '验证集')]: