resnet
# 1. 从 torchvision 中加载预训练的 ResNet18 模型
# pretrained=True 表示使用在 ImageNet 上预训练过的参数,学习效果更好
base_model_resnet18 = models.resnet18(pretrained=True)# 2. 获取 ResNet18 模型中全连接层(fc)的输入特征数
# 这是为了方便替换成我们自己任务的输出类别数
num_ftrs = base_model_resnet18.fc.in_features# 3. 替换原来的全连接层
# 原本的 fc 层是用来预测 1000 类(ImageNet),现在我们改成自己项目的 num_classes 类
# 比如 ASL 手势识别是 29 类,就写 nn.Linear(num_ftrs, 29)
base_model_resnet18.fc = nn.Linear(num_ftrs, num_classes)# 4. 把模型移动到 GPU 或 CPU 上进行训练
# device 变量一般是提前设置好的,比如:device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
base_model_resnet18 = base_model_resnet18.to(device)# 5. 使用模型对一批图像做预测
# 假设 b_img_rgb 是一个 batch 的图像张量(例如大小为 [64, 3, 224, 224]),表示 64 张 RGB 图
# .to(device) 表示把图像也放到和模型相同的设备上(GPU/CPU)
# 调用模型,相当于做前向传播,输出每张图片在 29 个类别上的得分(logits)
base_model_resnet18(b_img_rgb.to(device)).shape
输出torch.Size([64, 29])
表示:模型为每张图像输出了一个 长度为 29 的向量,每个数字代表这张图在某一类上的预测得分(不是概率,还没 softmax)。
base_model_resnet18 = models.resnet18(pretrained=True)
创建一个基于 ResNet18 的图像分类模型,并加载预训练参数,把它存到变量 base_model_resnet18中
loss_fn = nn.CrossEntropyLoss()
# 定义一个“交叉熵损失函数”(Cross Entropy Loss)
# 这个函数专门用于“分类问题”(比如手势识别有 29 个类别)
# 它会比较:
# - 模型输出的预测结果(如:[0.1, 0.2, ..., 0.05])
# - 和真实的标签(如:第 3 类)
# 然后计算两者差距,差距越小越好,模型就越准确。
optimizer = torch.optim.SGD(base_model_resnet18.parameters(), lr=1e-3)
# 定义一个优化器,用来更新模型参数,让 loss 更小
# 使用的是 “随机梯度下降(SGD)” 优化方法
# 参数解释:
# base_model_resnet18.parameters():告诉优化器要优化哪些参数(就是模型的全部参数)
# lr=1e-3:学习率(learning rate),表示每次更新的步子有多大,这里是 0.001
loss_fn = nn.CrossEntropyLoss() | 定义分类任务用的损失函数,用来衡量“模型预测”和“真实标签”的差距 |
optimizer = torch.optim.SGD(...) | 定义优化器,训练过程中帮你更新模型参数,让模型学得更好 |
# 设置训练轮数(epoch 表示:把整个训练集过一遍)
epochs = 25 # 一共训练 25 轮# 创建空列表,用来保存每一轮的训练/测试损失和准确率(后面可以画图)
train_loss_list = [] # 存每一轮训练集的 loss
train_acc_list = [] # 存每一轮训练集的准确率
test_loss_list = [] # 存每一轮测试集的 loss
test_acc_list = [] # 存每一轮测试集的准确率# 开始训练循环,共执行 epochs 次
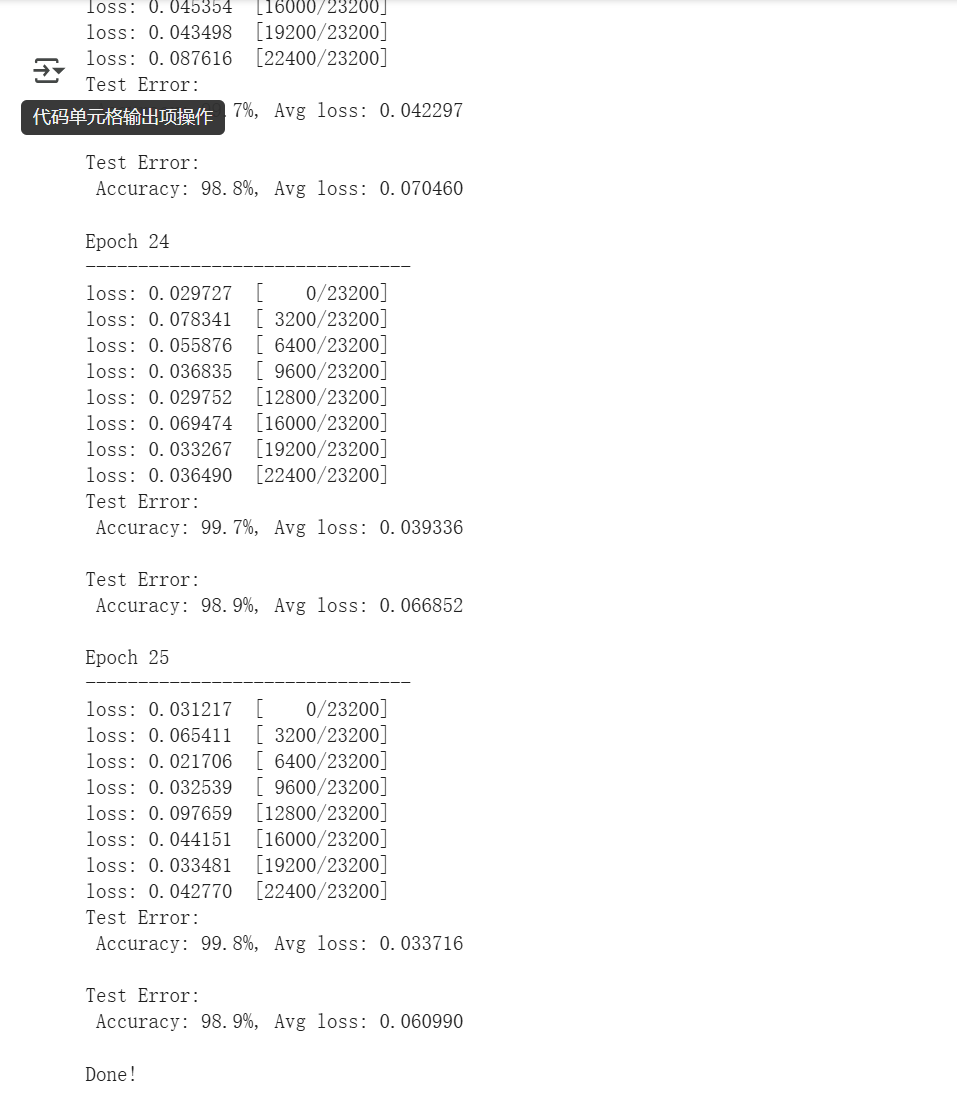
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------") # 打印当前是第几轮训练# ---------- 训练模型 ----------# 调用你自定义的 train() 函数,执行一轮训练# 它会对 base_model_resnet18 模型进行训练,使用指定的 loss 函数和优化器train(train_dataloader, base_model_resnet18, loss_fn, optimizer)# ---------- 评估模型 ----------# 在训练集上测试模型效果,获取当前的 loss 和 正确率train_loss, train_correct = test(train_dataloader, base_model_resnet18, loss_fn)# 在测试集(验证集)上测试模型效果,获取 loss 和 正确率test_loss, test_correct = test(test_dataloader, base_model_resnet18, loss_fn)# ---------- 保存数据 ----------# 把每一轮的损失和准确率保存到列表中,后面可以画图分析训练效果train_loss_list.append(train_loss)train_acc_list.append(train_correct)test_loss_list.append(test_loss)test_acc_list.append(test_correct)# 所有训练轮次完成
print("Done!")
# 把训练集准确率记录保存为 acc
acc = train_acc_list# 把测试集准确率记录保存为 val_acc(val 表示 validation)
val_acc = test_acc_list# 把训练集损失记录保存为 loss
loss = train_loss_list# 把测试集损失记录保存为 val_loss
val_loss = test_loss_list# 创建一个迭代次数(epoch)的范围,比如 range(25) 表示从 0 到 24
epochs_range = range(epochs)# 设置画布大小为 8x8 英寸
plt.figure(figsize=(8, 8))# 画第一个子图(1行2列的第1个图):准确率曲线
plt.subplot(1, 2, 1) # 行数=1,列数=2,这是第1个图
plt.plot(epochs_range, acc, label='Training Accuracy') # 训练集准确率折线图
plt.plot(epochs_range, val_acc, label='Validation Accuracy') # 验证集准确率折线图
plt.legend(loc='lower right') # 设置图例显示在右下角
plt.title('Training and Validation Accuracy') # 设置标题# 画第二个子图(1行2列的第2个图):损失曲线
plt.subplot(1, 2, 2) # 行数=1,列数=2,这是第2个图
plt.plot(epochs_range, loss, label='Training Loss') # 训练集损失折线图
plt.plot(epochs_range, val_loss, label='Validation Loss') # 验证集损失折线图
plt.legend(loc='upper right') # 图例显示在右上角
plt.title('Training and Validation Loss') # 设置标题# 显示整个图像
plt.show()

# 创建空列表:用于保存最终的预测标签、真实标签、预测概率
predict_list = [] # 保存预测标签(整数类编号)
label_list = [] # 保存真实标签(整数类编号)
predict_pro_list = [] # 保存预测概率(softmax 后的概率)# 创建 softmax 层,将模型的输出 logits 转换为概率分布(每一类的可能性)
m_softmax = nn.Softmax(dim=1) # dim=1 表示在每一行上做 softmax(对每张图片的输出做 softmax)# 遍历测试数据集中的每一个 batch(图像+真实标签)
for (img_rgb, y) in test_dataloader:# 把图像和标签送到和模型一样的设备上(CPU 或 GPU)img_rgb = img_rgb.to(device)y = y.to(device)# 模型对图像进行预测,输出的是“原始得分”(logits)predict_score = base_model_resnet18(img_rgb)# 将原始得分用 softmax 转换为概率predict_pro = m_softmax(predict_score) # 每张图会得到一个 shape=[num_classes] 的概率向量# 使用 numpy 的 argmax,取概率最大值对应的类别编号作为“预测标签”predict_label = np.argmax(predict_score.detach().cpu().numpy(), axis=1)# 把每个 batch 的 softmax 概率保存到列表中predict_pro_list.append(predict_pro.detach().cpu().numpy())# 把预测标签保存到列表中predict_list.append(predict_label)# 把真实标签也保存到列表中(用于后面比较准确率等)label_list.append(y.detach().cpu().numpy())# 将预测的概率拼接成一个大矩阵(np.vstack 是垂直拼接)
# 然后取第 2 列([:,1]),表示预测为“第2类(index=1)”的概率 —— 适用于二分类
predict_pro_array = np.vstack(predict_pro_list)[:, 1]# 将预测标签列表拼接成一维数组(从多个 batch 拼起来)
predict_array = np.hstack(predict_list)# 将真实标签列表也拼接成一维数组
label_array = np.hstack(label_list)# 打印前 5 个预测概率、预测标签、真实标签,看看模型表现
predict_pro_array[:5], predict_array[:5], label_array[:5]

















![[从零开始学习JAVA ] 深入多线程](https://i-blog.csdnimg.cn/direct/4a9d4d39a97040b2b1470caf1506e32a.png)



