抓包分析,用抓包分析爬取腾讯视频某视频所有评论(Fiddler工具包的分享)
文章目录
- 抓包分析,用抓包分析爬取腾讯视频某视频所有评论(Fiddler工具包的分享)
- 一、抓包分析
- 1.下载工具并安装
- 2.Fiddler工具的使用
- 二、爬取腾讯视频某视频所有评论
- 1.思路分析
- 2.具体代码
- 3.结果展示
一、抓包分析
1.下载工具并安装
如果我们要进行抓包分析,首先,我们必须要有一款抓包的工具,只有用工具抓到包,我们才能进行分析,在这里我介绍一款抓包软件Fiddler,我这里有这个软件的分享:
链接:https://pan.baidu.com/s/1JvJvH7wfRLzALluOrOlcvQ
提取码:9099
安装不需要过多的说,按照上面提示的步骤装就可以了。
2.Fiddler工具的使用
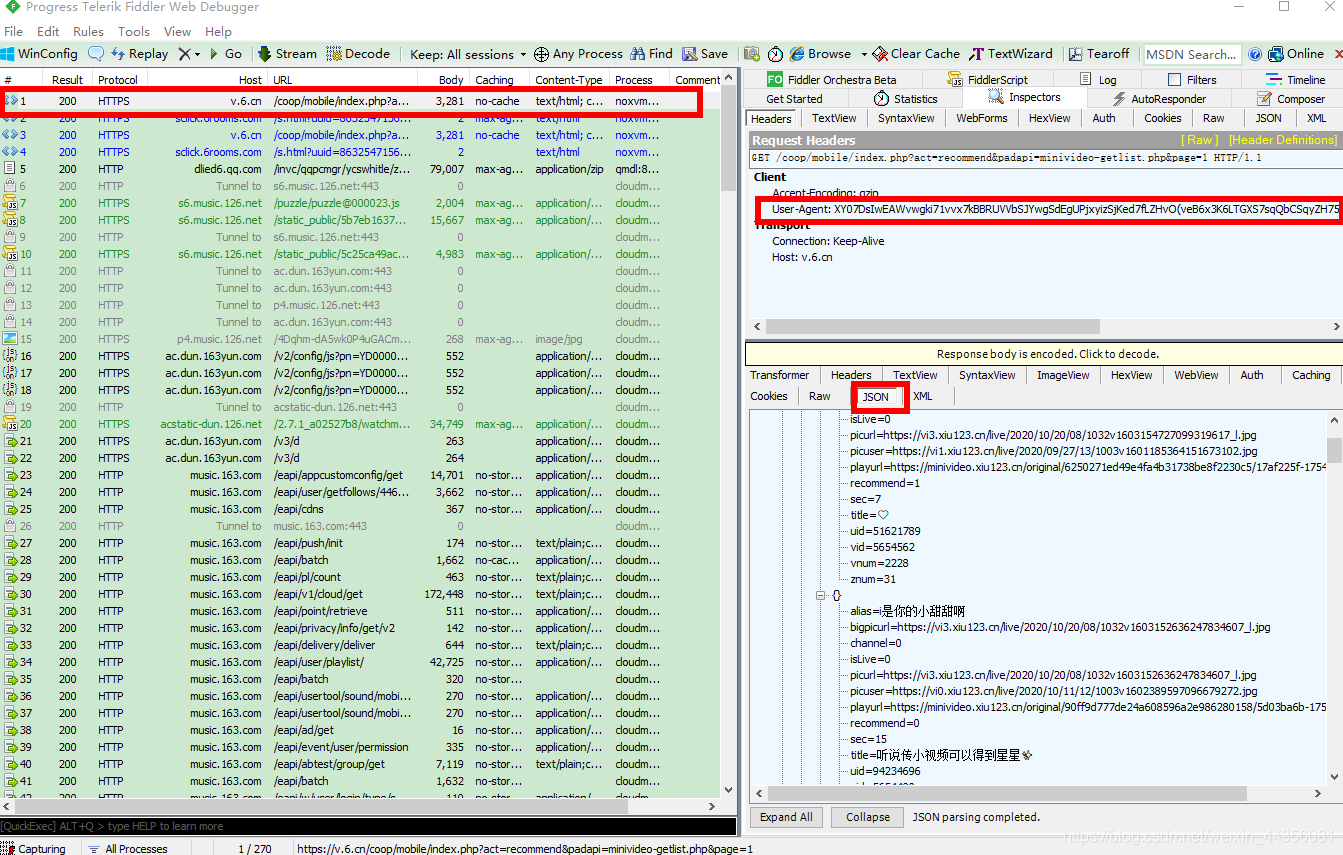
(1)首先,Fiddler工具分为四块:显示所抓的包、请求区、响应区和语句输入区
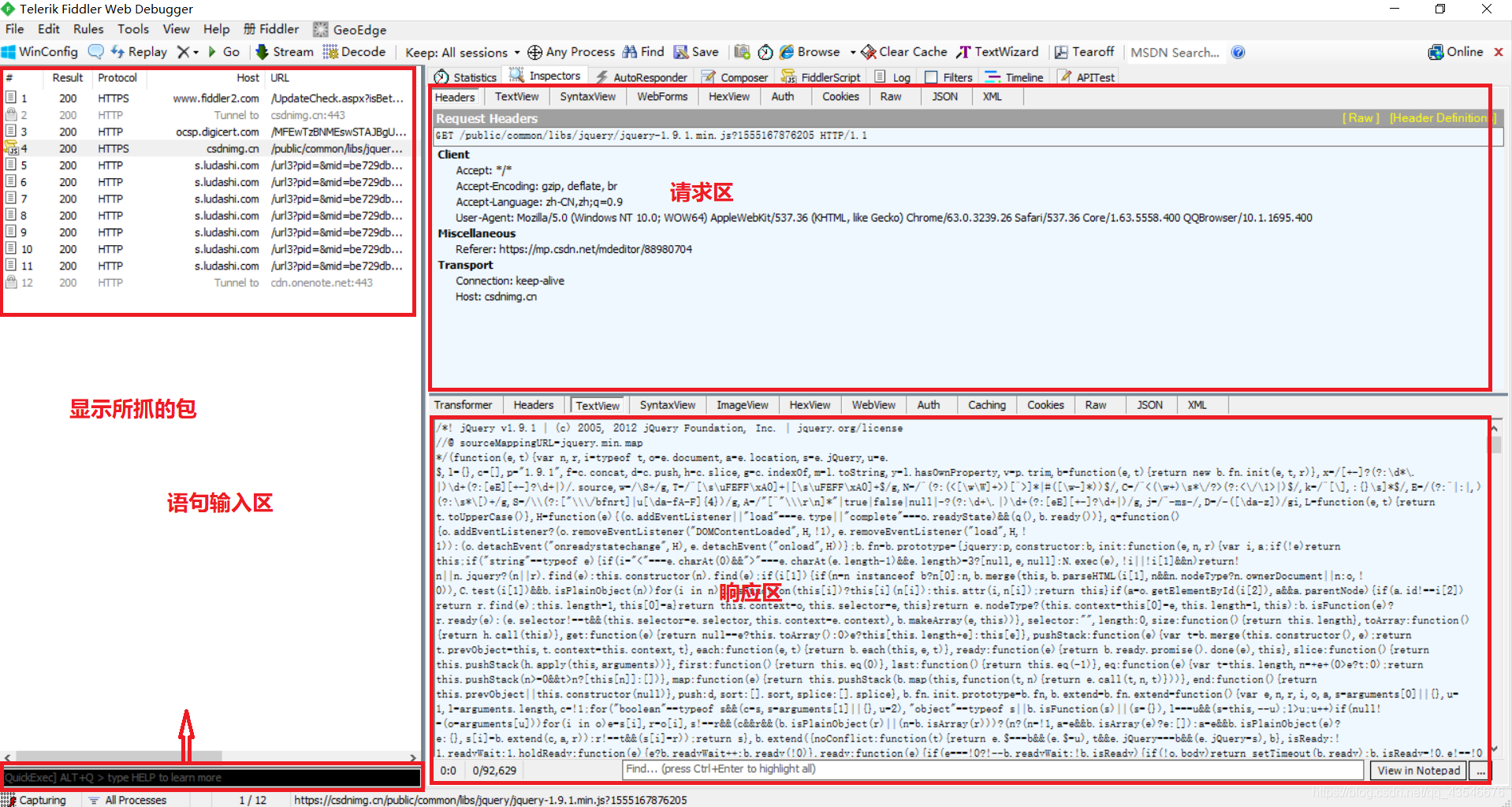
(2)有的js包需要手动点击一下,才能解析出来:

(3)一般,我们抓包分析都是点击响应区中的TextView,再观察。
二、爬取腾讯视频某视频所有评论
1.思路分析
这里我想爬取斗罗大陆的所有评论。
(1)进入到斗罗大陆动画片的评论区:
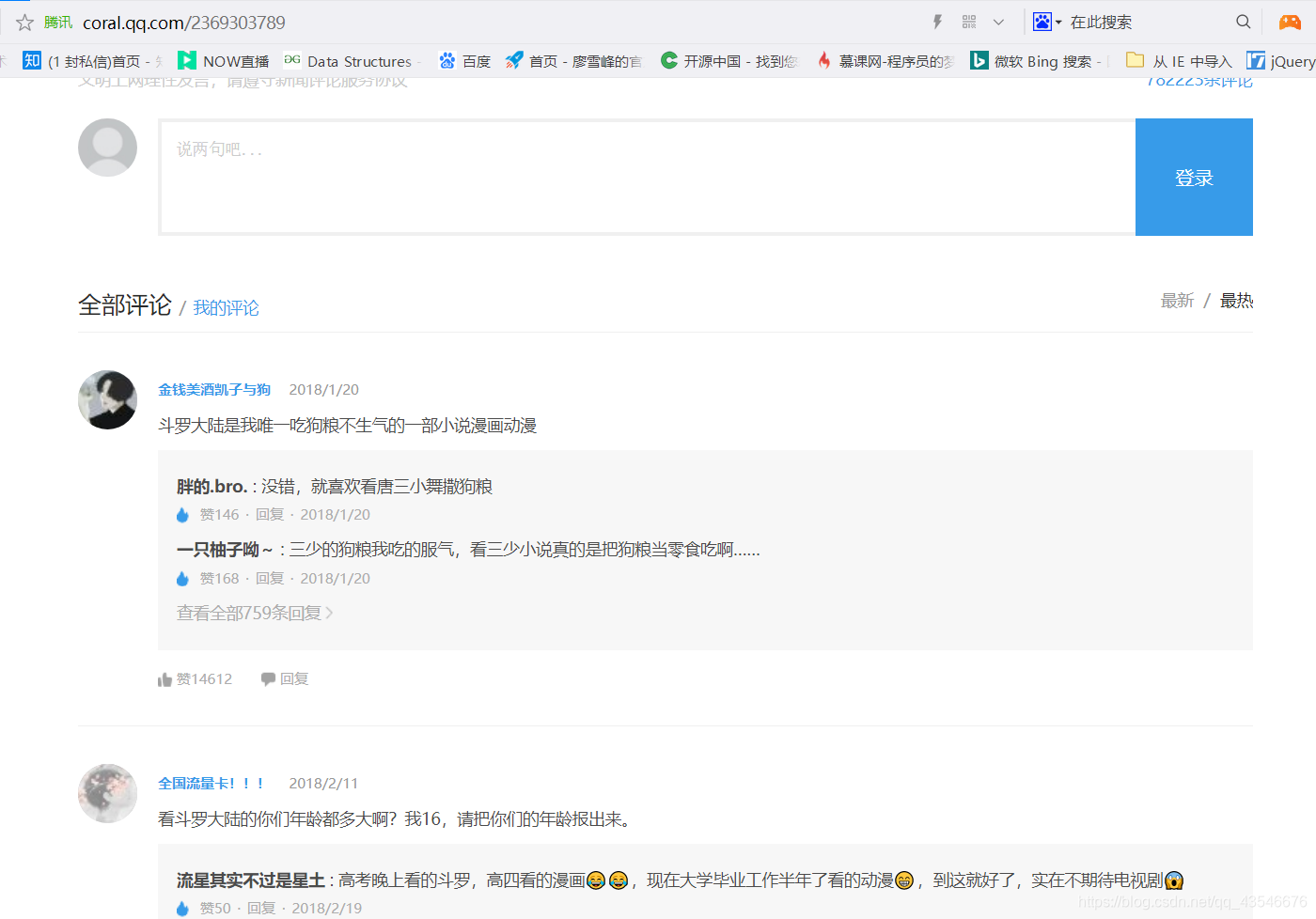
(2)打开Fiddler,然后,刷新页面,找到存放评论信息的js包:


(3)因为评论是手动点击加载更多触发的,所有,我们多加载几个:
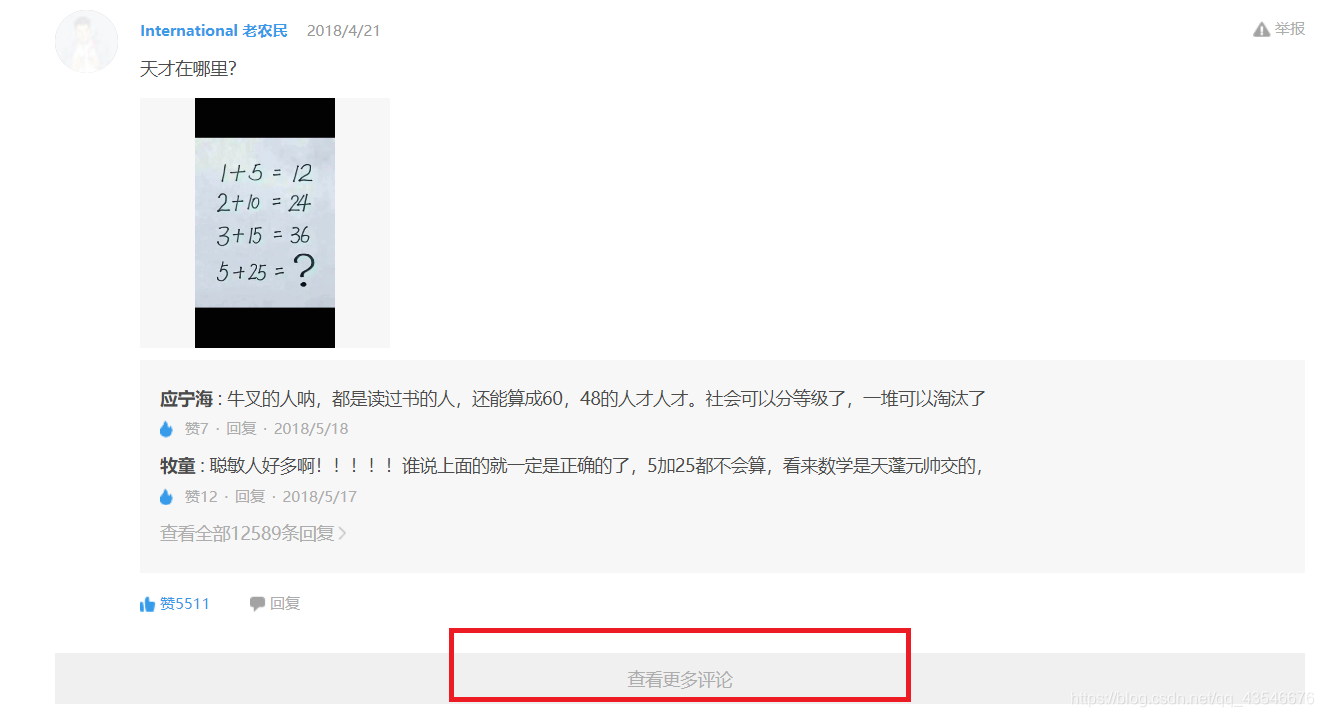
(4)观察网址结构,得出结论:

(5)下一个提取id我发现每次都可以在上一个js包中找到,这些js包像一个链表一样,是链式链接的。下面的图片是我在第一个js包中搜索第二个js包的id的例子:
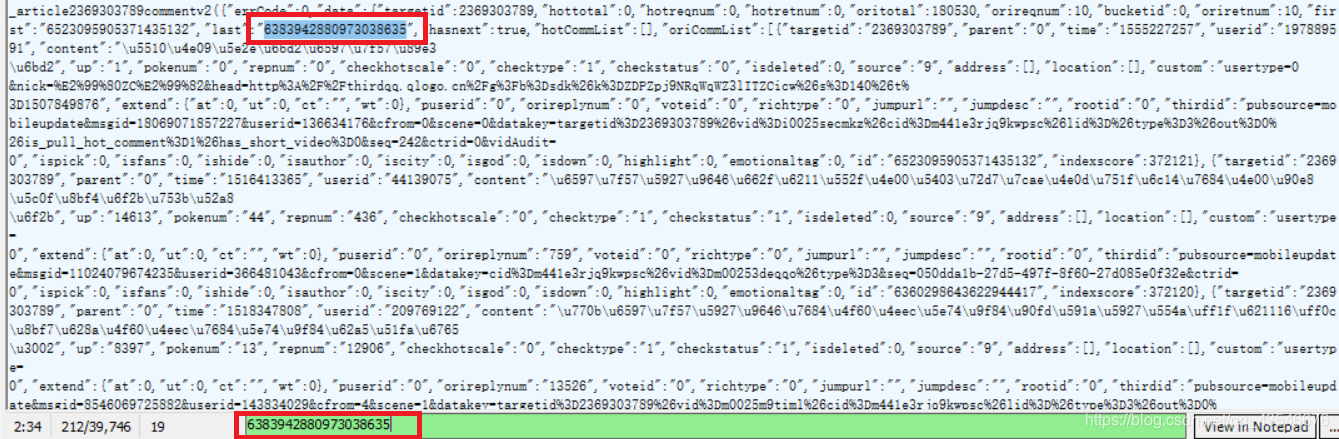
这样,我们就能找到所有的js包,从而爬取所有的评论。
2.具体代码
#提取10次,每次提取10个
import urllib.request,time
import urllib.error
import random,re'''
作用:该模块为爬虫设置用户和ip代理
参数:thisUrl是要爬取的网址ip_pool是ip代理池
返回值:返回爬取网页信息的二进制数据
'''
def ua_ip(thisUrl, ip_pool):#构建用户代理池ua_pool = ['Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5558.400 QQBrowser/10.1.1695.400','User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)','Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36','Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)","Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)","Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)","Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0","Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5","Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20","Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1","Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5","Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre","Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11","Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"]thisUA = random.choice(ua_pool) #从用户代理池中随机选择一个用户代理thisIP = random.choice(ip_pool) #从ip代理池中随机选择一个ip代理print("用户代理:{}".format(thisUA))print("ip代理:{}".format(thisIP))#将IP代理格式化proxy = urllib.request.ProxyHandler({'http': thisIP})#安装IP代理,并构建开启工具opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)#构造报头headers = ('user-agent', thisUA)#安装报头opener.addheaders = [headers]#将opener设置为全局urllib.request.install_opener(opener)#以二进制形式爬取信息respense = urllib.request.urlopen(thisUrl)data = respense.read()respense.close() #避免持续链接导致被发现是爬虫return datadef main():ip_pool = ['127.0.0.1:8888']v_id = '2369303789' #要爬取的视频的id,这里我爬取的是斗罗大陆的c_id = '0' #第一次评论的idnum = '10' #每一页提取的评论数数目n = 1 #用来记录获取的评论总数fp = open('D:\\python\\new.txt', 'a+')for i in range(0, 10):try:# 网址格式:http://coral.qq.com/article/【视频id】/comment/v2?callback=_article2369303789commentv2&orinum=【一次提取的评论数目】&oriorder=o&pageflag=1&cursor=【下一个视频id】url = 'http://coral.qq.com/article/'+ v_id +'/comment/v2?callback=_article2369303789commentv2&orinum='+ num +'&oriorder=o&pageflag=1&cursor='+c_id#对获取的二进制数进行解码data = ua_ip(url, ip_pool).decode('utf-8', 'ignore')#构造获取下一页评论ip的正则表达式pat1 = '"last":"(.*?)"'c_ids = re.compile(pat1).findall(data)c_id = c_ids[0] #c_ids是一个列表,获取他的第一个元素就是下一页评论id#构造获取评论内容的正则表达式pat2 = '"content":"(.*?)"'comment_list = re.compile(pat2).findall(data)for comment in comment_list:thisdata = "第"+str(n)+"个评论为:" + eval('u"' + comment + '"')print(thisdata)fp.write(thisdata + '\n')n += 1except urllib.error.HTTPError as e:if hasattr(e, 'code'):print(e.code)if hasattr(e, 'reason'):print(e.reason)except Exception as err:print(err)time.sleep(2) # 每爬取一页,停顿2秒,减少频率,从而减少被发现的几率fp.close()if __name__ == '__main__': main()
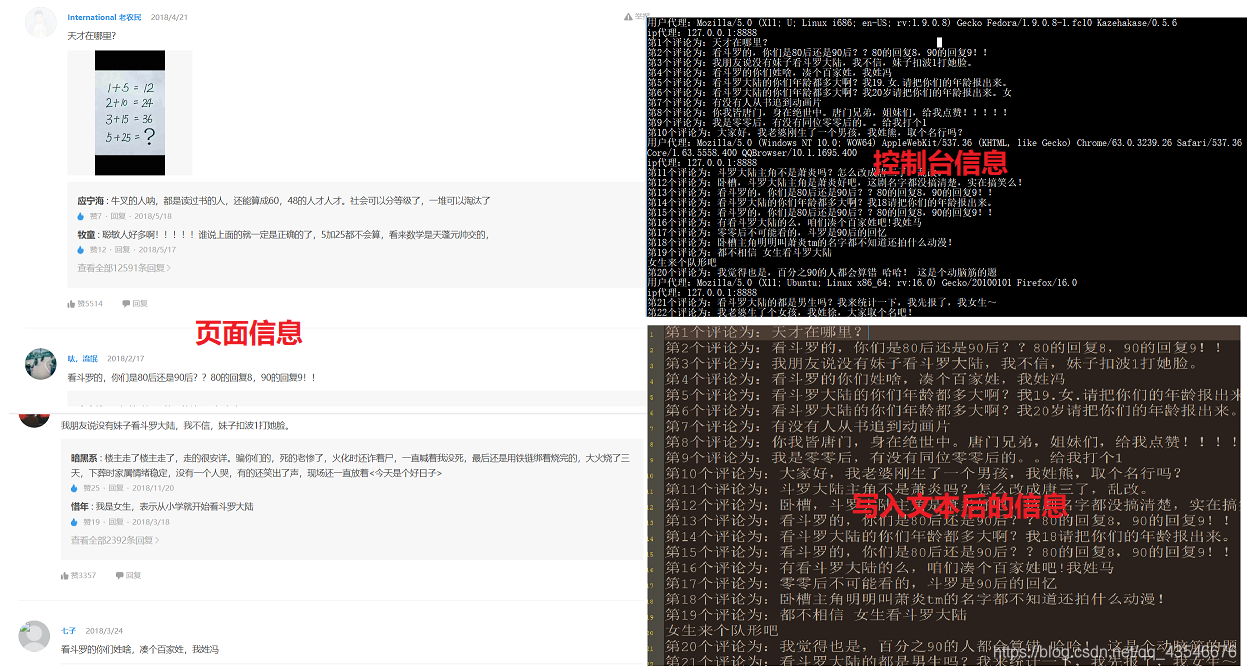
3.结果展示