目录
前言
LangChain介绍
为什么选择LangChain
LangChain的结构
代理
SQL Database Agent
数据库模式和资源
导入必要的库
连接到数据库:
设置 LLM、工具包和代理执行器:
使用自然语言查询数据库:
完整代码示例:
结论
前言
在LLM模型还没有特别成熟,像现在这样火爆之前,我们对于数据库的传统理解方式依然还是建立在需要先去学习如如何使用SQL脚本来跟Database进行交互。这将需要花费你大量的时间和精力,而且随着时代的发展,数据库版本的升级迭代和新型的数据库产品的诞生,我们都需要快速的去适应。
前几年随着云计算的火热,为了适应市场的需求,我们的产品需要去适配各大主流云厂商的DB产品;2022年开始在信创领域,也开始陆续推进国产数据库的适配(如达梦、人大金仓、TBase、OceanBase、GaussDB、TiDB),毫无疑问,为了跟上技术发展的浪潮,只能被迫继续推进国产数据库的适配,毫不夸张的讲,最多的时候我们一个产品可能需要适配上十种不同的DB产品,而各家的产品虽然宣传都号称完全兼容标准SQL、MySQL和Oracle的语法,实际上在改造适配过程中依然会经历无数次爬坑的过程,而且在面临性能方面的问题一度会陷入绝望。同时,每适配一款DB你还得努力去啃一堆文档,经历漫长的改造和测试阶段,所消耗的研发成本可想而知。
那么,有没有更好的办法去适应和改变这种现状呢,答案是肯定的,随着自然语言处理技术的新突破,一大波优秀的LLM涌现出来,如BERT、GPT-3/4等。我们完全可以使用自然语言来跟数据库交流,不需要去从头开始学习一堆数据库产品的语法,就像你身边多了一个智能助理来帮助你讲你的文本需求转换为高质量的SQL脚本或者数据库指令。
从而实现自然语言查询数据库的功能。
自然语言查询允许用户更直观、更高效地与数据库进行交互。通过利用LangChain,SQL Agents和OpenAI的大型语言模型(LLM)(如ChatGPT)的强大功能,我们可以创建应用程序,使用户能够使用自然语言查询数据库。今天,我们就来看看如何用LangChain实现用自然语言和你的数据库说话。
LangChain介绍
LangChain是一个开源的项目,它可以让你用自然语言和你的数据库聊天。它支持多种数据库,如MySQL,PostgreSQL,MongoDB等。它也支持多种语言,如英语,中文,日语等。它使用了最先进的自然语言处理技术,如BERT,GPT-3等,来理解你的问题,并生成合适的SQL语句或数据库命令。它还可以根据你的数据生成可视化图表,让你更直观地分析你的数据。
LangChain 目前提供了SQL Chain(SqlDatabaseChain)和SQL Agent(SqlAgent)的方式来实现与存储在数据库中的数据进行交互。
在这篇文章中,我将向你介绍LangChain的基本概念和功能,以及如何用它实现自然语言查询数据库的神奇功能。
为什么选择LangChain
LangChain是一个对开发者很重要的工具,它可以让使用LLM构建复杂应用变得更容易。它可以让用户把LLM连接到其他数据源。通过把LLM连接到其他数据源,应用可以处理更广泛的信息。这使得应用更强大和多样化。
LangChain还提供了以下特点:
灵活性:LangChain是一个高度灵活和可扩展的框架,它允许用户轻松地更换组件和定制链条,以满足不同的需求。
速度:LangChain的开发团队不断地提升库的速度,确保用户能够使用最新的LLM功能。
社区:LangChain有一个强大而活跃的社区,用户可以在那里寻求必要的帮助。
LangChain的结构
这个框架由七个模块组成。每个模块可以让你管理和LLM交互的不同方面。

-
LLM LLM是LangChain的基础组件。它是一个对大型语言模型的封装,可以让用户利用模型的功能和能力。
-
链条 有时候,要解决任务,单独调用一个LLM的API是不够的。这个模块可以让你集成其他工具。例如,你可能需要从一个特定的URL获取数据,对返回的文本进行摘要,然后用生成的摘要来回答问题。这个模块可以让你把多个工具连接起来,以解决复杂的任务。
-
提示 提示是任何自然语言处理应用的核心。它是用户和模型交互的方式,试图从模型那里得到一个输出。知道如何写一个有效的提示是很重要的。LangChain提供了提示模板,可以让用户格式化输入和其他工具。
-
文档加载器和工具 LangChain的文档加载器和工具模块可以帮助你连接到数据源和计算。工具模块提供了Bash和Python解释器会话等。这些适合于那些需要直接和底层系统交互或者需要用代码片段来计算一个特定的数学量或者解决一个问题,而不是一次性地计算答案的应用。
-
代理 一个代理是一个做出决定,采取行动,并观察所做的事情,并继续这个循环直到任务完成的LLM。LangChain库提供了可以根据输入沿途采取行动,而不是一个硬编码的确定性序列的代理。
-
索引 最好的模型通常是那些和你的一些文本数据结合在一起的模型,以便添加上下文或向模型解释一些东西。这个模块可以帮助我们做到这一点。
-
内存 这个模块可以让用户在模型的调用之间创建一个持久化的状态。能够使用一个记住过去说过什么的模型会提高我们的应用。
代理
SQL Database Agent: SQL数据库代理是专门用来和SQL数据库交互的,可以让用户用自然语言提问,并得到答案。下面是如何实
pip install langchain openai pymysql --upgrade -q
导入必要的库
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
os.environ['OPENAI_API_KEY'] = "your_openai_api_key"
os.environ["SERPAPI_API_KEY"] = "your_serpapi_api_key"
这里需要使用你自己的OPENAIAPIKEY和SERPAPIAPIKEY,其中SERPAPIAPIKEY为Google Search API,可以从这里注册获取,100次免费查询。

llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION)
agent.run(" OpenAI的老板是谁,他的年龄的0.5次方是多少?")
输出:
6.164414002968976
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run(" OpenAI的老板是谁,他的年龄的0.5次方是多少?")输出:
> Entering new AgentExecutor chain...I need to find out who the CEO of OpenAI is and then calculate their age to the power of 0.5.
Action: Search
Action Input: "OpenAI CEO"
Observation: Sam Altman, the CEO of ChatGPT maker OpenAI, used a high-profile trip to South Korea on Friday to call for coordinated international ...
Thought: I need to find out the age of the CEO
Action: Search
Action Input: "Sam Altman age"
Observation: 38 years
Thought: I now know the age of the CEO and need to calculate it to the power of 0.5
Action: Calculator
Action Input: 38^0.5
Observation: Answer: 6.164414002968976
Thought: I now know the final answer
Final Answer: 6.164414002968976> Finished chain.
'
6.164414002968976SQL Database Agent
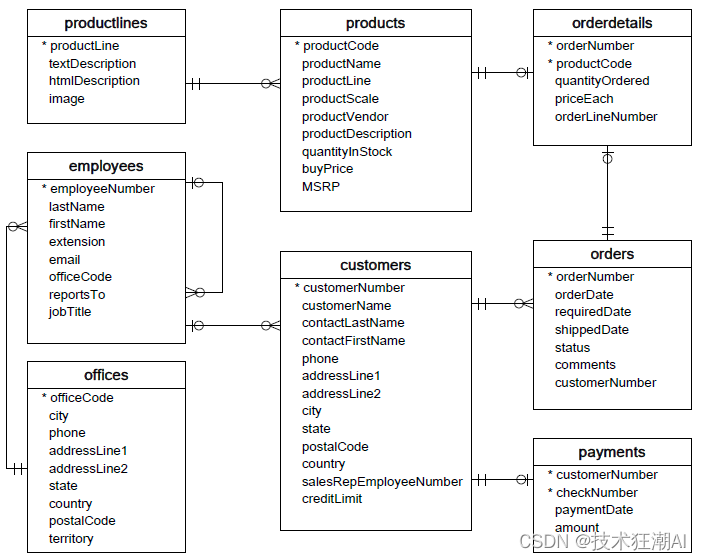
数据库模式和资源
本文使用了一个特定的数据库模式来进行演示。这个模式包括了与订单、产品、客户等相关的表。为了帮助你跟随例子并探索数据库模式,这里提供了一个到模式和资源的链接。在此处访问数据库模式。
SQL数据库代理是用来与SQL数据库交互的,允许用户用自然语言提问并得到答案。下面来介绍如何实现它:
导入必要的库
import os
from langchain.agents import *
from langchain.llms import OpenAI
from langchain.sql_database import SQLDatabase
连接到数据库:
codedb_user = "db_user"
db_password = "db_password"
db_host = "db_host"
db_name = "db_name"
db = SQLDatabase.from_uri(f"mysql+pymysql://{db_user}:{db_password}@{db_host}/{db_name}")
设置 LLM、工具包和代理执行器:
codefrom langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo")toolkit = SQLDatabaseToolkit(db=db)
agent_executor = create_sql_agent(llm=llm,toolkit=toolkit,verbose=True
)
使用自然语言查询数据库:
1)、描述一个表及其关系:
agent_executor.run("描述与订单相关的表及其关系")
2)、从错误中恢复:
agent_executor.run("描述PurchaseDetails表")
3)、找出总销售收入最高的前5个产品:
agent_executor.run("找出总销售收入最高的前5个产品")
输出:
> Entering new AgentExecutor chain...
Action: list_tables_sql_db
Action Input: ""
Observation: customers, employees, payments, products, productlines, orderdetails, offices, orders
Thought:我应该查询'products'和'orderdetails'表来得到每个产品的总销售收入
Action: query_checker_sql_db
Action Input: SELECT products.productName, SUM(orderdetails.quantityOrdered * orderdetails.priceEach) AS totalRevenue FROM products INNER JOIN orderdetails ON products.productCode = orderdetails.productCode GROUP BY products.productName ORDER BY totalRevenue DESC LIMIT 5;
Observation: SELECT products.productName, SUM(orderdetails.quantityOrdered * orderdetails.priceEach) AS totalRevenue
FROM products
INNER JOIN orderdetails
ON products.productCode = orderdetails.productCode
GROUP BY products.productName
ORDER BY totalRevenue DESC
LIMIT 5;
Thought:这个查询看起来是正确的,我应该执行它来得到总销售收入最高的前5个产品。
Action: query_sql_db
Action Input: SELECT products.productName, SUM(orderdetails.quantityOrdered * orderdetails.priceEach) AS totalRevenue FROM products INNER JOIN orderdetails ON products.productCode = orderdetails.productCode GROUP BY products.productName ORDER BY totalRevenue DESC LIMIT 5;
Observation: [('1992 Ferrari 360 Spider red', Decimal('276839.98')), ('2001 Ferrari Enzo', Decimal('190755.86')), ('1952 Alpine Renault 1300', Decimal('190017.96')), ('2003 Harley-Davidson Eagle Drag Bike', Decimal('170686.00')), ('1968 Ford Mustang', Decimal('161531.48'))]
Thought:我可以看到总销售收入最高的前5个产品是:1992 Ferrari 360 Spider red,2001 Ferrari Enzo,1952 Alpine Renault 1300,2003 Harley-Davidson Eagle Drag Bike,和1968 Ford Mustang。
Final Answer: 总销售收入最高的前5个产品是1992 Ferrari 360 Spider red,2001 Ferrari Enzo,1952 Alpine Renault 1300,2003 Harley-Davidson Eagle Drag Bike,和1968 Ford Mustang。> 链结束。
总销售收入最高的前5个产品是1992 Ferrari 360 Spider red,2001 Ferrari Enzo,1952 Alpine Renault 1300,2003 Harley-Davidson Eagle Drag Bike,和1968 Ford Mustang。
4)、列出订单数量最多的前3个国家:
agent_executor.run("列出订单数量最多的前3个国家")
完整代码示例:
Colab Notebook (Full Code):
https://github.com/Crossme0809/langchain-tutorials/blob/main/LangchainAgentsSQLDatabaseAgent.ipynb
结论
在本文中,我们探索了LangChain、SQL Agents和OpenAI LLMs在自然语言数据库查询方面的能力。通过结合这些技术,我们可以创建强大的应用程序,让用户用自然语言与数据库交互,使数据检索更加高效和直观。随着这些技术的不断发展,我们可以期待未来更加先进和多样化的自然语言数据库查询应用程序。
如果你对这篇文章感兴趣,而且你想要学习更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。立即获取:
- 「ChatGPT超全资料汇总|总有一款是你需要的」
- 「最完整的ChatGPT提示工程(含PPT|Xmind|视频|代码)」
- 「最强ChatGPT工具集合|超1200+工具,58个分类」
您将找到丰富的资源和工具,帮助您深入了解和应用ChatGPT。