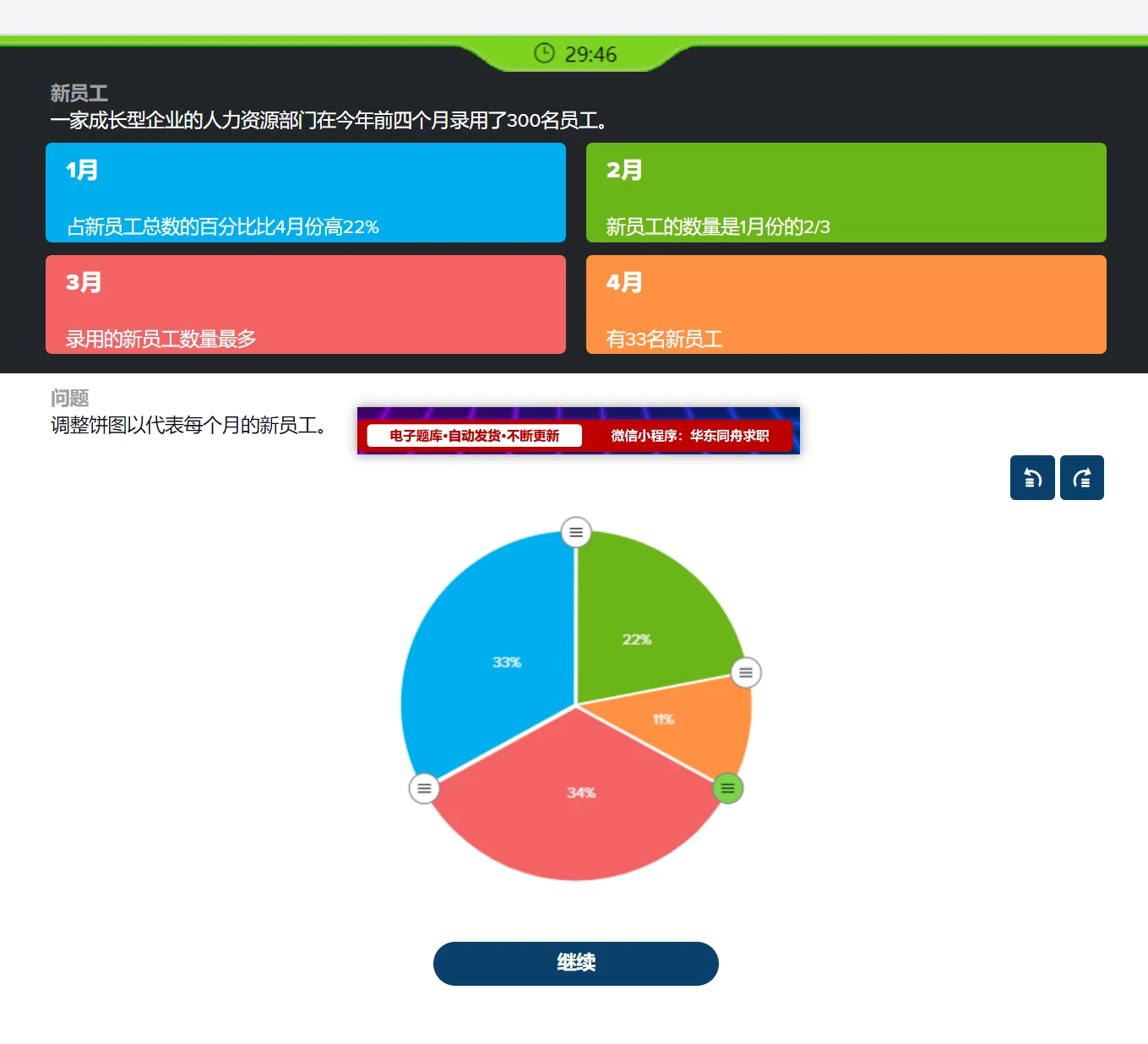
CUDA 实战 5.3.3 基于共享内存的位图:突出了同步操作的重要性
__synthreads() 才能保证图像的正确输出,如果去掉同步操作,输出图像如下:

加上同步操作之后:

#include "cpu_bitmap.h"
#include "cpu_anim.h"
#include "cuda_runtime.h"
#include <device_launch_parameters.h>
#include <device_functions.h>#define IMAGESIZE 1024
#define BLOCK_DIM 16
#define PI 3.141592653__global__ void generateBitmap(unsigned char * ptr)
{int x = threadIdx.x + blockIdx.x * blockDim.x;int y = threadIdx.y + blockIdx.y * blockDim.y;int offset = x + y * blockDim.x * gridDim.x;__shared__ float shared[BLOCK_DIM][BLOCK_DIM];const float period = 128.0f;shared[threadIdx.x][threadIdx.y] = 255 * (sinf(x * 2.0f * PI / period) + 1.0f) \* (sinf(y * 2.0f * PI / period) + 1.0f) / 4.0f;__syncthreads();ptr[offset * 4 + 0] = 0;ptr[offset * 4 + 1] = shared[BLOCK_DIM - 1 - threadIdx.x][BLOCK_DIM - 1 - threadIdx.y];ptr[offset * 4 + 2] = 0;ptr[offset * 4 + 3] = 255;
}int main(void)
{CPUBitmap bitmap(IMAGESIZE, IMAGESIZE);unsigned char* dev_bitmap;cudaMalloc((void**)&dev_bitmap, bitmap.image_size());dim3 grids(IMAGESIZE / BLOCK_DIM, IMAGESIZE / BLOCK_DIM);dim3 threads(BLOCK_DIM, BLOCK_DIM);generateBitmap <<<grids, threads >>> (dev_bitmap);cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost);bitmap.display_and_exit();cudaFree(dev_bitmap);return 0;
}