
什么是无头浏览器测试?
无头浏览器测试通常指没有头的物体或东西,在浏览器的语境中,它指的是没有 UI 的浏览器模拟。无头浏览器自动化使用 Web 浏览器进行端到端测试,而无需加载浏览器的 UI。
- 无头模式是一个功能,它允许执行浏览器的完整版本,同时以编程方式控制它。
- 它们通过命令行界面或使用网络通信执行。这意味着它可以在没有图形或显示的服务器上使用,并且 Selenium 测试仍然可以运行!
- 当网页没有在屏幕上渲染,并且测试在没有 UI 交互的情况下执行时,执行速度比实际浏览器自动化更快。
Puppeteer 的功能
Puppeteer 的一些主要功能包括:
- 无头浏览: Puppeteer 可以控制 Chrome 或 Chromium 的无头版本,这意味着浏览器可以在没有图形用户界面 (GUI) 的情况下运行。这使它能够高效地执行后台任务和自动化。
- 自动化任务: Puppeteer 允许您模拟用户交互,例如浏览页面、点击按钮、填写表单等。它还可以自动访问网页并提取数据,适合数据收集和分析。
- 页面操作: 您可以通过注入 JavaScript 代码、更改样式和操作 DOM(文档对象模型)来修改网页内容。
- 屏幕截图和 PDF 生成: Puppeteer 可以截取屏幕截图或将网页导出为 PDF 格式。这对于创建视觉报告和文档非常有用。
- 网络监控: Puppeteer 可以拦截和修改网络请求和响应,用于调试或测试不同的网络场景。
- 性能分析: 获取页面加载时间和资源使用量等性能指标,以帮助优化网页性能。
- 网页抓取: Puppeteer 通常用于网页抓取任务,因为它可以像真实用户一样与网站交互,从而从动态和 JavaScript 繁重的页面中提取数据。
- 测试: Puppeteer 通常用于自动化 Web 应用程序的端到端测试。它可以模拟用户行为和交互,以确保您的 Web 应用程序按预期运行。
- 无头和有头模式: 它可以在无头模式下运行,也可以在有头模式下调试,这对开发和测试很方便。
Puppeteer 中的“无头”是什么意思?
Puppeteer 是一个 Node.js 库,用于控制 Chrome 或 Chromium 浏览器,主要用于自动化测试、网页抓取和生成 PDF 等任务。“无头”在 Puppeteer 中指的是可以无需用户界面运行的浏览器实例。
换句话说,浏览器在后台运行,不会显示可以与之进行视觉交互的窗口。相反,它以编程方式执行任务,并且可以通过脚本或代码进行控制。
Puppeteer 允许您控制具有可见 GUI 的常规浏览器实例和无头浏览器实例。无头模式对于网页抓取、自动化测试以及生成屏幕截图或 PDF 等任务特别有用,因为它允许以高效的方式执行这些任务,而不会显示浏览器窗口。
使用 Puppeteer 无头模式的一些好处:
- 性能: 无头模式下的浏览器通常比图形浏览器运行速度更快,因为它们不必渲染和显示网页的视觉元素。
- 资源效率: 由于没有显示图形用户界面,因此无头浏览器比运行带有 GUI 的完整浏览器占用更少的内存和 CPU 资源,这使得它们适合在服务器上或在 CI/CD 环境中运行。
- 后台任务: 无头浏览器非常适合无需用户交互或视觉反馈的自动化任务,例如网页抓取和自动化测试。
- 服务器端操作: 无头浏览器可以在服务器环境中使用,以在没有物理显示的情况下自动化任务。
- 自动化: 可以编写脚本以模拟用户浏览器操作,例如点击、输入、屏幕截图等,而无需人工干预。
无头浏览器对于需要与网站进行自动交互、数据提取、测试以及其他不需要视觉渲染的操作的任务特别强大。
您对网页抓取和 Browserless 有什么奇妙的想法或疑问?
让我们看看其他开发人员在 Discord 和 Telegram 上分享了什么!
如何使用 Puppeteer 和 Browserless 进行无头浏览器测试?
让我们在接下来的内容中找出答案!
使用 Browserless 在 Puppeteer 中运行无头测试
初始化环境
在测试之前,我们需要有一个 Browserless 服务。Browserless 可以帮助我们解决复杂的 Web 抓取和大型自动化任务。借助完全托管的成果的云部署,Browserless 具有更强大的功能。
Browserless 采用以浏览器为中心的策略,提供强大的无头部署能力,并提供更高的性能和可靠性。请阅读文档教程了解有关 Browserless 服务配置的更多信息。
- 我们需要首先获取 Nstbrowser 的 API KEY。您可以访问 Nstbrowser 客户端的 Browserless 菜单页面:
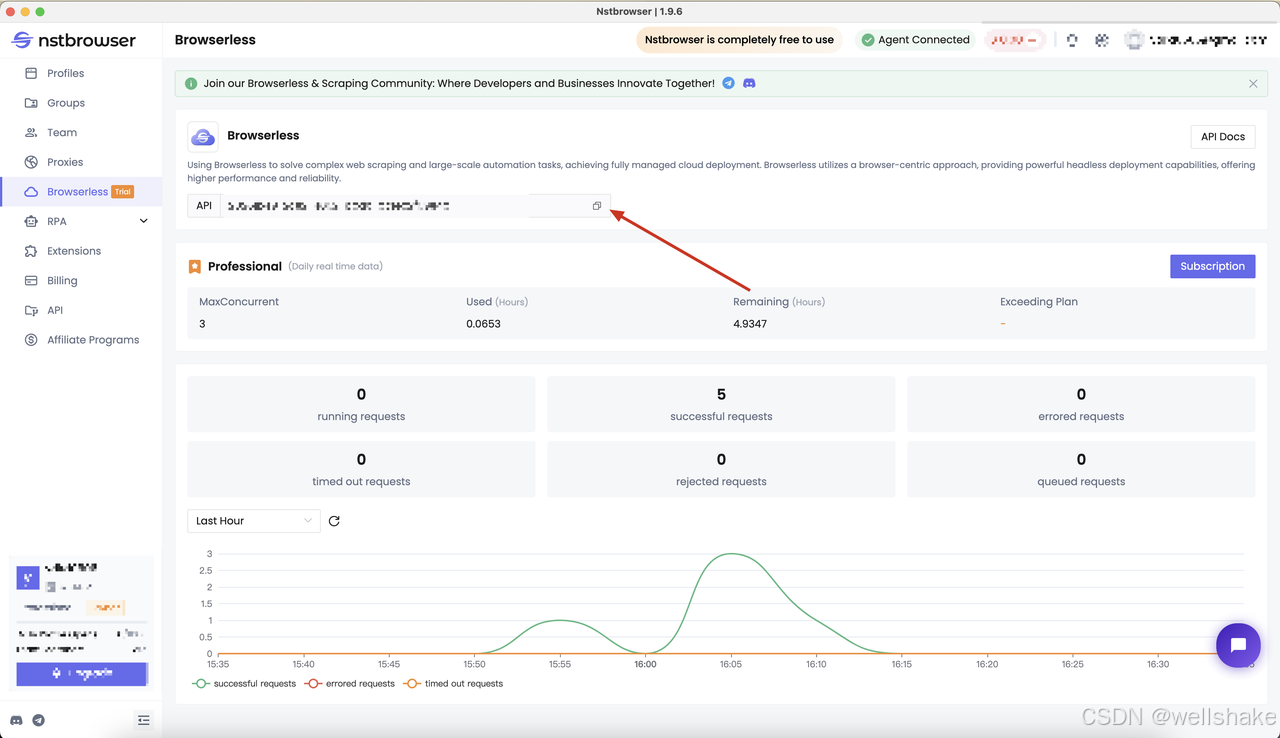
确定测试用例目标
完成环境初始化后,我们需要进一步确定测试目标。
我们将只学习一个使用 Puppeteer 与 Browserless 的示例,而没有特定的网页。请根据您的目标网站和要求指定样本。
这里,让我们使用 Puppeteer 获取页面的标题并创建屏幕截图。之后,我们将把它与 Jest 结合起来编写测试用例。
以下是我们主要的测试内容:
- 页面的标题是否为目标标题
- 屏幕截图是否包含目标元素
项目初始化
接下来,请按照以下步骤安装 Puppeteer 并运行测试脚本:
步骤 1: 在 Vs code 中创建一个新文件夹
步骤 2: 打开 Vs code 终端并运行以下命令以安装相关依赖项
npm init -y
pnpm add jest jest-html-reporter puppeteer-core步骤 3: 完成相关文件
1. 创建 jest.config.js 配置文件以执行相关配置:
module.exports = {testTimeout: 10000, // 10 秒reporters: ['default',['jest-html-reporter',{pageTitle: 'Test Report',outputPath: './test-report.html',includeFailureMsg: true,includeConsoleLog: true,},],],
};2. 创建 __tests__/puppeteer.spec.js 测试脚本
要启动浏览器,您需要传入相关的配置(有关完整配置,请参考 LaunchNewBrowser)
const puppeteer = require('puppeteer-core');describe('My First Puppeteer Test', () => {it('should load the page and check the title', async () => {const browserWSEndpoint = await launchAndConnectToBrowser();const browser = await puppeteer.connect({browserWSEndpoint: browserWSEndpoint,defaultViewport: null,});const page = await browser.newPage();await page.goto('https://example.com');const title = await page.title();expect(title).toBe('Example Domain');await browser.close();});// 拍摄页面的屏幕截图it('should take a screenshot of the page', async () => {const browserWSEndpoint = await launchAndConnectToBrowser();const browser = await puppeteer.connect({browserWSEndpoint: browserWSEndpoint,defaultViewport: null,});const page = await browser.newPage();await page.goto('https://example.com');await page.screenshot({ path: 'example.png' });await browser.close();});
});async function launchAndConnectToBrowser() {const token = ''; // 您从 nstbrowser 获取的 api tokenconst config = {proxy:'', // 必需;输入格式:schema://user:password@host:port 例如:http://user:password@localhost:8080// platform: 'windows', // 支持:windows、mac、linux// kernel: 'chromium', // 只支持:chromium// kernelMilestone: '128', // 支持:128// args: {// "--proxy-bypass-list": "detect.nstbrowser.io"// }, // 浏览器参数// fingerprint: {// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent 支持从 v0.15.0 开始// },};const query = new URLSearchParams({token: token, // 必需config: JSON.stringify(config),});const browserWSEndpoint = `ws://less.nstbrowser.io/connect?${query.toString()}`;return browserWSEndpoint;
}运行项目
现在我们只需要打开控制台并运行以下脚本命令:
npx jest --detectOpenHandles这里的命令可以主要分解为:
- 使用
npx命令执行 jest 命令。 - jest 将找到当前项目的
jest.config.js配置文件并获取基本配置信息。 - 根据配置文件的内容,在当前项目目录中找到匹配的测试文件并开始执行。
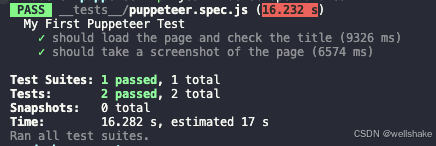
结果输出
执行上述命令后,我们将看到以下输出。这里,测试执行过程的每个重要结果都会被输出,并且它向我们展示了我们的测试用例已经通过。
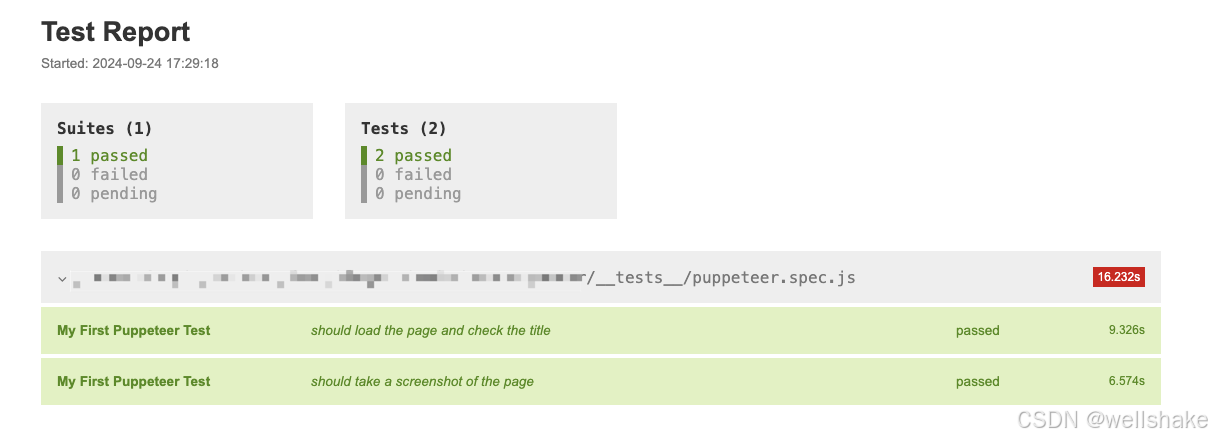
同时,我们可以打开 test-report.html 文件查看生成的具体报告:
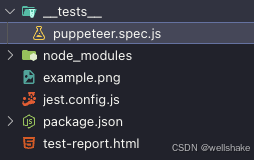
项目的文件夹结构如下。我们还可以看到输出的屏幕截图文件内容,这意味着我们的测试用例已经完全通过。
Puppeteer 无头测试的好处
- 与真实浏览器相比,无头浏览器测试速度更快,因为它消耗的系统资源更少。
- 它提高了测试执行性能,因为它通常比实际浏览器测试快 2 倍。
- 它非常适合网页抓取。假设您需要通过 Puppeteer 自动化从网页中获取大量数据(体育数据、股票数据等)并将其存储在任何 Excel 或数据库中。在这种情况下,Puppeteer 无头模式是最佳选择,因为不需要启动真实浏览器来验证 UI,主要重点是获取数据。
- 它有助于在单个系统上模拟多个浏览器,而不会造成资源开销。
- 它适合并行测试。基于 UI 的浏览器会消耗大量的内存和资源。因此,Puppeteer 无头浏览器在这里是更好的选择。
使用 Puppeteer 无头测试的 7 个最佳实践
- 管理资源使用: 由于 Puppeteer 无头模式在没有图形界面的情况下运行,因此它更快且使用更少的资源。但是,在运行多个实例时,仍然需要管理内存和 CPU 使用量。利用 Puppeteer 的内置功能,例如页面池和高效的选项卡管理,可以减少资源消耗。
- 处理超时和重试: 网页抓取或自动化任务可能会遇到网络延迟或超时。设置适当的超时值并实现重试逻辑可以确保您的脚本能够处理间歇性故障而不会崩溃。
- 明智地等待元素: 在执行操作之前,请始终等待所需的元素加载。不要使用静态延迟(例如
page.waitForTimeout),而是优先等待特定事件或元素 (page.waitForSelector),这使您的自动化更有效率,并且更能抵抗不同的加载时间。 - 使用隐身上下文进行隔离: 为了避免数据泄漏并确保每次测试或抓取都在干净的环境中运行,请使用隐身上下文 (
browser.createIncognitoBrowserContext)。这可以防止缓存数据、cookie 或本地存储影响后续会话。 - 利用无头检测绕过: 许多网站会检测无头浏览器,并且可能会阻止或向这些请求提供有限的内容。使用诸如修改浏览器标志、覆盖用户代理以及欺骗 Web 功能(例如
navigator.webdriver删除)之类的技术可以帮助绕过无头检测。 - 监控性能和日志: 使用 Puppeteer 的性能和控制台日志工具来调试和优化脚本。监控页面性能指标和处理浏览器日志可以帮助诊断瓶颈和其他问题。
- 针对可扩展性进行优化: 如果您计划在大型规模上运行 Puppeteer,请考虑使用 Docker 进行容器化、使用负载均衡器以及并行运行多个浏览器实例。这些步骤有助于确保可扩展性并在生产环境中减少停机时间。
总结
Puppeteer 无头浏览器 使一切都变得容易。在本博文中,我们旨在与您分享:
- 强大的功能
- 以及使用 Browserless 与 Puppeteer 无头模式的高效步骤






![[C++]使用纯opencv部署yolov8-cls图像分类onnx模型](https://i-blog.csdnimg.cn/direct/9baa1cb73ac048cea1cbac6fd15232e9.jpeg)











