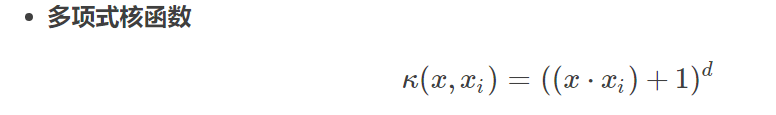【官方教程】VisualGLM技术讲解_哔哩哔哩_bilibili报告文件下载: https://pan.baidu.com/s/1gfdpyfT6EVnygMPDO_iwvQ?pwd=8wpc 提取码: 8wpcVisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于ChatGLM-6B,具有 62 亿参数;图像部分通过训练BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。, 视频播放量 6647、弹幕量 3、点赞数 267、投硬币枚数 139、收藏人数 615、转发人数 109, 视频作者 ChatGLM, 作者简介 让机器像人一样思考,相关视频:【清华NLP】刘知远团队大模型公开课全网首发|带你从入门到实战,【官方教程】ChatGLM-6B 微调:P-Tuning,LoRA,Full parameter,超强动画,一步一步深入浅出解释Transformer原理!,MiniGPT4横空出世,本地电脑直接部署运行,一出手就霸榜Github!!,【官方教程】XrayGLM微调实践,(加强后的GPT-3.5)能力媲美4.0,无次数限制。仅供技术交流。,惊出!ChatGPT4.0被开源?不仅GitHub星标38.4k!还上了Trending周榜~~,吹爆!这可能是2023最新的GPT4公开讲座了,1小时讲明白GPT4是如何工作的,以及使用GPT4打造智能程序,看完就对GPT4全面了解!人工智能|机器学习,LangChain + GLM =本地知识库,pytorch入门19 - 本地知识库LLM对话系统(langchain-ChatGLM项目)- 源码分析(1/2) https://www.bilibili.com/video/BV14L411q7fk/?spm_id_from=333.999.0.0&vd_source=4aed82e35f26bb600bc5b46e65e25c22
https://www.bilibili.com/video/BV14L411q7fk/?spm_id_from=333.999.0.0&vd_source=4aed82e35f26bb600bc5b46e65e25c22
 通过VQVAE将图像变成token
通过VQVAE将图像变成token







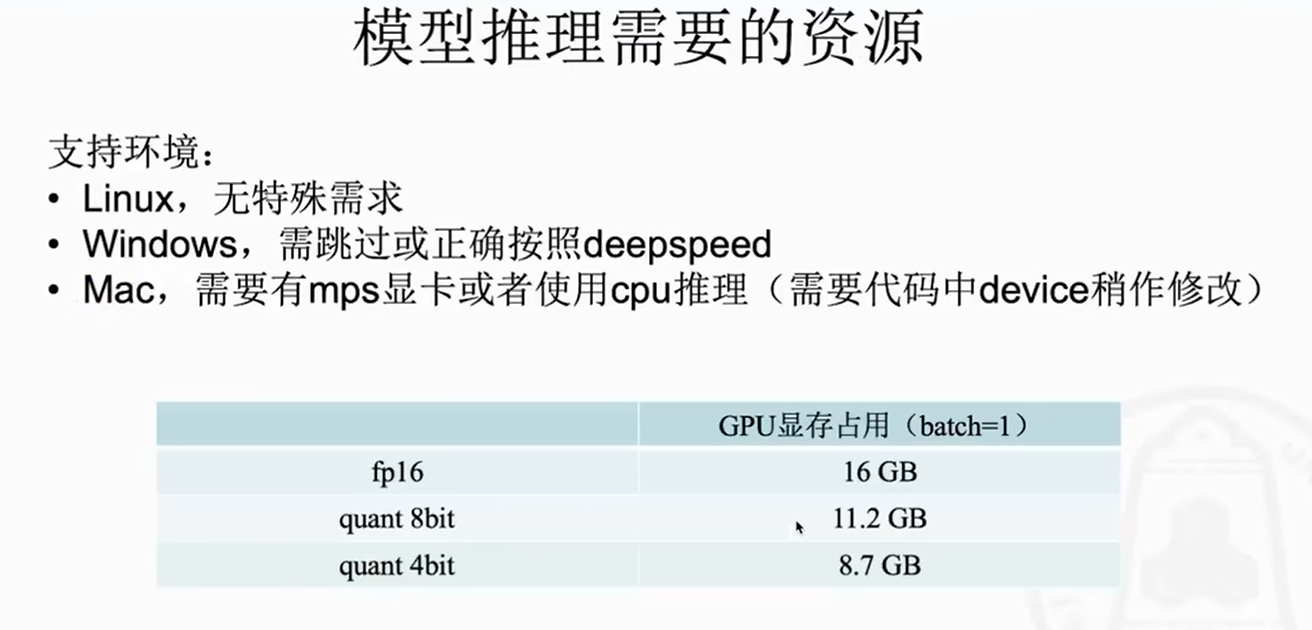 vit对量化比较敏感,text侧还可以,4bit也是针对chatglm
vit对量化比较敏感,text侧还可以,4bit也是针对chatglm


模型:
VisualGLMModel((mixins): ModuleDict((chatglm-final): ChatGLMFinalMixin((lm_head): Linear(in_features=4096, out_features=130528, bias=False))(chatglm-attn): ChatGLMAttnMixin((rotary_emb): RotaryEmbedding())(chatglm-layer): ChatGLMLayerMixin()(eva): ImageMixin((model): BLIP2((vit): EVAViT((mixins): ModuleDict((patch_embedding): ImagePatchEmbeddingMixin((proj): Conv2d(3, 1408, kernel_size=(14, 14), stride=(14, 14)))(pos_embedding): InterpolatedPositionEmbeddingMixin()(cls): LNFinalyMixin((ln_vision): LayerNorm((1408,), eps=1e-05, elementwise_affine=True)))(transformer): BaseTransformer((embedding_dropout): Dropout(p=0.1, inplace=False)(word_embeddings): VocabParallelEmbedding()(position_embeddings): Embedding(257, 1408)(layers): ModuleList((0): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(1): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(2): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(3): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(4): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(5): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(6): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(7): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(8): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(9): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(10): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(11): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(12): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(13): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(14): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(15): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(16): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(17): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(18): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(19): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(20): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(21): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(22): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(23): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(24): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(25): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(26): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(27): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(28): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(29): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(30): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(31): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(32): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(33): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(34): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(35): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(36): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(37): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(38): BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False))))))(qformer): QFormer((mixins): ModuleDict()(transformer): BaseTransformer((embedding_dropout): Dropout(p=0.1, inplace=False)(word_embeddings): VocabParallelEmbedding()(position_embeddings): None(layers): ModuleList((0): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(1): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(2): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(3): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(4): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(5): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(6): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(7): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(8): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(9): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(10): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(11): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False))))(final_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)))(glm_proj): Linear(in_features=768, out_features=4096, bias=True)))(auto-regressive): CachedAutoregressiveMixin())(transformer): BaseTransformer((embedding_dropout): Dropout(p=0, inplace=False)(word_embeddings): VocabParallelEmbedding()(position_embeddings): Embedding(2048, 4096)(layers): ModuleList((0): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(1): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(2): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(3): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(4): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(5): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(6): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(7): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(8): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(9): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(10): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(11): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(12): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(13): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(14): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(15): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(16): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(17): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(18): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(19): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(20): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(21): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(22): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(23): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(24): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(25): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(26): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False)))(27): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0, inplace=False))))(final_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True))
)
推理:
model,model_args=AutoModel.from_pretrained("visualglm")->
quantize(model.transformer,)->
prompt='<img>/root/autodl-tmp/VisualGLM-6B/examples/2.jpeg</img>'->
'<img>/root/autodl-tmp/VisualGLM-6B/examples/2.jpeg</img>问:描述这张图片。\n答:'->
image_position:5,image_path:'/root/autodl-tmp/VisualGLM-6B/examples/2.jpeg',text:'<img></img>问:描述这张图片。\n答:'->
BlipImageEvalProcessor(224)->
- transform=transforms.Compose([transforms.Resize([]),transforms.ToTensor(),self.normalize])->
image=processor(image.convert('RGB'))-> [3,224,224]
image=image.unsqueeze(0)->[1,3,224,224]
input0=tokenizer.encode(prompt[:image_position],add_special_tokens=False)->:<img>,[46,2265,33]
input1=[tokenizer.pad_token_id]*model.image_length->[3]*32
input2=tokenizer.encode(prompt[image_position:],)->'</img>问:描述这张图片。\n答:'[98, 2265, 33, 64286, 12, 67194, 74366, 65842, 63823, 4, 67342, 12]
inputs=sum([input0,input1,input2],[])->[46, 2265, 33, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 98, 2265, 33, 64286, 12, 67194, 74366, 65842, 63823, 4, 67342, 12]
inputs=torch.tensor(tokenizer.build_inputs_with_special_tokens(inputs))->
mask_position=len(inputs)-2->47
context_length=len(inputs)-1->48
get_masks_and_position_ids_glm->
seq=torch.cat([])->2048
[tokenizer.eos_token_id]:[13005],top_p:0.4,top_k:100,temerature:0.8,repetition_penalty:1.2->
output=filling_sequence(model,seq,batch_size=1,get_masks_and_position_ids,strategy,pre_image,image)->
filling_sequence=sat.generation.autoregressive_sampling.filling_sequence
== 生成初始的 tokens、attention_mask 和 position_ids
- tokens,attention_mask,position_ids=get_masks_and_position_ids(seq)->
-- tokens:,1x2048;attention_mask:1x2048x2048,attention_mask.tril_()对角线,1x1x2048x2048;
-- 2d position_ids:2x2048->1x2x2048,
-- tokens:1x2048,attention_mask:1x1x2048x2048,position_ids:1x2x2048->
- tokens=tokens[...,:context_length]:1x49->
== 初始化generation
- index:0,counter:48
== step-by-step generation
- logits,*output_per_layers=model(tokens[:,index:],position_ids=position_ids[...,index:counter+1],attention_mask=attention_mask[...,index:counter+1,:counter+1],mems,log_attention_weights)->
-- model=sat.model.official.chatglm_model.ChatGLMModel.forward
-- input_ids:1x49,position_ids:1x2x49,attention_mask:1x1x49x49->
-- super().forward(input_ids,attention_mask,position_ids,past_key_values)->
-- sat.model.base_model.BaseModel.forward()->
-- transformer.hooks.clear()->
-- transformer.hooks.update(hooks)->通过hook把qformer给整合进去了
-- transformer()->
- logits:1x49x130528,len(output_per_layers):28 output_per_layers[0]:past_key_values,mem_kv->
- mem_kv[0]:1x49x8192,len(mem_kv):28->
== sampling
- tokens,mems=strategy.forward(logits,tokens,memes)->
-- sat.generation.sampling_strategies.base_strategy.BaseStrategy.forward()->
-- logits:1x130528,tokens:1x49,mems:28x1x49x8192->
-- logits=top_k_logits(logits,top_k,top_p)->
-- sat.generation.sampling_strategies.base_strategy.top_k_logits->
-- 利用top_k,top_p来决定保留哪些token,在 top_k > 0 的情况下,该函数首先在 logits 中找到分值最大的前 k 个 token,然后将分值小于第 k 个 token 的 token 对应 logits 的值设置为一个很小的值,filter_value。这样就可以移除所有概率值小于第 k 个 token 的 token。
在 top_p > 0.0 的情况下,该函数先将 logits 进行排序,然后计算 softmax 函数,获取每个 token 及其前缀的累计概率。接着,在 cumulative_probs 大于 top_p 的位置,将 sorted_indices_to_remove 对应的项设为 True,表示要移除该位置及其之后的 token。移除时,将对应 logits 的值设置为 filter_value,从而达到移除的目的。
- 使用 logists 调用 top_k_logits 函数来移除低概率的 token,并使用 softmax 计算每个 token 的概率分布。接着,它使用 multinomial 方法基于这些概率分布从批次中进行抽样,得出下一个 token 的预测值 pred。
- probs=F.softmax(logits,dim=1)->1x130528
- pred=torch.multinoimal(prob,num_samples=1)->[51]
- tokens=torch.cat((tokens,pred.view(tokens.shape[0],1)),dim=1)
- strategy.finalize(tokens,mems)->
response=tokenizer.decode(output_list[0])->
response=process_reponse(response)->
注意这个网络和前面的图是能够联系在一起的,先使用blip2中的vit进行图像特征提取,是一个39层的transformer,再用qformer进行特征融合,是一个12层的transformer,在后面是chatglm,是一个28层的transformer。
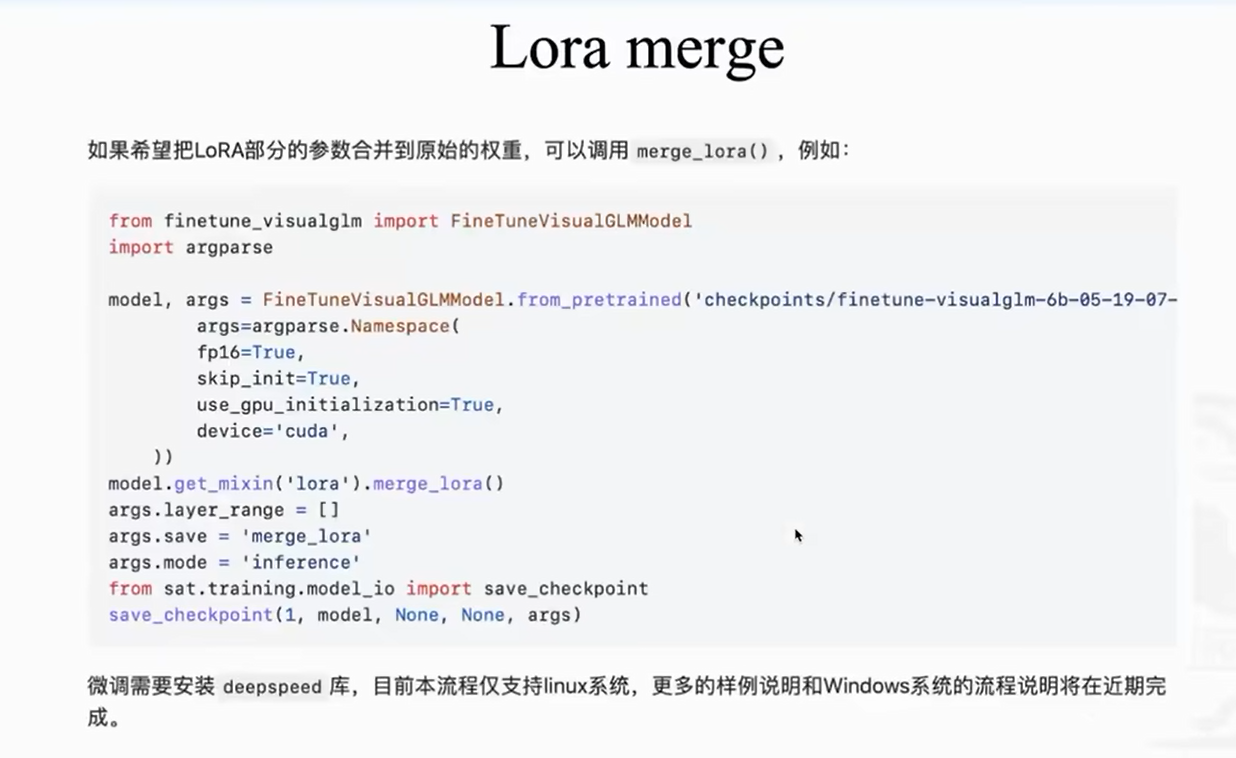
微调:


model,args=FineTuneVisualGLMModel.from_pretrained("visualglm-6b")->
tokenizer=get_tokenizer(args)->
ChatGLMTokenizer(name_or_path='/root/.cache/huggingface/hub/models--THUDM--chatglm-6b/snapshots/1d240ba371910e9282298d4592532d7f0f3e9f3e', vocab_size=130344, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<sop>', 'eos_token': '<eop>', 'unk_token': '<unk>', 'pad_token': '<pad>', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True)
training_main()->
- train_data,val_data,test_data=make_loaders(args,hooks['create_dataset_function'])->
- model,optimizer=setup_model_untrainable_params_and_optimizer(model)->
- lr_scheduler=get_learning_rate_scheduler(optimizer)->
- summary_writer=get_sampler_writer()->
- iteration,skipped=train(model,optimizer,lr_scheduler,...)->
-- lm_loss,skipped_iter,metrics=train_step(train_data_iterator,model,optimizer,lr_scheduler)->
-- forward_ret=forward_step(data_iterator,model)->
-- tokens,labels,image,pre_image=get_batch(data_iteror...)->
-- data:[input_ids,labels,image,pre_image]:4x320,4x320,4x3x224x224,3->
-- finetune_visualglm.forward_step->sat.model.official.chatglm_model.ChatGLMModel.forward->
sat.model.base_model.BaseModel.forward->sat.model.transformer.BaseTransformer.forward->
-- hidden_states = self.hooks['word_embedding_forward'](input_ids, output_cross_layer=output_cross_layer, **kw_args)-> 4x257x1408
-- position_embeddings = self.hooks['position_embedding_forward'](position_ids, output_cross_layer=output_cross_layer, **kw_args)-> 1x257x1408
-- hidden_states = hidden_states + position_embeddings ->4x257x1408
-- hidden_states = self.embedding_dropout(hidden_states)-> 4x257x1408
-- layer_ret = layer(*args, layer_id=torch.tensor(i), **kw_args, **output_cross_layer, output_this_layer=output_this_layer_obj, output_cross_layer=output_cross_layer_obj)->
-- sat.model.transformer.BaseTransformerLayer.forward->sat.transformer_defaults->
--- self = self.transformer.layers[kw_args['layer_id']] kwargs:'layer_id','image','output_this_layer','output_cross_layer'
self=BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False))
)
--- attention_input = self.input_layernorm(hidden_states):4x257x1408->
SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False)
)
--- attention_output=self.attention(attention_input,mask,**kw_args)->
--- sat.model.transformer.SelfAttention.forward->sat.transformer_defaults.attention_forward_default->
--- self = self.transformer.layers[kw_args['layer_id']].attention->
--- mixed_raw_layer = self.query_key_value(hidden_states)-> hidden_states:4x257x1408,mixed_raw_layer:4x257x4224->
--- (mixed_query_layer,mixed_key_layer,mixed_value_layer) = split_tensor_along_last_dim(mixed_raw_layer, 3):4x257x1408->
--- query_layer = self._transpose_for_scores(mixed_query_layer):4x16x257x88
key_layer = self._transpose_for_scores(mixed_key_layer)
value_layer = self._transpose_for_scores(mixed_value_layer)->
--- context_layer = attention_fn(query_layer, key_layer, value_layer, mask, dropout_fn, **kw_args):4x16x257x88->
--- output = self.dense(context_layer):context_layer/output:4x257x1408->
--- output=self.output_dropout(output)->
-- hidden_states = hidden_states + attention_output:4x257x1408->
-- mlp_input = self.post_attention_layernorm(hidden_states):4x257x1408->
-- mlp_output = self.mlp(mlp_input, **kw_args):4x257x1408->
-- output = hidden_states + mlp_output:4x257x1408->
--- decoder模式
--- encoder_outputs = kw_args['encoder_outputs']:4x257x1408->
--- attention_output = self.cross_attention(mlp_input, **kw_args)->
--- sat.model.transformer.CrossAttention.forward->sat.transformer_defaults.cross_attention_forward_default->
CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False)
)
--- hidden_states:4x32x768,corss_attention_mask:1x1,encoder_outputs:4x257x1408->
--- mixed_query_layer = self.query(hidden_states):4x32x768,图像的
--- mixed_x_layer = self.key_value(encoder_outputs):4x257x1536,text侧
--- (mixed_key_layer, mixed_value_layer) = split_tensor_along_last_dim(mixed_x_layer, 2) :4x257x768->
--- query_layer = self._transpose_for_scores(mixed_query_layer):4x12x32x64
--- key_layer = self._transpose_for_scores(mixed_key_layer)
--- value_layer = self._transpose_for_scores(mixed_value_layer)->
--- context_layer = attention_fn(query_layer, key_layer, value_layer, cross_attention_mask, dropout_fn, cross_attention=True, **kw_args):4x12x32x64->
--- output=self.dense(context_layer):context_layer/output:4x32x768->
--- output = self.output_dropout(output):4x32x768->
--- 会把self.transformer里的模块都过一篇
--- model.blip2.BLIP2.forward->
--- enc = self.vit(image) image:4x3x224x224,enc:4x257x1408 ->
EVAViT((mixins): ModuleDict((patch_embedding): ImagePatchEmbeddingMixin((proj): Conv2d(3, 1408, kernel_size=(14, 14), stride=(14, 14)))(pos_embedding): InterpolatedPositionEmbeddingMixin()(cls): LNFinalyMixin((ln_vision): LayerNorm((1408,), eps=1e-05, elementwise_affine=True)))(transformer): BaseTransformer((embedding_dropout): Dropout(p=0.1, inplace=False)(word_embeddings): VocabParallelEmbedding()(position_embeddings): Embedding(257, 1408)(layers): ModuleList((0-38): 39 x BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))))
)
--- out=self.qformer(enc)[0] out:
blip2.QFormer.forward->
---- input_ids:4x32,attention_mask:1x1,cross_attention_mask:1x1->
---- sat.model.transformer.BaseTransformer.forward->
--- self.glm_proj(out)
--- model.visualglm.ImageMixin.word_ebedding_forward->
--- 代码中确实没见到作者用blip2中的三种训练,用的仅是lm的自回归损失,也没看到对比损失。
FineTuneVisualGLMModel((mixins): ModuleDict((chatglm-final): ChatGLMFinalMixin((lm_head): Linear(in_features=4096, out_features=130528, bias=False))(chatglm-attn): ChatGLMAttnMixin((rotary_emb): RotaryEmbedding())(chatglm-layer): ChatGLMLayerMixin()(eva): ImageMixin((model): BLIP2((vit): EVAViT((mixins): ModuleDict((patch_embedding): ImagePatchEmbeddingMixin((proj): Conv2d(3, 1408, kernel_size=(14, 14), stride=(14, 14)))(pos_embedding): InterpolatedPositionEmbeddingMixin()(cls): LNFinalyMixin((ln_vision): LayerNorm((1408,), eps=1e-05, elementwise_affine=True)))(transformer): BaseTransformer((embedding_dropout): Dropout(p=0.1, inplace=False)(word_embeddings): VocabParallelEmbedding()(position_embeddings): Embedding(257, 1408)(layers): ModuleList((0-38): 39 x BaseTransformerLayer((input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False))))))(qformer): QFormer((mixins): ModuleDict()(transformer): BaseTransformer((embedding_dropout): Dropout(p=0.1, inplace=False)(word_embeddings): VocabParallelEmbedding()(position_embeddings): None(layers): ModuleList((0): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(1): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(2): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(3): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(4): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(5): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(6): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(7): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(8): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(9): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(10): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(cross_attention): CrossAttention((query): ColumnParallelLinear()(key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(11): BaseTransformerLayer((input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False))))(final_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)))(glm_proj): Linear(in_features=768, out_features=4096, bias=True)))(lora): LoraMixin())(transformer): BaseTransformer((embedding_dropout): Dropout(p=0.1, inplace=False)(word_embeddings): VocabParallelEmbedding()(position_embeddings): Embedding(2048, 4096)(layers): ModuleList((0): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): LoraLinear((original): HackColumnParallelLinear()(matrix_A): HackParameterList((0): Parameter containing: [torch.float16 of size 10x4096 (GPU 0)](1): Parameter containing: [torch.float16 of size 10x4096 (GPU 0)](2): Parameter containing: [torch.float16 of size 10x4096 (GPU 0)])(matrix_B): HackParameterList((0): Parameter containing: [torch.float16 of size 4096x10 (GPU 0)](1): Parameter containing: [torch.float16 of size 4096x10 (GPU 0)](2): Parameter containing: [torch.float16 of size 4096x10 (GPU 0)]))(attention_dropout): Dropout(p=0.1, inplace=False)(dense): LoraLinear((original): HackRowParallelLinear()(matrix_A): HackParameterList( (0): Parameter containing: [torch.float16 of size 10x4096 (GPU 0)])(matrix_B): HackParameterList( (0): Parameter containing: [torch.float16 of size 4096x10 (GPU 0)]))(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(1-13): 13 x BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(14): BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): LoraLinear((original): HackColumnParallelLinear()(matrix_A): HackParameterList((0): Parameter containing: [torch.float16 of size 10x4096 (GPU 0)](1): Parameter containing: [torch.float16 of size 10x4096 (GPU 0)](2): Parameter containing: [torch.float16 of size 10x4096 (GPU 0)])(matrix_B): HackParameterList((0): Parameter containing: [torch.float16 of size 4096x10 (GPU 0)](1): Parameter containing: [torch.float16 of size 4096x10 (GPU 0)](2): Parameter containing: [torch.float16 of size 4096x10 (GPU 0)]))(attention_dropout): Dropout(p=0.1, inplace=False)(dense): LoraLinear((original): HackRowParallelLinear()(matrix_A): HackParameterList( (0): Parameter containing: [torch.float16 of size 10x4096 (GPU 0)])(matrix_B): HackParameterList( (0): Parameter containing: [torch.float16 of size 4096x10 (GPU 0)]))(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False)))(15-27): 13 x BaseTransformerLayer((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((query_key_value): ColumnParallelLinear()(attention_dropout): Dropout(p=0.1, inplace=False)(dense): RowParallelLinear()(output_dropout): Dropout(p=0.1, inplace=False))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): MLP((dense_h_to_4h): ColumnParallelLinear()(dense_4h_to_h): RowParallelLinear()(dropout): Dropout(p=0.1, inplace=False))))(final_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True))
)visualglm中核心的Qformer模块
推理时:

训练时: