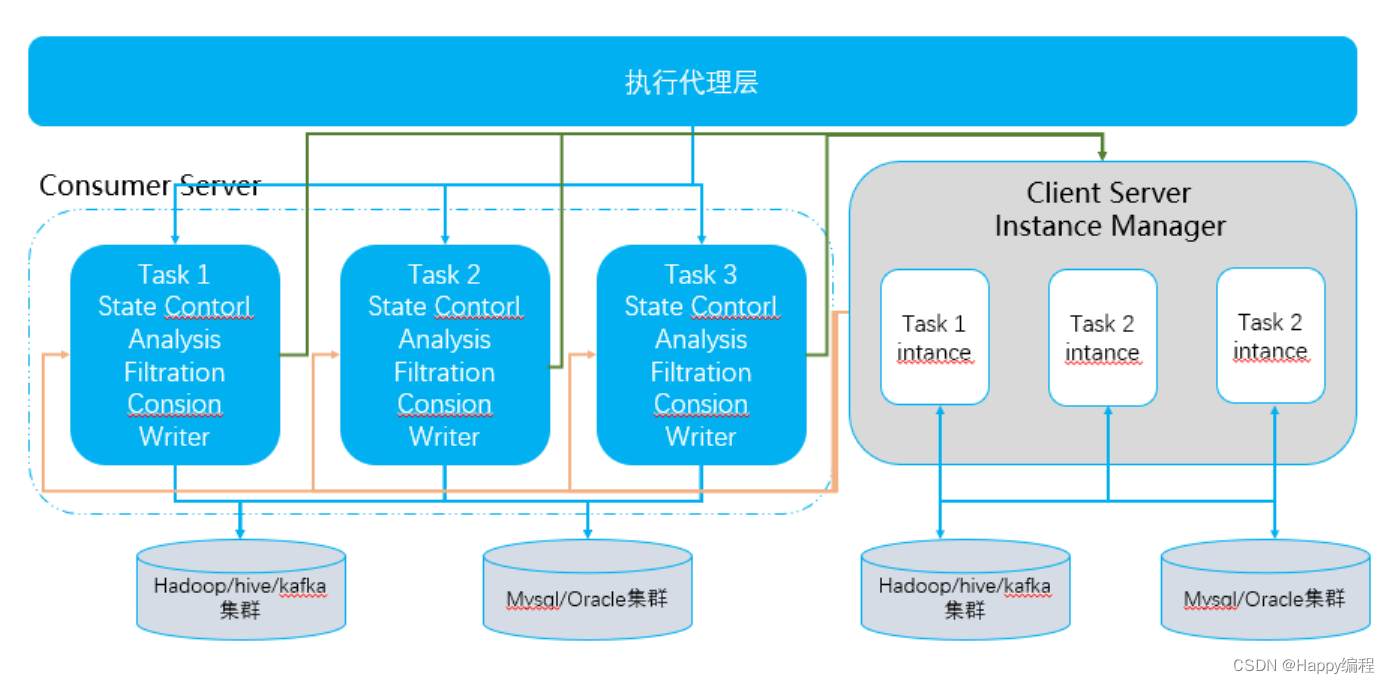
1、机器学习算法平台ai-studio
MLOPS-基于机器学习算法平台建设AllData MLOPS平台
2、AI算法应用市场ai-tasks
数据平台的人工智能引擎:AI算法驱动1、数据准备2、模型开发支持自定义与可视化模型开发3、训练和超参数调节4、模型服务5、模型调整和理解6、模型监控7、模型管理8、AI算法应用市场3、alldata-k8s
基于Docker拉起大数据集群组件
1、配置/etc/hosts
10.0.12.4 namenode
10.0.12.4 resourcemanager
10.0.12.4 elasticsearch
10.0.12.4 kibana
10.0.12.4 prestodb
10.0.12.4 hbase-master
10.0.12.4 jobmanager
10.0.12.4 datanode
10.0.12.4 nodemanager
10.0.12.4 historyserver
10.0.12.4 hive-metastore
10.0.12.4 hive-metastore-pg
10.0.12.4 hive-server
10.0.12.4 zookeeper
10.0.12.4 kafka
10.0.12.4 elasticsearch
10.0.12.4 jobmanager
10.0.12.4 taskmanger
10.0.12.4 hbase-master
10.0.12.4 hbase-regionserver
10.0.12.4 hbase-thrift
10.0.12.4 hbase-stargate
10.0.12.4 alluxio-master
10.0.12.4 alluxio-worker
10.0.12.4 alluxio-proxy
10.0.12.4 filebeat2、docker-compose up -d
3、访问hive
3.1 进入hive-metastore 9083
docker exec -it hive-metastore /bin/bash
3.2 进行hive客户端
hive --hiveconf hive.root.logger=INFO,console
4、页面访问
4、AllData整包编译安装部署assembly
> AllData整包编译安装部署5、buried-trade
ALL DATA Double 微服务商城
启动配置教程
1、启动前,打包dubbo-service
执行mvn clean package -DskipTests=TRUE打包,然后执行mvn install.
2、启动dubbo项目,配置tomcat端口为8091

3、启动商城项目的多个子系统
后台:访问http://localhost:8090
前端:启动mall-admin-web项目,进入项目目录,执行npm install,然后执行npm run dev;
后端:启动mall-admin-search项目,
配置tomcat端口为8092,接着启动pcManage项目,tomcat端口配置为8093;


前台:小程序手机预览,移动端访问:http://localhost:6255
4、小程序和移动端
前端:商城小程序,启动mall-shopping-wc项目,
安装微信开发者工具,配置开发者key和secret,
使用微信开发者工具导入即可,然后点击编译,可以手机预览使用。

5、商城移动端
mobile-h5, 进入项目目录,执行npm install和npm run dev
6、小程序和移动端用的是同一个后台服务,
启动mobileService项目,进入项目目录,配置tomcat端口8094

7、商城PC端 访问http://localhost:8099
前端:启动computer项目,
进入项目目录,执行npm install和npm run dev;
8、启动admin-service项目,配置tomcat端口为8095;

6、系统埋点buried
Logan 开源的是一整套日志体系
包括日志的收集存储,上报分析以及可视化展示。
我们提供了五个组件,包括端上日志收集存储 、iOS SDK、
Android SDK、
Web SDK,
后端日志存储分析 Server,
日志分析平台 LoganSite。
并且提供了一个 Flutter 插件Flutter 插件
buried-shop
ALL DATA 商城生态体系
1、采用lilishop开源项目作为数仓数据来源
2、前端支持mobile、小程序、android、ios
3、后台支持电商用户侧+商家侧管理系统
4、数据运营报表分析系统
演示地址
平台管理端:https://47.107.48.119:8870 账号:admin/123456
店铺管理端:https://47.107.48.119:8871 账号:13011111111/111111
商城PC页面:https://47.107.48.119:8873
7. crawler爬虫项目
1.1 直接http构造es查询,显示查询结果,提供web端查看
1.2 前端拼接hivesql,查询hive表数据
2. 爬虫系统
2.1 爬取数据后,走rabbitmq消息队列通信,数据文件爬取后上传到sftp,然后跑mapreduce任务创建hive表,上传到hdfs
2.2 定时调度爬虫系统
3. data-spider基本架构图
https://my-macro-oss.oss-cn-shenzhen.aliyuncs.com/mall/images/20200304/data-spider.png
4. 启动脚本
django搜索服务
source /usr/local/python-3.6.2/envs/scrapytest/bin/activate
cd /usr/local/scrapy/search
python3 manage.py runserver 0.0.0.0:8000#启动scrapy后台服务
cd /usr/local/scrapy/spider
/usr/local/python-3.6.2/envs/scrapytest/bin/scrapyd &#查看scrapyd
netstat -tlnp | grep 6800#部署spider到scrapy
/usr/local/python-3.6.2/envs/scrapytest/bin/scrapyd-deploy Myploy -p ArticleSpider#启动爬虫
curl http://120.79.159.59:6800/schedule.json -d project=ArticleSpider -d spider=zhihu
curl http://120.79.159.59:6800/schedule.json -d project=ArticleSpider -d spider=lagou
curl http://120.79.159.59:6800/schedule.json -d project=ArticleSpider -d spider=jobbole
8、CRAWLAB FOR ALL DATA PLATFORM 数据采集引擎
数据平台的人工智能引擎:CRAWLAB
基于Golang的分布式爬虫管理平台
支持Python、NodeJS、Go、Java、PHP等多种编程语言以及多种爬虫框架。
9、数据集成引擎dts
AllData社区项目数据集成平台
基于Canal/Debezium/FlinkCDC的原理机制,设计开发CDC异常恢复程序,保障数据同步链路的可靠性和准确性
- 一、监控canal/dbz的失活状态,触发DTalk告警
- 二、获取Kafka Topic最新时间值的数据
- 三、获取恢复数据-先统一获取mysql/oracle最大时间戳字段
- 四、获取源表近[最新起始,最新起始+10s]的操作最新的数据
1、DataX
2、flink cdc
3、FlinkX
4、InLong
5、Canal
6、Debezium
10、govern
DATA GOVERN FOR ALL DATA PLATFORM 数据治理引擎
数据平台的数据治理:数据治理是一个大而全的治理体系。需要数据质量管理、元数据管理、主数据管理、模型管理管理、数据价值管理、
数据共享管理和数据安全管理等等模块是一个活的有机体。1、数据质量: 依托Griffin平台,为您提供全链路的数据质量方案,包括数据探查、对比、质量监控、SQL扫描和智能报警等功能:开源方案: Apache Griffin + ES + SparkSql2、元数据: 描述数据的数据,对数据及信息资源的描述性信息,例如字段元数据描述字段的类型、长度、默认值。
发布:指将某一元数据发布为数据资产的动作。数据资产是指可以对外提供服务并且产生价值的数据。
表/字段血缘:即表/字段的来龙去脉,主要包含表/字段的来源、加工方式、映射关系及数据出口。血缘是元数据的一部分,
有利于数据变更影响分析以及数据问题排查。开源方案: Apache Atlas + ES + Hbase + JanusGraph + Hive + Kafka3、数据标准: 参考阿里的DataWorks,数据标准是用于描述公司层面需共同遵守的数据含义和业务规则,
它描述了公司层面对某个数据的共同理解,这些理解一旦确定下来,就应作为企业层面的标准在企业内被共同遵守。
数据标准,也称数据元,由一组属性规定其定义、标识、表示和允许值的数据单元,是不可再分的最小数据单元。
您可以将数据标准关联到各个业务上的数据库中。
其中,标识符、数据类型、表示格式、值域是数据交换的基础,它们用于描述表的字段元信息,规范字段所存储的数据信息。暂无事实性标准的开源方案:Mysql + SpringBoot4、数据服务:参考阿里的DataWorks, 数据服务旨在为企业搭建统一的数据服务总线,帮助企业统一管理对内对外的API服务。
数据服务为您提供快速将数据表生成API的能力,同时支持您快速注册现有的API至数据服务平台,进行统一的管理和发布。
数据服务已经与API网关(API Gateway)连通,支持一键发布API服务至API网关。
数据服务与API网关为您提供了安全稳定、低成本、易上手的数据开放共享服务。
数据服务采用Serverless架构,您只需要关注API本身的查询逻辑,无需关心运行环境等基础设施,
数据服务会为您准备好计算资源,并支持弹性扩展,零运维成本。开源方案:Apache Kong + Mysql + Lua + Postgresql + ES
11、knowledge
DATA AI FOR ALL DATA
知识图谱(Knowledge Graph)
12、lakehouse
DATABASES FOR ALL DATA PLATFORM 分布式存储引擎
数据平台的分布式存储引擎:存算分离譬如Kylin+Parquet 存算一体譬如CK
1、cassandra
2、clickhouse
3、drill
4、flinksql
5、greenplum
6、hql
7、kylin
8、memcached
9、mongodb
10、mysql
11、oracle
12、phoenix
13、presto
14、postgresql
15、redis
16、sparkSql
17、teradata
18、janusgraph
19、iceberg
20、hudi
13、olap
基于Calcite建设多引擎SQL解析路由系统
基于Kylin3.1.3 DataSourceSDK + Calcite进行开发1、增加ClickHouseAdapter2、基于Calcite进行语法词法解析3、根据Calcite解析SQL进行规则路由4、封装JDBC转发查询不同OLAP引擎5、返回SQL查询结果14、studio
AllData社区版

1、AllData输入
实时开发
Dlink
离线开发
FlinkX
数据治理
ElAdmin
湖仓一体
Dlink+CDC+Hudi
机器学习算法平台
cube-studio
数据集成
ElAdmin
数据中台
ElAdmin
大数据集群运维平台
Rancher
数据分析
Hive+Doris
实时同步
Dlink+FlinkCDC+Doris
任务调度
DolphinScheduler
运维中心
SREWorks
数仓建模
Doris
低代码引擎
lowcode-engine
墨刀产品原型
2、输出
MVP产品
设计文档
项目会议
3、补强
前端开发
产品设计
后端架构
云原生架构
大数据架构
UI设计
15、studio-tasks
BUSINESS FOR ALL DATA PLATFORM 计算引擎
数据平台的计算引擎:离线开发&实时开发
1、druid
2、flink
3、griffin
4、ksql
5、mapreduce
6、spark
7、spark streaming
8、storm
9、tez