普通索引和唯一索引,应该怎么选择?
普通索引,不能保证字段的唯一性,所以普通索引会比唯一索引要多N次判断,比如判断下一条记录是否和目标相同。
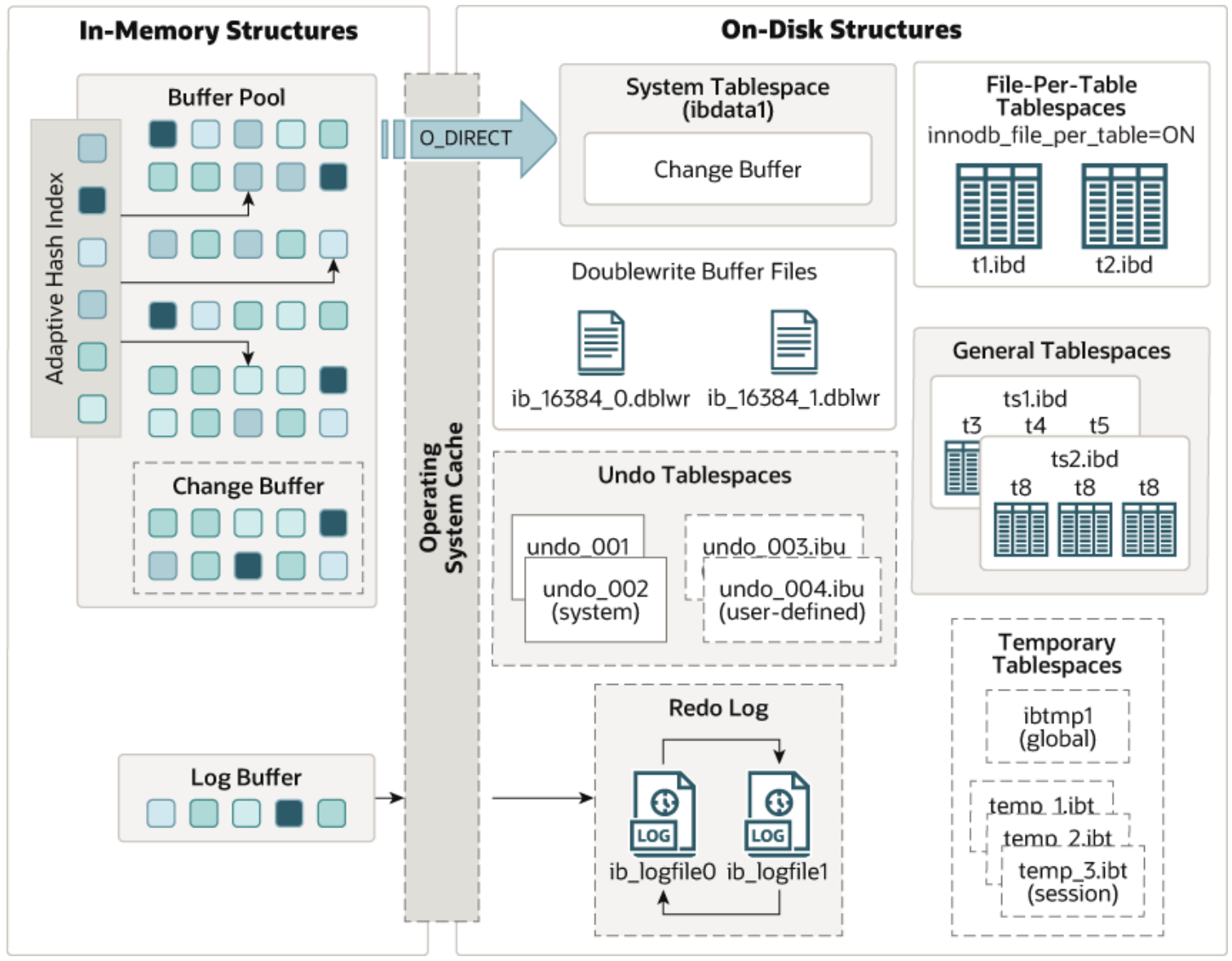
InnoDB的数据其实是按页来取的,也就是说要拿到某一个数据,其实会把这一整页的数据都从磁盘加载到内存中,一页默认是16KB。
Change Buffer
如果查找普通索引中某个字段刚好在页尾,那是不是就还得继续往后判断,那就还得再加载一次数据页,而磁盘的IO操作是MySQL中成本最大的一个操作了,这样的代价会变得很大,因此,MySQL引入了Change Buffer这一概念,Change Buffer是共用Buffer Pool的空间的,它的最大空间不能超过Buffer Pool。
- 若数据页在内存中,直接更新Buffer Pool中的数据,标记为脏页
- 若数据不在内存中,会把更新操作先临时写入Buffer Pool中,如果马上有人访问这个数据,就会从磁盘加载这一页的数据,做完更新操作后,再把数据返回,如果暂时没有人访问,MySQL会有一个线程定时去刷盘。
而唯一索引则一定会把数据页加载到内存当中,然后更新Buffer Pool中的数据
因此,对于写多读少的场景,普通索引的效率会更高一些。
Change Buffer & Redo Log
Change Buffer 和 Redo Log 是数据库系统(尤其是 MySQL 中)用于提高性能和保证数据一致性的两种机制,它们的主要区别在于功能和应用场景:
-
Change Buffer(更改缓冲区):
- 作用:用于缓冲索引页的变化,特别是非聚簇索引的变化。在写入数据时,不是立即将这些数据写入磁盘上的索引页,而是暂时保存在 Change Buffer 中,等到需要读取相关索引页或者系统空闲时再将其应用到磁盘上。
- 目的:减少频繁的磁盘 I/O 操作,尤其是在索引较多的情况下可以显著提升性能。
- 适用场景:主要针对二级索引的写入操作。
-
Redo Log(重做日志):
- 作用:记录事务的变化(即使事务还没有提交),以便在数据库崩溃后可以通过重做日志恢复数据到一致状态。它记录的是对数据页的物理更改。
- 目的:确保数据库的持久性和数据一致性,在系统崩溃时能够通过重做日志进行恢复。
- 适用场景:Redo Log 适用于所有对数据的更改,不论是数据页还是索引页的修改。
总结:Change Buffer 主要是为了优化磁盘 I/O 而设计的,缓冲的是索引页的变化;而 Redo Log 主要是为了数据的持久性,记录的是对数据页的更改,确保系统崩溃时能够恢复。
mysql> insert into t(id,k) values(id1,k1),(id2,k2);
这里,我们假设当前 k 索引树的状态,查找到位置后,k1 所在的数据页在内存 (InnoDB buffer pool) 中,k2 所在的数据页不在内存中。
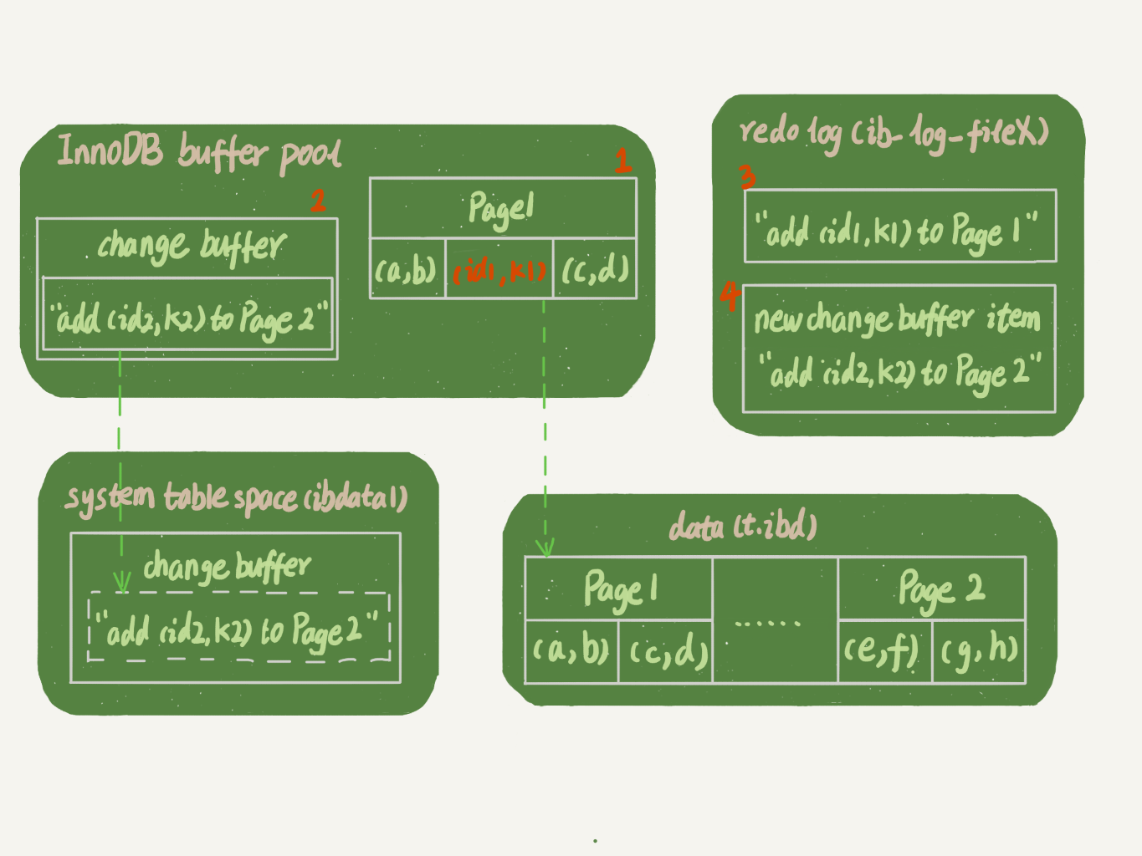
- Page 1 在内存中,直接更新内存;
- Page 2 没有在内存中,就在内存的 change buffer 区域,记录下“我要往 Page 2 插入一行”这个信息将上述两个动作记入 redo log 中(图中 3 和 4)。
- 做完上面这些,事务就可以完成了。所以,你会看到,执行这条更新语句的成本很低,就是写了两处内存,然后写了一处磁盘(两次操作合在一起写了一次磁盘),而且还是顺序写的。同时,图中的两个虚线箭头,是后台操作,不影响更新的响应时间。
比如,我们现在要执行 select * from t where k in (k1, k2)。
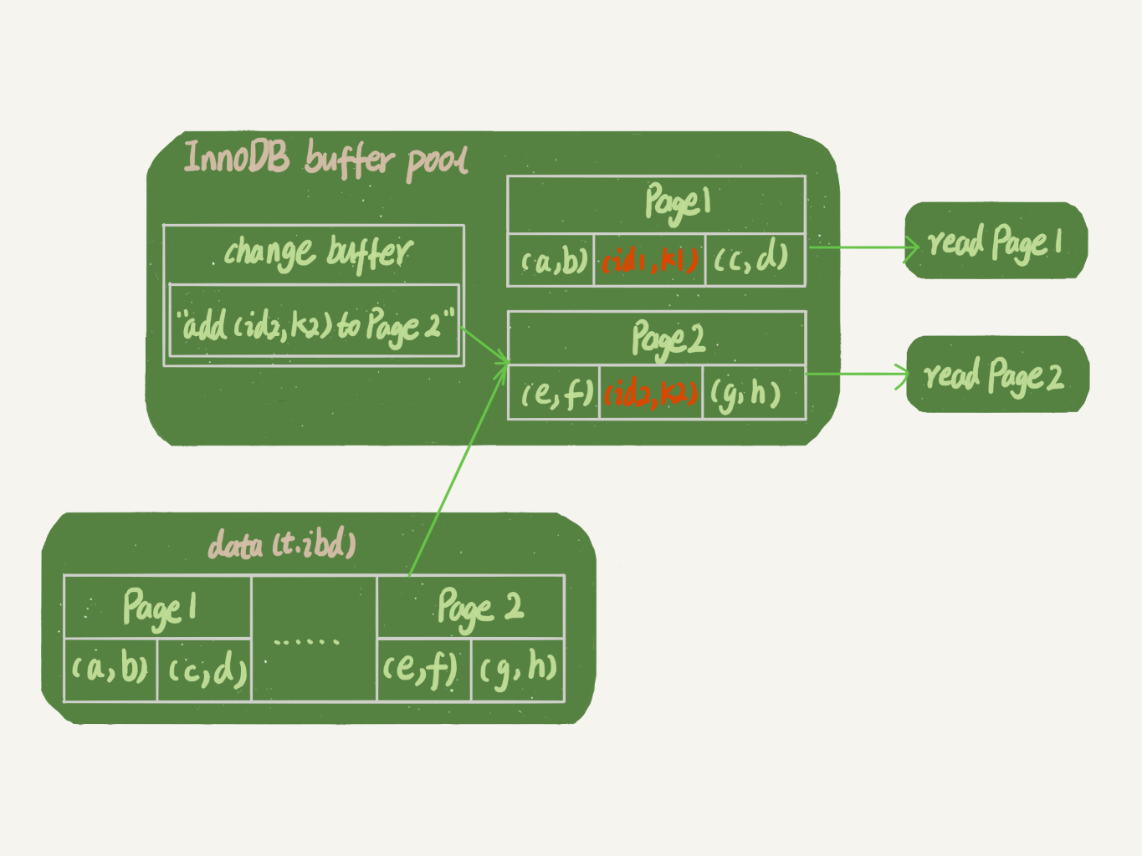
Page 1 的数据已经写入了 InnoDB 的缓冲池(buffer pool),因此可以直接从内存中读取并返回。而 Page 2 的数据还没有写入缓冲池,它的修改只记录在变更缓冲区(change buffer)中。因此,当需要读取 Page 2 时,必须先从磁盘中加载该数据页到缓冲池,然后再应用变更缓冲区中的修改,才能得到最终的正确数据版本。
















![[AWS云]kafka调用和创建](https://i-blog.csdnimg.cn/direct/e5ebb644cd364faf877716f2d11001c7.png)
