摘要
本文提出了一种基于遗传模拟退火算法的风电功率聚类分析方法。风电功率受气象条件的影响波动较大,给电网调度带来较大挑战。本文通过遗传算法结合模拟退火算法,对风电功率进行聚类分析,旨在挖掘风电功率数据中的模式,提升风电功率的预测精度和稳定性。仿真实验表明,该方法能够有效识别风电功率的典型波动模式,为电力系统的优化调度提供参考。
理论
-
遗传算法(GA):遗传算法是一种基于自然选择和遗传机制的搜索算法。通过选择、交叉、变异等操作,遗传算法能够快速在复杂的搜索空间中找到接近最优解的解。在风电功率聚类问题中,遗传算法可用于优化聚类中心的位置,从而提高聚类结果的准确性。
-
模拟退火算法(SA):模拟退火是一种基于物理退火过程的优化算法,能够在搜索空间中进行全局优化。与遗传算法结合,模拟退火算法可帮助遗传算法跳出局部最优,从而在复杂的非线性问题中找到全局最优解。
-
聚类分析:聚类是将数据集划分为若干个相似的簇,每个簇中的数据具有相似的特征。在风电功率分析中,通过聚类可以将相似的功率波动模式归为一类,从而简化数据的复杂性,并为电网调度提供参考。
实验结果
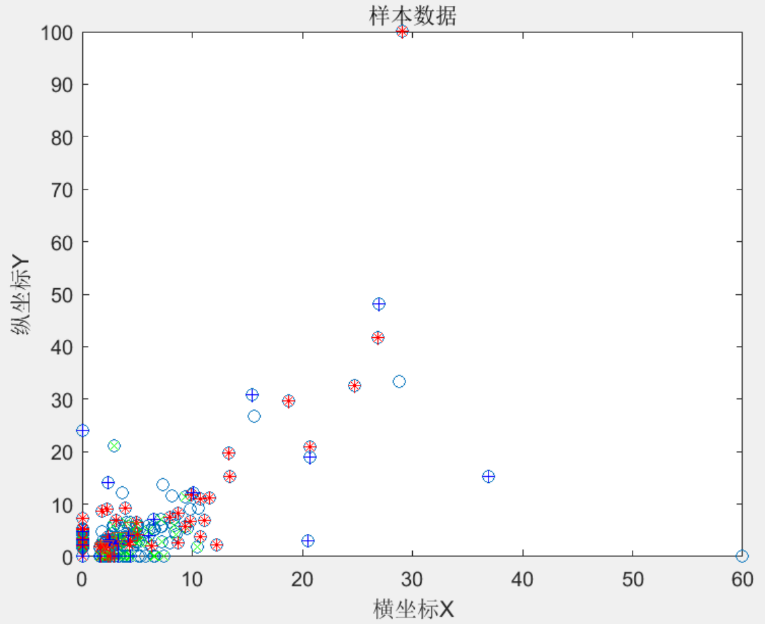
实验基于MATLAB仿真平台,选取了风电场的历史功率数据进行聚类分析。首先对风电功率进行预处理,剔除异常值。然后,使用遗传模拟退火算法进行聚类,并将聚类结果进行可视化。
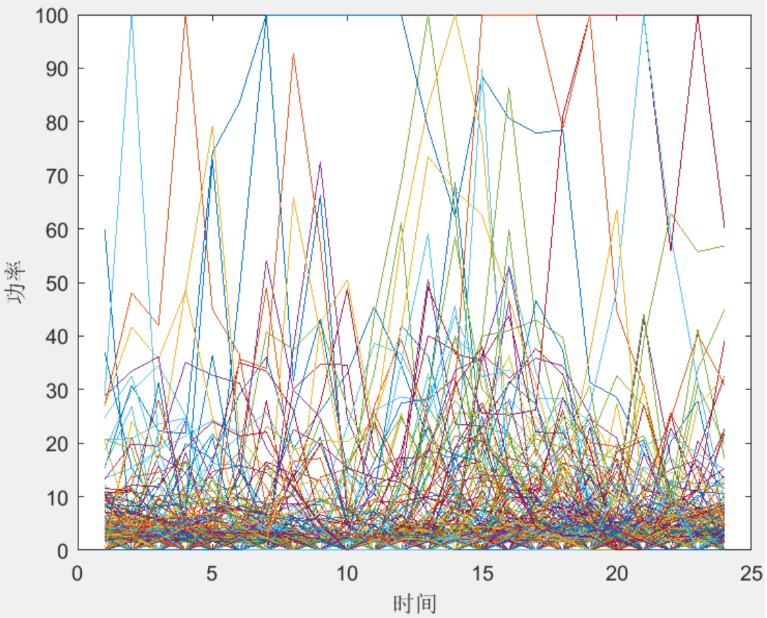
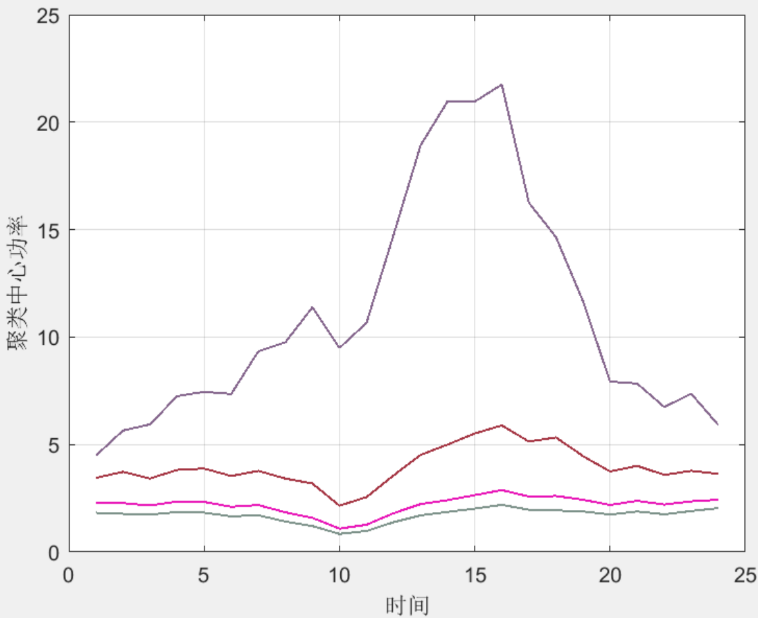
图1为风电功率样本数据分布图;图2展示了多个风电功率曲线的时序变化情况,图3为聚类中心的时序功率曲线,可以看到,经过聚类分析后,风电功率数据被合理地划分为若干类,每类代表一种典型的功率波动模式。
部分代码
% 初始化参数
num_clusters = 5; % 聚类中心数目
max_iter = 100; % 最大迭代次数
data = load('wind_power_data.mat'); % 加载风电功率数据% 初始化聚类中心
centers = initialize_centers(data, num_clusters);% 遗传模拟退火算法主循环
for iter = 1:max_iter% 计算每个点到聚类中心的距离distances = calculate_distances(data, centers);% 根据距离分配每个点的簇clusters = assign_clusters(distances);% 重新计算聚类中心new_centers = update_centers(data, clusters, num_clusters);% 进行模拟退火操作,跳出局部最优centers = simulated_annealing(centers, new_centers, iter, max_iter);% 检查收敛条件if has_converged(centers, new_centers)break;end
end% 绘制聚类结果
figure;
subplot(3,1,1);
scatter(data(:,1), data(:,2), 'DisplayName', '样本数据');
title('样本数据');subplot(3,1,2);
plot(time, data);
title('风电功率时序变化');subplot(3,1,3);
plot(time, centers);
title('聚类中心功率曲线');
参考文献
❝
Goldberg, D. E. (1989). Genetic Algorithms in Search, Optimization, and Machine Learning. Addison-Wesley.
Kirkpatrick, S., Gelatt, C. D., & Vecchi, M. P. (1983). Optimization by simulated annealing. Science, 220(4598), 671-680.
Jain, A. K., Murty, M. N., & Flynn, P. J. (1999). Data clustering: A review. ACM Computing Surveys (CSUR), 31(3), 264-323.
(文章内容仅供参考,具体效果以图片为准)