前言
本篇文章将详细介绍http协议,将介绍http抓包工具的下载与使用。

目录
一.http协议初识
1.概念
2.特点
1)版本
2)工作方式
二.http抓包工具
1.抓包是什么
2.抓包软件下载(Fiddler)
3.使用
三.http格式
1.http请求的基本格式
1)首行
2)请求头(header)
3)空行
4)正文
2.http响应的基本格式
1)首行
2)响应头
3)空行
4)正文
四.URL
一.http协议初识
1.概念
http协议(全程为“超文本传输协议”)是一种应用非常广泛的应用层协议

http不仅能够传输文本,还能传输图片,音频,视频等其他各种数据,广泛应用于日常开发的各种场景之中。
例如:
1.使用浏览器,打开网页
2.打开手机app
3.后端程序,分布式/微服务体系结构
服务器之间的调用,大概率也是http协议
2.特点
1)版本

http协议版本3.0前,都是基于TCP协议。3.0是基于UDP协议。
其中 ,互联网见到http协议,以1.1版本为主流
2)工作方式
http协议是一种典型的一问一答协议(客服端发一个请求,服务器返回一个响应,一 一对应)
例如打开网页就是典型的一问一答
除一问一答模式外,还有一问多答,多问一答,多问多答等
一问多答:下载一个大的文件
多问一答:上传一个大的文件
多问多答:远程桌面
二.http抓包工具
1.抓包是什么
抓包是把通过网卡的数据获取到,并解析出来
借助抓包软件,我们可以观察http请求/响应的详细情况
TCP/UDP都可以抓包,但在日常开发中,很少会抓TCP层次的包,抓http的包比较常见。

电脑与服务器传输数据时,在二者之间加一个关卡(抓包程序),每次数据传输过程必须经过经过这个关卡,再转发给服务器,服务器同理。
此时,这个关卡就能获取到数据,这个程序也被称为“代理”。
2.抓包软件下载(Fiddler)
首先进入官方:https://www.telerik.com/fiddler

点击下载

随便填写好,下载,更改路径,一路next安装好,打开应用


第一次配置时,会弹出一个弹窗,点击yes,如果点了no,就得卸掉重下了。
3.使用

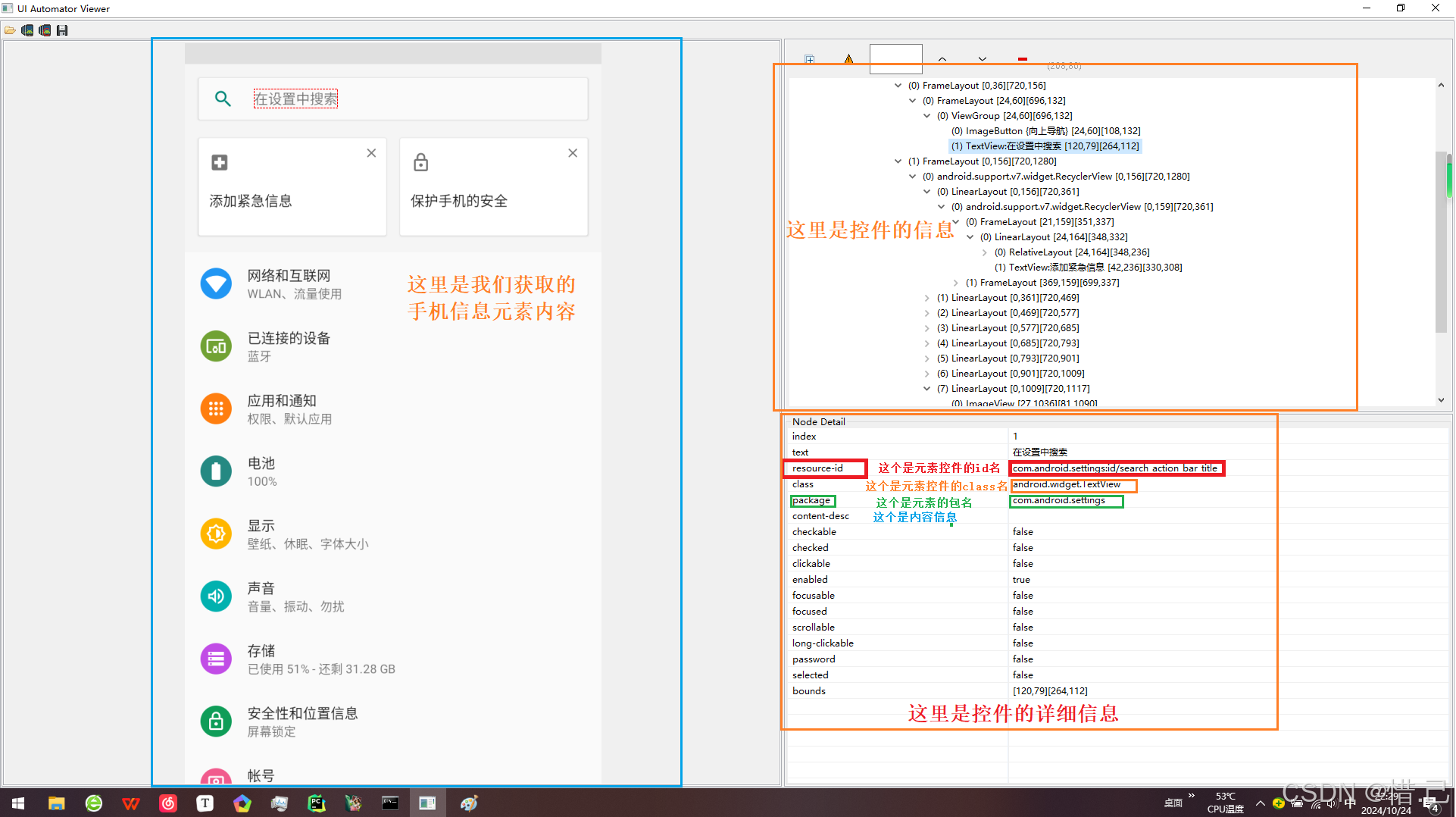
打开Fiddler后,我们会在左侧看到大量的数据包,因为Fiddler会把应用程序的数据包都截取到,即使不打开网站,数据包也会蹦出来。
为了方便抓包,我们可以Ctrl+a全部选中,再Delete进行清空

我们打开bilibili的网站,Fiddler就会截取数据包

我们选择该数据包,点击raw标签查看原始数据

我们点击View in Notepad,可以用记事本打开该数据包。
以上便是http的抓包过程。
三.http格式
1.http请求的基本格式
1)首行
以上述抓包为例
![]()
此段为行首
为http请求的方法(method),表示要做什么操作
为URL
为版本号
2)请求头(header)
请求行是从第二行开始,一直到空行结束

每一行都是键值对结构。
3)空行
请求头的结束,啥都没有。
若是数据包由正文,则在空行后接上
4)正文
有一些数据包有正文,有一些无正文

此数据包为有正文的数据包

此为正文段,记录着用户输入的信息

2.http响应的基本格式
响应报文的结构与请求报文的结构非常相似,但也略有不同

1)首行
HTTP/1.1 200 OK
HTTP/1.1表示版本
200表示状态码
OK表示状态码的说明
2)响应头
与请求报文的请求头类似
3)空行
响应头的结束位置,若有正文,则接在空行的后面
4)正文
{"msg":"操作成功","code":200,"token":"eyJhbGciOiJIUzUxMiJ9.eyJ1c2VyX2lkIjozMTMxMCwidXNlcl9rZXkiOiIxYTNkYzcxMC1hNzFhLTQ2YWItYjMzMS1iNWM2YzMwNWVhODciLCJ1c2VybmFtZSI6InhpZXl1bWluZyJ9.JcfyfzD6lBb5cnOTOMkwRsy64Son3sgAXbcnw91nW5_SdNbqn8gotrt7uoCncHvgcQQt4QZnVcxu_Bs0IeVcXw"}
0
四.URL
URL,唯一资源定位符,用于定位网络资源。
随便以一个URL为例:https://v.bitedu.vip/personInf/student?userId=10000&classId=100
https:// :协议方案名,常见的有http和https(https是http+ssl,加密)
v.bitedu.vip :域名,会通过DNS协议解析成一个具体的IP地址
personInf/student :带层次的文件路径
userId=10000&classId=100 :查询字符串(query string),本质是一个键值对结构,键值对之间用“&”分隔,键与值用“=”分隔
URLencode
像/?:等这样的字符,已经被url当做特殊意义理解了.因此这些字符不能随意出现. 比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进⾏转义
转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不⾜4位直接处理),每2位做 ⼀位,前⾯加上%,编码成%XY格式
例如:
我们去浏览器搜索C++

“++”字符被转义成“%2B%2B”

以上便是全部内容,如有不对,欢迎指正