概述:本文基于langchain和Cyber Security Breaches数据集构建Agent,并基于该Agent实现了数据分析、趋势图输出、预测攻击态势三个功能,最后给出Agent在安全领域应用的三点启示。
前提:
1、拥有openai API KEY;(要付费的)
2、熟悉Google colab 环境;(T4显卡可免费使用12个小时)
3、下载好数据集。
一、选定数据集,
数据集的选择是根据我们想要做的事情定的,基于我们的目标事件,去HG上寻找是否有相关数据集。这里笔者想要分析网络安全漏洞影响,所以选择了“Cyber Security Breaches”数据集。

&&网络安全漏洞库Cyber Security Breaches
Cyber Security Breaches数据集,该数据集包含了各种有关网络安全漏洞的信息,如受影响组织的名称、国家、受影响人数、数据泄露类型等。用户可以通过该页面查看数据集的详细信息,并使用Hugging Face库进行数据集的访问和处理。页面提供了数据集的统计信息、示例数据和数据集字段的详细描述,帮助用户更好地了解数据集内容。
数据集地址:https://huggingface.co/datasets/schooly/Cyber-Security-Breaches/viewer
上传数据集:下载好Cyber Security Breaches到本地计算机后运行上传代码,并打印前面10行进行有原数据进行比对并确认无错误。
from google.colab import filesdef load_csv_file():
# """Loads a CSV file into a Pandas dataframe."""uploaded_file = files.upload()file_path = next(iter(uploaded_file))document = pd.read_csv(file_path)return documentif __name__ == "__main__":document = load_csv_file()
二、基于langchian搭建agent
通常来说,基于langchain搭建agent主要包含定义代理类型、配置工具和语言模型,并根据需要将代理部署在应用程序中等步骤:以下是一个基于 LangChain 搭建基本 `agent` 的示例流程:
2.1、安装依赖
确保安装了 `LangChain` 和其他必要的依赖。
```python
!pip install langchain
!pip install openai
```
2.2、导入模块
导入 `LangChain` 的核心模块,包括代理、工具和语言模型。
```python
from langchain.agents import initialize_agent, Tool
from langchain.llms import OpenAI
from langchain.agents.agent_types import AgentType
```
2.3、定义语言模型
设置 OpenAI 的语言模型,比如 `ChatOpenAI` 或 `OpenAI`,并调整温度等参数来控制模型响应的创造性。
```python
llm = OpenAI(api_key="your_openai_api_key", temperature=0)
```
2.4、配置工具
定义代理将使用的工具(Tool),这些工具可以包括搜索、数据库查询、文件读取等操作。
```python
tools = [
Tool(
name="search_tool",
func=lambda query: "Search result for: " + query, # 假设一个简单的搜索工具
description="这个工具用于从搜索引擎中获取信息。"
)
]
```
langchain常见工具举例,本文将使用到PandasDataFrame工具进行数据分析。
| 函数名称 | 说明 | 使用场景举例 |
|
| 一个简单的搜索工具,允许通过查询访问网络信息。 | 用户询问最新的科技新闻,代理使用搜索工具提供最新的信息。 |
|
| 从维基百科提取信息的工具,可以用于快速获取知识性内容。 | 用户询问某个历史事件,代理调用维基百科工具提供相关信息。 |
|
| 处理和分析 Pandas DataFrame 的工具,支持数据操作。 | 用户请求对某数据集进行统计分析,代理使用 Pandas 工具执行操作。 |
|
| 基本计算器工具,用于执行数学计算。 | 用户询问复杂的数学问题,如积分或代数,代理调用计算器工具进行计算。 |
|
| 网页抓取工具,用于从网页中提取数据。 | 用户希望获取某个电商网站的产品价格信息,代理使用网页抓取工具提取数据。 |
|
| 读取文件内容的工具,如文本文件或 CSV 文件。 | 用户上传文件并请求数据分析,代理使用文件读取工具加载数据。 |
|
| 处理对话的工具,用于与用户进行交互。 | 用户与代理进行问答,代理调用对话工具生成自然语言响应。 |
|
| 调用 OpenAI API 的工具,进行自然语言处理和生成。 | 用户请求生成一篇文章,代理调用 OpenAI 函数生成文本内容。 |
2.5、 初始化代理
使用 `initialize_agent` 函数创建代理,指定类型、工具和语言模型。
```python
agent = initialize_agent(
tools=tools,
llm=llm,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION, # 设置代理类型
verbose=True # 启用详细模式以跟踪代理执行过程
)
```
2.6、使用代理
一旦代理配置完成,便可以用自然语言向代理发送请求,并获取相应的响应。
```python
query = "What are the latest trends in cybersecurity?"
response = agent.run(query)
print(response)
```
常用代理类型
- **Zero-Shot React**:适用于直接响应的代理,主要用于简单的 Q&A。
- **Self-Ask with Search**:将复杂问题分解成简单问题,并使用搜索工具查找答案。
- **React Docstore**:适合访问和查询文档库数据的代理类型。扩展功能
你可以根据需求添加更多工具,或使用特定的代理类型来处理特定任务,比如 `Structured Chat` 用于多输入工具或复杂聊天对话。代理的应用场景
可以将构建的代理用于各种应用场景,包括智能客服、数据分析助手、文档检索工具等。
三、 智能体应用
3.1、创建Agent
基于langchain框架导入模块并创建数据框agent,通过 create_pandas_dataframe_agent 函数,创建了一个 Pandas 数据框代理 sm_ds_OAI。该代理会与 OpenAI 的模型结合,能够接受自然语言的指令来分析和查询 document 中的数据,实现智能的数据处理和分析
# 导入模块
from langchain.agents.agent_types import AgentType #导入 AgentType 枚举,用于指定代理类型。from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
#从实验模块中导入 create_pandas_dataframe_agent 函数,这个函数允许我们创建一个 Pandas DataFrame 的智能代理。from langchain_openai import ChatOpenAI
from langchain_openai import OpenAI#创建数据框代理
sm_ds_OAI = create_pandas_dataframe_agent(OpenAI(temperature=0),document,verbose=True
)3.2、实践一:分析总结
使用sm_ds_OAI.invok()进行数据分析,invok是Langchain中向智能体发送自然语言指令的方法,它允许agent根据这些指令执行相关让任务并返回结果,具体功能包括任务调度、自然语言执行、支持多种工具调用和生成响应。
sm_ds_OAI.invoke("请分析此数据,并用大约 100 字的中文简要说明。请将分析过程的标记,如'Thought'和'Action'替换为'思考'和'执行'")
在 LangChain 中,有多个方法可以用于执行不同任务。下面是一些常见的方法,包括说明、使用场景和 Python 调用示例:
| 函数名称 | 说明 | 使用场景举例 | 函数调用示例 |
|
| 发送指令到代理,自动匹配工具或模型执行任务,并返回结果。 | 进行数据分析、生成报告、回答问题等任务 |
|
|
| 类似于 | 用户请求快速问题回答,如“今天的天气如何?” |
|
|
| 动态添加工具到代理中,使代理在调用时可以使用新工具。 | 用户希望添加一个新的搜索工具,以增强代理的能力 |
|
|
| 获取当前代理中的所有可用工具,便于了解代理的能力范围。 | 用户希望查看代理具备哪些工具来完成特定任务 |
|
|
| 设置代理的详细模式,显示执行过程的详细信息,有助于调试。 | 在调试过程中查看代理调用的每个步骤和输出细节 |
|
|
| 清除代理的临时记忆,适用于多轮对话中重置上下文的情况。 | 用户在会话中想从头开始交谈,以避免前面内容的干扰 |
|
|
| 初始化代理,配置语言模型、工具等资源,用于设置代理环境。 | 初始化代理的配置,如加载数据处理工具和模型 |
|
运行上面的语言后,Agent开始运行,可以看到经过九步思考与执行后,agent给出了最终的分析结论。
> Finished chain.{'input': "请分析此数据,并用大约 100 字的中文简要说明。请将分析过程的标记,如'Thought'和'Action'替换为'思考'和'执行'",'output': '根据对该数据的分析,可以发现该数据集包含1055条记录,涉及到不同州的医疗机构发生的违规事件。其中,受影响人数最多的州是加利福尼亚州,受影响人数最少的州是阿拉斯加州。同时,通过散点图可以发现,随着年份的增加,受影响人数也呈现增加的趋势。此外,还发现数据中存在大量缺失值,需要进一步处理。'}

| Entering new AgentExecutor chain... 一步 | Thought: 我需要使用pandas来分析这个数据 Action: python_repl_ast Action Input: import pandas as pd Observation: |
| 两步 | Thought: 我需要将数据读取到一个pandas dataframe中 Action: python_repl_ast Action Input: df = pd.read_csv('data.csv') Observation: |
| 三步 | Thought: 我需要先将数据文件下载到本地 Action: 下载数据文件 Action Input: data.csv Observation: |
| 四步 | Thought: 我需要使用pandas的head()函数来查看数据的前几行 Action: python_repl_ast Action Input: print(df.head()) Observation: |
| 五步 | Thought: 我需要对数据进行简单的描述性统计分析 Action: python_repl_ast Action Input: df.describe() Observation: |
| 六步 | Thought: 我需要对数据进行更深入的分析,比如查看缺失值和数据类型 Action: python_repl_ast Action Input: df.info() |
| 七步 | Thought: 我需要对数据进行可视化分析,比如绘制柱状图来查看不同州的数据数量 Action: python_repl_ast Action Input: df['State'].value_counts().plot(kind='bar') Observation: Axes(0.125,0.11;0.775x0.77) Observation: Axes(0.125,0.11;0.775x0.77) |
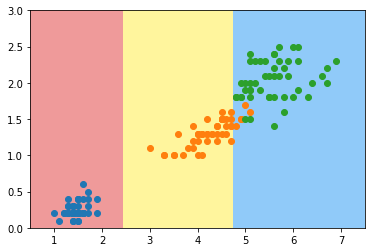
| 八步 | Thought: 我需要对数据进行更深入的可视化分析,比如绘制散点图来查看受影响人数和年份的关系 Action: python_repl_ast Action Input: df.plot.scatter(x='year', y='Individuals_Affected') Observation: Axes(0.125,0.11;0.775x0.77) |
| 九步 | Thought: 我现在知道了数据的大致情况,可以开始撰写分析报告了 Final Answer: 根据对该数据的分析,可以发现该数据集包含1055条记录,涉及到不同州的医疗机构发生的违规事件。其中,受影响人数最多的州是加利福尼亚州,受影响人数最少的州是阿拉斯加州。同时,通过散点图可以发现,随着年份的增加,受影响人数也呈现增加的趋势。此外,还发现数据中存在大量缺失值,需要进一步处理。 |
| Finished chain. | {'input': "请分析此数据,并用大约 100 字的中文简要说明。请将分析过程的标记,如'Thought'和'Action'替换为'思考'和'执行'", 'output': '根据对该数据的分析,可以发现该数据集包含1055条记录,涉及到不同州的医疗机构发生的违规事件。其中,受影响人数最多的州是加利福尼亚州,受影响人数最少的州是阿拉斯加州。同时,通过散点图可以发现,随着年份的增加,受影响人数也呈现增加的趋势。此外,还发现数据中存在大量缺失值,需要进一步处理。'} |
备注:因为Observation数据较多,为节省空间,前面几步的内容不再文章内呈现。
此处想到这个画面应该不过分吧?


图片来源:https://www.youtube.com/watch?v=zt9Oh_RZ5KU
3.3、实践二:趋势图输出
在讲langchain中的invoke方法时有提到,run方法通常用于快速执行单步指令,适合简单任务。实践二基于run()实现趋势图的绘制。
sm_ds_OAI.run("画一条体现整体安全的趋势图")

3.4、实践三:预测攻击态势
运行:
sm_ds_OAI.invoke("""选择一个预测模型来预测攻击态势。使用这种类型的模型来预测在加利福尼亚州未来3年的平均攻击次数和受影响的人数。output输出的内容翻译为中文。""")
输出结果: '加利福尼亚州未来3年的平均攻击次数为536.27次,受影响的人数为41345.94人。'

四、安全应用启示
一、安全领域应用:将 Cyber Security Breaches数据集替换为用户的网络安全攻击日志,那么基于智能体开展态势分析、威胁狩猎、攻击溯源、态势预测、数据统计等工作均成为可能。
二、 数据安全:SOTA大模型效果虽然相对好,但是调用API方式存在数据安全的问题,国内政府、金融、能源等行业难以落地,本地部署安全领域垂直模型是一种可行路径。
三、价格昂贵:即使能接受数据外传,调用API方式的花费依然是个天文数字,笔者大概观测了下,上文实践一运行一次0.2元,实践三运行一次0.3元,而且是基于gpt-3.5-turbo,如果换位GPT4-O,实时流量检测场景下,一个用户平均一天1亿条HTTP日志,一条HTTP按照1000Token计算,每天的费用上亿美元,如此看来实时检测通过调用SOTA大模型API是天方夜谭,不过在安全分析场景可以考
《本文完》

图:高铁外的雪山
参考:https://github.com/peremartra/Large-Language-Model-Notebooks-Course/blob/main/3-LangChain/LangChain_Agent_create_Data_Scientist_Assistant.ipynb





![Vue3入门--[vue/compiler-sfc] Unexpected token, expected “,“ (18:0)](https://i-blog.csdnimg.cn/direct/91155f5766894531ad67df6a650e6509.png)