摘要
- 构建一个基于AES的深度学习系统,需要一个包含人为打分的训练数据集。
- 本文介绍了EssayGAN,一个基于生成对抗网络的自动文章生成器。
- 为了生成打分了的文本,EssayGAN有每个分数范围对应的生成器以及一个鉴别器。每个生成器致力于一个特定的分数,并且生成打分为该分数的文本。这样,生成器能够只关注于产生一个看起来实际可行的文章,这个文章能够欺骗鉴别器,使得鉴别器不用考虑目标分数。
- 尽管普通文本的生成对抗网络(GANs)基于词来产生文本,EssayGAN基于句子来产生文本。所以,EssayGAN不仅能够通过在每一步预测一个句子的方式来创作长文章,而且能够通过应用针对不同目标分数的生成器来创作已经打好分的文本。
- 由于EssayGAN能够产生打好分的文本,产生的文本能够被用在AES的有监督的学习过程中。
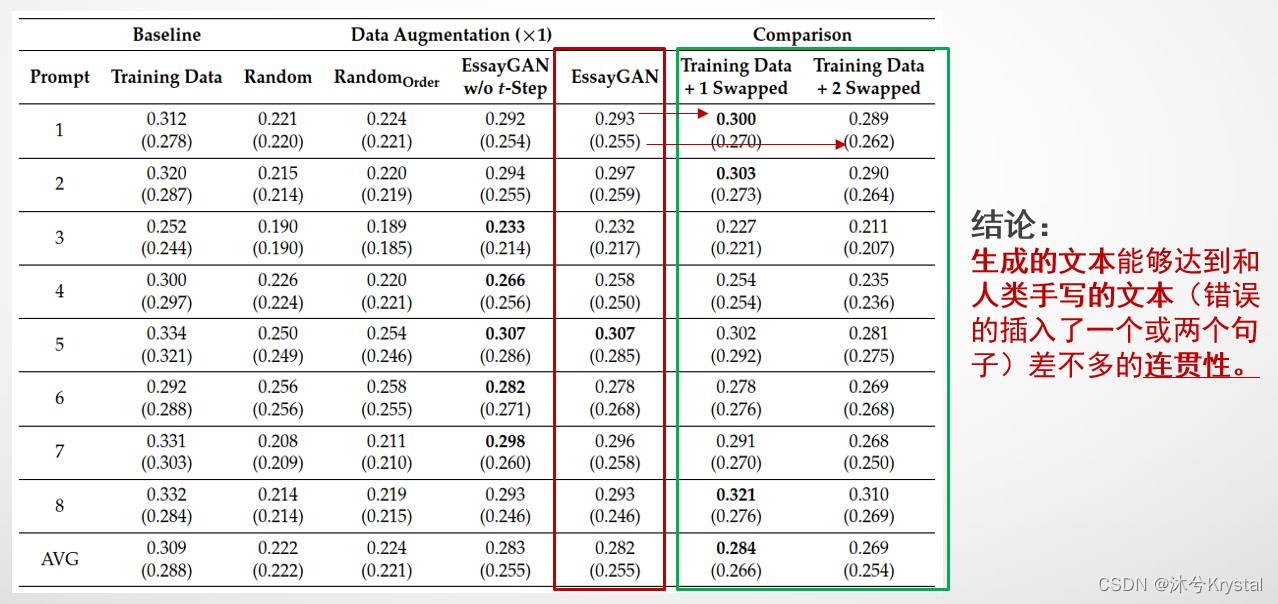
- 实验结果显示使用扩充的文章来进行数据增强有助于提升AES系统的性能。我们得出结论,EssayGAN不仅能产生包含多个句子的文本,并且能够保持文章中句子之间的连贯性。
引言
- 在构建一个边缘的打分系统时候,收集人为打好分的文章的代价很高,这是一个瓶颈。自动数据增强能够作为一个对长期以来缺乏训练数据这一问题的解决方案。
- 传统的GANs包含两个子网络:一个产生假数据的生成器 以及 一个用于区分真实数据和假数据的鉴别器。GAN的核心想法是在鉴别器和生成器之间做一个min-max game,比如说对抗训练。生成器的目标是产生鉴别器相信是真的的数据。
- 为了产生具有不同的分数的文章,EssayGAN有多个生成器和一个鉴别器。每个生成器只致力于产生某个分数的文本。生成器被训练用来区分真实和生成的文本。
- 总体而言,用GAN来生成文本,包含从一集合的预定义好的tokens中,预测下一个token,来产生最真实可信的文本。沿用同样的脉络,我们将文本生成考虑成,基于一集合预先选择好的句子的,一系列的对下一个句子的预测操作。
- 对于EssayGAN为什么对句子进行采样,而不是对token,有两个原因:一个时GAN很难产生长文本,即使是一个前沿的GAN模型也不能才是一篇长度有150-650个词的组织结构很好的文本。另一个是通过从目标分数下的文本中采样句子,能够使得更加容易得创作出对应于这个特定分数的文本。
相关工作
CS-GAN和SentiGAN
- 一些研究是基于整合额外的类型信息到GANs中,有两个主要的方法来处理GANs中的类别信息。辅助分类器GAN(ACGAN,Auxiliary classifier GAN)是其中一个最流行的类别数据生成的架构。ACGAN在鉴别器上部署了一个分类层。一个生成器被训练用来最小化通过鉴别器和分类器计算的损失。另一个是采用多个生成器,每个生成器对应于一个类别。SentiGAN是一个有着多个生成器的代表。
- 在文本生成中,类别句子GAN(CS-GAN),它是一个ACGAN,把类别信息整合进GAN来合成具有类别分类的句子。CS-GAN开发了长短期记忆网络(LSTM,long short-term memory),它是句子生成的最常用的方法。在CS-GAN中,一个强化学习的梯度方针被用来更新生成器的参数。
- SentiGAN包含多个生成器和一个多类别的判别器。SentiGAN被设计用来产生具有不同情感标签的文本。它的鉴别器是一个多类别的分类器,该分类器具有k个类比和一个附加的假类别。
基于预训练模型的自动作文评分
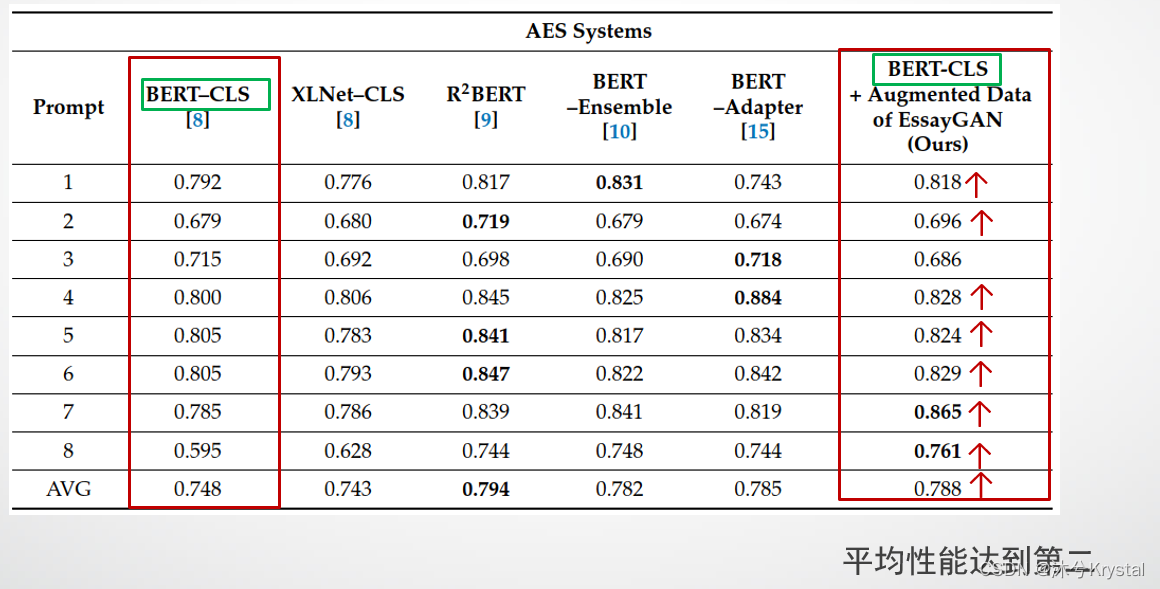
- XLNet是一个预训练的模型,它通过消除预训练数据中的mask tokens来减少预训练和微调之间的差异。相反地,它产生自回归的预训练方法,它通过排列输入的序列,来使得模型能学习到双向的上下文。
- 一个叫做多损失(multi-loss)的新方法被提出用来微调AES任务的BERT模型。它的最终层输出两个结果:一个回归分数和一个排序。那么,所有的权重在微调的过程中是根据回归和排序损失的结合来更新的。在训练过程中,回归损失的重要性增加,排序损失的重要性减少。
- 预训练模型的适应器模块被提出,不是微调整个模型,二十冻结模型的一部分,并且更新只几千的参数来达到优秀的性能。适应器模块利用预训练模型的大量的知识,以及相对少的微调来达到高的性能表现。
EssayGAN
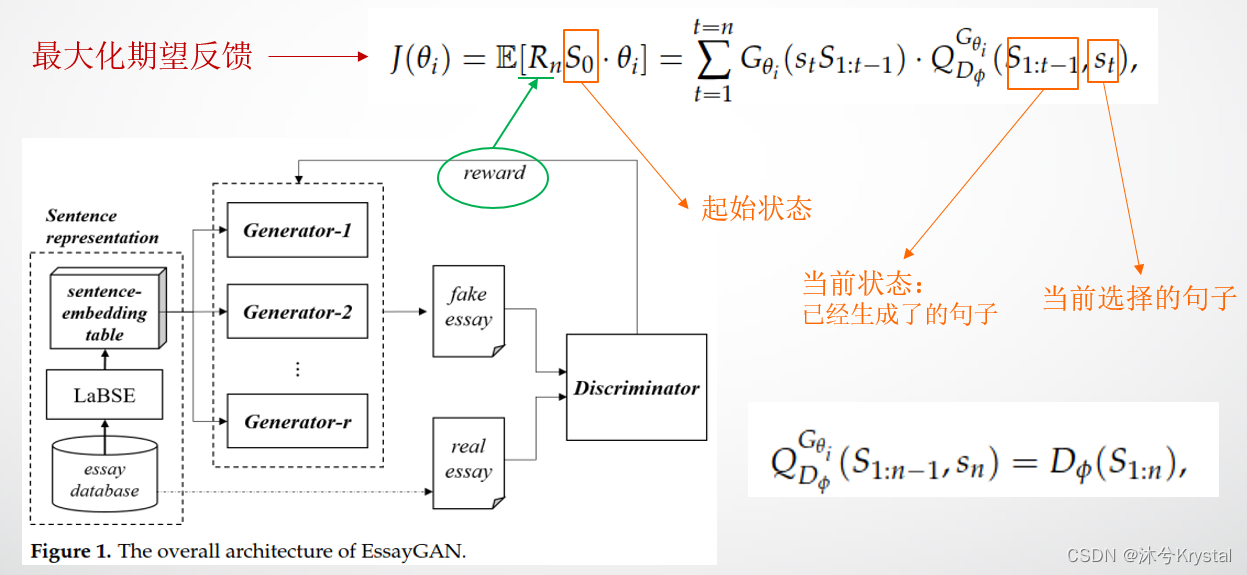
- EssayGAN从一个句子集合中采样句子来创作一篇新的文章。
- 假设文章被 r r r 个评分段/等级来打分,那么我们使用 r r r 个生成器和 1 个鉴别器。
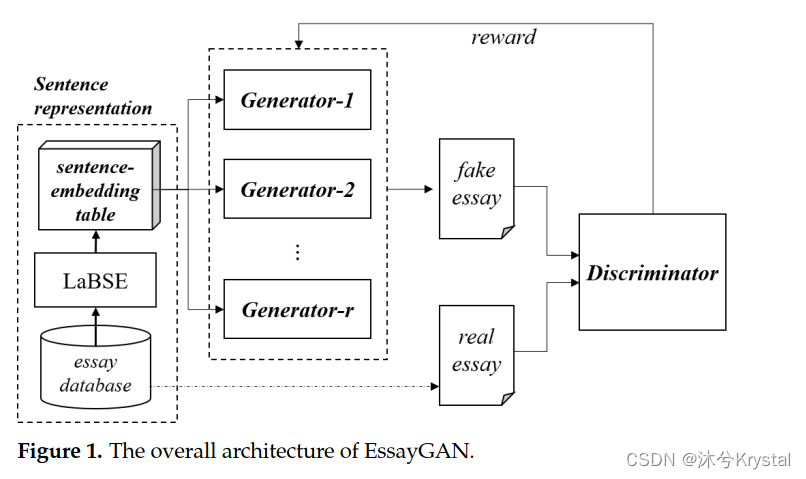
- 第 i i i 个带有参数 θ i \theta _i θi的生成器 G i G_i Gi,表示为 G θ i G_{\theta _i} Gθi,并且带有参数 ϕ \phi ϕ 的鉴别器被表示为 D ϕ D_{\phi} Dϕ。第 i i i 个鉴别器的目标是产生能够被评估为分数为 c i c_i ci 的文本。每个生成器 G θ i G_{\theta _i} Gθi 产生一篇假文本来欺骗鉴别器 D ϕ D_{\phi} Dϕ,鉴别器辨别真和假的文本。
- 我们应用了一个增强学习的方法来训练生成器。鉴别器的输出分数被反馈给生成器。
句子表示
- 由于 EssayGAN 把句子作为它们的输入,每个句子需要被表示为一个单独的嵌入向量。
- 采用语言不可知(language-agnostic)的BERT句子嵌入(LaBSE),它能够产生对于109种语言的跨语言的语言无关的句子嵌入。
鉴别器
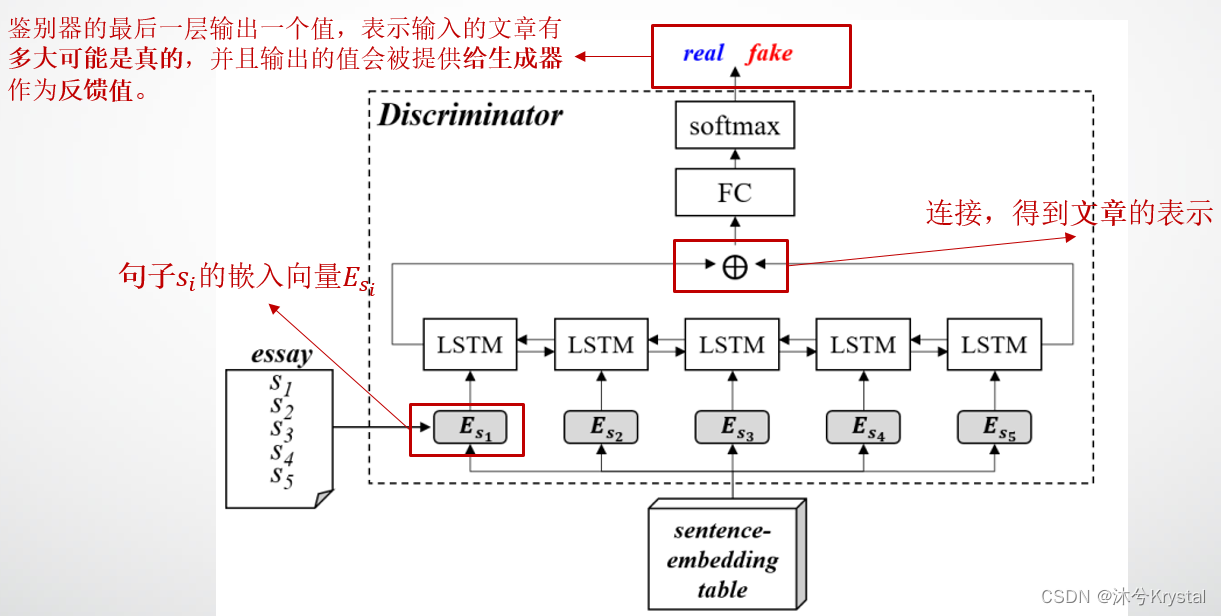
- 鉴别器的目标是区分人类写的和生成器创作的文章。
- 鉴别器的构建是基于双向LSTM网络的。通过查询向量表,第 i i i 个句子 s i s_i si
被转换为 一个嵌入向量 E s i E_{s_i} Esi。 - 句子嵌入被馈入LSTM的隐藏层,第一个和最后一个隐藏状态会被连接成一篇文章表示。鉴别器的最后一层输出一个值,表征输入的文章有多大可能是真的。并且输出的值会被提供给生成器作为反馈值。
生成器与增强学习
- 下图是第 i i i个生成器,它被分配生成打分为 c i c_i ci的文章。
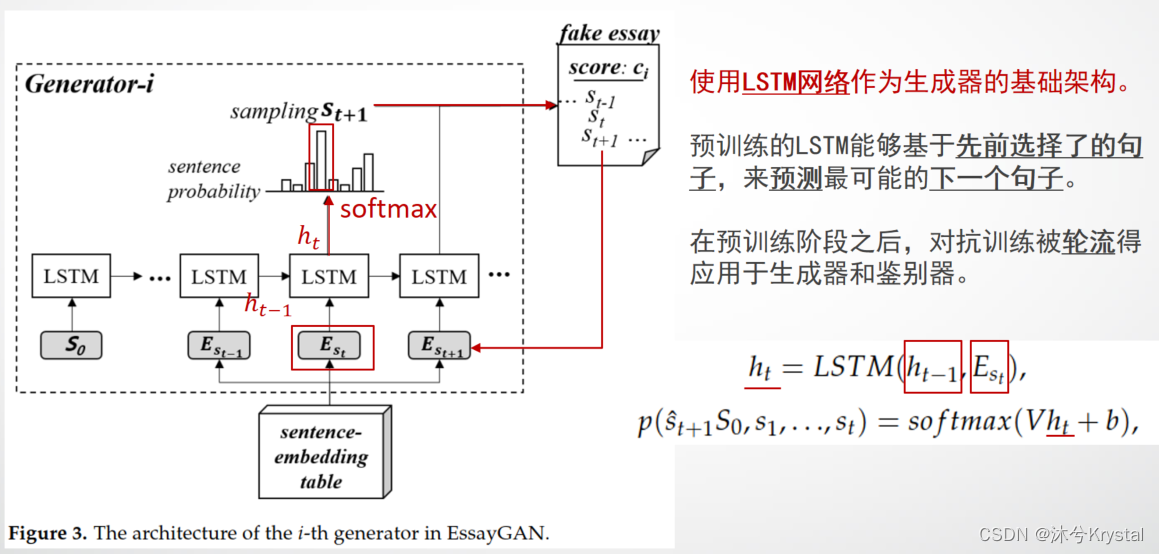
- 我们使用LSTM网络作为生成器的基础架构。LSTM网络最初是使用训练数据集采取一个句子级别的语言模型进行预训练的,并且采用了一个常规的最大似然估计方法。这样,预训练的LSTM能够基于先前选择了的句子,来预测最可能的下一个句子。在预训练阶段之后,对抗训练被轮流得应用于生成器和鉴别器。
- 每个LSTM单元的输出层有和句子级别的独热向量一样的维度,它能够标识一个特定的句子。每个LSTM单元的隐藏层输出 h t h_t ht 被递归的定义如公式(1),并且LSTM预测的句子能够被定义如公式(2):
h t = L S T M ( h t − 1 , E s t ) ( 1 ) p ( s t + 1 ^ ∣ S 0 , s 1 , . . . , s t ) = s o f t m a x ( V h t + b ) ( 2 ) \begin{array}{cr} h_t=LSTM(h_{t-1},E_{s_t})&(1)\\ p(\hat{s_{t+1}}|S_0,s_1,...,s_t)=softmax(Vh_t+b)&(2) \end{array} ht=LSTM(ht−1,Est)p(st+1^∣S0,s1,...,st)=softmax(Vht+b)(1)(2) - 下一个句子是通过基于期望概率的随机采样来选择的。
- 在应用对抗训练来文章生成的时候有一个障碍:鉴别器只能对一整篇文章提供一个反馈值,但是生成器需要在每一个采样步骤时得到不完整的文章的反馈值。这样,为了在每个采样步骤对生成器给予反馈,我们在评估下一个位置句子的时候应用了蒙特卡洛搜索来给出一篇完整的文章。
- 第 i i i 个生成器 G i G_i Gi 使用鉴别器 D ϕ D_{\phi} Dϕ 提供的反馈,采用REINFORCE算法的方式进行更新。生成器的目标是最大化期望的反馈。 R n R_n Rn 是一整篇长度为 n n n 的文章的反馈。 Q D ϕ G θ i ( s , a ) Q_{D_{\phi}}^{G_{\theta _i}}(s,a) QDϕGθi(s,a) 是一个序列的行动值函数,比如说,期望的累计反馈从状态 s s s 开始,之后采取行动 s s s,并且遵循 G θ i G_{\theta _i} Gθi的方式。


实验结果
训练EssayGAN和数据集
- 对抗训练算法

- 数据集:ASAP数据集,8个话题(prompts)
- 分数范围的处理:
采用一个分区模型,将分数离散化为几个分区。比如,分数范围为0-60,将其离散化为5个分区0,1,2,3,4。
扩充文本的特征
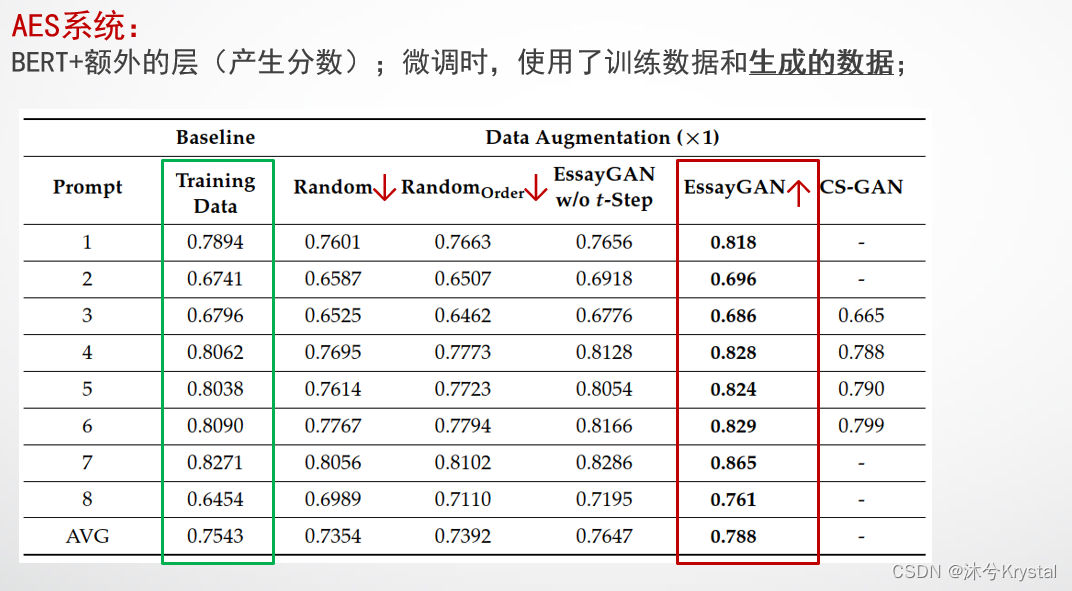
- 我们设置了两个baseline模型来做数据增强,来与EssayGAN做比较。 R a n d o m Random Random 是一个数据增强模型,它通过随机组合选择的句子来产生新文本。
- 训练数据集中的每篇文本中的所有句子都被假设是有序编号的。 R a n d o m O r d e r Random_{Order} RandomOrder 通过以非降序的顺序收集句子来产生文本,来保证句子之间最低的连贯性。
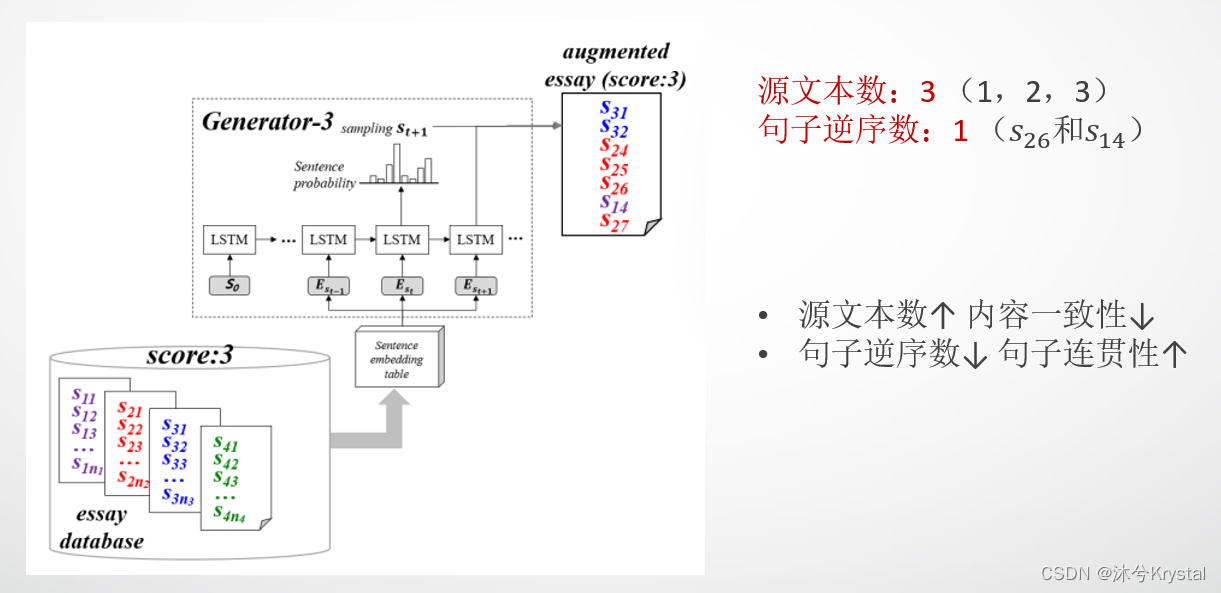
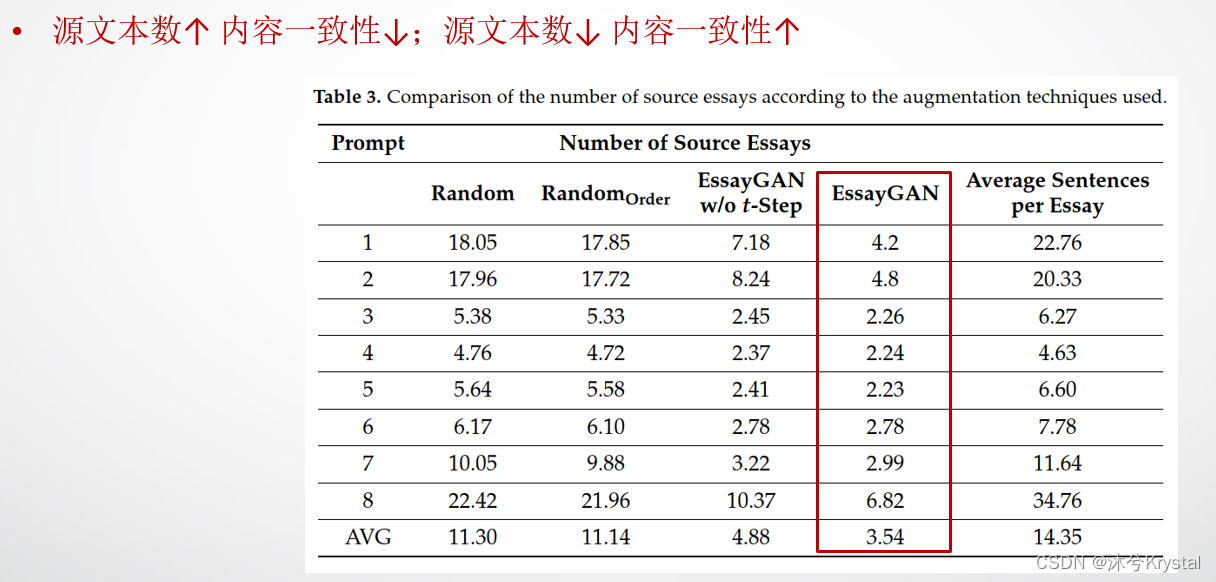
- 源文本数:如果一个新生成的文本的源文本数太多,那么它的内容一致性就会降低;
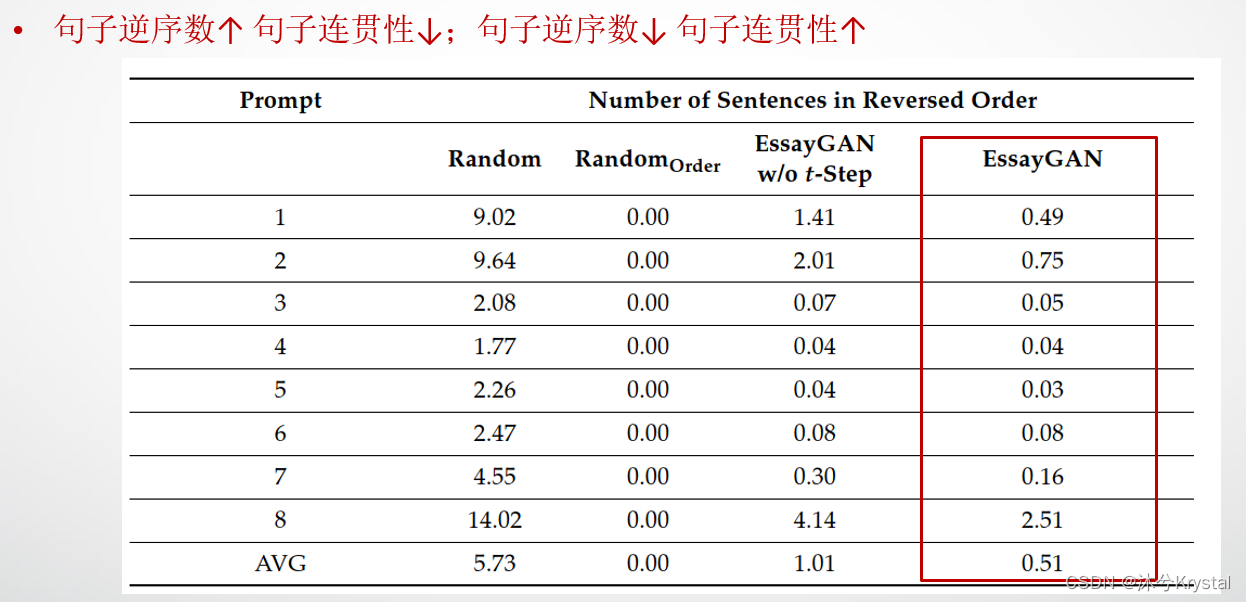
- 句子逆序数:如果新产生的文本的句子逆序数很少,那么文本的连贯性就会更高。
- 一个更加显式的指标来检验扩充文本的连贯性。语义相似度衡量了一篇文本内的语义相似度。

实验结果
- 以下实验的目的是展示产生的文本作为训练数据是否对AES系统有用。













![[简易的网站登录注册,注销退出操作]](https://img-blog.csdnimg.cn/5b9346d144ea4997b9d1cc984866b0a1.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5bCP5pm6UkUw,size_17,color_FFFFFF,t_70,g_se,x_16)