本文主要内容
-
介绍一篇大模型推理加速综述论文,简单说明了LLM推理加速的基本内容。
-
介绍了推理阶段的prefilling(主要方向:计算优化)和decoding(主要方向:内存优化)差异。
-
prefilling优化方面,针对流行的FlashAttention和PagedAttention和Lmdeploy等优缺点进行了详细讲解。
-
decoding优化方面,主要有多token预测、降低kv cache等方法。
A Survey on Efficient Inference for Large Language Models
Transformer模块主要由Attention+MLP/MOE组成。
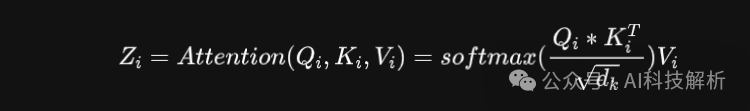
attention
-
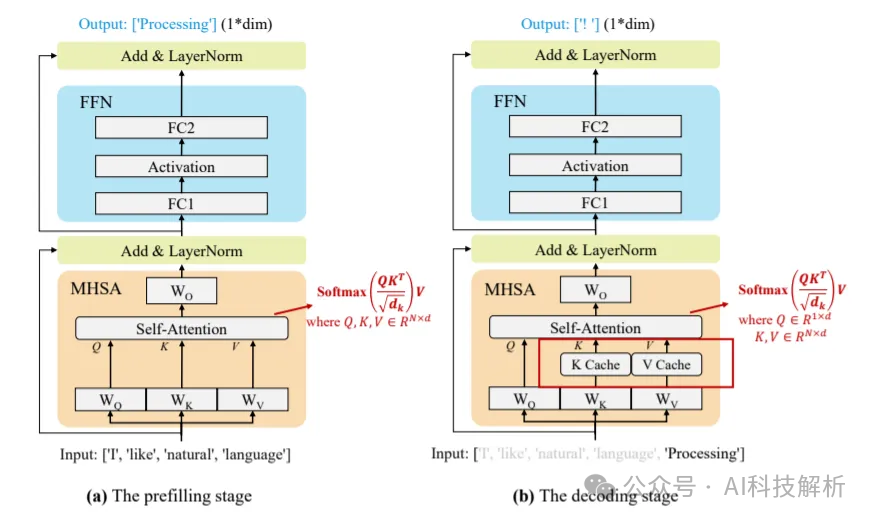
prefilling:大模型计算全部的prompt,生成第一个token,并存储所有的KV缓存。
-
decoding:输入前面生成的单个token,利用KV缓存一起计算出下一个token,将当前token计算出的新kv值添加到kv缓存队列中。循环当前步骤,直至当前输出的token等于截至token或者生成的token总数目到达输出上限。
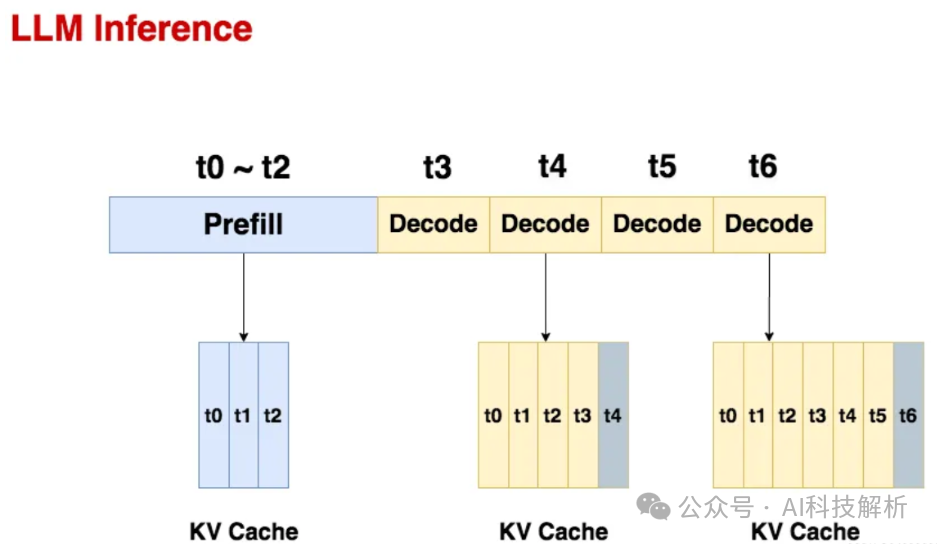
llm inference
存储kv cache是为了避免重复计算。
LLM性能指标有
-
Time to First Token (TTFT):prefilling阶段耗时
-
Time-Per-Output-Token (TPOT):每次decoder阶段平均耗时
-
Latency:生成总耗时=TTFT+TPOT*生成的token数目
-
throughput:生成的token数目/Latency
-
Model memory:模型内存
-
Peak Momery:峰值内存=模型内存+kvcache
LLM推理时的Memory和Latency变化
问题:随着context的增加,内存消耗和计算速度都会平方级增加。
模型在小bs*短seq情况下,会出现传输瓶颈,当数据量增大到一定程度,会碰到计算瓶颈。
极市开发者平台-计算机视觉算法开发落地平台-极市科技
推理优化
-
数据优化:prompt总结、压缩、检索
-
模型优化:1、GQA、GLA、MOE等;2、量化、蒸馏等
-
系统优化:vllm、lmdeploy、tensorRT等
1、数据优化
prompt总结、压缩、检索(RAG)。其中RAG用的最多,其他都用的很少。
akaihaoshuai:从0开始实现LLM:4、长上下文优化(理论篇)
2、模型级别优化
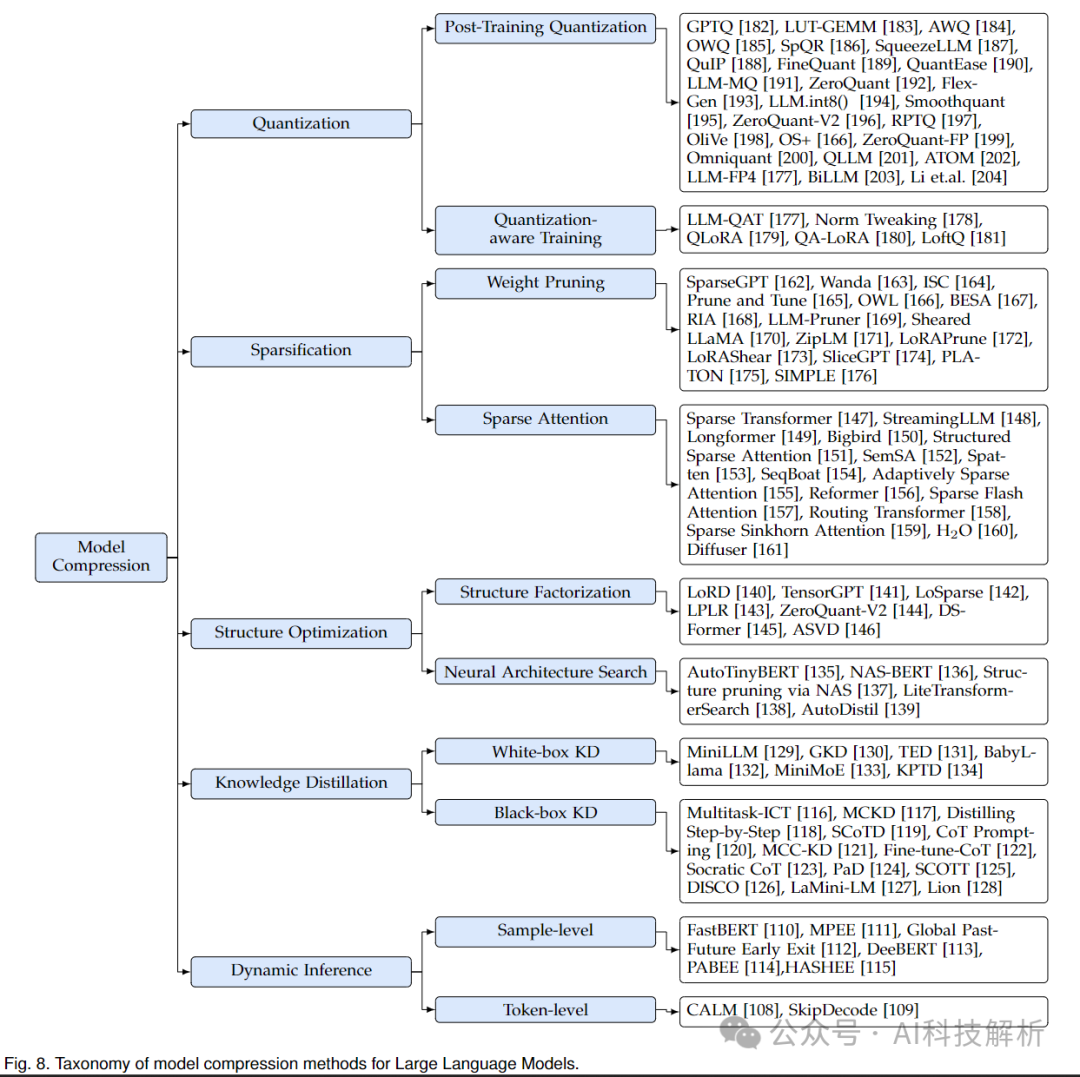
模型压缩方法总览
2.1、架构优化
架构上来说,主要是针对Attention和FFN进行优化。
-
Attention:MHA->MQA->GQA->MLA等。
-
FFN->MOE
模型的耗时分布如下图所示

推理耗时
FFN在大模型中贡献了很大一部分模型参数,这导致显著的内存访问成本和内存使用,特别是在解码阶段。例如,FFN模块在LLaMA-7B模型中占63.01%,在LLaMA-70B模型中占71.69%。
还有稀疏Attention、线性Attention,其他更大的架构变化还有KAN、megalodon、mamba等
架构调整需要重新训练LLM,耗时耗力,只有头部公司在做。剩下99%的公司都在pretrained model上做SFT和RLHF,无法修改预训练模型的结构。剩下比较好用的就是量化、剪枝、蒸馏等。其中相对来说量化最成熟,用的最多的有GPTQ和AWQ。
2.2、量化
akaihaoshuai:从0开始实现LLM:6、模型量化理论+代码实战(LLM-QAT/GPTQ/BitNet 1.58Bits/OneBit)akaihaoshuai:从0开始实现LLM:6.1、模型量化(AWQ/SqueezeLLM/Marlin)
量化可以大幅减少模型体积,但由于引入了反量化操作,计算量有所增加,在小bs+短token场景下(传输瓶颈),速度更快。在大bs和超长token场景下(计算瓶颈),反而比非量化更慢。其中vllm中的量化效果一般,Lmdeploy的量化速度很快。LMdeploy加速效果略好于TensorRT-LLM。底层都是基于FasterTransformer。
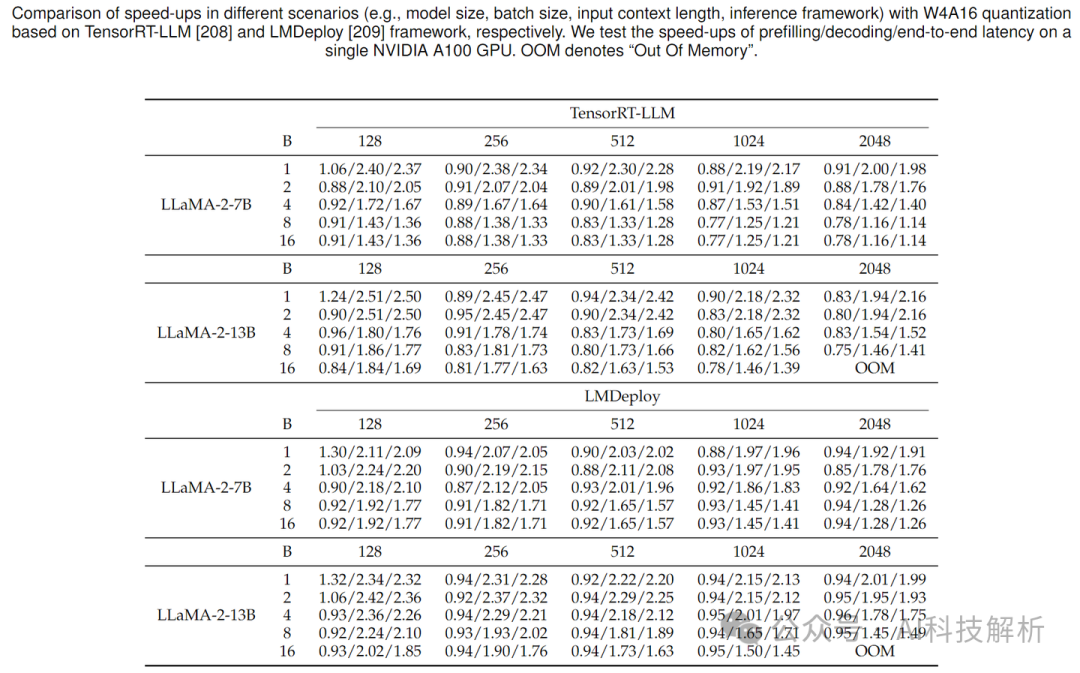
由图可看出,prefill阶段加速比基本在0.9~1之间,变化不大。decoding阶段加速比可在2倍左右。
3、系统级别优化
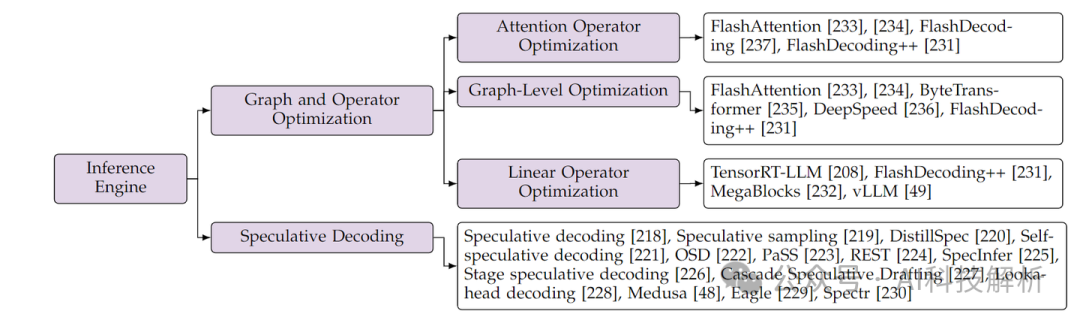
系统级别优化是工程性优化,主要是算子合并、加速、多卡并行、内存管理等方面进行优化。主要有FlashAttention、PagedAttention、FlashDecoding和continues batching等。后面会详细讲解。
Prefill vs decoding
以 Llama2-7B(4096 序列长度,float16精度)为例,计算一下 batch_size = 1的理想推理速度。
-
Prefilling:假设 prompt 的长度是 350 token,那么预填充所需要的时间 = number of tokens * ( number of parameters / accelerator compute bandwidth) = 350 * (2 * 7B) FLOP / 125 TFLOP/s = 39 ms(A10)。这个阶段主要是计算瓶颈。
-
decoding:time/token = total number of bytes moved (the model weights) / accelerato r memory bandwidth = (2 * 7B) bytes / (600 GB/s) = 23 ms/token(A10)。这个阶段的瓶颈是带宽。
大语言模型(LLM)推理性能优化以及推理框架、后端的评测 · Issue #107 · ninehills/blog
prefilling阶段的计算效率要高很多。prefilling数据量较大,更容易遇到计算瓶颈,这时候的优化方向是算子合并、简化等,降低模型计算量。
decoding时query长度为1,数据量小,更容易遇到传输瓶颈,这时候的优化主要为kv cache的访问优化,比如tile计算和cache量化等。
回旋托马斯x:FlashAttention:加速计算,节省显存, IO感知的精确注意力
DistServe多卡解耦prefill和decode优化
prefilling阶段对计算资源的需求量极大,哪怕是小批次的预填充任务,甚至单个较长的预填充任务,都足以使GPU的计算能力达到饱和。与此相对,解码任务则需要更大的批大小才能充分利用计算资源。
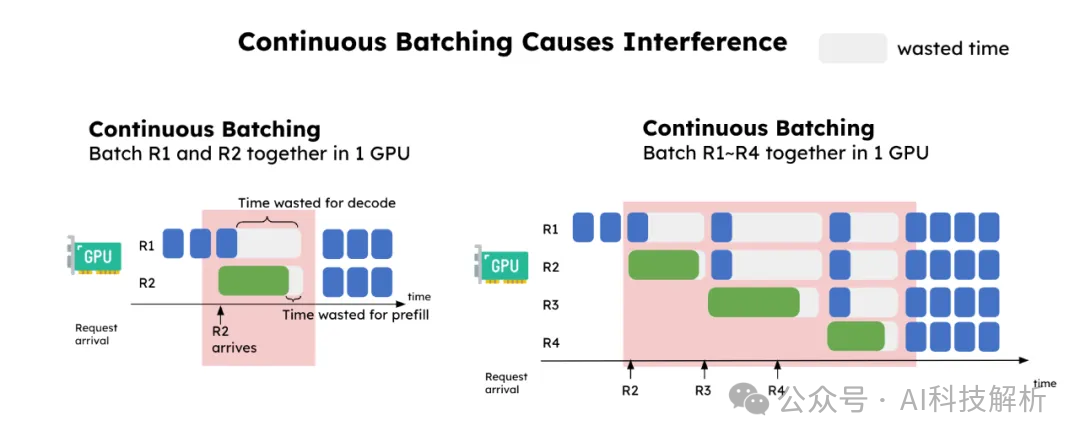
如上图所示,连续批处理任务中,prefill任务R2的加入,显著增加了decoding任务(R1)的时延,并略微增加了预填充任务(R2)的时延。处于解码阶段的请求在每次预填充请求进入系统时都会“卡住”,因此意外地增加了解码任务的时延。因此,将预填充和解码解耦到不同的GPU中,并为每个阶段定制并行策略。这自然解决了上述两个问题:
-
预填充和解码之间没有干扰,使得两个阶段都能更快地达到各自的SLO。
-
资源分配和并行策略解耦,从而为预填充和解码量身定制优化策略。
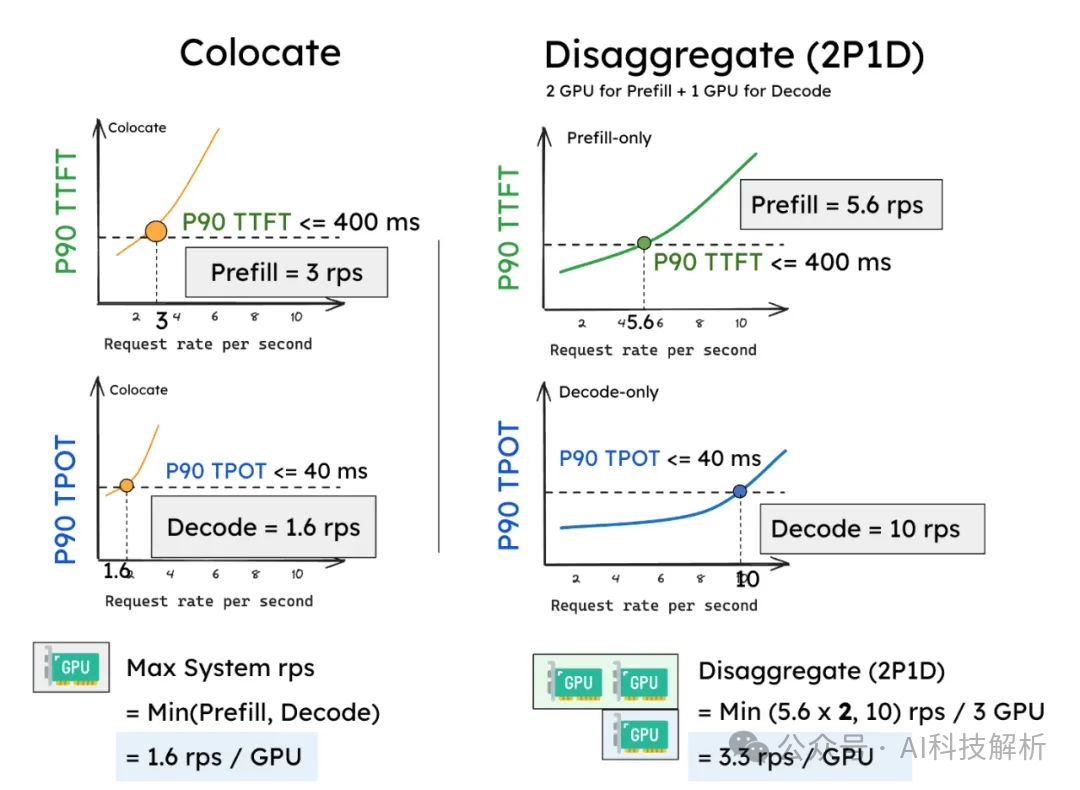
Serving有效吞吐量的最大化实现Throughput is Not All You Need: Maximizing Goodput in LLM Serving using Prefill-Decode Disaggregationhttps://github.com/LLMServe/DistServe/tree/main/distserve
预测解码、多token解码等
既然decoding的多次迭代耗时,那么自然而然的一个想法就是减少迭代次数。所以有个下面这篇一次预测多个token的论文。(需要修改模型架构)
next-token被淘汰!Meta实测多token训练方法,推理提速3倍
根据模型参数越小,速度越快。prefill速度比多次decode更快的结论。也可以通过小模型对prompt生成结果(prefilling+decoding),再将prompt+结果一起输入大模型(prefilling),达到加速目的。(ps:这个不一定能快多少,但是用不好的话会慢不少。。。)
Accelerating Large Language Model Decoding with Speculative Sampling
KV Cache Compression
https://github.com/opengear-project/GEAR/tree/main
GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM
GEAR通过三种互补技术来分解和压缩KV矩阵:
-
使用统一量化将大部分相似幅度的条目压缩到极低精度(如4位)。
-
使用低秩矩阵来有效近似量化残差。
-
引入稀疏矩阵来纠正异常条目的个别误差。
内存压缩可以降低kvcache内存,提高decoding效率。
draft模型和原始模型联合推理
创建一个小的draft模型,借助draft模型快速推理初始结果,将prompt和初始结果一起输入原始大模型做判别,充分利用了小模型速度快,prefill阶段比decoding阶段计算效率高的特点,也可以对模型进行加速。
Paper page - Distributed Speculative Inference of Large Language Models
continues batching/In-Flight Batching
Continuous Batching:一种提升 LLM 部署吞吐量的利器
现实情况比这个简化模型更复杂:因为预填充阶段需要计算,并且与生成阶段的计算模式不同,因此它不能很容易地与令牌的生成一起进行批量。 vllm的实现为:每次迭代前都会从request数据中查找还在运行的request和新收到的request,整理到一个大batch中。每次迭代结束会判断是否有request满足结束条件,若满足则标记为finished,不再处理。 由于不同batch的状态不同,为了减少pad的内存和计算浪费,最终处理时会将其整理成bs=1的超长total_seq序列,因为根据矩阵乘法,无论是(bs, seq)还是(1, bs*seq),linear层结果均完全相同,LN层也是。
FlashAttention分析
GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention
通过tile计算降低attention模块的数据传输量,提高模块效率。其cuda实现针对大batchsize有明显提升,小bs场景下提升不明显。详细原理网上有很多教程,这里不再赘述。
主要在于矩阵的拆分和softmax的拆分。
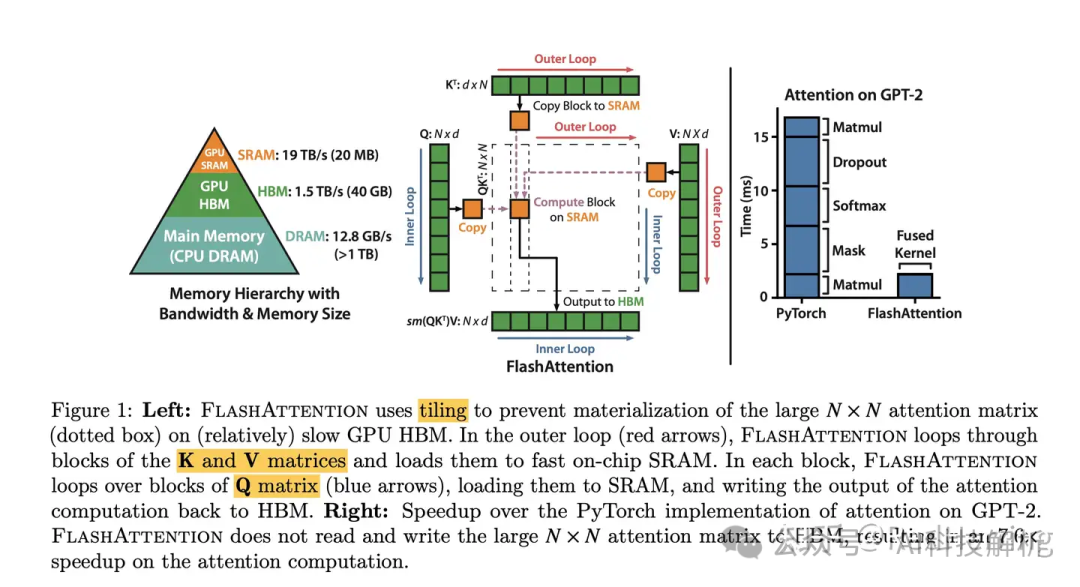
flash attention V1 V2 V3 V4 如何加速 attention
GPU内存图如下。从共享内存中访问数据比从全局内存中访问要快很多。
具体计算公式推导可参考:如何评价flashattention最新更新flash decoding,推理性能提升8倍?
代码逻辑
vllm只在所有的prompt都位于prefilling阶段时使用FlashAttention,在decoding阶段使用PageAttention(因为FlashAttention无法访问不连续的kvcache)。vllm输入时会将所有的seq合并到一起,并记录每一个prompt的起始位置、生成token的长度等状态。
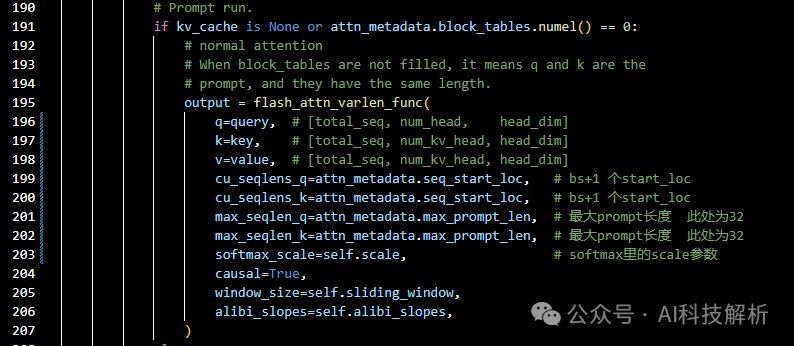
这里判断当block_tables为0,也就是全部数据都没有kvcache时,才能使用FlashAttention。在flash_attn_varlen_func()->_flash_attn_varlen_forward()函数中,也有要求输入数据qkv的内存连续。
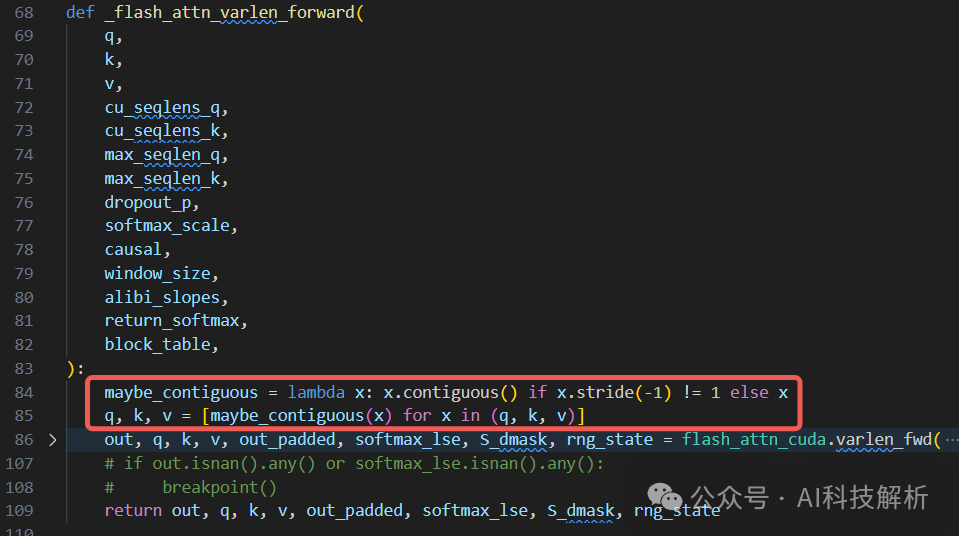
_flash_attn_varlen_forward调用flash_attn_cuda.varlen_fwd()==mha_varlen_fwd()函数,参数备注上有说明,参数的第一个维度是total_len,也就是合并seq的长度。
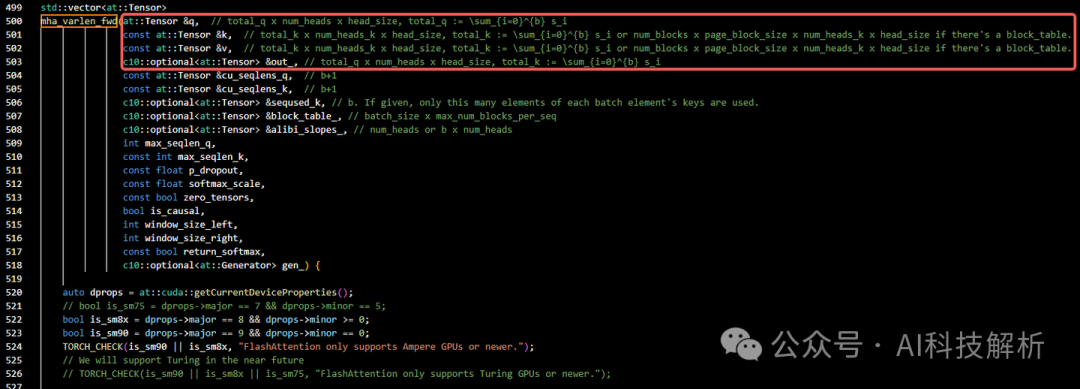
此处实验的模型head_dims=128,因此由run_mha_fwd()->run_mha_fwd_()->run_mha_fwd_hdim128()
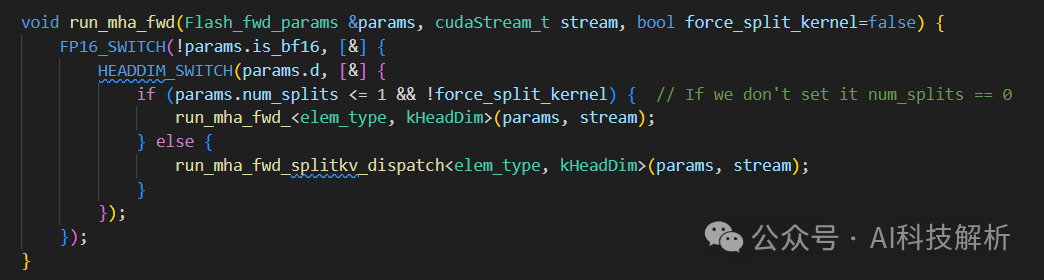
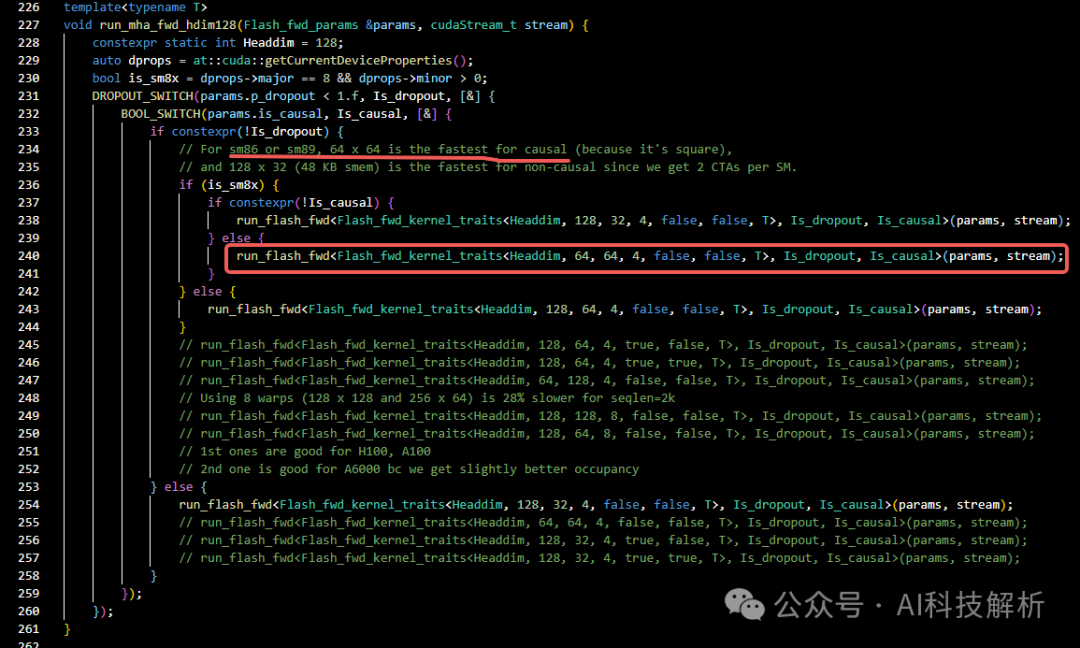
run_flash_fwd函数如下
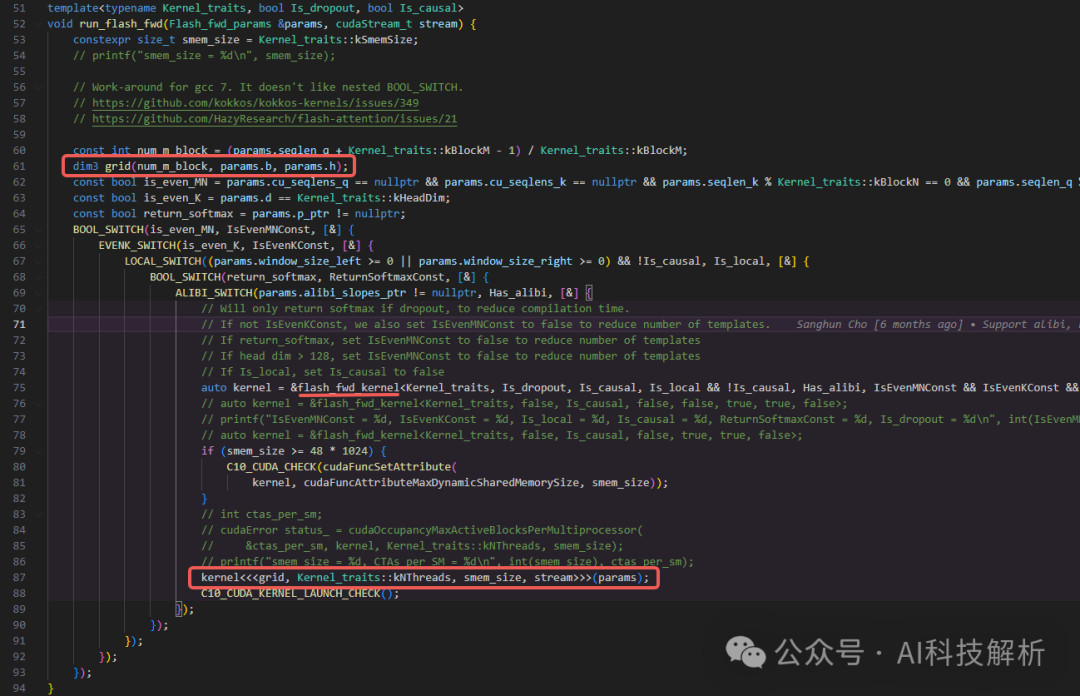
flash_fwd_kernel参数
kernel为flash_fwd_kernel,通常可以理解为一个kernel会开启一个进程,对应一个grid进行管理。同一个grid上的所有线程共享相同的全局内存空间。
grid中可以创建很多block(最大block数量在几亿级别以上,但是建议按需使用。不管1维2维还是3维,使用的总block数量一样的情况下,不同维度创建的位置排布不同,所以访问速度上还是有些差异。因此需要根据数据类型的维度来选择grid的维度)。每个block中又可以创建很多个线程。最终所有线程同时对数据进行处理。
grid参数为(num_m_block, params.b, params.h),代表着分配的block数目总共由num_m_block*params.b* params.h个。
这里的num_m_block为seqlen_q在kBlockM长度上对齐。本次输入的seqlen_q=32,kBlockM=64,那么num_m_block=64。params.b为batchsize,此处取256;params.h为head_dims,此处为128。由此可以看出此时的总共分配了64*256*128=2097152个block。注意:从grid参数中可以看出,batchsize越大,FlashAttention的计算效率越高。这也对应了FlashDecoding中的测试结果:https://crfm.stanford.edu/2023/10/12/flashdecoding.html
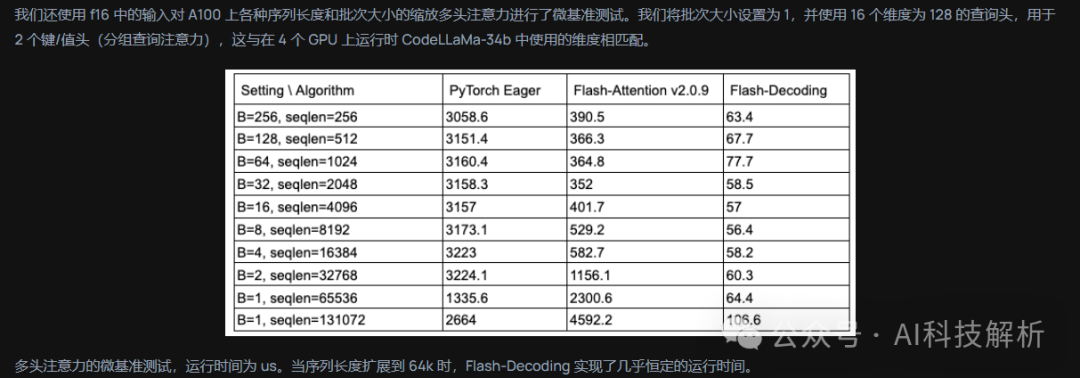
b*seqlen不变时,相同的数据和计算量。pytorch的耗时基本不变,而FlashAttention的耗时随着bs变小而越来越长!!!因此FlashAttention并不适合小批量的推理场景。一个block上的线程是放在同一个流式多处理器(SM)上的。比如在FlashAttention的代码中,kNWarps_为4 or 8,每个Warp是32个线程(每一次最基本调度指令就会执行32个线程),那么每个block会调用128 or 256个线程。而在SM中,通常最大上限为512 or 1024个线程。那么1个SM可以多个block。
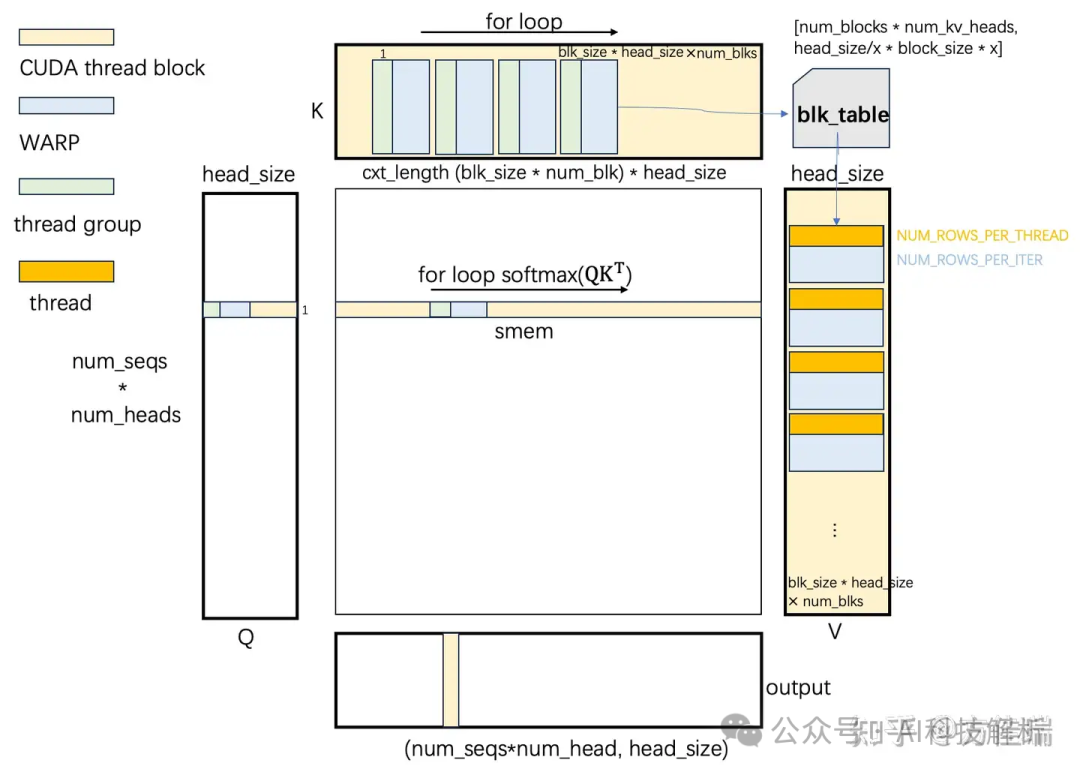
通常不建议线程数设置的太大(128/256足够),具体数量需要根据硬件性能和代码实现进行测试。具体在每个线程中的数据访问索引如下图
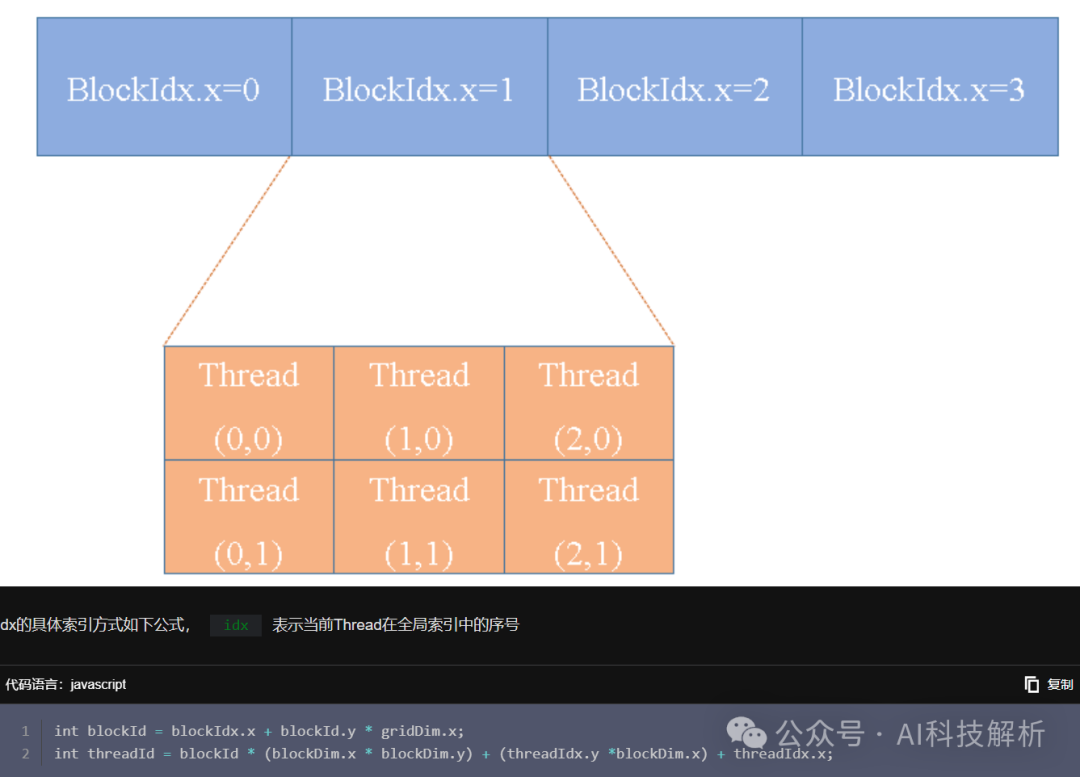
参考:GPU编程2–CUDA核函数和线程配置-腾讯云开发者社区-腾讯云
共享内存设置为kvcache+qcache的大小。访问共享内存比访问全局内存要快得多。然而,共享内存是有限的,过多的使用可能会限制块的最大数量,影响性能。
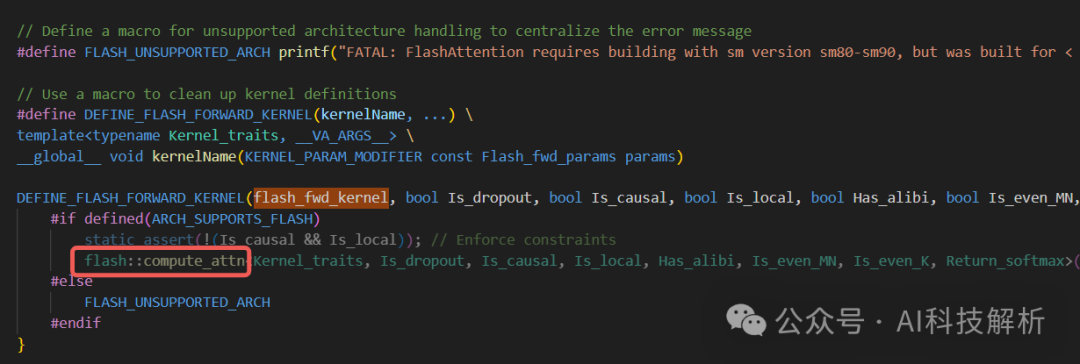
attn的tile计算核心代码
核函数flash_fwd_kernel根据宏定义可知,调用的是flash::compute_attn函数
compute_attn函数调用了compute_attn_1rowblock函数
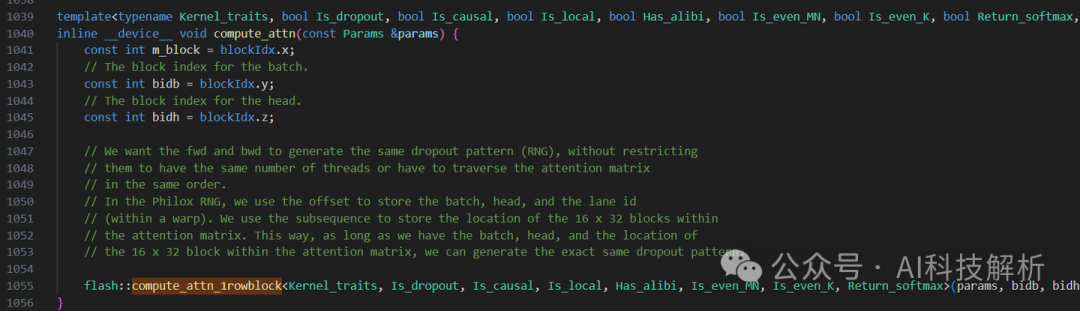
具体内容可参考:进击的Killua:FlashAttention v2核心代码解析(一)
FlashDecoding
FlashDecoding++: Faster Large Language Model Inference on GPUs
因为FlashAttention是对q在seq_len和bs维度上分块的,因此在推理时效率不高。
FlashDecoding就是针对这种场景进行优化:对kv做分块继续并行。
-
首先,我们将k/v分成更小的块。
-
我们使用 FlashAttention 并行计算每个分片的查询注意力。我们还为每行和每个分片写入 1 个额外的标量:注意力值的对数和指数。
-
最后,我们通过减少所有分割来计算实际输出,使用对数和指数来缩放每个分割的贡献。
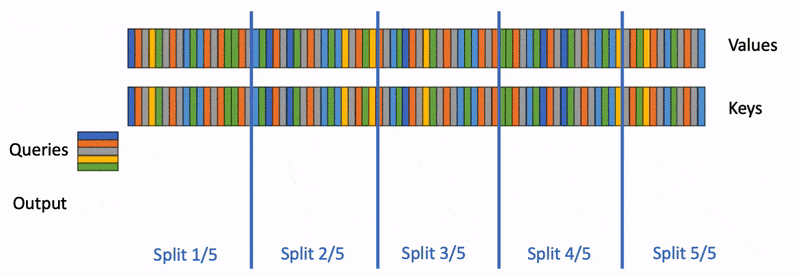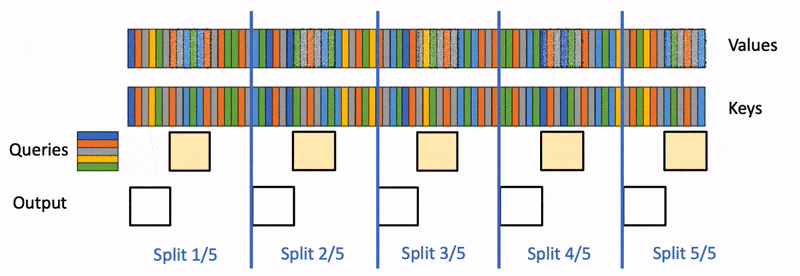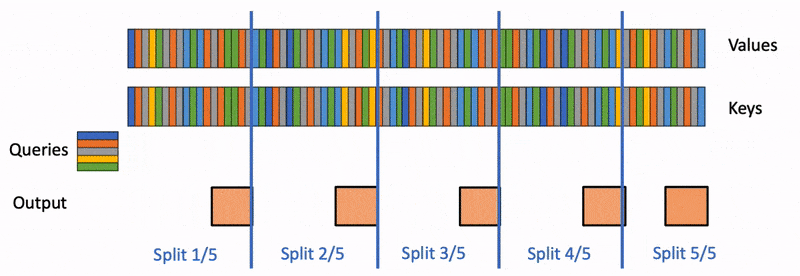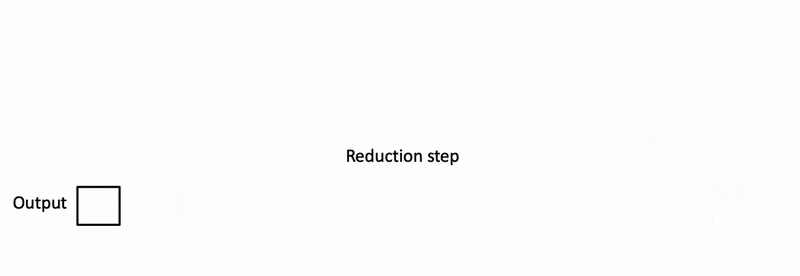
速度对比如下图所示
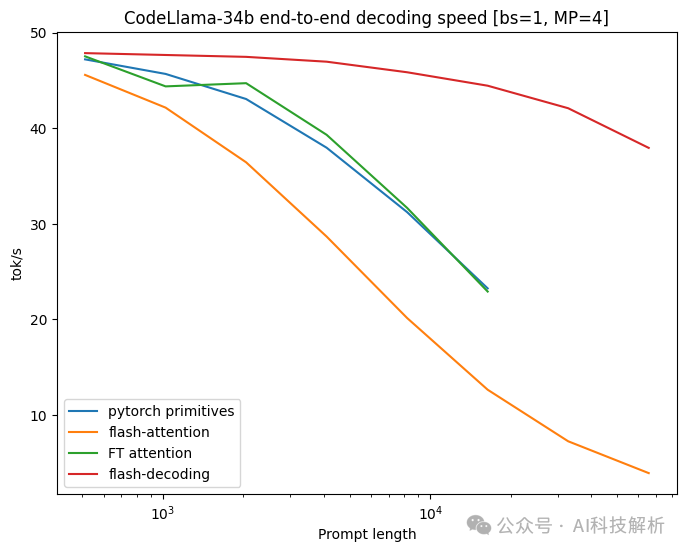
后续还有FlashDecoding++,针对softmax做了优化。
Stanford CRFM如何评价flashattention最新更新flash decoding,推理性能提升8倍?Austin:FlashAttenion-V3: Flash Decoding详解Austin:【FlashAttention-V4,非官方】FlashDecoding++https://arxiv.org/abs/2311.01282
TRT-LLM和PagedAttention V2已集成FlashDecoding。
PagedAttention
针对kv cache在自回归过程中的动态增长场景,通过碎片化内存管理,提高内存利用率。
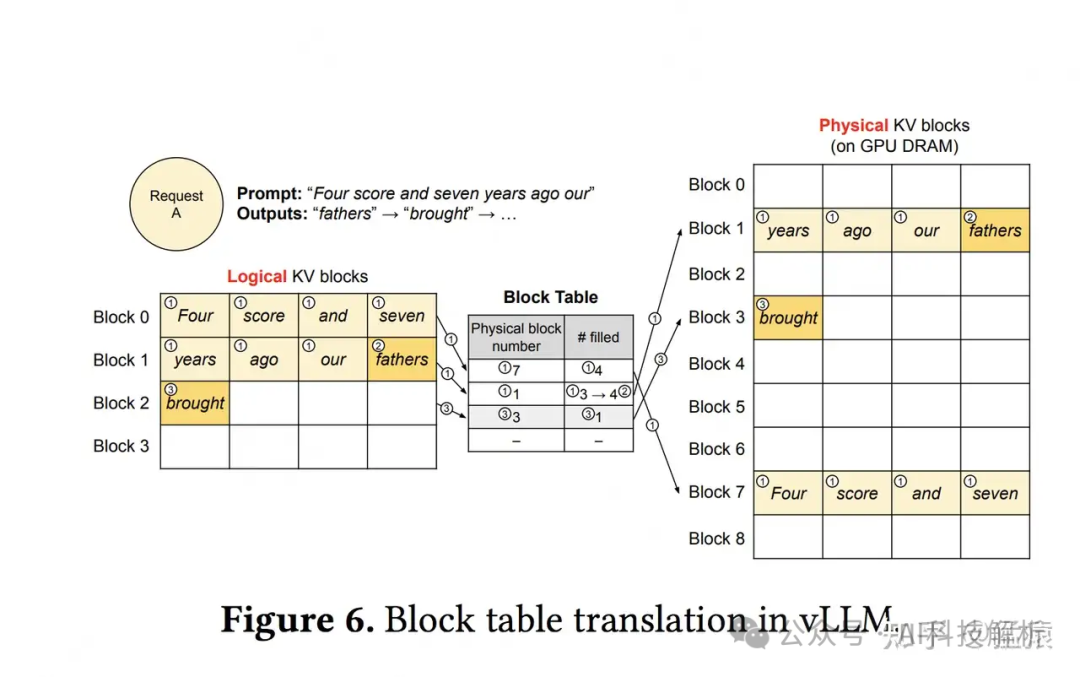
猛猿:图解大模型计算加速系列之:vLLM核心技术PagedAttention原理
缺点也在于内存太碎片,无法一次性读取,长token在Attention模块中计算时,需要多次访问存储在不同区域的kvcache数据,多了内存传输的耗时。长度越长,访问次数越多,内存访问耗时增加的越多。且这种访问方式需要写专门的kernel代码(PagedAttention),无法和FlashAttention通用。
在vllm中,只存在prompt计算时使用FlashAttention,只要有一个seq位于decoding阶段,便只能用PagedAttention。虽然常规长度的prompt场景速度都很快,但测试发现,在超长prompt场景下,耗时会增加特别多。在attention代码中,如果是第一次运行,则设为prompt,调用flash_attn_varlen_func,如果不是,则会调用PagedAttention。
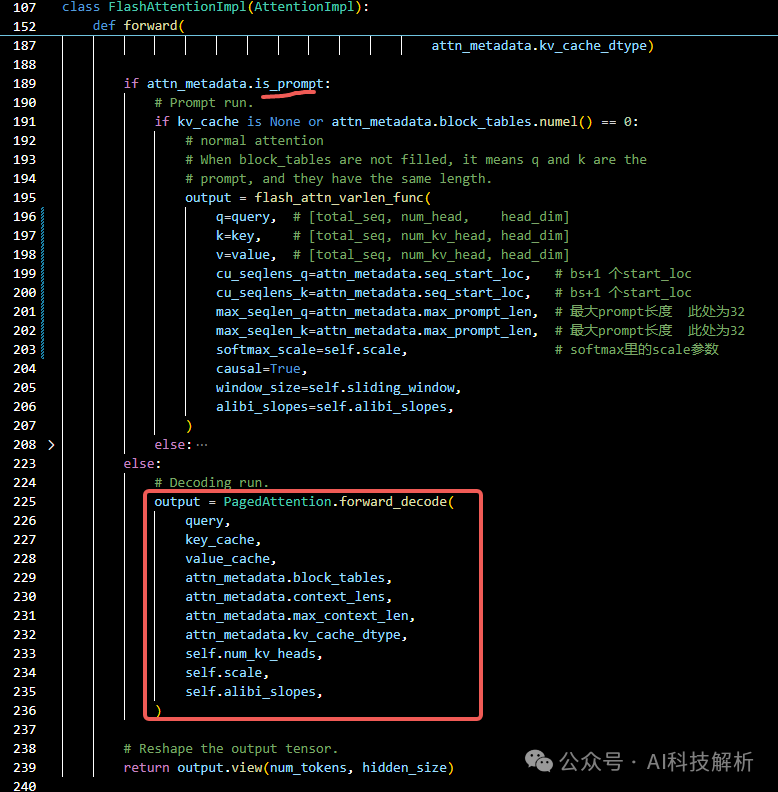
详细代码逻辑可参考:vLLM皇冠上的明珠:深入浅出理解PagedAttention CUDA实现
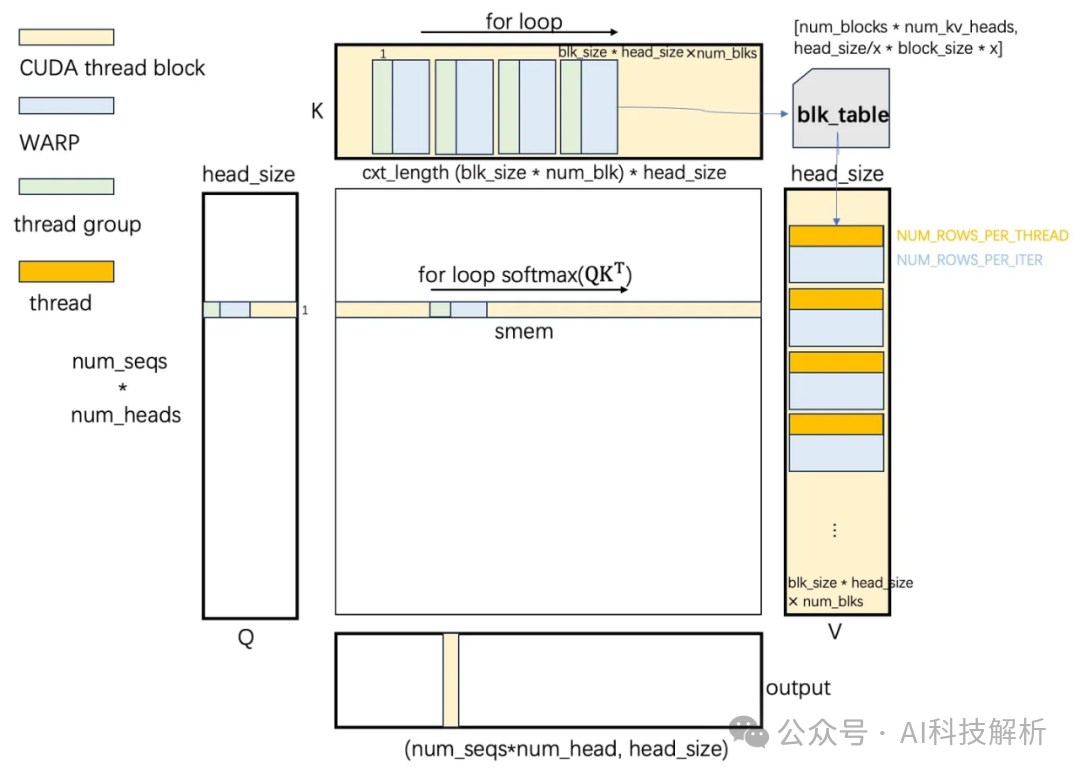
其中softmax分块实现原理如下
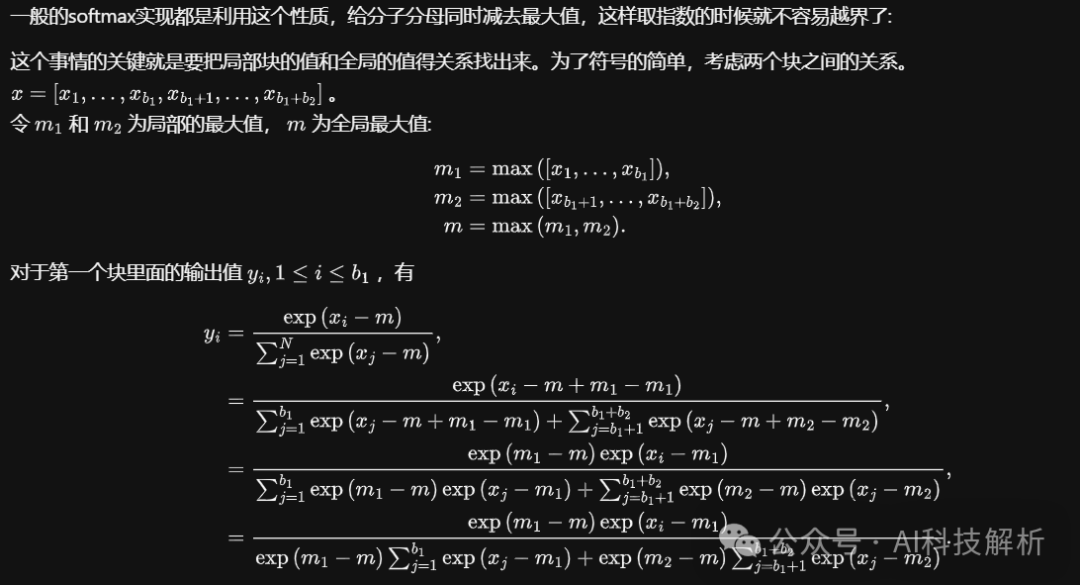
cuda代码实现
for循环k cache的block,找到对应tile的k值,并进行qk相乘
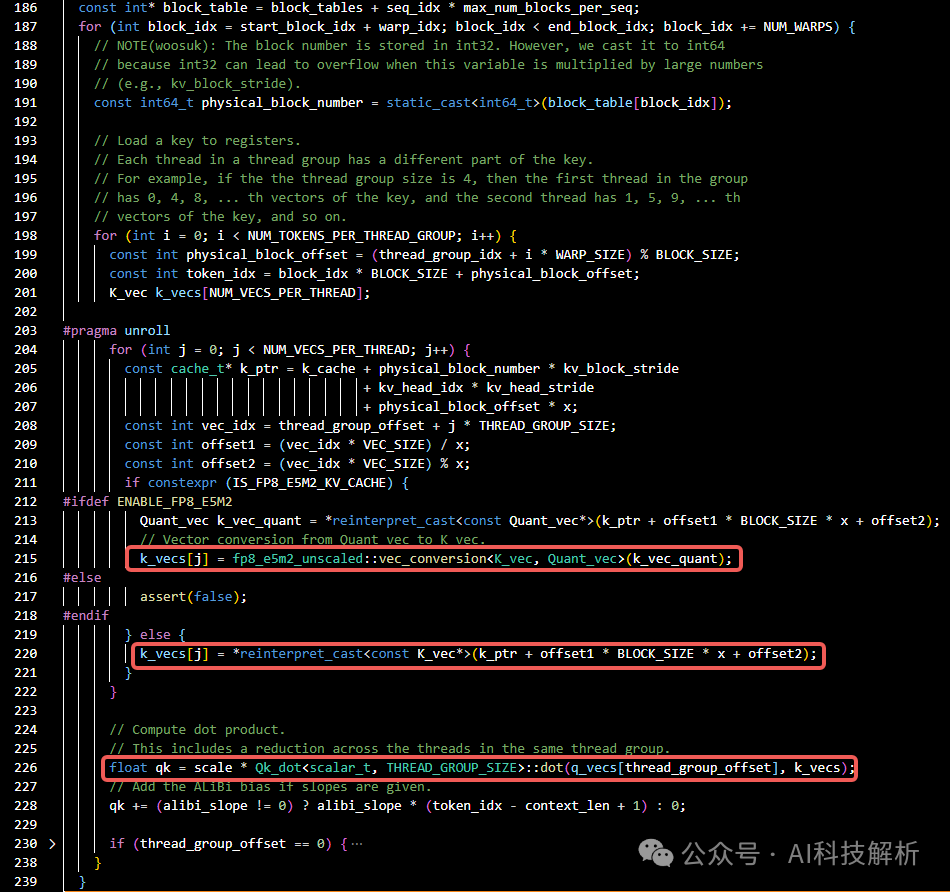
softmax是逐行计算,为防止指数结果数据溢出,一般使用x=x - x_max。分块计算原理如下

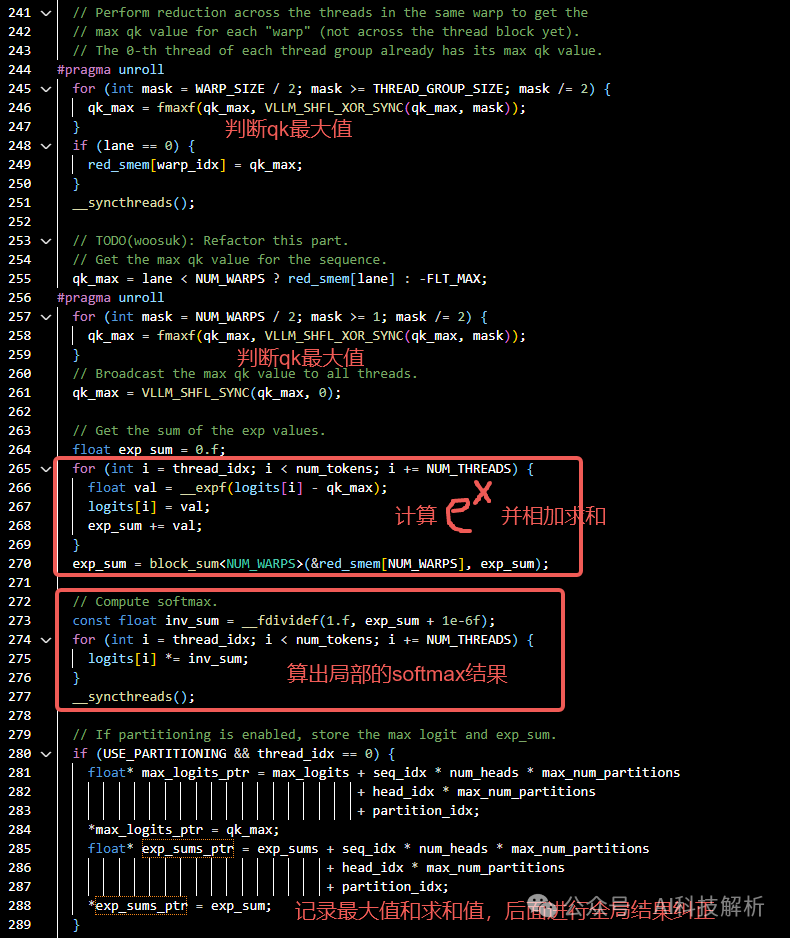
相应代码如下,计算每个tile的softmax结果,并统计局部最大值和累加和,一边后续进行全局结果校正。
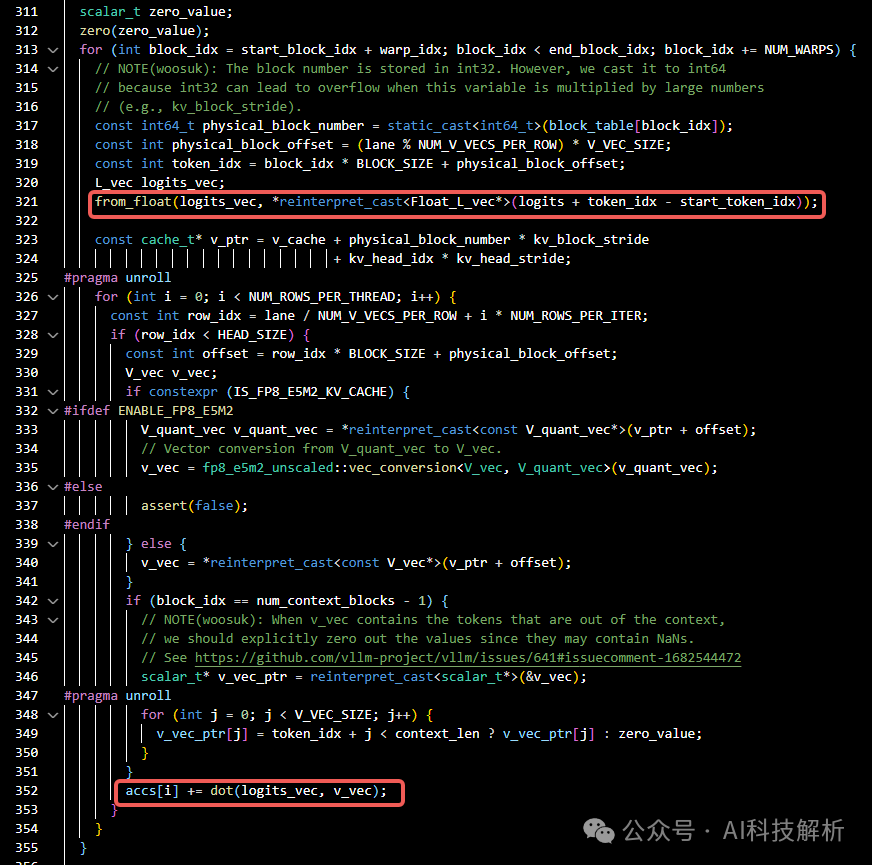
for循环遍历v的cache block,找到对应的v和softmax结果相乘
总结
1、大部分公司无法在架构上优化(没钱从零训LLM),只能在数据和系统级别上优化。RAG、量化和Attention 优化最普遍。
2、prefill多数据并行,属于计算瓶颈。decode阶段一次迭代一个token,内存耗时更多。因此加速方式如下
-
降低输入长度可以优化prefill阶段耗时
-
算子合并、优化的方式对prefill阶段加速更明显
-
降低kv cache显存对降低decoding阶段耗时更有效
-
MOE降低了激活参数也可以减少计算量,降低耗时
-
一次预测多个token减少decode迭代步骤;
-
用小draft模型快速推理初始结果,将prompt和初始结果一起输入大模型做判别,充分利用了LLM在prefill阶段计算效率更高的特点,在某种程度上也可以加速。
3、vllm和tensorRT-llm等框架,在处理时都会将不同batch的数据合并成一个batch(超长的total_seq),去除batch间不同长度的seq需要pad到同一长度造成的内存和计算量浪费。
4、FlashAttention的cuda实现,在bs小、seq小的场景下分配的cuda block数量小,会导致计算效率低。因此FlashAttention在实际推理场景加速效果不是特别好。且FA不支持head_dim超过256的场景。
5、FlashDecoding在FlashAttention的基础上,在query数据很小无法分块的场景下,针对kv继续分块,增加并行度,提高了计算效率。
6、PagedAttention碎片化内存管理大幅减少了内存的浪费,但不连续的内存无法一次性读取,在超超长token场景下会多出很多次的内存读取操作,大幅增减了耗时。其不连贯的内存读取需要修改kernel实现,无法和FlashAttention通用。
上面说了很多方法,但不同的实现,效果也不尽相同,且没有最好,只有更好。vllm是目前最流行的推理框架,效果也比pytorch原生推理快很多。但在很多场景下还有提升空间。
比如vllm在较小批量数据和超长数据场景下并不如基于FasterTransformer的TensorRT-llm和Lmdeploy,后者是基于C++编写,速度很快。(ps:TensorRT-llm部署起来有点麻烦,模型支持度没有vllm好)。
在分布式场景下,vAttention和LM-Infinite针对vllm的内存分配和访问也做了不同方面的优化。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓