Abstract
端到端自动驾驶在大规模数据中展示了强大的规划能力,但在复杂、罕见的场景中仍然因常识有限而表现不佳。相比之下,大型视觉语言模型(LVLMs)在场景理解和推理方面表现出色。前进的方向在于融合两者的优势。以往利用LVLMs预测轨迹或控制信号的方法效果不佳,因为LVLMs并不适合精确的数值预测。本文提出了Senna,一个结合LVLM(Senna-VLM)与端到端模型(Senna-E2E)的自动驾驶系统。Senna将高层次规划与低层次轨迹预测分离。Senna-VLM以自然语言生成规划决策,而Senna-E2E则预测精确的轨迹。Senna-VLM采用多图像编码方法和多视角提示以实现高效的场景理解。此外,我们引入了面向规划的问答及三阶段训练策略,从而在保持常识的同时提升了Senna-VLM的规划性能。在两个数据集上的大量实验显示,Senna达到了最先进的规划性能。值得注意的是,经过DriveX大规模数据集的预训练并在nuScenes数据集上微调后,Senna的平均规划误差降低了27.12%,碰撞率下降了33.33%。我们认为,Senna的跨场景泛化能力和迁移能力对于实现完全自动驾驶至关重要。
代码和模型将发布在:https://github.com/hustvl/Senna
欢迎加入自动驾驶实战群
Introduction
近年来,自动驾驶技术取得了快速发展。在驾驶感知、运动预测 和规划等领域取得了显著进展,为实现更精确、更安全的驾驶决策奠定了坚实的基础。其中,端到端自动驾驶因其依赖大规模数据而展现出显著的规划能力。同时,大型视觉语言模型(LVLMs)在图像理解和推理能力方面日益增强。通过利用其常识和逻辑,LVLMs可以分析驾驶环境并在复杂场景中做出安全决策。利用大量驾驶数据提升LVLMs在自动驾驶中的表现,并将LVLMs与端到端模型结合是实现安全、稳健和可泛化自动驾驶的关键。
端到端自动驾驶的普遍做法是直接预测未来轨迹或控制信号,而不涉及决策步骤。然而,这种方法可能导致模型学习难度增加且缺乏解释性。相比之下,当人脑进行详细决策时,系统通常由分层的高层决策和低层执行组成。此外,端到端模型往往缺乏常识,在简单场景中可能出现错误。例如,它们可能会将载有交通锥的卡车误解为路障,从而触发不必要的制动。这些限制阻碍了端到端模型的规划性能。
本文主要探索并尝试回答以下三个关键问题:
如何将LVLMs与端到端模型整合?目前,LVLMs在自动驾驶规划中的应用主要分为两种类型。一种是直接用LVLMs作为规划器预测轨迹点或控制信号 ,但LVLMs在精确的数学计算方面存在天然局限性 ,使其不适合预测准确数值。另一种方法是将LVLMs与端到端模型结合。以往的先驱工作使用LVLMs预测低频率的轨迹点,随后由端到端模型进一步优化生成高频率的轨迹。此举减少了LVLMs预测点的数量,部分缓解了问题。然而,由于LVLMs仍需预测轨迹点,问题尚未完全解决。在本文中,我们提出了Senna,一个结构化自动驾驶系统,将大型视觉语言模型(Senna-VLM)与端到端模型(Senna-E2E)集成,命名源自巴西著名赛车手艾尔顿·塞纳(Ayrton Senna)。
如何设计一个专门用于驾驶任务的LVLM?当前流行的LVLMs并未专门为多图像输入优化。此前用于驾驶任务的LVLMs要么只支持前视图输入,限制了空间感知能力并增加了安全风险,要么在支持多图像输入的情况下,仍缺乏设计或效果验证。Senna-VLM专为驾驶任务设计,支持多图像输入以编码全景数据,这是理解驾驶场景并确保安全的关键。最初,我们尝试整合基于LLaVA-1.5的全景输入,但由于图像标记过多导致效果不佳。为了解决这一问题,我们提出了一种驾驶视觉适配器来编码并压缩图像标记,并引入专为全景场景设计的提示。这些设计帮助模型区分来自不同视角的图像特征,并培养其空间理解能力。
如何有效地训练用于驾驶的LVLM?在设计出一个适用于驾驶任务的LVLM之后,确保有效的训练是最后一步,这需要合适的数据和策略。在数据方面,尽管先前的工作已提出了各种数据策略 ,但许多并未专门为规划任务设计,而是针对检测和定位等任务。本文中,我们首次验证了不同类型的问答在驾驶规划中的重要性。具体来说,我们引入了一系列面向规划的问答,以增强VLM对驾驶场景中与规划相关线索的理解,从而实现更准确的规划。这些问答包括驾驶场景描述、交通参与者的运动意图预测、交通信号检测、元动作规划等。与以往依赖手动注释的工作不同,我们的数据策略完全可以通过自动化流水线大规模生成。
在训练策略方面,现有方法大多采用通用预训练后进行驾驶微调 。然而,我们的实验结果表明,这可能并非最佳选择。相反,我们提出了Senna-VLM的三阶段训练策略,包括混合预训练、驾驶微调和规划微调。实验结果表明,我们提出的训练策略可以带来最佳的规划性能。
Senna具有多项优势。其结构化规划策略结合了LVLMs和端到端模型的优势,提升了自动驾驶的安全性、稳健性和泛化能力;支持全景和多图像输入,提高了对驾驶场景的感知和空间理解能力;所设计的面向规划的问答及三阶段训练策略,使Senna-VLM在保持常识的同时,能够更准确地做出规划决策,避免模型崩溃。
3.SENNA
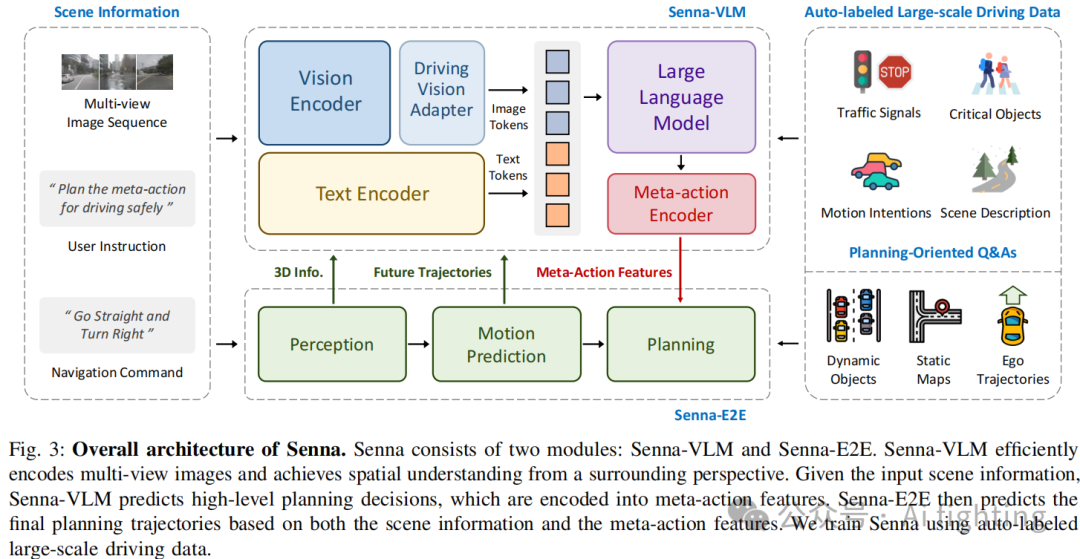
在本节中,我们将详细介绍 Senna。图3展示了 Senna 的总体架构。输入场景信息包括多视角图像序列、用户指令和导航命令。用户指令作为提示被输入到 Senna-VLM,而其他信息同时输入到 Senna-VLM 和 Senna-E2E。Senna-VLM 将图像和文本信息分别编码成图像和文本 tokens,随后被 LLM(大型语言模型)处理。LLM 生成高层次的决策,并通过 Meta-action 编码器将这些决策编码成高维特征。Senna-E2E 基于场景信息和 Senna-VLM 生成的 Meta-action 特征来预测最终的规划轨迹。我们为训练 Senna-VLM 设计了一系列面向规划的问答(QA),这些问答不需要人工标注,可完全通过自动标注管道大规模生成。
在第三节的 A 部分,我们详细介绍了驾驶场景理解的规划导向问答;B 和 C 部分分别介绍了 Senna-VLM 和 Senna-E2E 的设计;D 部分则介绍了我们提出的三阶段训练策略。
A. 驾驶场景理解
理解驾驶场景中的关键因素对于安全且准确的规划至关重要。我们设计了一系列规划导向的问答来增强 Senna-VLM 对驾驶场景的理解。每种问答类型的详细信息如图7所示。生成这些问答所需的原始数据,如 3D 物体检测框和物体跟踪轨迹,可以通过自动标注系统获得。此外,描述性问答可以通过大型视觉语言模型(如 GPT-4o)生成。我们将逐一阐述每种问答类型。
场景描述:我们使用预训练的 LVLM 基于环视图图像生成驾驶场景描述。为了避免生成与规划无关的冗余信息,我们在提示中指定了所需信息,包括交通状况、环境(如城市、乡村等)、道路类型(如铺装路、公路)、天气条件、时间和道路状况(如道路是否平整或是否存在障碍物)。通过这样结构化的提示,我们能够获得简明而有用的场景描述。
交通信号检测:交通信号种类繁多,但这里我们主要关注最关键的一种:交通灯。交通灯状态可分为四种:红灯、绿灯、黄灯和无交通灯,“无” 表示在自车前方未检测到任何交通灯。
弱势道路使用者识别:通过识别环境中的弱势道路使用者(VRUs),我们增强了 Senna 对这些关键物体的感知能力,从而提高了规划的安全性。具体而言,我们使用真实的3D检测结果获取VRU的类别和位置信息,并以文本形式描述该信息。位置信息以自车为中心,包括每个 VRU 相对于自车的横向和纵向距离。我们仅让 Senna-VLM 预测距离的整数部分,以降低学习复杂性,同时构建距离感知。
运动意图预测:准确预测其他车辆的未来运动意图是安全规划的前提。我们也采用 Meta-action 方法,允许 Senna 预测周围车辆的未来行为。这增强了 Senna 对场景动态特征的理解,使其能够做出更明智的决策。
Meta-action 规划:为避免使用 LVLM 进行精确的轨迹预测,我们将自车的未来轨迹转换为用于高层次规划的 Meta-action。具体而言,Meta-action 包括横向和纵向决策。横向 Meta-action 包括左转、直行和右转,而纵向 Meta-action 则涵盖加速、保持、减速和停车。横向 Meta-action 基于预测的未来时间步 T 的横向位移确定,纵向 Meta-action 则根据预测期内的速度变化确定。最终的 Meta-action 包括横向和纵向 Meta-action。
规划解释:我们还使用 LVLM 基于车辆的真实未来运动生成规划解释。换句话说,我们将车辆的实际未来运动(例如加速并左转)告知 LVLM,并要求它们分析这些决策背后的原因。在提示中,我们引导模型通过考虑以下影响规划的因素来分析决策:其他交通参与者的行为、导航信息、道路状况和交通灯状态。
B. Senna-VLM
Senna-VLM 由四个组成部分构成。视觉编码器(Vision Encoder)以多视角图像序列
![]()
作为输入,并提取图像特征,这些特征随后由驾驶视觉适配器(Driving Vision Adapter)进行编码和压缩,生成图像 tokens
![]()
。其中,
![]()
和分别表示图像数量、每张图像的图像 tokens 数量以及 LLM 的特征维度。H 和W分别是图像的高度和宽度。
文本编码器(Text Encoder)将用户指令和导航命令编码成文本 tokens
![]()
,其中
![]()
是文本 tokens 的数量。图像和文本 tokens 都会被送入 LLM,用于预测高层次决策。在实践中,我们使用 Vicuna-v1.5-7b 作为 LLM。最后,Meta-action 编码器(Meta-action Encoder)对这些决策进行编码,输出 meta-action 特征
![]()
,其中 D是 Senna-E2E 的特征维度。
我们使用来自 CLIP 的 ViT-L/14 作为视觉编码器,将每张图像调整为
![]()
,得到 576 个图像 tokens。对于多图像输入,这将产生过多的图像 tokens,不仅降低 VLM 的训练和推理速度,还会导致模型崩溃和解码失败。因此,我们引入了一个驾驶视觉适配器模块(Driving Vision Adapter)。该模块不仅具备与之前研究类似的功能(将图像特征映射到 LLM 特征空间),还执行额外的编码和压缩,以减少图像 tokens 数量。具体而言,我们采用一组图像查询
![]()
来编码图像特征并输出图像 tokens。
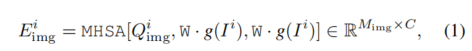
其中,MHSA 代表多头自注意力机制,g是视觉编码器,W是由线性层和 GELU激活层组成的多层感知机,用于投影图像特征。
![]()
和
![]()
分别表示第 i张图像 的图像 tokens 和图像查询。我们的实验表明,进一步编码和压缩图像特征不会降低模型性能,但过多的图像 tokens 会导致模型崩溃和解码失败。
为了使 Senna-VLM 能够区分来自不同视角的图像特征并构建空间理解,我们为驾驶场景设计了一种简单而有效的环视提示(surround-view prompt)。以前视图为例,相应的提示为::\n\n,其中 是 LLM 的特殊 token,在生成过程中将被图像 tokens 替代。图4展示了我们提出的多视角提示和图像编码方法的设计。
最后,我们提出了 Meta-action 编码器 ϕ,它将 LLM 输出的高层次决策转换为 meta-action 特征 。由于我们使用格式化的 meta-actions 集合,Meta-action 编码器 ϕ通过一组可学习的嵌入
![]()
实现了 meta-actions 到 meta-action 特征的一对一映射,其中
![]()
是 meta-actions 的数量。
![]()
其中,
![]()
是与第 i 张图像对应的环视提示。LLM 是 Senna 的大型语言模型。随后,meta-action 特征将被输入到 Senna-E2E 以预测规划轨迹。
C. Senna-E2E
Senna-E2E 基于 VADv2 扩展而来。具体来说,Senna-E2E 的输入包括多视角图像序列、导航命令和 meta-action 特征。它由三个模块组成:感知模块(Perception Module),该模块检测动态物体并生成局部地图;运动预测模块(Motion Prediction Module),用于预测动态物体的未来轨迹;以及规划模块(Planning Module),该模块使用一组通过注意力机制与场景特征交互的规划 tokens 来预测规划轨迹 V。我们将 meta-action 特征集成为 Senna-E2E 的附加交互 token。由于 meta-action 特征以嵌入向量的形式存在,Senna-VLM 可以轻松地与其他端到端模型结合。Senna-E2E 的轨迹规划过程 Φ可表示为以下公式:
![]()
其中,表示导航命令。
D. 训练策略
我们为 Senna-VLM 提出了一个三阶段的训练策略。第一阶段是混合预训练(Mix Pre-training),我们使用单图像数据来训练驾驶视觉适配器(Driving Vision Adapter),同时保持 Senna-VLM 中其他模块的参数冻结。这使得图像特征能够映射到 LLM 的特征空间。“混合”是指使用来自多种来源的数据,包括 LLaVA 使用的指令跟随数据和我们提出的驾驶场景描述数据。第二阶段是驾驶微调(Driving Fine-tuning),我们基于第三节第 A 部分提出的面向规划的问答数据(不包括 meta-action 规划问答)对 Senna-VLM 进行微调。在这一阶段,使用环视多图像输入代替单图像输入。第三阶段是规划微调(Planning Fine-tuning),仅使用 meta-action 规划问答对 Senna-VLM 进行进一步微调。在第二和第三阶段,我们微调 Senna-VLM 的所有参数,但视觉编码器(Vision Encoder)保持冻结状态。
对于 Senna-E2E,在训练阶段我们使用真实的 meta-action 作为输入,而在推理阶段,它依赖于 Senna-VLM 预测的 meta-action。
4.Experiment
1. 主要结果
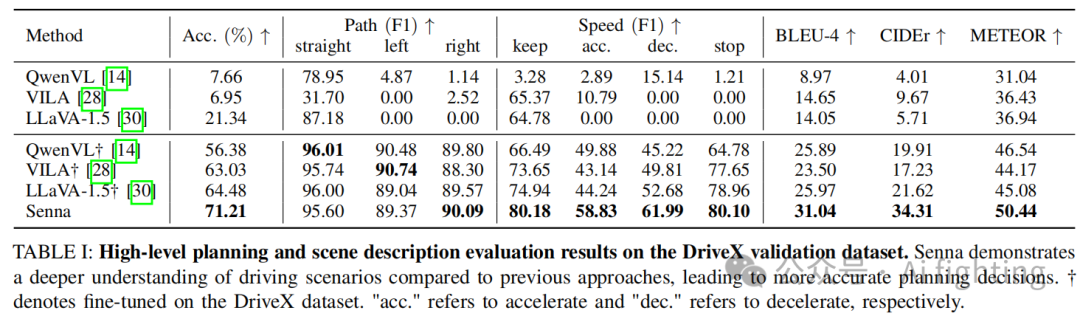
Meta-action 规划。Tab. I 显示了 Senna 在高级规划和场景描述方面的表现,并与最新的开源 LVLM 模型(包括 QwenVL、LLaVA 和 VILA)进行了对比。前面三行的结果是通过直接评估原始模型获得的。可以看出,使用预训练权重的模型在驾驶任务中的表现较差,因为它们的训练目标更偏向于通用理解和对话,而不是专门针对驾驶相关任务的。为了进一步验证 Senna 的优势,我们还使用相同的训练流程在 DriveX 数据集上微调了这些模型。结果显示,Senna 在高级规划和场景描述方面的表现均优于其他模型。与其他方法的最佳结果相比,Senna 将规划准确率提高了 10.44%。此外,在最关键的驾驶安全决策(例如减速)中,F1 分数从 52.68 提升至 61.99,实现了 17.67% 的提升。这突出表明 Senna 在驾驶场景分析和空间理解方面的优越能力。
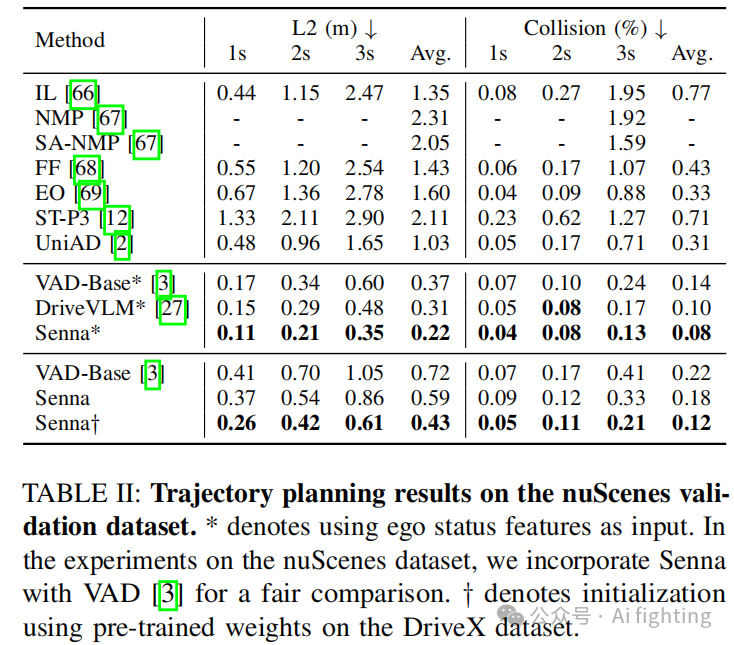
轨迹规划。我们在 nuScenes 数据集上展示了 Senna 的轨迹规划表现(如 Tab. II 所示)。为了公平比较,我们将端到端模型 VADv2 替换为 VAD。与之前结合 LVLM 和端到端模型的最新方法 [27] 相比,Senna 有效地将平均规划偏移误差减少了 29.03%,碰撞率减少了 20.00%。为了避免使用自车状态特征可能引起的问题(如之前研究中所提及),我们还报告了不使用自车状态特征的结果。通过使用 DriveX 数据集的预训练权重进行初始化,并在 nuScenes 数据集上进行微调,Senna 实现了最新的规划性能,与 VAD 相比显著降低了 40.28% 的平均规划偏移误差和 45.45% 的平均碰撞率。通过在 DriveX 数据集上进行预训练再在 nuScenes 数据集上微调,Senna 的性能显著提升,展示了其出色的泛化和迁移能力。
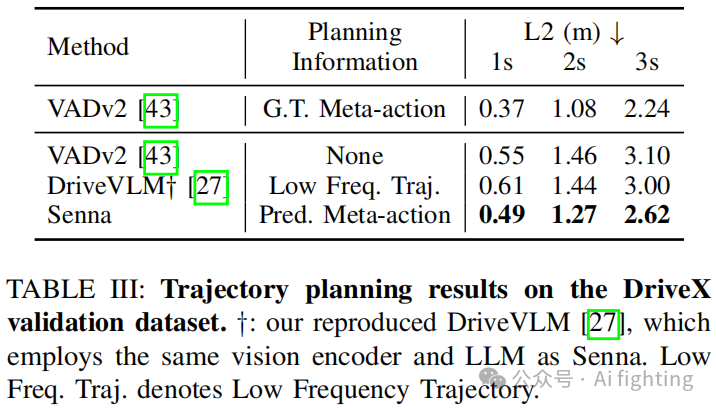
Tab. III 展示了在 DriveX 数据集上的轨迹规划结果。除了端到端模型 VADv2,我们还引入了两个额外的对比模型。第一个模型将真实的规划 meta-action 作为额外的输入特征,旨在验证我们提出的结构化规划策略的性能上限。第二个模型是我们复现的 DriveVLM ,它预测低频轨迹而非 meta-action,作为 LVLM 和端到端模型之间的连接。
如 Tab. III 所示,利用真实规划 meta-action 的 VADv2 达到了最低的规划误差,验证了我们提出的结构化规划策略的有效性。DriveVLM† 作为连接器预测低频轨迹,仅相较于 VADv2 略有改进。相比之下,我们提出的 Senna 在所有方法中表现最佳,将平均规划偏移误差显著降低了 14.27%。
2. 消融研究
面向规划的问答(Planning-oriented QAs)。Tab. IV 展示了消融研究的结果,验证了我们提出的面向规划的问答的有效性。作为我们评估的关键组成部分,Meta Action QA 的缺失对 Senna 的规划准确率有显著影响(ID 1)。缺少场景描述和交通信号灯检测问答也影响了加速和减速决策,因为在交通信号灯场景下的启动和停止与这些问答密切相关(ID 2-3)。此外,忽略其他任何问答会导致决策准确率的下降(ID 4-6)。当所有类型的问答都用于训练 Senna 时,它达到了最佳的规划性能(ID 7)。
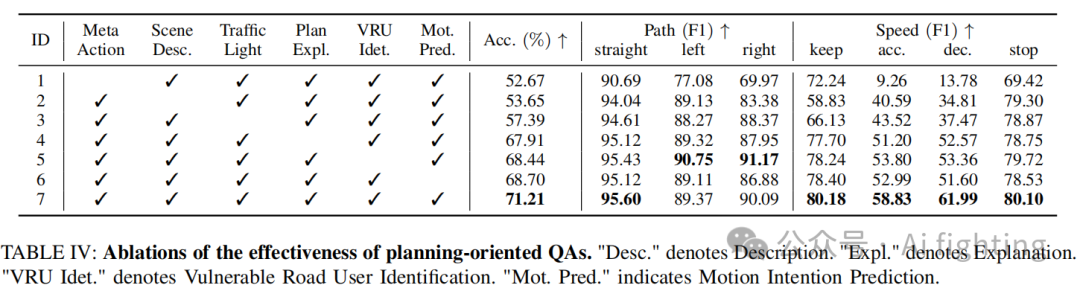
图像视角。如 Tab. V 所示,加入环视多图像输入后,Senna 的规划准确率从 64.91% 提高到 71.21%。这表明 Senna 的图像编码策略和环视提示设计的有效性,增强了模型对驾驶环境的理解能力,从而能够做出更准确的规划决策。

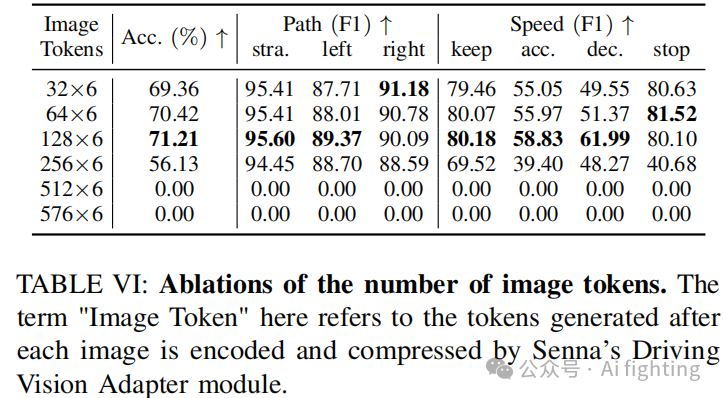
图像标记数量。Tab. VI 展示了应用环视多图像输入时使用不同数量的图像标记的结果。Senna 视觉编码器的原始输出包含 576 个图像标记,如表中最后一行所示。这导致了模型崩溃,造成解码失败。将图像标记数量减少至 512 并未解决问题。当图像标记数量减少至 256 时,模型开始正常输出,但规划准确率仍不理想。当图像标记数量设置为 128 时,取得了最佳结果。进一步将图像标记减少到 64 和 32 对规划准确率影响较小,表明了我们提出的多图像编码策略的有效性和鲁棒性。
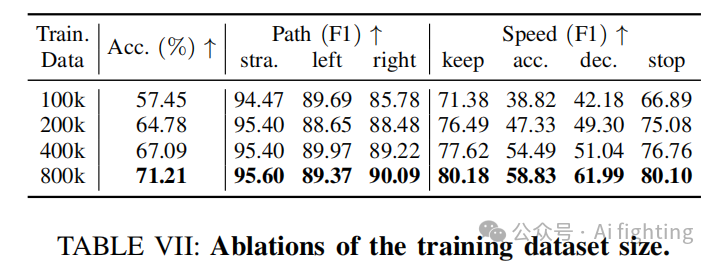
训练数据集规模。我们对训练数据集规模进行了消融研究,结果如 Tab. VII 所示。可以看出,当训练数据量相对较小时,Senna 的模型性能并未显著下降。然而,随着训练数据的增加,Senna 的决策准确率稳步提升,突显了其优秀的扩展能力。
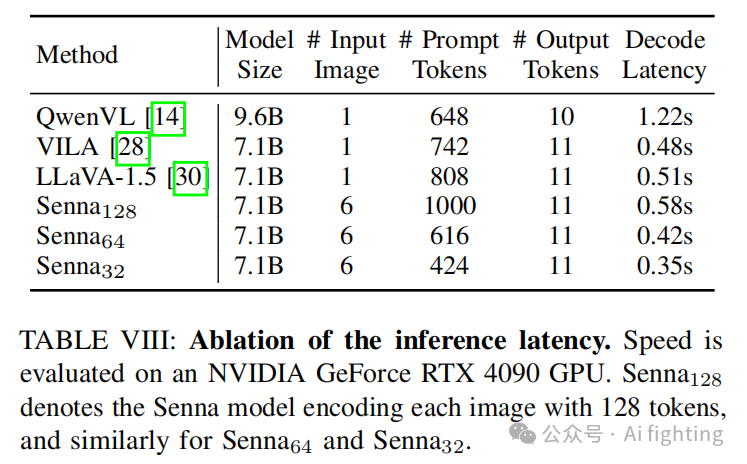
推理速度。Tab. VIII 比较了 Senna 与其他模型的推理速度,均使用相同长度的提示进行评估。使用六张输入图像(相较于其他模型的单张图像),Senna 由于其高效的多图像编码策略实现了可比或更快的推理速度。当将每张图像编码为 128 个标记时,Senna 的解码延迟接近 LLaVA-1.5,尽管处理了更多的提示标记。此外,通过将每张图像的标记数量减少到 64 和 32,Senna 将解码延迟分别减少到 0.42 秒和 0.35 秒,分别比 LLaVA-1.5 提高了 17.6% 和 39.7% 的推理速度。
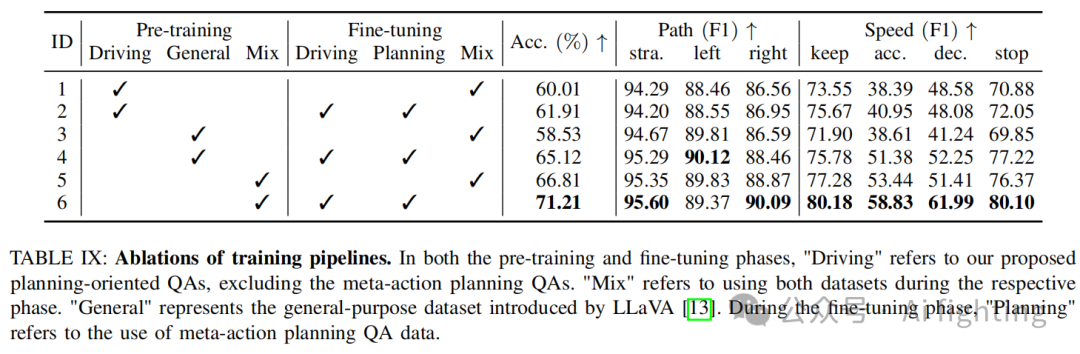
训练流程。我们验证了训练流程的有效性,结果如 Tab. IX 所示。通过应用我们提出的三阶段训练策略:混合预训练、驾驶微调和规划微调,Senna 取得了最佳性能。
结论
本文的主要贡献可概括为以下几点:
-
本文提出了Senna,一个结合LVLM与端到端模型的自动驾驶系统,实现了从高层决策到低层轨迹预测的结构化规划。Senna-VLM利用常识和逻辑推理分析场景并以自然语言输出决策,而Senna-E2E则基于这些决策生成具体的规划轨迹。
-
Senna采用高效的多图像编码策略及精心设计的全景提示,实现了驾驶场景的准确感知和空间理解。
-
本文设计了一系列面向规划的问答和三阶段训练策略,以增强Senna的驾驶理解与规划性能,同时保留其常识知识。
-
在nuScenes数据集及DriveX大规模数据集上的大量实验表明,Senna达到了SOTA的规划性能。通过在DriveX数据集上利用预训练权重并在nuScenes数据集上微调,Senna取得了显著的性能提升,表现出较强的跨场景泛化能力和迁移性。这些结果验证了Senna的结构化规划方法、架构设计及训练策略的有效性和通用性。
文章引用: Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术。
长按扫描下面二维码,加入知识星球。