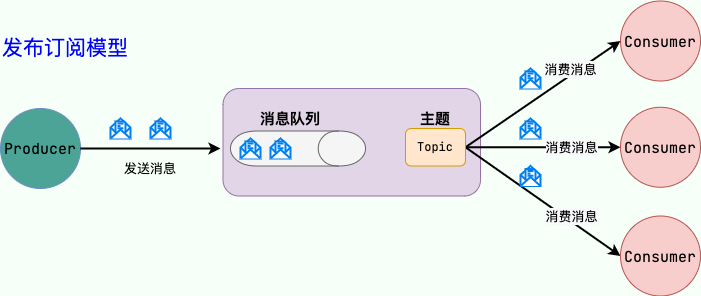
1. 背景概述
Milvus 是一款高效的矢量数据库管理系统,支持在高并发和高调用场景下加速相似度搜索。Milvus 的 GPU 支持由 NvidiaRAPIDS 团队提供,可以借助各种 GPU 索引类型来优化性能。本篇将重点解析 Milvus 支持的 GPU 索引类型、适用场景及各自的性能特点,并详细介绍如何配置和使用这些 GPU 索引,以帮助用户合理选择索引类型来提升系统吞吐量和召回率。
2. GPU 索引类型与性能分析
Milvus 支持多种 GPU 索引类型,包括 GPU_CAGRA、GPU_IVF_FLAT、GPU_IVF_PQ 和 GPU_BRUTE_FORCE,每种索引类型的优缺点和适用场景各不相同。
GPU_CAGRA
- 特点:适用于高吞吐量查询场景,具有较高的召回率。
- 适用场景:当面临大量并发请求或需要搜索大量向量时,GPU_CAGRA 是较为经济的选择,尤其适合推理级 GPU。
- 配置与使用:
# 配置索引参数 index_params = {"metric_type": "L2","index_type": "GPU_CAGRA","params": {"intermediate_graph_degree": 32,"graph_degree": 64,"build_algo": "IVF_PQ","cache_dataset_on_device": "false"} } # 创建索引 collection.create_index(field_name="embedding", index_params=index_params)- 搜索参数:GPU_CAGRA 索引支持
itopk_size、search_width等特有参数,用于控制搜索宽度和召回率。search_params = {"params": {"itopk_size": 64,"search_width": 4} } results = collection.search(data=query_vectors, anns_field="embedding", param=search_params, limit=top_K)
- 搜索参数:GPU_CAGRA 索引支持
GPU_IVF_FLAT
- 特点:该索引采用聚类和距离比较方式,对大型数据集有较快的查询速度。
- 适用场景:适合需要低延迟但仍要求高召回率的场景,尤其在需要找到大致准确的相似结果时更具性价比。
- 配置与使用:
# 配置索引参数 index_params = {"metric_type": "L2","index_type": "GPU_IVF_FLAT","params": {"nlist": 128,"cache_dataset_on_device": "false"} } # 创建索引 collection.create_index(field_name="embedding", index_params=index_params)- 搜索参数:
nprobe控制访问的聚类数量,可以平衡查询速度和召回率。search_params = {"params": {"nprobe": 16} } results = collection.search(data=query_vectors, anns_field="embedding", param=search_params, limit=top_K)
- 搜索参数:
GPU_IVF_PQ
- 特点:通过乘积量化压缩向量存储空间,从而减少内存占用和计算时间。
- 适用场景:适用于需要快速响应但能容忍一定精度损失的场景。
- 配置与使用:
# 配置索引参数 index_params = {"metric_type": "L2","index_type": "GPU_IVF_PQ","params": {"nlist": 128,"m": 4, # 量化因子数"nbits": 8,"cache_dataset_on_device": "false"} } # 创建索引 collection.create_index(field_name="embedding", index_params=index_params)- 搜索参数:与 GPU_IVF_FLAT 类似,使用
nprobe控制查询的准确性。search_params = {"params": {"nprobe": 8} } results = collection.search(data=query_vectors, anns_field="embedding", param=search_params, limit=top_K)
- 搜索参数:与 GPU_IVF_FLAT 类似,使用
GPU_BRUTE_FORCE
- 特点:该索引类型执行完全比较,保证召回率为 1,适合对召回率要求极高的场景。
- 适用场景:当需要获得绝对精确的查询结果时,GPU_BRUTE_FORCE 是首选,但由于耗费大量计算资源,仅适合小规模数据集或查询数量有限的情况。
- 配置与使用:
# 配置索引参数 index_params = {"metric_type": "L2","index_type": "GPU_BRUTE_FORCE" } # 创建索引 collection.create_index(field_name="embedding", index_params=index_params)- 搜索参数:只需设置
top-K值,无需额外参数。results = collection.search(data=query_vectors, anns_field="embedding", limit=top_K)
- 搜索参数:只需设置
3. 优化建议
使用 GPU 索引时,可以通过以下方式进一步优化性能:
- 缓存原始数据:如果内存允许,可以将
cache_dataset_on_device设为true,在 GPU 内存中缓存数据集以提升性能。 - 参数调优:根据业务场景和实际测试结果,调整
nlist、nprobe等参数,以在召回率和速度之间找到平衡点。
总结
在 Milvus 中使用 GPU 索引可以大幅提高搜索效率,不同的 GPU 索引在 Milvus 中有不同的适用场景和参数配置。合理选择和配置索引类型,结合业务场景的需求,可以在查询速度、召回率和内存占用之间找到最佳平衡。希望本篇内容能帮助您深入理解 Milvus 的 GPU 索引类型,为数据检索和查询优化提供参考。

![pytest高版本兼容test_data[“log“] = _handle_ansi(“\n“.join(logs))错误](https://i-blog.csdnimg.cn/direct/da4d245509cc4f5596ba4c29d3f50b4a.png)








![[Unity Demo]从零开始制作空洞骑士Hollow Knight第十九集:制作过场Cutscene系统](https://i-blog.csdnimg.cn/direct/d95a1fa86b0e474ca59bdeaa1ae4b6b6.png)