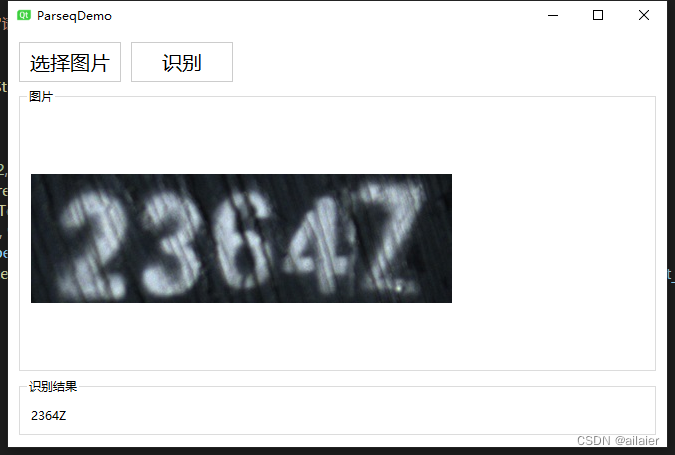
识别假设对于打破假设至关重要ーー而打破假设是创造力和技术创新。
近来,chatGPT再一次激发了人们对通用人工智能的热情,甚至到了人人都在谈AIGC的地步。然而,大模型对数据丰富性的依赖更加严重,面向机器学习以及深度学习的数据架构又是怎样的呢?

“Garbage in,Garbage out”,数据获取已经成为许多机器学习应用中的关键问题,甚至成为了瓶颈,深度学习的兴起进一步加剧了这一问题。尽管高质量的机器学习模型最终从昂贵的开发和高度专业化的代码过渡到了更像商品的东西,但这些模型涉及数百万甚至数百亿个参数,需要大量数据进行训练。因此,当今机器学习的主导模式是每当面临新任务时就创建一个新的大型数据集。虽然这种方法取得了重大进展,但收集大量高质量的数据集往往需要耗费大量的时间和人力资源。对于某些任务,例如罕见疾病的检测,构建大型数据集几乎是不可行的。
在一个软件系统中,尤其是机器学习驱动的软件系统,如何解决数据匮乏的问题呢?
数据匮乏在机器学习领域普遍存在,在监督式学习中尤为突出,但也适用于无监督的情形。为了简化问题,暂不考虑强化学习,可以从监督,无监督和半监督学习入手。
数据匮乏问题可以分为两大类:一是数据难以获取导致数据缺失,另一类是已有的数据缺乏标签,无法形成高质量的数据。
“知易行难”,每一类问题又是求解的呢?

1.数据缺失
1.1 数据集再利用
数据集再利用是指将预先存在的数据集用于新用途。可能是添加数据的最明显的方法,例如,ImageNet 最初制作并用于分类,但后来被重用于图像生成。
数据重用还包括对现有数据集的转换。例如,考虑修复,即根据周围信息恢复图像丢失部分的过程。修复是使用各种预先存在的数据集完成的。
当然,也有可能重新定义一个没有任何机器学习任务的数据集。
1.2 数据增强
数据增强是生成更多数据的常用方法,它通过对应用的修改人为地使训练集膨胀,最初的目标是防止过载。
数据增强通常采用邻域风险最小化(VRM)。在 VRM 中,需要人类知识来定义训练数据中每个样本周围的邻域,并从这个邻域分布中提取虚拟样本。在CV领域,常见的数据增强是几何变换,比如翻转、裁剪、缩放和旋转等,其思想分类器不变,而改变图像的位置和方向,类似地,光度变换还可以修改颜色通道。
特别是在小型数据集或数据集不平衡的时候,数据增强可以提高泛化能力,可以采用联合训练生成增强模型的方法。除了人类定义的转换,使用预先训练的生成性对抗网络(GAN)也可以来创建新的示例。
1.3 多模态学习
多模态学习试图丰富学习算法的输入,使学习者可以访问多个模态,例如,一个图像及其标题或图像的说明。多模态学习的主要缺点是要获得丰富的输入信息,并能够有效地将其集成到模型中。这种方法应该可以减少数据需求和提高一般性。
此外,当数据点的数量非常小时,特别是在学习过程中只有少数目标有特定标签示例的时候,多模态学习也可以被使用。例如,通过将图像与多种和更丰富的语义(类别标签,属性和自然语言描述)相结合,可以有更良好的表现。
1.4 规程学习
在规程学习中,使用预先确定的规程来访问示例,这些示例通常按难度的增加顺序排列。其动机来自人类自身教学方式,因为教师往往从教授更简单的概念开始,试图通过难度分数来增加训练实例。
在给定难度分数的情况下,该算法从一组简单的数据点开始,逐渐增加了在整个学习过程中训练样例的难度。这种进展使模型能够在一些简单的例子上学习广泛的概念,然后用更困难的例子来完善概念。这种方法可以提高性能,同时减少收敛所需的示例数量。其约束是对难度标签估计器的内在需求。对困难的标注可能非常苛刻,甚至可能比标准的标注还要苛刻。

1.5 基于论证的机器学习
基于论证的机器学习(ABML)是一种利用专家的局部知识来约束搜索空间的方法。简而言之,就是试图找到 if-then 规则来归纳过程中解释论证的例子。首先找到一条规则,将其添加到一组规则中,然后删除该规则所涵盖的所有训练数据点。重复这个过程,直到删除所有示例。ABML 的主要优势是使用专家知识来证明特定的示例,这往往比解释全局现象更容易。
ABML 可能不那么受欢迎,然而,如果专家局部知识是可用的,这将是一个集成部分先验知识的强大方法。此外,归纳假设对专家来说更有意义,因为它必须与输入论点一致。
1.6 多任务学习
多任务学习是一个突出的研究领域,其中试图训练多个不同(但相关)的任务同时进行,同时解决这些多重任务,利用它们之间的共性和差异。同时共同学习多个任务,以增强跨任务的相似性,更好地概括。
多任务学习在视觉和自然语言处理中都得到了成功的应用。在没有大型数据集的情况下,这种成功的关键因素是: 它是一种基于跨任务共性的隐式数据增强方法; 它能够解开跨任务和特征相关性; 鼓励分类器在稍微不同的任务上也表现良好。
以垃圾邮件过滤为例。通常,来自单个用户的数据不足以完成模型的训练。直观地说,不同的人有不同的特性分布来区分垃圾邮件和合法的电子邮件。但是,可以利用用户间的共性来解决这个问题。为了建立这些相似性,可以将每个用户作为一个独特但相关的分类任务,并在不同用户之间进行一个模型的训练。
多任务学习的实现可以分为两大类——隐藏层的硬参数共享和软参数共享,其中硬参数共享更为常用。在硬参数共享的类型中,隐藏层在所有任务之间共享,同时保留几个特定于某些任务的输出层。在软参数共享中,每个任务都有自己的模型和参数。然后,模型参数之间的距离被正则化,以增强交叉任务间的相似性。
1.7 迁移学习
迁移学习是一种被广泛使用的、非常有效的整合先前知识的方法,将在解决一个问题时获得的知识转移到另一个不同但相关的问题上。这个思想是使用在相关任务上受过训练的预先存在的模型。这些预先训练的模型通常用作使用手头任务的小数据集进行微调的初始化。因此,为了收敛,需要特定于任务的示例要少得多。
另一个有益的副作用是使用模型初始的宽领域知识,相比于初始化随机权重,模型以一些相关的全局知识来开始微调阶段。例如,在 ImageNet 上训练的模型已经被转移到医学成像任务中,使用在一个大型和多样化的图像数据集上训练的普遍视觉特征。尽管 ImageNet 中的图像和下游任务中的图像有所不同,但这些特性与许多视觉任务相关。因此,这种方法显著减少了所需标记特定任务的数据大小。
在自然语言处理中,通常使用的预训练模型 BERT 在各种任务中取得了最先进的结果。预训练模型通常是以自我监督的方式进行,其中不同的输入部分被掩盖,目标是预测被掩盖的部分。例如,给定一个句子,可以对它进行迭代,每次屏蔽一个不同的单词,以创建各种示例。
深度网络中的微调通常是通过添加一个未经训练的最后一层,并在特定任务的小数据集上训练新模型来完成的,或者是通过嵌入下一个最后一层的输出来完成。另一种可能的微调技术是以一个相对较小的学习率来训练整个网络; 也就是说,对已经合适的权重进行小的改变。微调也可以通过冻结预训练模型的前几层权重来完成。这种技术背后的动机是第一层捕获通用特性,这些特性可能也与新任务相关。因此,在微调期间会冻结它们应该保留与原始任务和新任务相关的捕获信息。
总之,迁移学习对于减少任务的特定数据数量和提高模型的性能都是一个强有力的工具。
1.8 元学习
元学习通过对多个学习过程的经验进行推广来改进学习算法。虽然元学习通常可以与 多任务学习系统有意义地结合,但它们的目标是不同的。多任务学习的目标是解决所有的训练任务,而元学习的目标是利用训练任务来解决新的小数据任务。因此,元学习是创建具有先验经验的模型,能够快速适应新的任务。具体来说,元学习会逐渐学习跨任务的元知识,在使用很少的任务特定信息时,就可以推广到一个新的任务。
元学习有三种常见的方法: 基于度量(类似于最近邻算法)、基于优化(元梯度优化)和基于模型(不假设数据分布)。
作为基于度量的方法,可以显式地从给定的支持集中学习,以最小化批处理的损失。结果是一个模型学会了将一个小的、带标签的支持集和一个未标签的示例进行映射,从而不用微调就能适应新类类型的需要。
在基于优化的研究领域,典型的方法是模型无关元学习(MAML) ,这是一个通用的优化算法,与任何基于梯度下降的模型兼容。它使用了一个元损失,用于诱导快速变化时,微调新的任务和基于任务总数的梯度。
在基于模型的研究领域,一般地,元学习模型依赖于“快速权重”,这些权重是网络的参数,与常规的基于梯度的权重变化相比,变化的时间尺度更小。这种 短期可塑性维持了一种动态变化的短期记忆,记忆了数据单元在网络中活动的近期历史,而不是标准的慢循环连接。该模型在多个任务中的性能优于许多其他的循环模型。

2. 标签缺失
另一类问题是数据非常丰富,但是几乎没有标签。这种情况在实践中很常见,因为未标记的数据通常比标记的数据更容易获得。
如何解决标签缺失的问题呢?
2.1 主动学习
当需要更多的标签但标注成本高昂的时候,一个直接的问题是如何有效地获取新的标签数据。主动学习就是一个很好的方法,可以通过反复查询信息源来标记新的数据点。这些查询可以包括来自数据集或新的前数据点中未标记的示例,通常是接近决策边界的示例。
有许多方法可以确定下一步应该查询训练集中的哪些数据点。通常的目标包括挑选最能改变当前模型的例子,当前模型最不确定的例子,或者类似于数据分布的不同例子。在存在少量数据的情况下,用典型的示例来展示模型是最有益的。
当生成新的示例时 ,仍然需要人工标注,虽然数据增强修改了输入,但是主动学习生成的示例没有标签。因此,生成算法应该保持新的数据点可解释,也就是说,确保它们有一个清晰的标签。例如,使用 GAN 来生成新的示例,或者从头开始并标记它们 ,或者通过修改现有的示例同时试图保留标记。重要的是,GAN 方法比基于转换的方法更具表现力,但是结果往往更难以解释。
2.2 半监督学习
半监督学习通过在学习过程中整合有标记和无标记的示例来减少标记要求。这是一个非常广泛而活跃的领域,但并不能说是涵盖了所有的领域
半监督学习使用大量未标记的数据估计分布 P (X = x) ,以减少带注释的数据需求。它对 P (X = x)和 P (Y = y | X = x)之间的关系作出强有力的假设,以减少所需要的标记例子的数量。通常,这些假设采取以下形式:
平滑度: 相邻的点更有可能共享一个标签,即每两个相邻的样本 x,x’应该有相似的标签。
聚类能力: 数据倾向于形成离散的聚类,其中属于同一聚类的点更有可能共享一个标签。因此,决策边界只能通过特征空间中的低密度区域。
流形: 数据近似地位于一个比输入空间维数低得多的流形上。因此,当考虑输入空间的低维流形时,同一流形上的任何数据点都应该有相同的标签。
这三种假设都可以看作是对点间相似性的不同定义: 平滑性将其定义为输入空间中的邻近性,聚类能力假设高密度区域包含相似的数据点,以及位于同一低维流形上的点状态是相似的。
使用无监督预处理方法的一种常用方法是利用 P (X = x)上的知识在比原始维数更低的维数上提取有用的特征,从而降低学习复杂度。这包括使用自动编码器模型来学习表示,或者使用像 PCA 这样的降维方法。
2.3 数据编程
数据编程是编程创建训练集的范例。在数据编程中,用户将弱监督策略或领域启发式表示为标记函数(LF) ,即对数据子集进行标记的程序。LF 是不精确的,可能是相互矛盾的,会导致噪音标签的产生。数据编程通过明确地将标记过程 f: x → Y 表示为一个生成模型,目的是“去噪”生成训练集。
还是垃圾邮件检测例子,如果电子邮件包含 URL 或转账请求,潜在的 LF将返回“垃圾邮件”标签,如果来自联系人列表中的某人,则返回“非垃圾邮件”。这些函数本身的性能很差,然而,就像集成方法一样,数据编程的优势在于许多弱启发式的结合。

2.4 正则化期望
正则化期望使用了关于数据子组中不同标签比例的先验知识来创建有噪声的标签。关于标签在数据各个子组中比例的先验知识,使得正则化期望成为可能(从标签比例中学习)。
这个估计过程依赖于期望运算的一致收敛性,它使用子群体的经验方法来近似预期关于一个群体的分布,然后利用后者计算给定标签的期望值,最后利用标签分布上的条件平均值估计群的平均值。
2.5 远程监督
远程监督使用了已有数据库收集所需关系的示例,然后使用这些示例自动生成带标签的训练数据。
远程监督也是利用现有数据集的一种常用方法。在远程监督中,一个模型被学习给一个标记的训练集,就像在“标准”监控机器学习中一样,但是训练数据被弱标记,也就是说,是基于启发式或规则的自动标记。
例如,一个大型未标记的语义数据库为关系抽取提供远程监控,任何一个句子中包含一对与该语义数据库中关系已知的实体,都可能以某种方式表达这种关系。由于包含给定实体对的句子数量可能很多,有可能为标记过程提取和组合有噪声的特征。
2.6 附带监督
附带监督基于这样一种思想,即任务的信息线索可能存在于数据集中,而这些数据集并没有考虑到这个任务。例如,从名字中推断出性别。人们可以使用维基百科,它不是为这个任务而创建的。附带的信号是出现在维基百科页面第一段关于名字相同的人及其性别指标。这个信号与手头的任务相关,可以用于监督,减少对数据标注的需要。
附带监督是不假设知识的标注过程。附带信号可以是噪音,或只有弱相关的目标任务,仍然可以用来提供监督和促进学习。这里的监督概念与远程监控的概念不同: 在远程监控中,模型以标准的监督式学习方式学习,但训练集是基于启发式自动标记的。在附带监督下,一套完整的训练集可能永远不会存在。
例如,上下文相关的拼写和语法检查是一直依赖于附带监督的任务。在假设大多数编辑过的文本资源(书籍、报纸、维基百科)不包含许多拼写和语法错误的情况下,这些方法为单词、句读和现象生成上下文表示。然后,这些表示用于识别错误,并以与上下文相关的方式予以纠正。
3. 不是结束的结束语
机器学习的主导模式一般是使用众包来创建大型的、特定于任务的数据集。在机器学习驱动的数据架构中,经常面临的是数据匮乏的问题,而数据匮乏可以分为两类:数据缺失和标签缺失。
如何解决数据缺失的问题呢?
如何解决标签缺失的问题呢?
对于非机器学习驱动的软件系统而言,数据架构又面临哪些问题呢?
任何软件系统都需要以数据为中心来考虑基本架构。随着技术的发展,尤其是NewSQL,NoSQL 以及多开发语言环境下的存储、可伸缩性和可用性(最终一致性)、事件溯源和分析的不断挑战,AI与机器学习的日渐普及,数据架构的这些问题不可能在工程实践中一次性得到解决,那么,如何保持数据架构的持续性乃至整个软件系统的持续性呢?希望《持续架构实践》一书可以给大家带来些许的帮助。

【关联阅读】
机器学习系统架构的10个要素
一文弄清混合云架构模式
软件架构的10个质量属性
端边云协同:从云到边缘
浅析面向云架构的SLA
面向数据架构的云演变
IoT云服务连接性的方式
在传感器与云之间
10行Python代码的词云
理解一下混合云
架构软件工程的未来(精要版)
软件架构的10个常见模式
回顾Bob大叔的简洁架构
解读六边形架构
老曹眼中的面向数据架构
从应用架构看大数据
架构大数据应用