概述
心理保健是现代社会一个日益严重的问题。例如,在日本,自杀是 10-39 岁人群的首要死因。此外,根据世界卫生组织(WHO)的数据,自杀是全球年轻人的首要死因。在此背景下,通过短信应用程序提供心理支持的短信咨询正备受关注。
与电话或电子邮件咨询相比,文本咨询的优点是更容易获得,尤其是对年轻一代而言,心理障碍较少。然而,目前缺乏有经验的辅导员。即使是那些有面对面、电话或电子邮件咨询经验的人,如果没有适当的指导和培训,也很难提供文本咨询。此外,能够提供这种适当指导的人员也很缺乏。
在此背景下,人们正在研究利用自然语言处理技术为心理健康提供支持的方法。其中,自动检测心理健康问题和障碍是一个备受关注的研究领域。在对话系统领域,已经开发出一些旨在改善心理健康的系统。另一方面,尽管最近在大规模语言建模方面的发展显示了对各种任务和领域的适应性,但使用大规模语言建模的咨询对话系统的性能尚未得到全面评估。
本文使用 GPT-4 构建了一个咨询对话系统,并由专业咨询师对生成的回复进行评估。为了生成适当的回复,我们通过与专业辅导员的角色扮演情景收集了辅导对话数据,并在语句中标注了辅导员的意图。为了评估在真实咨询情境中使用对话系统的可行性,第三方咨询师正在评估人类咨询师和 GPT-4 在角色扮演对话数据的相同情境中生成的回复是否恰当。
收集角色扮演对话并生成辅导员的回应
两名辅导员参与了角色扮演对话的收集工作,其中一人扮演求助者,另一人扮演辅导员,对话使用消息应用程序LINE 以日语进行。共收集了六次对话数据,下表所列的六个主题各一次。

为了测试大规模语言模型在咨询对话中的有效性,我们使用收集到的角色扮演对话数据,以咨询者的身份在 GPT-4 上生成语句。如下表所示,为了获得高质量的回复,收集到的辅导员话语都标注了回复要点(Key point)和意图(Intent)。
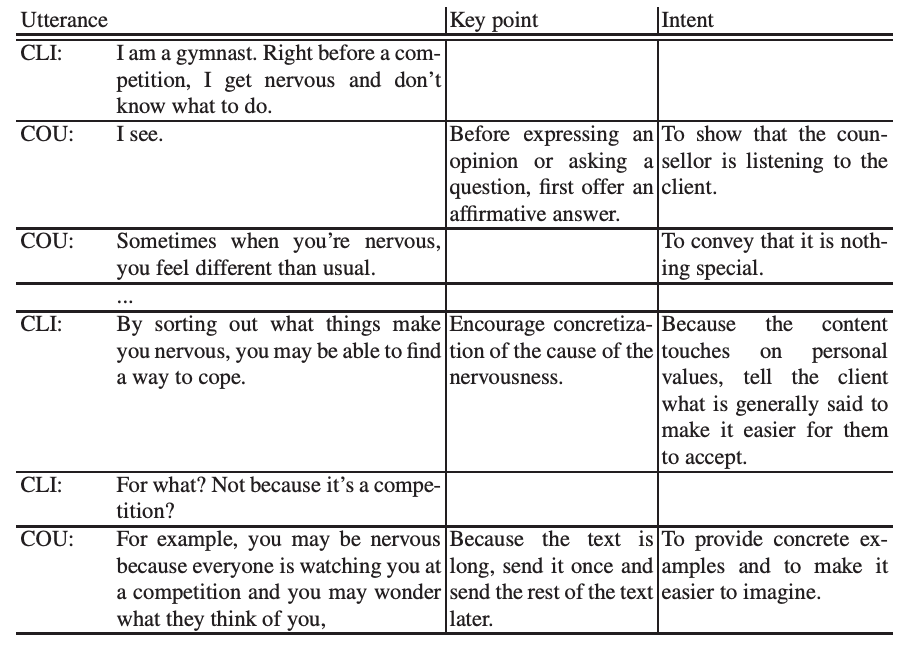
用于提示 GPT-4 生成回复的提示也显示在下表中。该提示指示 GPT-4 以辅导员的身份作出回应,同时还增加了由专业辅导员监督的指导原则。该提示还包括辅导员与客户之间正在进行的对话。

对话包含从开始到前一位客户发言的所有文本,辅导员在发言之前会对回答的要点和意图进行注释,如下表所示。
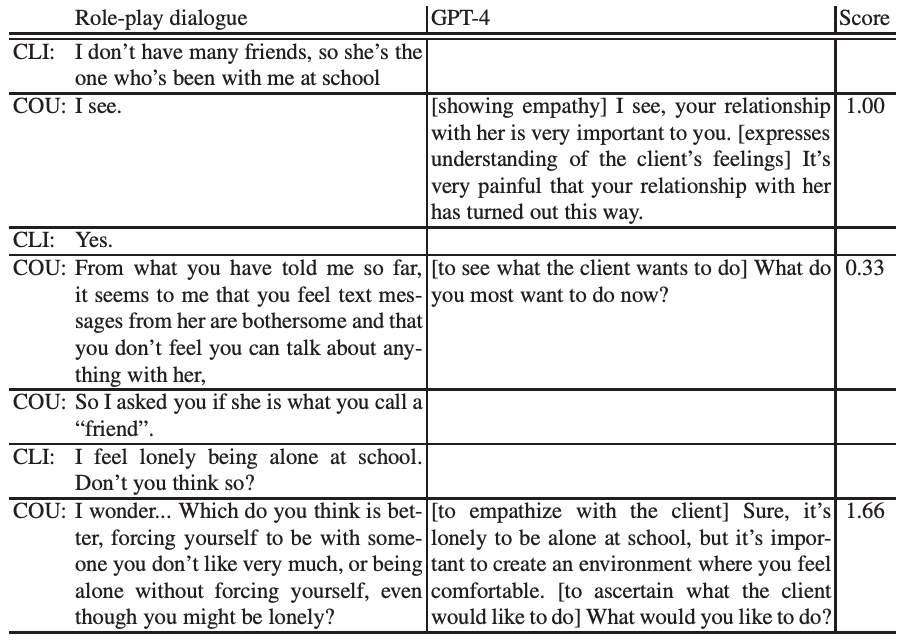
GPT-4使用OpenAI APIGPT-4-0613,温度为 0.0,其他参数保持默认设置。生成语篇的统计数据如下表所示。
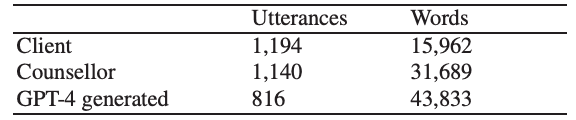
人类辅导员的发言次数之所以高于 GPT-4 的发言次数,是因为 GPT-4 一次只生成一个发言,而在角色扮演情景中,人类发言人可以发送一系列信息。
分析
专家辅导员对角色扮演对话和 GPT-4 生成的话语进行评分。评分采用 0(差)至 2(好)的三点李克特量表,每段对话有三名辅导员参与。评分原因也被记录在案,共有七位辅导员参与评分。下表显示了生成的对话样本以及每位辅导员的平均得分。
请注意,计算克里彭多夫阿尔法系数的目的是衡量主题 1 至 3 对话(辅导员话语:157,GPT-4 话语:124)评分的一致程度,阿尔法系数为 0.24,表明评分者之间的相关性较弱。
辅导员和 GPT-4 语篇的平均评分分别为 0.99(方差:0.49)和 0.94(方差:0.61)。我们还在 0.05 的显著性水平上进行了曼-惠特尼 U 检验,结果没有发现显著差异。这表明辅导员和 GPT-4 在答复质量方面没有明显差异。
下图显示了辅导员和 GPT-4 对话语的评分百分比,表明 GPT-4 的话语比辅导员的话语更常被评为 0 分和 2 分。
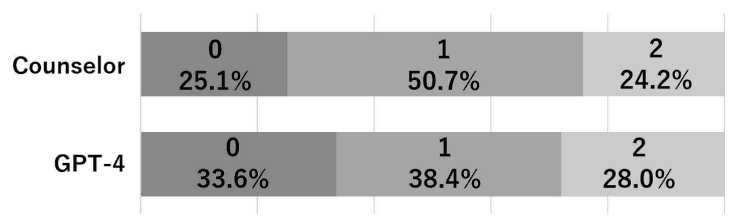
半数以上辅导员的话语被评为 1 分,这是因为 "我明白了 "和 "是的 "等简短话语被评为 1 分。
评估结果表明,评分者的评分倾向存在个体差异。因此,我们分析了同一评分者在同一情境下如何对心理咨询师的话语和 GPT-4 的话语进行评分。如果辅导员在求助者做出反应之前说了一系列话语,那么所有话语的平均评分将作为辅导员话语的评分。结果如下表所示。

比较辅导员与 GPT-4 评为优秀的发言百分比,34.8% 对 30.5%,虽然高于GPT-4,但差距较小,34.7% 的发言被评为等同(Tie) GPT-4 反应的质量与辅导员的反应非常接近非常接近辅导员的答复。鉴于大规模语言模型生成的回复即使在提示语没有完全解释清楚的情况下也能与人类的回复相媲美,GPT-4 的性能还可以进一步提高,预计基于大规模语言模型的系统可用于实际提供咨询。
案例研究
在真实对话系统中提供咨询时,必须尽量减少不恰当的反应。本文分析了这一被低估的 GPT-4 反应。
评分较低的回答被认为是语言或措辞不当或不自然所致。例如,使用 "有趣 "一词可能会冒犯求助者。辅导员可能会认为这个词把求助者的问题当作好奇的对象(有趣)。
他们还指出,GPT-4 的回答可能会把客户的问题当成别人的问题。例如,评估员指出,"这听起来很困难 "这句话被认为是不真诚的,应避免使用。
避免有风险的回答在咨询中尤为重要:GPT-4 生成的语句不包含攻击性或歧视性言论,但也发现了少量有风险的语句。例如,"仁慈会让你受苦 "这一回答可能会灌输错误的价值观,即人不应该仁慈。
虽然在本次验证中发现的高危反应数量很少,但如果输入提示包含攻击性内容,GPT-4 就会倾向于生成攻击性语句作为反应。虽然在本文的角色扮演对话中没有产生攻击性内容,但在真实的咨询情境中,客户有可能会包含攻击性内容。未来的研究应分析此类情况,开发更安全、更有效的咨询对话系统。
总结
本文收集了角色扮演咨询对话数据,并对其进行了注释,由专业咨询师对 GPT-4 生成的回答是否恰当进行了评估。结果表明,GPT-4 的回复质量与人类辅导员的回复质量相当。他们还报告说,被评为低分的回答不包括攻击性、歧视性或高风险的回答。
这篇论文是探索人工智能在实际咨询工作中的作用的重要的第一步:GPT-4 几乎与人类咨询师一样出色的发现表明,人工智能未来可以在咨询领域发挥重要作用。
不过,他们也指出,要实现完全自动化的咨询服务,还需要进一步的验证和改进。我们的目标是开发一个能够理解人类情绪和细微差别并做出适当反应的人工智能系统,这需要在各种场景中进行测试并不断改进。
通过这些论文,我们希望人工智能技术的发展和进一步的研究能使人们更容易获得咨询。这可以创造一种环境,让有严重问题的人能够得到及时的支持。
注:
论文地址:https://arxiv.org/pdf/2402.12738
原文地址:https://ai-scholar.tech/articles/large-language-models/gpt4-counselling



![HTB:PermX[WriteUP]](https://i-blog.csdnimg.cn/direct/99fffde6ea264c81a6ea859e072f4b4e.png)