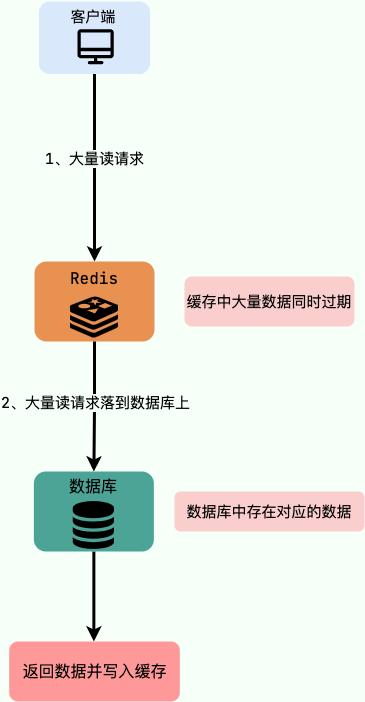
在人工智能与机器学习领域,Google的TensorFlow无疑是最受欢迎的学习框架之一。TensorFlow不仅支持构建和训练深度学习模型,还提供了高度灵活的API和跨平台兼容性,使其适用于从实验研究到工业应用的广泛场景。本文将带你详细了解TensorFlow的功能、核心概念以及基本的使用方法,帮助你快速入门并掌握这一强大的AI学习框架。
一、TensorFlow简介
TensorFlow是Google在2015年推出的开源机器学习框架,以其高性能和可扩展性迅速获得了广泛的应用。TensorFlow采用计算图(Computation Graph)机制,在图上定义节点和边,用来表示计算任务和数据流。通过这种设计,TensorFlow可以灵活地部署到不同的硬件设备上,包括CPU、GPU,甚至TPU(Tensor Processing Unit),使其成为一个功能强大的多平台框架。
主要特点:
1. 多设备支持:支持在多个硬件平台上运行,包括CPU、GPU和TPU。
2. 灵活性强:提供低级API供开发者实现自定义操作,也有高级API(如Keras)来简化操作。
3. 庞大的社区和丰富的工具生态:丰富的官方教程、社区资源和工具(如TensorBoard)使学习和使用更加便捷。
二、TensorFlow的核心概念
要熟练掌握TensorFlow,理解其核心概念非常重要。以下是一些TensorFlow中的关键术语:
1. 张量(Tensor):TensorFlow的基本数据结构,类似于Numpy数组。张量可以是任意维度的数据结构,如标量(0维)、向量(1维)、矩阵(2维)等。
2. 计算图(Computational Graph):TensorFlow通过计算图定义了数据流。计算图中的节点代表运算操作,边则代表张量的数据流。所有的计算都在计算图中完成,提供了很高的灵活性和跨设备兼容性。
3. 会话(Session):在TensorFlow 1.x中,会话是用来执行计算图的环境。尽管在TensorFlow 2.x版本中会话已被简化,但理解它仍有助于掌握TensorFlow的计算方式。
4. 自动微分:TensorFlow内置自动微分功能,可以自动计算梯度,简化模型训练中的反向传播过程。
三、TensorFlow的安装与配置
在使用TensorFlow之前,你需要在本地或云端配置好开发环境。
1. 安装TensorFlow
TensorFlow可以通过Python的包管理工具pip安装。你可以在命令行中运行以下命令:
pip install tensorflow2. 配置GPU支持(可选)
如果你的设备支持GPU,可以加速模型的训练过程。安装CUDA和cuDNN后,你可以直接使用GPU加速。安装过程中请务必参照TensorFlow官网的安装指南,以确保版本兼容性。
四、TensorFlow的基本使用:实现简单的线性回归
下面,我们通过一个简单的线性回归实例,演示TensorFlow的基本用法。
1. 导入必要的库
首先,导入TensorFlow库:
import tensorflow as tf2. 准备数据集
创建一个简单的线性数据集,用于演示:
import numpy as np# 生成一些线性数据
X = np.array([1, 2, 3, 4, 5], dtype=np.float32)
Y = np.array([2, 4, 6, 8, 10], dtype=np.float32)3. 定义模型结构
使用TensorFlow的tf.keras.Sequential创建一个简单的线性模型:
model = tf.keras.Sequential([tf.keras.layers.Dense(units=1, input_shape=[1])
])4. 编译模型
使用均方误差(MSE)作为损失函数,选择梯度下降优化器:
model.compile(optimizer='sgd', loss='mean_squared_error')5. 训练模型
使用fit方法对模型进行训练:
model.fit(X, Y, epochs=100)6. 模型预测
在训练结束后,你可以通过模型进行预测:
print(model.predict([6]))在这里,我们创建了一个简单的线性回归模型。通过定义、编译和训练,模型可以根据数据拟合出一个线性关系,并预测新的输入值。虽然这是一个简单的示例,但它展示了TensorFlow的基础流程,为构建更复杂的神经网络打下了基础。
五、TensorFlow应用:构建神经网络
在深度学习中,神经网络是TensorFlow的主要应用场景。下面是一个创建简单前馈神经网络的示例,用于处理MNIST手写数字分类数据集。
1. 加载数据集
TensorFlow内置了MNIST数据集,可以直接调用:
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.02. 构建神经网络模型
创建一个多层感知器(MLP)模型:
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10)
])3. 编译模型
设置优化器、损失函数和评价指标:
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])4. 训练模型
运行训练过程:
model.fit(x_train, y_train, epochs=5)5. 评估模型
评估模型的准确率:
model.evaluate(x_test, y_test, verbose=2)在这里,我们通过TensorFlow构建了一个简单的神经网络模型,并进行了训练和评估。通过这种方式,开发者可以利用TensorFlow来完成各种深度学习任务。
六、总结
TensorFlow作为Google推出的开源框架,在机器学习和深度学习领域占据了重要地位。无论是初学者还是专业开发者,TensorFlow都提供了丰富的工具和资源,帮助用户快速构建、训练和部署模型。通过本文的介绍,你可以尝试在TensorFlow上实现简单的模型,并逐步探索更复杂的神经网络和机器学习任务。