笔者还记得是从大学开始的时候玩的炉石传说,还记得当时的版本只有黑石山,纳克萨玛斯,地精大战侏儒这些卡包,转眼间到了现在,炉石传说早已和之前的那个炉石传说不再一样了,还记得以前的卡牌套路冰法,奴隶战,机械法等等,到现在一系列稀奇八怪的打法,什么偶数萨,天启骑,战吼萨,群星德,青玉德等等.......
这个游戏的变化太大了,感觉真的追不动了,于是,小编准备弃坑了,不去玩炉石了,再此之前,为了纪念一下我那逝去的炉石青春,就把它的所有卡牌都整理出来吧!
首先,我们先找到卡牌的网址:
http://cha.17173.com/hs/

接下来我们要采取爬虫的方式来获取卡牌了,由于网址是异步加载的,所以我们采用selenium来自动爬取网页上的内容。

下面我们要先找打页面上所有卡牌的特征,之后采用正则去匹配卡牌的图片:
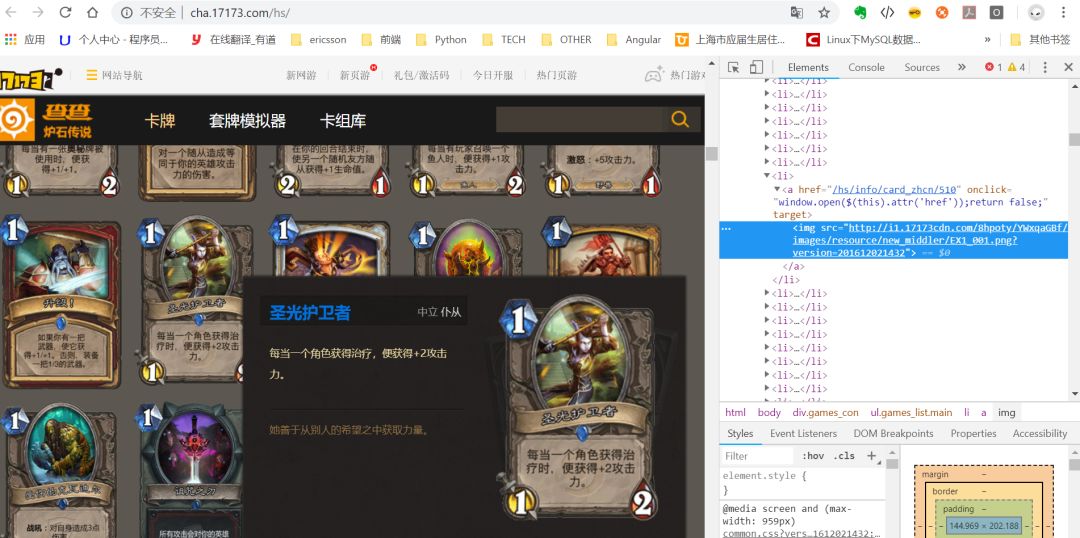
所有的卡牌的是img标签里面的,所以我们可以大胆地写正则了:
"window.open($(this).attr('href'));return false;" target=""><img src="(.*?)"
咋一看看起来写的太长了,感觉不好,那就适当的再修改一下:
e;" target=""><img src="(.*?)"
这样就不错了
()里面使我们需要匹配的内容。
由于时间关系,我就直接贴代码了,注释都在代码里:
def get_html():
browser = webdriver.Chrome(r'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
browser.get('http://cha.17173.com/hs/')
for i in range(90):
browser.execute_script('var q=document.documentElement.scrollTop='+str(i*1000))
time.sleep(1)
time.sleep(1)
html = browser.page_source.encode('GBK', 'ignore').decode('GBk')
browser.close()
return html
def get_imgs(html):
img_urls = re.findall('e;" target=""><img src="(.*?)"', html)
for img_url in img_urls:
img_url = img_url.split('?')[0]
img_content = requests.get(img_url).content
with open(img_url.split('/')[-1],'wb') as f:
f.write(img_content)
if __name__ == '__main__':
html = get_html()
get_imgs(html)
大概的结果就是这样了。
喜欢炉石的朋友可以去试试吧!


“SCAN IT”