神经网络量化之 Ristretto、增量量化INQ、IAO代码实战分析
博文末尾支持二维码赞赏哦 _
1. Ristretto 固定点浮点数量化
详细介绍
量化逼近方案
Ristretto允许以三种不同的量化策略来逼近卷积神经网络:
1、动态固定点:修改的定点格式, DYNAMIC_FIXED_POINT。
2、迷你浮点型:缩短位宽的浮点数,MINIFLOAT。
3、两个幂参数:当在硬件中实现时,具有两个幂参数的层不需要任何乘法器,INTEGER_POWER_OF_2_WEIGHTS。
rounding_scheme 量化的舍入方案:
a. 最近偶数(NEAREST)
b. 随机舍入(STOCHASTIC)
网络中将不同的卷基层替换成带有量化的卷基层,新添加了一些新的层:
a. 量化卷基层 ConvolutionRistretto
b. 量化全连接层 FcRistretto,
c. 量化局部响应归一化层 LRNRistretto
d. 量化反卷积层 DeconvolutionRistretto
新层 定义 src/caffe/proto/caffe.proto
message LayerParameter {
...optional QuantizationParameter quantization_param = 145;
// 新添层参数 量化参数 quantization_param
...}message QuantizationParameter{+ enum Precision { // 量化策略 3种量化方法 枚举
+ FIXED_POINT = 0; // 定点/动态定点
+ MINI_FLOATING_POINT = 1; // 迷你浮点
+ POWER_2_WEIGHTS = 2; // 二进制指数
+ }
+ optional Precision precision = 1 [default = FIXED_POINT];
+ // 量化策略 precision 默认为 定点/动态定点+ enum Rounding { // 量化的舍入方案 取整方法 枚举
+ NEAREST = 0; // 最近偶数
+ STOCHASTIC = 1; // 随机舍入(向上或向下取整)
+ }
+ optional Rounding rounding_scheme = 2 [default = NEAREST];
+ // 量化的舍入方案 rounding_scheme 默认为 最近偶数+ // Fixed point precision 定点量化参数
+ optional uint32 bw_layer_out = 3 [default = 32]; //层激活输出数据 量化位宽
+ optional uint32 bw_params = 4 [default = 32];//卷积核w 数据 量化位宽
+ optional int32 fl_layer_out = 5 [default = 16];//层激活输出数据小数部分量化位宽
+ optional int32 fl_params = 6 [default = 16]; //卷积核w 数据小数部分量化位宽+ // Mini floating point precision 迷你浮点数量化参数
+ optional uint32 mant_bits = 7 [default = 23];
+ // 尾数尾数 32位:1+8+23 16位: 1+5+10
+ optional uint32 exp_bits = 8 [default = 8]; // 指数尾数+ // Power-of-two weights 二进制指数量化参数
+ optional int32 exp_min = 9 [default = -8]; // 使用的最小指数 2(-8)
+ optional int32 exp_max = 10 [default = -1]; // 使用的最大指数 2(-1)
+}
Fixed point precision 定点量化参数 计算
tools/ristretto.cpp —> src/caffe/ristretto/quantization.cpp ---->
Quantization::QuantizeNet() -----> RunForwardBatches() ----> caffe_net->RangeInLayers()
(找出各层参数的绝对最大值, src/caffe/net.cpp 中)
// 找到 数据BOLB中的 最大绝对值的参数值
template <typename Dtype>
Dtype Net<Dtype>::findMax(Blob<Dtype>* blob)
{const Dtype* data = blob->cpu_data();int cnt = blob->count();// blob->count() 获取总数量Dtype max_val = (Dtype)-10;// 初始化最大值 -10for (int i = 0; i < cnt; ++i) // 遍历 BOLB中的每一个参数{max_val = std::max(max_val, (Dtype)fabs(data[i]));// 绝对最大值// max_val = std::max(max_val, (Dtype)data[i]); // 实际最大值// min_val = std::min(min_val, (Dtype)data[i]); // 实际最小值}return max_val;
}
//
// 遍历每一层 获取每一层 参数/输入/输出 数据中的 最大最小等值
// 这里还可以记录更复杂的 统计数据======================================
template <typename Dtype>
void Net<Dtype>::RangeInLayers(vector<string>* layer_name,// 返回包含所有层名字的 数组vector<Dtype>* max_in, // 返回层输入最大值 数组vector<Dtype>* max_out, // 返回层输出最大值 数组vector<Dtype>* max_param) // 返回层权重参数 最大值 数组{// Initialize vector elements, if needed.// 初始化 各种函数返回的 数据对象====================================if(layer_name->size() == 0 ) {for (int layer_id = 0; layer_id < layers_.size(); ++layer_id) // 变量每一层 layer_id < layers_.size(){// 记录所有层类型为 卷积层/全连接层 的 层名字if (strcmp(layers_[layer_id]->type(), "Convolution") == 0 || strcmp(layers_[layer_id]->type(), "InnerProduct") == 0) {layer_name->push_back(this->layer_names()[layer_id]);// 层名字max_in->push_back(0); // 初始化输入最大值为0 并创建vector空间 push_back()max_out->push_back(0); // 初始化输出最大值为0max_param->push_back(0);// 初始化卷积参数最大值为0} }}
// 找到各层的最大值==================================================// Find maximal values.int index = 0;Dtype max_val;for (int layer_id = 0; layer_id < layers_.size(); ++layer_id) { // 统计所有层类型为 卷积层/全连接层 的 层名字if (strcmp(layers_[layer_id]->type(), "Convolution") == 0 || strcmp(layers_[layer_id]->type(), "InnerProduct") == 0) {max_val = findMax(bottom_vecs_[layer_id][0]);// 输入值 bottom_vecs_ 最大绝对值max_in->at(index) = std::max(max_in->at(index), max_val);// max(0,max_) 至少为0max_val = findMax(top_vecs_[layer_id][0]);// 输出值 top_vecs_ 最大绝对值max_out->at(index) = std::max(max_out->at(index), max_val);// max(0,max_) 至少为0// Consider the weights only, ignore the bias 这里统计权重参数 仅仅考虑了 w 的范围,没有考虑 偏置b的范围max_val = findMax(&(*layers_[layer_id]->blobs()[0]));// &(*layers_[layer_id]->blobs()[0])max_param->at(index) = std::max(max_param->at(index), max_val);//max(0,max_) 至少为0index++;}}// 其他 方式统计
}
动态固定点 量化方法 Quantization::Quantize2DynamicFixedPoint()
// 计算整数数值所需的 量化位宽 2^x = max, x = log2(max)for (int i = 0; i < layer_names_.size(); ++i) {il_in_.push_back((int)ceil(log2(max_in_[i])));il_out_.push_back((int)ceil(log2(max_out_[i])));il_params_.push_back((int)ceil(log2(max_params_[i])+1));
}
// 指定量化位宽===================================
bw_conv_params_ = 8; // 卷积层 卷积参数 量化总位宽
bw_fc_params_ = 8; // 全连接层 卷积参数 量化总位宽
bw_out_ = 8; // 层激活输出 量化总位宽
bw_in_ = bw_out_; // 层激活输如 量化总位宽// 编辑网络参数,替换卷积层,全连接层,写入 卷积参数和激活值的 量化参数EditNetDescriptionDynamicFixedPoint(¶m, "Convolution_and_InnerProduct","Parameters_and_Activations", bw_conv_params_, bw_fc_params_, bw_in_,
bw_out_);编辑网络参数EditNetDescriptionDynamicFixedPoint()
void Quantization::EditNetDescriptionDynamicFixedPoint(NetParameter* param,const string layers_2_quantize, const string net_part, const int bw_conv,const int bw_fc, const int bw_in, const int bw_out)
{for (int i = 0; i < param->layer_size(); ++i)// 遍历网络中的每一层{
// 修改卷积层 Convolution 添加量化参数============================if (layers_2_quantize.find("Convolution") != string::npos &¶m->layer(i).type().find("Convolution") != string::npos) {// quantize parameters 添加卷积参数量化参数if (net_part.find("Parameters") != string::npos) {LayerParameter* param_layer = param->mutable_layer(i);// 取当前层的原有网络参数param_layer->set_type("ConvolutionRistretto");// 替换层类型为 ConvolutionRistretto// 设置小数位量化位宽=总位宽-整数位位宽param_layer->mutable_quantization_param()->set_fl_params(bw_conv -GetIntegerLengthParams(param->layer(i).name()));// 设置总量化位宽 param_layer->mutable_quantization_param()->set_bw_params(bw_conv);}// quantize activations 量化激活值部分量化参数{LayerParameter* param_layer = param->mutable_layer(i);param_layer->set_type("ConvolutionRistretto");// 设置激活输入 小数位量化位宽param_layer->mutable_quantization_param()->set_fl_layer_in(bw_in -GetIntegerLengthIn(param->layer(i).name()));param_layer->mutable_quantization_param()->set_bw_layer_in(bw_in);// 设置激活输出 小数位量化位宽 param_layer->mutable_quantization_param()->set_fl_layer_out(bw_out -GetIntegerLengthOut(param->layer(i).name()));param_layer->mutable_quantization_param()->set_bw_layer_out(bw_out);}}
// 修改 全连接层 Convolution 添加量化参数============================if (layers_2_quantize.find("InnerProduct") != string::npos &&(param->layer(i).type().find("InnerProduct") != string::npos ||param->layer(i).type().find("FcRistretto") != string::npos)) {// quantize parameters 添加卷积量化参数if (net_part.find("Parameters") != string::npos) {LayerParameter* param_layer = param->mutable_layer(i);param_layer->set_type("FcRistretto");param_layer->mutable_quantization_param()->set_fl_params(bw_fc -GetIntegerLengthParams(param->layer(i).name()));param_layer->mutable_quantization_param()->set_bw_params(bw_fc);}// quantize activations 添加激活值量化参数if (net_part.find("Activations") != string::npos) {LayerParameter* param_layer = param->mutable_layer(i);param_layer->set_type("FcRistretto");param_layer->mutable_quantization_param()->set_fl_layer_in(bw_in -GetIntegerLengthIn(param->layer(i).name()) );param_layer->mutable_quantization_param()->set_bw_layer_in(bw_in);param_layer->mutable_quantization_param()->set_fl_layer_out(bw_out -GetIntegerLengthOut(param->layer(i).name()) );param_layer->mutable_quantization_param()->set_bw_layer_out(bw_out);}}}
}
网络新层量化部分
conv_ristretto_layer.cpp ----> base_ristretto_layer.cpp
----> BaseRistrettoLayer::QuantizeWeights_cpu() —> Trim2FixedPoint_cpu()
template <typename Dtype>// 模板类型 Dtype
void BaseRistrettoLayer<Dtype>::QuantizeWeights_cpu(vector<shared_ptr<Blob<Dtype> > > weights_quantized, // 需要量化的 blob 数组const int rounding, // 量化取整方案const bool bias_term) // 是否量化 bias
{Dtype* weight = weights_quantized[0]->mutable_cpu_data();const int cnt_weight = weights_quantized[0]->count(); switch (precision_) {case QuantizationParameter_Precision_MINIFLOAT:Trim2MiniFloat_cpu(weight, cnt_weight, fp_mant_, fp_exp_, rounding); if (bias_term) {Dtype* bias = weights_quantized[1]->mutable_cpu_data();const int cnt_bias = weights_quantized[1]->count(); Trim2MiniFloat_cpu(bias, cnt_bias, fp_mant_, fp_exp_, rounding);}break;
// 动态固定点量化方案=========================================case QuantizationParameter_Precision_DYNAMIC_FIXED_POINT:// 量化 weight fx = a × w + bTrim2FixedPoint_cpu(weight, cnt_weight, bw_params_, rounding, fl_params_);// 量化 b if (bias_term) {Dtype* bias = weights_quantized[1]->mutable_cpu_data();const int cnt_bias = weights_quantized[1]->count(); Trim2FixedPoint_cpu(bias, cnt_bias, bw_params_, rounding, fl_params_);}break;case QuantizationParameter_Precision_INTEGER_POWER_OF_2_WEIGHTS:Trim2IntegerPowerOf2_cpu(weight, cnt_weight, pow_2_min_exp_, pow_2_max_exp_,rounding);// Don't trim biasbreak;default:LOG(FATAL) << "Unknown trimming mode: " << precision_;break;}
}动态固定点量化方法 Trim2FixedPoint_cpu()
template <typename Dtype>// 模板类型 Dtype
void BaseRistrettoLayer<Dtype>::Trim2FixedPoint_cpu(Dtype* data, // 数据起始指针const int cnt, // 数量const int bit_width,// 量化总位宽const int rounding, // 取整策略int fl) // 小数位量化位宽
{
// 计算对应量化上限 总位宽内包含一个0,所以 bit_width - 1
// 全部为整数位宽时,最大值为 2^(bit_width - 1)
// 去除小数位所占位宽: 2^(bit_width - 1)/2^fl = 2^(bit_width - 1)*2^(-fl)Dtype max_data = (pow(2, bit_width - 1) - 1) * pow(2, -fl);Dtype min_data = -pow(2, bit_width - 1) * pow(2, -fl);for (int index = 0; index < cnt; ++index)// 遍历每一个需要量化的数据{// Saturate data 数据饱和处理,上下截断,限幅data[index] = std::max(std::min(data[index], max_data), min_data);// Round datadata[index] /= pow(2, -fl);// 放大小数部分 对应的位宽倍数{case QuantizationParameter_Rounding_NEAREST:data[index] = round(data[index]);// 最近偶数取整break;case QuantizationParameter_Rounding_STOCHASTIC:data[index] = floor(data[index] + RandUniform_cpu());// 随机取整break;default:break;}data[index] *= pow(2, -fl);// 最后再反量化会小数 缩小对应的位宽倍数}
}
反向更新策略
前向传播时,使用量化后的参数进行计算,同时保留量化后的参数和全精度的参数。
反向传播时,对全进度的参数进行更新。
之后再次对更新的参数进行量化,再次前向传播,反向传播更新全精度权重,如此往复。
保存网络权重时,保存量化后的参数,但是是以全精度位宽进行保存的,所以宏观上权重文件大小不变。
2. 增量量化 INQ
详细解读
数量上-增量式神经网络量化。
属于增量型量化的方式。
增量型量化的基本思路是,部分的对参数或者激活函数进⾏量化处理,
使得整个量化过程更加平稳。
这⾥的 部分 可以有多种层⾯,可以是数量上的部分,也可以是程度上的部分。INQ,是从数量上,不断增加 quantized 参数的数量.
增量量化
- INQ 数量上逐步量化
http://arxiv.org/abs/1702.03044 - Bottom-to-Top 分层 来增量型量化。
http://arxiv.org/abs/1607.02241 - BinaryRelax 二值量化的增量量化
http://arxiv.org/abs/1801.06313
主要思想
在载入网络参数的同时,对参数进行量化,按照权重大小进行重要性排序,
每次量化部分最重要的一些参数,同时标记已经量化的参数,
在反向传播更新时,仅更新未量化的参数,多次量化微调之后,量化全部的参数。
代码部分
blob.cpp 逐步量化策略
// Blob<Dtype>::FromProto() // 510行前后
// net.cpp 中 载入权重函数 CopyTrainedLayersFrom() 会调用 Blob<Dtype>::FromProto()
// 传入标记值(是否量化的标志, is_quantization 可对w、b进行量化,未考虑BN层参数,激活值)// INQ if(is_quantization)// 根据标志位,对部分进行量化以及不量化// 如 权重w量化 而 bias不量化{
Dtype* data_copy=(Dtype*) malloc(count_*sizeof(Dtype));// 新申请blob一样大小的内存caffe_copy(count_,data_vec,data_copy); // 拷贝数据 xcaffe_abs(count_,data_copy,data_copy); // 绝对值处理 abs(x)std::sort(data_copy,data_copy+count_); // 排序处理(升序)
// 计算上限 n1 //caculate the n1 上限 : W -> {±2^(n1), ... ,±2^(n2), 0}Dtype max_data = data_copy[count_-1];// 升序后最后一个数为最大值 为 s = max(abs(x))int n1=(int)floor(log2(max_data*4.0/3.0));// n1 = floor(log2(4*s/3))
// 量化的分割点
// 第一次 (1-0.7) 第二次(1-0.4) 第三次(1-0.2) 最后一次(1-0)int partition=int(count_*0.7)-1;// 每次量化的比例 分界点for (int i = 0; i < (count_); ++i) {if(std::abs(data_vec[i]) >= data_copy[partition])// 优先量化 绝对值较大的 权重参数=========={data_vec[i] = weightCluster_zero(data_vec[i],n1);// 进行量化,在 until/power2.cpp中实现
// data_vec[i] 量化为 +pow(2,ni) / -pow(2,ni) , ni: n1-7:n1, 选择量化误差最小的一个
// 权重值-----> pow(2,i)mask_vec[i]=0;// 置位 已经量化的标志=======================}}// 代码其实有点小问题,data_copy malloc 使用完之后 没有 free释放free(data_copy); }
until/power2.cpp 具体量化方法
int bits = 8;// 量化精度// 量化 权重值-----> pow(2,i)=========
// weight 量化为 +pow(2,ni) / -pow(2,ni) , ni: n1-7:n1, 选择量化误差最小的一个template <typename Dtype>double weightCluster_zero( Dtype weight, int M){double min=100;double ind=0;double flag=1.0;// 最小值if(min > std::abs(weight)){min = std::abs(weight);flag=0.0;// 权重绝对值未超过100}
// the number 7 (default, n2的值 ) is corresponding to 5 bits in paper,
// you can modify it, 3 for 4 bits, 1 for 3 bits, 0 for 2 bits.
// n2 = n1 + 1 −2^(b−1)/2 = n1 - (2^(b−2)-1)
// For instance, if b = 3(量化精度) and n1 = −1, it is easy to get n2 = −2,
// if b=5, n1 = −1, n2= -1 + 1-(2^(5-1))/2 = -8
// 0 for 2 bits
// 1 for 3 bits
// 3 for 4 bits
// 7 for 5 bits
// 15 for 6 bits
// 31 for 7 bits 2^b - 1
// 63 for 8 bitsint bias = pow(2, bits-2) - 1;// n2 = n1 - 2^(b-2)+1for(int i=(M-bias);i<=M;i++)// 从最高比特位 M=n1 到 n1-n2 进行遍历{ if(min > std::abs(weight - pow(2,i)))// weight 量化为 +pow(2,i) 的量化差值{min = std::abs(weight - pow(2,i));// 最小量化差值ind=i;flag=1.0;// weight 量化为 +pow(2,i)} if(min > std::abs(weight + pow(2,i)))// weight 量化为 -pow(2,i) 的量化差值{min = std::abs(weight + pow(2,i));// 最小量化差值ind = i;flag = -1.0;}}return flag*pow(2,ind);// 量化后的值}
训练 更新参数值 SGDSolver.cpp
#ifndef CPU_ONLY
// sgd方法计算各参数 更新权重 diff=========================sgd_update_gpu(net_params[param_id]->count(),net_params[param_id]->mutable_gpu_diff(),history_[param_id]->mutable_gpu_data(),momentum, local_rate);
// 使用 量化mask 对 diff 进行滤波,已经量化后的参数不再进行更新========
// diff = mask * diff;caffe_gpu_mul(net_params[param_id]->count(),net_params[param_id]->gpu_mask(),net_params[param_id]->mutable_gpu_diff(),net_params[param_id]->mutable_gpu_diff());
// 在re-training中,我们只对未量化的那些参数进行更新。
// 待更新的参数,mask中的值都是1,这样和diff相乘仍然不变;
// 不更新的参数,mask中的值都是0,和diff乘起来,相当于强制把梯度变成了0。
3. uint8整形量化 IAO
详细参考
对量化的实现是通过把常见操作转换为等价的八位版本达到的。
涉及的操作包括卷积,矩阵乘法,激活函数,池化操作,以及拼接。
转换脚本先把每个已知的操作替换为等价的量化版本。
然后在操作的前后加上含有转换函数的子图,将input从浮点数转换成8 bit,
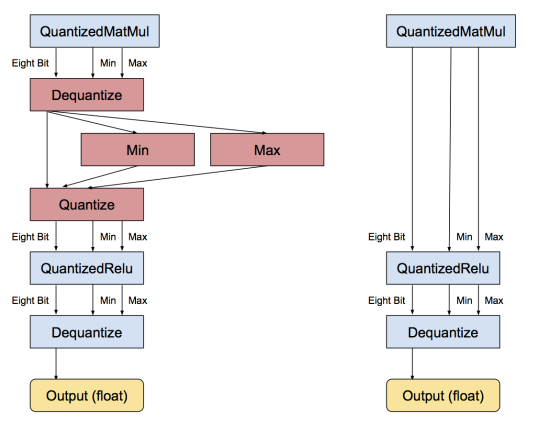
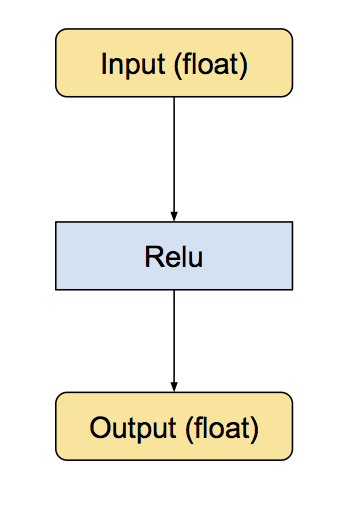
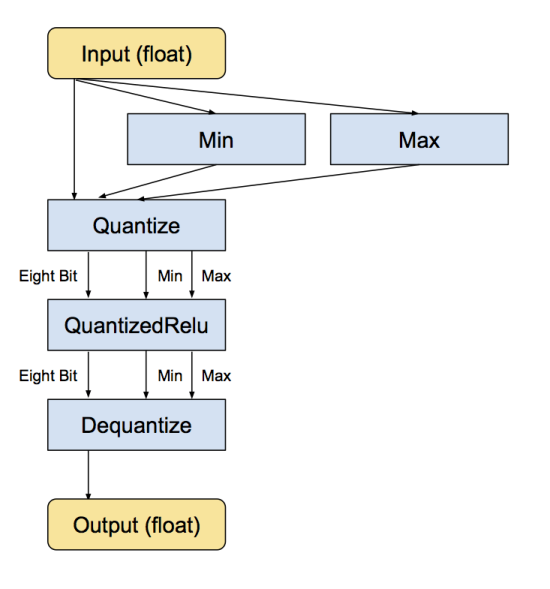
再把output从8 bit转回浮点数。下面是 ReLu 的例子:
浮点版本 relu层:
量化版本 relu层:
谷歌IAO算法实现细节
a. 记录各层 激活输入、卷积核参数、激活输出的参数范围 max min,而量化范围为0~255 uint_8b. 计算量化参数,缩放尺度S 和 零点(偏移量) Zfloat S = (max-min)/ (255-0);uint8_t Z = round(0 – min/S) ;c. 量化输入in_ 和 卷积参数 w_in_quan = in_/S_in + Z_in;w_quan = w_/S_w + Z_w;d. 浮点矩阵乘法 变成 量化卷积乘法out_ = sum( in_(i) * w_(i) );// 浮点矩阵乘法= (S_in * S_W) * sum( (in_quan-Z_in) * (w_quan – Z_w) );==> out_quan = out_/S_out + Z_out;==> = (S_in * S_W/ S_out) * sum( (in_quan-Z_in) * (w_quan – Z_w) ) + Z_out式中 (S_in * S_W/ S_out) 仍为浮点数,所以也需要转换成整数浮点乘子 real_multiplier = S_in * S_W / S_out;量化乘子 quantized_multiplier = round(real_multiplier * (1 << 31)); 扩大2^31次方变成32位整数e. 之后再将整数结果转换成 浮点结果 用于后续计算out_ =(out_quan -Z_out) * S_out;
Inference
量化就是把float型的数值映射到int8或者uint8来进行卷积运算 缩放系数 S = (max_x - min_x)/(255-0)偏置零点 Z = - min_x/Sr = S * (q-Z) 反量化q = r/S + Z 量化r - 需要量化的float型数值 q - 量化后的uint8类型数值 Z - 量化前r = 0时,量化后q的数值 S - 为了能把量化后的q还原到r, 引入了一个缩放系数例如一直input的最大值是30.0,最小值是-10.0,则量化后的值为
Quantized | Float
--------- | -----
0 | -10.0
255 | 30.0
128 | 10.0如何把float类型的乘法用int8替代,paper中的公式写的很明白, 输入: r1 = S1 * (q1 - Z1)r2 = S2 * (q2 - Z2)乘法: out = r1 * r2 = S1 * (q1 - Z1) * S2 * (q2 - Z2) q_out = out / S3 + Z3 = S1 * S2 / S3 * (q1 - Z1) * (q2 - Z2) + Z3= M * (q1 - Z1) * (q2 - Z2) + Z3 公式(4)乘子 M = S1 * S2 / S3本来公式中全部都是int8类型了,只有的个 M 仍然是float类型的, 但是据经验值M是一个大于0小于1的数值,于是我们对M做一些小操作:M = M0 / 2^n 令M0在[0.5, 1)范围内, 举个例子, M = 0.3, 那么M0 = 0.3 * 2, 于是n = 1,然后我们把M0量化到整形数, 具体是16位还是32根据机器决定,以32位为例,M0 = M0 * (1 << 31 ), 取整后 M0 就是一个32位的整型数,此时n = 32, 因此公式(4)中加号后半部分全部为 整型乘法 和 移位操作( 这里M0和另外一部分都为32位的整型,其乘积结果应该是64位的整型)
Training 训练
大家可能还有另外一个疑惑,weight和input的 max, max, S, Z这些都很好计算, paper中S3, Z3(激活值的量化参数) 这些参数在 inference 的时候是不知道的。 这一波操作精妙的地方 在于 一开始就假设 r3 也是 int8 的, 所以 整型矩阵 相乘后 通过 bit shift 等操作,结果仍然是int8类型的, 直接进入下一次卷积操作,而 不需要dequantize 操作, 至于 S3,Z3 这些参数 是在训练过程中计算出来的。激活值中的 max, min 都是在训练过程中使用EMA计算出来的, 作者还提到在 训练刚开始 不太稳定的时候不要对网络进行量化, 待稳定后再量化,可以尽快的使整个网络收敛。
量化代码
1. 找到浮点数的 数据范围 最大值和最小值
// Find the min and max value in a float matrix.
template <gemmlowp::MapOrder tOrder>
void FindMinMax(const gemmlowp::MatrixMap<float, tOrder>& m, float* min,float* max) {*min = *max = m(0, 0);// 初始化最大最小值 为矩阵(0,0)处的值for (int i = 0; i < m.rows(); i++) {for (int j = 0; j < m.cols(); j++) {const float val = m(i, j);*min = std::min(*min, val);// 最小值*max = std::max(*max, val);// 最小值}}
}
2. 计算量化参数 尺度scale 偏移量zero
struct QuantizationParams {float scale; // 缩放尺度std::uint8_t zero_point;// 零点(偏移量)
};
// 根据 最大值和最小值计算量化参数
QuantizationParams ChooseQuantizationParams(float min, float max) {min = std::min(min, 0.f);// 确保最小值 <= 0max = std::max(max, 0.f);// 确保最大值 >= 0// the min and max quantized values, as floating-point values// uint8 量化的数据范围const float qmin = 0;const float qmax = 255;// 计算量化缩放尺度================================// 每一个量化数据单位代表的浮点数大小 0.0~510.0 量化到 0~255 则每一个量化数代表 2const double scale = (max - min) / (qmax - qmin);// 计算 零点(偏移量)===========================const double initial_zero_point = qmin - min / scale;// 对 零点(偏移量) 限幅 并取整=================std::uint8_t nudged_zero_point = 0;if (initial_zero_point < qmin) {nudged_zero_point = qmin;} else if (initial_zero_point > qmax) {nudged_zero_point = qmax;} else {nudged_zero_point =static_cast<std::uint8_t>(std::round(initial_zero_point));}QuantizationParams result;result.scale = scale; // 量化缩放尺度 floatresult.zero_point = nudged_zero_point; // 零点(偏移量) uint8_treturn result;
}
3. 量化 0.0-510.0 量化到 0-255
void Quantize(const QuantizationParams& qparams, const std::vector<float>& src,std::vector<std::uint8_t>* dst)
{assert(src.size() == dst->size());for (std::size_t i = 0; i < src.size(); i++) // 遍历每一个浮点数{const float real_val = src[i]; // 每一个浮点数const float transformed_val = qparams.zero_point + real_val / qparams.scale;const float clamped_val = std::max(0.f, std::min(255.f, transformed_val));// 限制幅度 0.0 ~ 255.0 之间(*dst)[i] = static_cast<std::uint8_t>(std::round(clamped_val));// 取整}
}
4. 反量化 0-255 反量化到 0.0-510.0
void Dequantize(const QuantizationParams& qparams,const std::vector<std::uint8_t>& src, std::vector<float>* dst)
{assert(src.size() == dst->size());for (std::size_t i = 0; i < src.size(); i++) {// 遍历每一个 uint8const std::uint8_t quantized_val = src[i];(*dst)[i] = qparams.scale * (quantized_val - qparams.zero_point);// 变换到浮点数}
}
5. 浮点数卷积运算 FloatMatMul()
void FloatMatrixMultiplication(const gemmlowp::MatrixMap<const float, tLhsOrder>& lhs,const gemmlowp::MatrixMap<const float, tRhsOrder>& rhs,gemmlowp::MatrixMap<float, tResultOrder>* result) {assert(lhs.cols() == rhs.rows());assert(lhs.rows() == result->rows());assert(rhs.cols() == result->cols());for (int i = 0; i < lhs.rows(); i++) {// 每行for (int k = 0; k < rhs.cols(); k++) {// 每列(*result)(i, k) = 0;for (int j = 0; j < lhs.cols(); j++){// lhs_quantized_val = Quantize(lhs);// 上层feature map 输入// rhs_quantized_val = Quantize(rhs);// 本层卷积核// (*result)(i, k) += lhs(i, j) * rhs(j, k);// 卷积块内 求和 使用浮点数(*result)(i, k) += lhs_scale * rhs_scale * (lhs_quantized_val(i, j) - lhs_zero_point) * (rhs_quantized_val(j, k)-rhs_zero_point);// 使用量化数表示浮点数之后运算 得到浮点数结果// 而浮点数结果 也需要进行量化// result_real_value = result_scale *(result_quantized_value - result_zero_point)// result_quantized_value = result_zero_point + result_real_value / result_scale}}}
}
6. 量化卷积运算 QuantizedMatMul()
// ========================================for (int i = 0; i < lhs.rows(); i++) {// 每行for (int k = 0; k < rhs.cols(); k++) {// 每列(*result)(i, k) = 0;for (int j = 0; j < lhs.cols(); j++){// lhs_quantized_val = Quantize(lhs);// 上层feature map 输入// rhs_quantized_val = Quantize(rhs);// 本层卷积核// (*result)(i, k) += lhs(i, j) * rhs(j, k);// 卷积块内 求和 使用浮点数//(*result)(i, k) += lhs_scale * rhs_scale * // (lhs_quantized_val(i, j) - lhs_zero_point) * // (rhs_quantized_val(j, k)-rhs_zero_point);
// (*result)(i, k) += (lhs_quantized_val(i, j) - lhs_zero_point) * (rhs_quantized_val(j, k)-rhs_zero_point); // uint8计算
// === 循环之后 (*result)(i, k) *= lhs_scale * rhs_scale // 得到浮点数// 使用量化数表示浮点数之后运算 得到浮点数结果// 而浮点数结果 也需要进行量化// result_real_value = result_scale *(result_quantized_value - result_zero_point)// result_quantized_value = result_zero_point + result_real_value / result_scale(*result_quantized_value)(i,k) += (lhs_quantized_val(i, j) - lhs_zero_point) * (rhs_quantized_val(j, k)-rhs_zero_point); // uint8计算 }
// 循环之后
(*result_quantized_value)(i,k) = (*result_quantized_value)(i,k) * lhs_scale * rhs_scale / result_scale + result_zero_point;
// 得到 量化数}}总结版本===================================for (int i = 0; i < lhs.rows(); i++) {// 每行for (int k = 0; k < rhs.cols(); k++) {// 每列// (*result_quantized_value)(i, k) = 0;int32_accumulator = 0;for (int j = 0; j < lhs.cols(); j++){
//(*result_quantized_value)(i,k) += (lhs_quantized_val(i, j) - lhs_zero_point) * (rhs_quantized_val(j, k) - rhs_zero_point); // uint8计算
int32_accumulator += (lhs_quantized_val(i, j) - lhs_zero_point) * (rhs_quantized_val(j, k) - rhs_zero_point);}
// 循环之后
(*result_quantized_value)(i,k) = int32_accumulator * lhs_scale * rhs_scale / result_scale + result_zero_point;
// 这里三个尺度参数 lhs_scale 、 rhs_scale 、 result_scale 差不多都是在 0~1.0 范围内的小数。
// 把这部分的 浮点运算也转换一下,变成 32位整数编制}}
7. 小于1的小数 乘子 M 转换成 32位的整数 M0
void QuantizeMultiplierSmallerThanOne(float real_multiplier, // 实际小数 乘数std::int32_t* quantized_multiplier,int* right_shift)
{
// 确保在 0.0~1.0 之间================== assert(real_multiplier > 0.f);assert(real_multiplier < 1.f);
// 改变范围 到 0.5~1 之间===============int s = 0;// 扩大倍数 记录, 之后右移相同的数量,就会还原while (real_multiplier < 0.5f) {real_multiplier *= 2.0f;s++;// 扩大倍数 记录, 之后右移相同的数量,就会还原}// 转换浮点数乘子 [1/2, 1) 到 32位固定点整数std::int64_t q = static_cast<std::int64_t>(std::round(real_multiplier * (1ll << 31))); // 1左移31位,后面的是两个ll 长整形,相当于扩大 2^31次方 =========assert(q <= (1ll << 31));
// 如果原数 real_multiplier 比较趋近于1,将其减半,同时扩大倍数记录-1if (q == (1ll << 31)) {q /= 2;// 将其减半s--;// 同时扩大倍数记录-1}assert(s >= 0);assert(q <= std::numeric_limits<std::int32_t>::max());*quantized_multiplier = static_cast<std::int32_t>(q);*right_shift = s;
}// 调用===================================const float real_multiplier = lhs_scale * rhs_scale / result_scale;int right_shift;// 除去 左移31位,原数的扩大倍数记录std::int32_t quantized_multiplier = QuantizeMultiplierSmallerThanOne(real_multiplier, &quantized_multiplier, &right_shift);
8. 量化卷积计算步骤
1. 输入 量化的特征图 lhs_quantized_val, uint8类型, 偏移量 lhs_zero_point, int32类型;
2. 输入 量化的卷积核 rhs_quantized_val, uint8类型, 偏移量 rhs_zero_point, int32类型;
3. 转换 unit8 到 int32类型;
4. 每一块卷积求和(int32乘法求和有溢出风险,可换成固定点小数树乘法);int32_accumulator += (lhs_quantized_val(i, j) - lhs_zero_point) * (rhs_quantized_val(j, k) - rhs_zero_point);
5. 输入 量化的乘子 quantized_multiplier, int32类型 和 右移次数记录 right_shift, int类型;
6. 计算乘法,得到int32类型的结果 (int32乘法有溢出风险,可换成固定点小数树乘法);quantized_multiplier * int32_accumulator7. 再左移动 right_shift 位还原,得到 int32的结果;
8. 最后再加上 结果的偏移量 result_zero_point;(7和8的顺序和 官方说的先后顺序颠倒);
9. 将int32类型结果 限幅到[0, 255], 再强制转换到 uint8类型;
10. 之后再 反量化到浮点数,更新统计输出值分布信息 max, min;
11. 再量化回 uint8;
11. 之后 经过 量化激活层;
12. 最后 反量化到 浮点数,本层网络输出;13. 进入下一层循环执行 1~12 步骤
当遇到连续的被量化的操作时
有一个优化是当连续出现多个被量化了的操作时,没有必要在每个操作前做反序列化/序列化,
因为上一个操作的反序列化和下一个操作的序列化是会被互相抵消的。
例如下图:
反量化和量化会抵消,左边是量化展开的,右边是去除冗余量化的