介绍
在本文中,我们将学习如何使用 Train Test Split 模型将数据集分为四个部分,开发预测模型,并通过用例分析预测和数据集。
用例——问题陈述
我们这篇文章的目标是预测患者是否患有糖尿病。我们所有的患者都是年轻女性,她们提供的数据(即怀孕次数、血糖水平和 BMI)将用于预测糖尿病。这是我们将要使用的数据集。
机器学习中的训练和测试数据
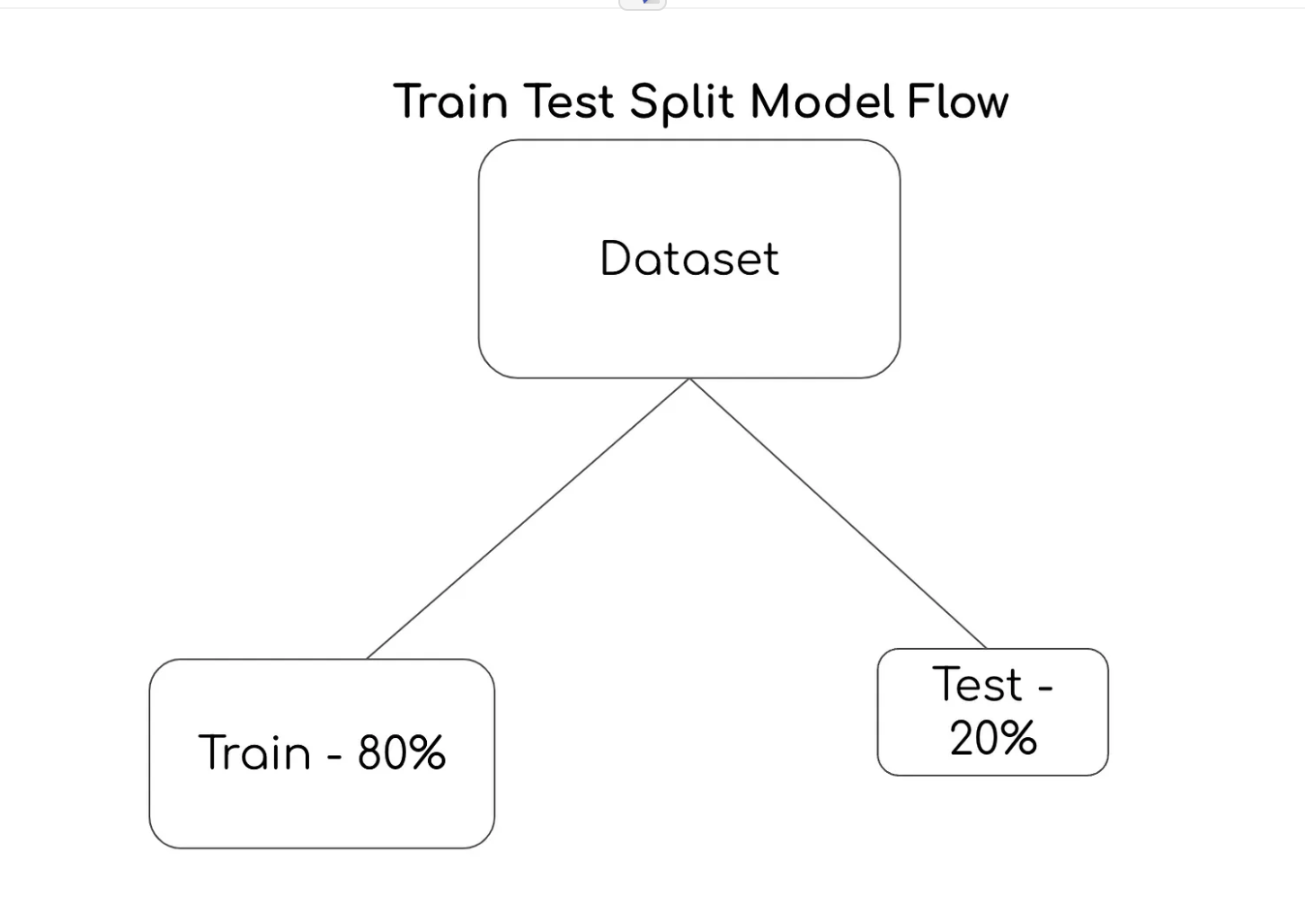
使用数据集,几乎所有机器学习算法都在三个不同的阶段运行:数据预处理、预测模型和数据分析。在该过程的第 1 阶段,数据集被分成 80% 的训练数据和 20% 的测试数据。使用Train Test Split模型,在预测模型和数据分析之前,我们首先要完成数据预处理。
为了开始数据预处理,我们首先需要使用 pip 安装几个Python 库:
>>>pip install pandas>>>pip install sklearn
安装必要的库后,我们将使用 pandas 库导入数据集,并使用 sklearn 库执行数据集的划分

导入这些包后,我们会将我们的数据集从 csv 文件读取到 pandas 数据框