基于大模型的虚拟数字人__虚拟主播实例
本文目录:
一、技术的背景:
二、创意名称:
三、创意背景
四、创意目标
五、创意设计
六、技术实现路径
七、完整代码实现
八、创意总结
九、人工智能虚拟人物的一些优秀代表作品及其特点
十、参考范例:
很多时候,这世间有很多无奈,我们遇到很多难以理解的事情,为什么同样是人,怎么忍心做这样那样伤害人的事情?难道他们就没有给别人伤害过吗?自己如果淋过雨,就应该知道雨中的滋味,特别是冬日寒风里。
在我的世界里,我没有敌人,起码我是这样认为的,一直以来,我所遇到的人大都对我很好,他们不论彼此之间竞争什么,都从不把我牵扯进去,也不会让我知道一些不太好的事情。我知道,我从小到大都是很乖很单纯的好孩子,不会争也不会抢,所以了解我性格的人,都选择了不教坏我,感恩他们能让我一把年纪还像孩子一样没变。
但现实毕竟是现实,世界在变化,这种变化是巨变,我不可能老是依赖身边的人保护,依赖别人替我撑起一片相对简单的天空。
这。。。年以来,我在跌跌撞撞中成长,无论从科技知识面提升还是自我心理调整上,我都在长大,这种成长是反反复复在崩溃和自愈中磨练出来的,这期间依赖的是那些我视为珍宝收进“时光宝盒”里的回忆,一句温暖的话,我可以记一辈子。因为我知道生活不易,还能给与别人温暖并不是一件容易的事。当中的滋味只有自己心里清楚。
有些人,无论身份是什么,在岁月的流转中悄悄从你生命中退出,但在与不在,都会在你岁月中留下了华美的荏苒。不需太多,仅仅是一句话,一点面具后的恻隐,那份隐而不说的不舍,一句发自真切的关心话,在你落难时没有随大流狠踩一脚的义气,……岁月静好,念起便是温暖。点点滴滴,如缕缕阳光,温暖迷雾中的前程。
到现在我还是没变,依然保持着个人和内心的纯粹干净。世事变迁,很多东西都禁不起时间的考验,经历过的风景,或黑或白,装点着生活的诗意,叠加着光阴故事,偏偏又带着几行清泪。。。如果带着一份感激的心态去领悟,便是携了一款时光宝盒,将生命的本真化作阳光雨露……心情低落时,拿出来重新感受一下,可以驱散心中的阴霾。
以金相交,金耗则忘;以利相交,利尽则散;以势相交,势去则倾;以权相交,权失则弃;以情相交,情逝人伤;唯心相交,静行致远。
网上看到的别人的总结,记录一下:
上天不给你磨难,你又如何看透人心?
上天不给你失败,你又如何发现身边的人是假是真?
上天不给你孤独,你又如何反思自己?
上天不给你配上君子和小人,你又如何懂得去提高智慧?
不经受风雨,看不懂沧桑!逆境清醒
2023.6.19


基于大模型的虚拟数字人实例效果展示:
一、技术的背景:
基于大模型的虚拟人物生成: 大模型可以训练一个虚拟人物生成的系统,可以生成高质量的虚拟人物。
随着深度学习和图像处理技术的不断发展,基于大模型的虚拟人物生成技术近年来得到了迅猛的发展。 这种技术利用深度学习网络构建出大规模的虚拟人物生成模型,能够通过输入一些关键点或者草图,自动生成逼真的虚拟人物形象。
虚拟人物生成的系统技术的背景:
深度学习技术的突破。深度学习已经成为计算机视觉和图像处理领域的一种重要技术手段,神经网络模型能够自动从海量数据中学习特征和模式,通过模型训练,可以得到非常强大的图像处理能力。
3D建模技术的发展。随着3D建模技术的发展,越来越多的3D模型被制作和分享。而3D模型的制作需要大量的工作和时间,这促进了虚拟人物生成的需求,使得基于大模型的虚拟人物生成技术应运而生。
游戏和影视行业的发展。随着游戏和影视行业的不断扩展,人们对于逼真的虚拟人物形象的需求越来越高。而基于大模型的虚拟人物生成技术能够非常好地满足这种需求,因此受到了越来越多的关注和应用。
PaddlePaddle强大的开源生态和AI能力,支持虚拟数字人的开发。
PaddleSpeech将文字转换成语音,让虚拟数字人有了自己的声音。
PaddleGAN的人脸生成赋予了虚拟数字人一张可爱的脸蛋,表情迁移、唇形合成(同步)模型驱动虚拟数字人的脸部活动,让虚拟人更加栩栩如生。
PaddleHub已经把以上模型纳入了模型库当中,现在只需要简单的十几行代码调用模型,输入图片和文字,即可生成一个生动形象的虚拟数字人。
二、创意名称:
【大模型课程】虚拟主播|基于大模型的虚拟人物生成
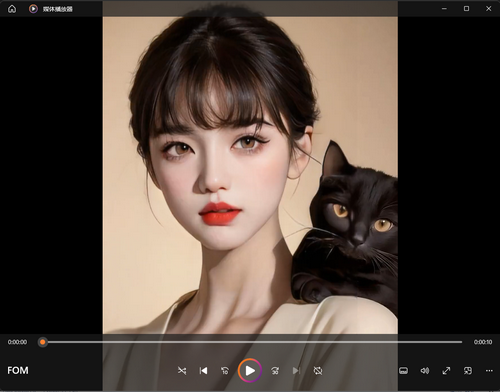
三、创意背景
创意背景
-
基于大模型的虚拟人物生成是一种人工智能技术,即使用深度学习算法训练庞大的数据集来创造高质量的虚拟人物或角色。
-
这种技术的创意背景可以是游戏开发、电影制作、虚拟现实、社交媒体、人机交互等领域。
-
该技术可用于创造真实感、表现力、交互性强的虚拟人物,进而拓展用户体验的多样化与个性化。
-
此外,基于大模型的虚拟人物生成技术也可应用于医疗、教育、劳动力、安防等领域,如建立智能机器人、模拟化医疗过程、提升教学效果等。
四、创意目标
基于大模型的虚拟人物生成的创意目标可能会因具体项目而异
数字人就是你在不同的电子产品、不同平台上的分身,代替你行人的职责。可以是:
-
【形象创作】:利用大模型生成虚拟人物,可以创造出各种不同类型的形象,如英雄、恶棍、美女、怪物等等,满足不同类型的故事或场景需求。
-
【角色动画制作】:通过大模型生成虚拟人物,可以制作出高质量的角色动画,使角色更加逼真、精细,增加观众的观感体验。
-
【游戏人物设计】:利用大模型生成虚拟人物可以为游戏制作高质量的人物设计,增加游戏的可玩性和吸引力。
-
【营销推广】:基于大模型的虚拟人物生成,还可以应用于营销推广领域,例如通过打造虚拟品牌形象、虚拟代言人来吸引消费者的注意力,提高品牌的知名度和影响力。例如售前、售后客服;
-
【电子导游】:电子导游是指利用现代科技手段,如无线通信、GPS定位、虚拟现实技术等,通过手机、平板电脑等移动设备实现,游客可以随时随地获取导游信息,为游客提供个性化、全方位、实时的旅游信息服务的一种新型导游方式。使用虚拟主播进行电子导游,游客可以更加深入地了解当地的文化、历史和风貌,增强旅游体验的趣味性和互动性。
-
【电子解说员】:虚拟电子解说员是一种人工智能技术,其目的是为了在虚拟世界或者数字化场景中提供语音解说服务。这些虚拟电子解说员能够为用户提供声音交互、信息查询、语音提示和实时指导等服务。虚拟电子解说员不仅可以用于游戏、虚拟现实、智能家居等领域,还可以用于公共场合、博物馆、展览等地方,为人们提供全方位的语音解说服务。虚拟电子解说员技术的应用将会越来越广泛,同时也将极大地促进数字化技术的发展和普及。
-
【虚拟老师】:虚拟老师是指利用虚拟现实、人工智能等技术仿真出的教学角色,担任在线教育平台、电子学习系统、智能辅导等教育应用中的教师角色,为学生提供在线学习、指导、评估等服务。虚拟老师可以根据学生的学习情况和需求,提供个性化的学习建议和策略,具有方便、高效、经济、普及的优势。
-
【虚拟前台指引】:前台是基于人工智能技术的虚拟形象,可以为客户提供便捷的服务和帮助。可以通过语音或文本输入方式提出需求,与虚拟前台进行交流。
五、创意设计
创意设计为创意的设计思路和效果演示,包括界面是如何操作的,创意运行逻辑,最终输入、输出的结果等。
只需要简单的十几行代码调用模型,输入图片和文字,即可生成一个生动形象的虚拟数字人。
虚拟人物形象可以由大模型生成,按自己实际需要生成不同性格和特征的虚拟形象。
-
【基于角色特征的人物生成系统】:该系统可以通过输入角色特征(如年龄、性别、身高、体型等)来生成符合特征的虚拟人物。可以应用于游戏开发、影视特效等领域。
-
【基于情感驱动的人物生成系统】:该系统可以通过输入情感(如快乐、悲伤、愤怒等)来生成符合情感的虚拟人物,可应用于虚拟主播、虚拟情感咨询等领域。
-
【个性化虚拟形象生成系统】:该系统可以通过输入用户信息(如兴趣、爱好、生活方式等)来生成符合用户个性的虚拟形象,可应用于社交娱乐、虚拟形象替身等领域。
-
【基于历史文化人物的虚拟生成系统】:该系统可以通过输入历史文化人物信息(如外貌、衣着、语言等)来生成符合历史文化人物特征的虚拟人物,可以应用于历史教育、文化旅游等领域。
这些创意设计可以通过大模型训练生成具有真实感和个性化的虚拟人物,为各行各业提供更多创意和应用空间。
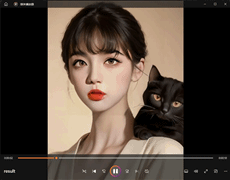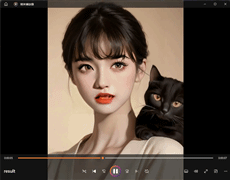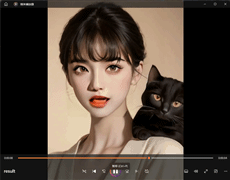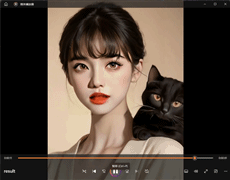
我用模型生成的虚拟人物形象举例图片(不同性别和特征):

最终输入:
除模型库外,还需要一个驱动视频,驱动视频可以按自己需要和喜欢自行配备,作为表情参考的对象
图片:
本例中,使用了一张图片(网络)作为示范,这张图片是本实例虚拟主播的模型。

文字内容:
本例中,使用了文本转语音的功能
文本内容: ['当困难悄悄地来临,我们不知所措艰难的前行,沧海桑田忘不了那信念,心若在我们还会站起来,勇敢向前任泪水划过容颜,擦干泪微笑着面对生活。']
输出的结果:
输入图片和文字,即可生成一个生动形象有自己的声音的虚拟数字人。
六、技术实现路径
技术实现路径是创意提案最重要的组成部分,需要依据创意设计的逻辑和实际创意搭建的过程,阐述技术细节。
📖 技术原理
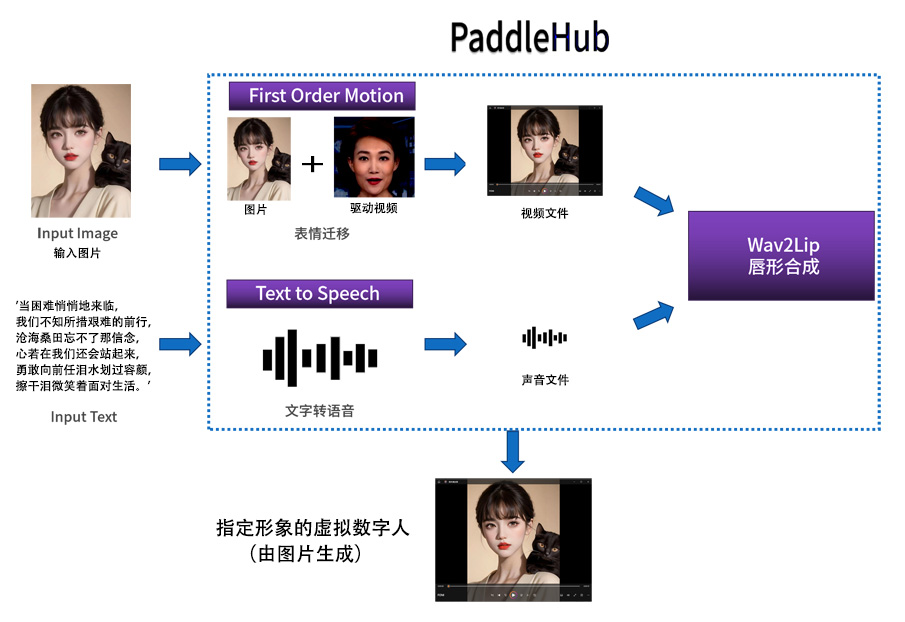
📖 技术实现过程
-
【数据收集】:首先需要收集大量的数据,包括图像、语音、姿势、行为等各种类型的数据。这些数据可以来自各种来源,如公共数据集、社交媒体、游戏、虚拟现实等。
-
【数据预处理】:对数据进行预处理,包括数据清洗、去噪、标注、对齐等。这些预处理步骤将有助于提高模型的精度和鲁棒性。
-
【模型训练】:选择适当的神经网络结构,如生成对抗网络(GAN)、变分自编码器(VAE)等,并使用收集的数据进行模型训练。由于大模型所需的计算和存储资源较多,可以考虑使用分布式计算或云计算来加速训练和优化模型。
-
【模型优化】:在训练模型的过程中,需要进行模型调优和超参优化,以提高模型的性能和准确性。这需要进行多次实验和测试,以找到最优的模型配置和超参数。
-
【虚拟人物生成】:通过模型生成虚拟人物的图像、声音、行为等,可以使用混合现实技术、虚拟现实技术等来将生成的虚拟人物与现实世界进行交互和展示。
-
【模型迭代和更新】:由于虚拟人物的需求和应用场景不断变化,在实际使用中,需要不断迭代和更新模型,以保持模型的准确性和实用性。
拟数字人生成总共需要调用三个模型,分别是:
- First Order Motion(表情迁移)、
- Text to Speech(文本转语音)
- Wav2Lip(唇形合成)。
- 辅助的第四个就是闲聊式对话机器人,或者是一个对话系统。
具体技术步骤如下:
- 把图像放入First Order Motion模型进行面部表情迁移,让虚拟主播的表情更加逼近真人。
- 通过Text to Speech模型,将输入的文字转换成音频输出。
- 得到面部表情迁移的视频和音频之后,通过Wav2Lip模型,将音频和视频合并,并根据音频内容调整唇形,使得虚拟人更加接近真人效果。
下面是一个示例代码,用于训练一个ResNet模型来进行人物特征提取。
import torch.nn as nn
import torch.optim as optim
import torchvision.models as models# 定义数据集和数据加载器
dataset = MyDataset(...)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 定义模型
model = models.resnet18(pretrained=True)
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 256)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(10):for inputs, targets in dataloader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()
七、完整代码实现
# 升级PaddleHub
!pip install --upgrade paddlehub# 下载nltk_data
!wget https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf nltk_data.tar.gz# 安装ParaKeet
!git clone https://github.com/PaddlePaddle/Parakeet ./home/aistudio/Parakeet
!unzip Parakeet.zip
%cd Parakeet/Parakeet-develop/
!pip install -e .# 安装依赖
import paddlehub as hub
!hub install first_order_motion==1.0.0
!hub install wav2lip
!hub install fastspeech2_baker==1.0.0
!pip install typeguard==2.13.3FOM_Module = hub.Module(name="first_order_motion")
FOM_Module.generate(source_image="input_data/girl1.jpg", # 输入图像driving_video="input_data/qd.mp4", # 输入驱动视频ratio=0.4, image_size=256, output_dir='./output/', # 输出文件夹filename='move1.mp4', # 输出文件名use_gpu=True)# 文本转语音 输入你想让虚拟数字人说的话,转换生成一段音频。
import paddlehub as hub
sentences = ['当困难悄悄地来临,我们不知所措艰难的前行,沧海桑田忘不了那信念,心若在我们还会站起来,勇敢向前任泪水划过容颜,擦干泪微笑着面对生活。'] # 输入说话内容
TTS_Module = hub.Module(name='fastspeech2_baker',version='1.0.0')
wav_files = TTS_Module.generate(sentences)
print(f'声音已生成,音频文件输出在{wav_files}')#唇形合成
#把刚刚得到的动态视频和音频文件输入到Wav2Lip模型中,让唇形根据说话的内容动态改变。
import paddlehub as hub
W2F_Module = hub.Module(name="wav2lip")W2F_Module.wav2lip_transfer(face='output/move1.mp4', audio='wavs/1.wav', output_dir='./transfer_result/', use_gpu=True) 八、创意总结
创意总结一般阐述创意的总体效果,创作过程中的成长,当前内容的不足以及未来改进的规划。
基于大模型的虚拟人物生成技术是一项创新性的技术,可以构建高度精细、逼真的虚拟人物模型,进而应用于游戏、电影、影视特效等领域。
以下是一些基于大模型的虚拟人物生成技术的创意总结:
-
构建高度逼真的虚拟人物角色,以提高游戏的互动体验和游戏的视觉效果。
-
利用虚拟人物来进行影视拍摄,大大降低拍摄成本和风险,并提高制作效率和制作质量。
-
将虚拟人物生成技术应用于医学领域,可以用来模拟治疗过程、进行手术模拟等,有助于提高医疗水平与技术水平。
-
将虚拟人物技术应用于教育领域,可以帮助学生更容易理解知识点,提高学习效率和质量。
-
将虚拟人物技术应用于社交领域,可以构建更加逼真的虚拟社交场景,增强社交体验和互动性。
总之,基于大模型的虚拟人物生成技术的应用领域非常广泛,未来还有很大的发展潜力。
本实例总结:
- 虚拟数字人精度跟3D模型的数字人对比有明显差距。
- 虚拟数字人替换头像使用大头贴或对最终效果有可能提升。
- 虚拟数字人成本比专业的动作捕捉设备便宜。
- 虚拟数字人依靠一张图片和算法直接生成,简单快捷,适用要求不太高的场合。
九、人工智能虚拟人物的一些优秀代表作品及其特点
以下是人工智能虚拟人物的一些优秀代表作品及其特点:
| 作品名称 | 代表角色 | 特点 |
|---|---|---|
| Siri | 苹果公司 | 智能语音助手,能回答问题、执行命令、发送信息等 |
| Cortana | 微软公司 | 智能语音助手,类似Siri,但更加个性化,能获取更多的信息并预测用户需求 |
| Watson | IBM公司 | 人工智能平台,能进行自然语言处理、机器学习和数据分析等任务 |
| Xiaoice | 微软中国 | 语音交互式人工智能机器人,能扮演聊天伴侣、情感陪伴和知识助手等角色 |
| Replika | Luka公司 | 基于聊天机器人技术的虚拟人物,能模拟人类情感和思维,通过聊天与用户建立情感连结 |
| Mitsuku | Pandorabots公司 | 多次获得Loebner人工智能对话竞赛冠军的聊天机器人,能与用户进行自然语言对话并提供各种服务和功能 |
| Erica | 株式会社人工智能(日本) | 由大量对话数据训练而成的人工智能虚拟人物,能模拟人类情感和行为,被称为“最人性化”的机器人 |
| GPT-3 | OpenAI | 自然语言处理模型,具有惊人的语言生成能力,能够产生连贯、逻辑的自然语言文本 |
| AvatarMind Robot | AvatarMind公司 | 拥有机器视觉、语音识别、自然语言处理和运动控制等多种功能的机器人,被称为“智慧之脑机器人”。 |
以上仅列举了一部分优秀的人工智能虚拟人物代表作品,随着技术的发展,未来还会有更加先进的人工智能虚拟人物诞生。
十、参考范例:
本文参考了以下文章,个人学习所用。感谢。
PaddleHub元宇宙直通车:手把手教你造个虚拟数字人! - 飞桨AI Studio



![前沿重器[35] | 提示工程和提示构造技巧](https://img-blog.csdnimg.cn/img_convert/7e58021e19c2a1fd75a3989cf3729549.png)