一、概述
title:Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge
论文地址:https://arxiv.org/abs/2305.01651
相关代码:
- EKP数据和代码:GitHub - yasumasaonoe/entity_knowledge_propagation
- MEND: Model Editing Networks using Gradient Decomposition:GitHub - eric-mitchell/mend: MEND: Fast Model Editing at Scale
1.1 Motivation
- 如何在预训练模型中引入最新的知识并验证模型能否对注入的知识进行推理呢?之前的模型编辑的方法注入知识只评估模型是否能复现原有知识,没有评估是否能对注入的知识进行推理。
1.2 Methods
- 通过两个完型填空任务来做这个实验
-
- 存在真实世界的的一个新实体数据集ECBD,以及简化版本easy-ECBD。
- 一个新的人工设置的模板的benchmark,需要对注入的知识进行各种级别的推理。
- 通过参数更新的方法以及非参数更新的方法来对比有效性
-
- 参数更新
-
-
- fine-tuning(全部参数 or 最后一层)
- MEND:通过新数据,一次性更新参数的方法
- ROME:先拿到某个新实体k的特征v,然后按照新实体的信息修改v,对其进行参数更新,学习新的知识
-
-
- 非参数更新
-
-
- in-context learning方法:不改变模型参数,直接将信息拼接到probe探针上
-
1.3 Conclusion
- 基于梯度的fine-tuning方法对注入的知识推理能力比较差,只当lexical重叠比较大才有提升。
- 直接将实体定义信息预先加到上下文(in-context-learning)获得了持续的提升,说明通过参数更新来注入知识还有很大的研究空间。
1.4 limitation
- 实验还考虑的不够全,因为某些实体的更新可能会牵扯到非常多其他实体,这里没有考虑这类实体。
- 只在英语上做了实验。
- 还需要尝试更大的模型和最新的一些参数更新的方法。
二、大纲

三、详细内容
1 评估是否能对引入的知识进行推理

- 参数说明
-
- <e, de, xe, ye>
- e: 新实体
- de: 新实体e定义的句子
- xe:probe 探针,用于检查是否注入知识
- ye: xe的理想答案
- 知识编辑的方法是在原来的参数上,通过添加e,de来更新新的参数,即: θ′ ← update(θ, e, d )
- prior work
-
- 直接对注入的知识进行提问
- this work
-
- 不直接提问,根据注入的知识进行推理性质的提问
2 评测数据集说明
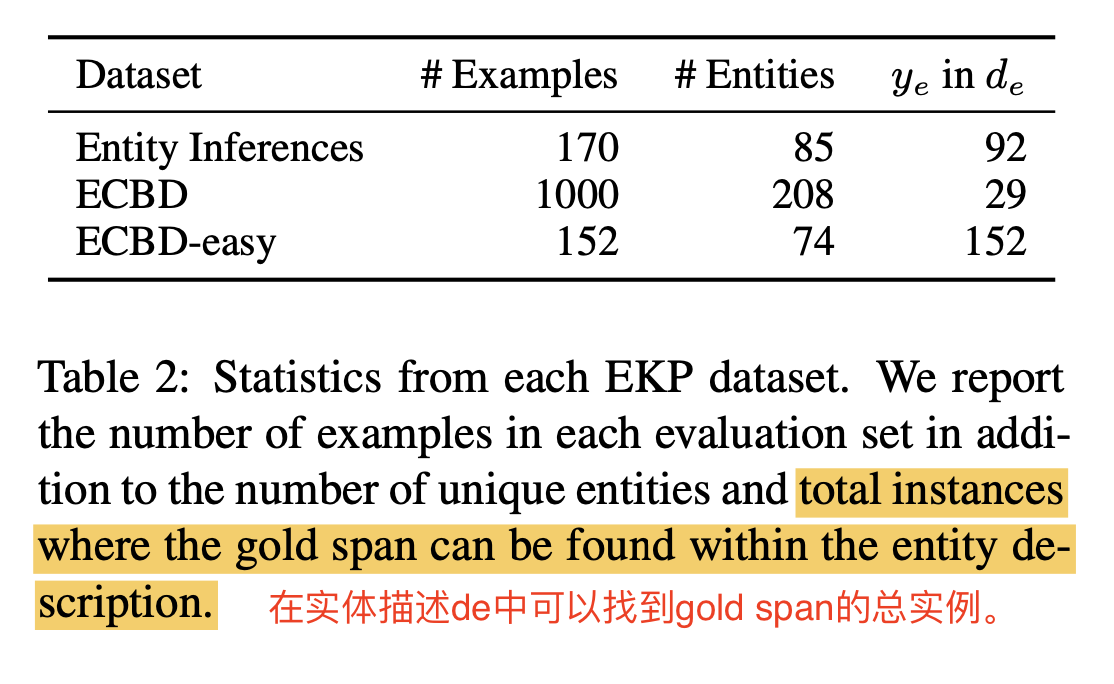
- ECBD
-
- 重新根据更新时间来组织ECBD数据集,这样来评估知识的的更新情况
- e:wikipedia的实体词
- definition:一般是wikipedia的第一句话
- xe:探针句子,在wikipedia页面里main选出来的
- goldspan:target span
- ECBD-EASY
-
- 从ECBD中挑选了一个简单的子集,其他definition句子de包含了target masked span y
- 之前的MEND方法就是这种方式来做的,任务更简单
- 评估方法:困惑度(由于tokenizer的不同,不同模型不好比较困惑度)
- ENTITY INFERENCES
-
- ECBD任务还是非常难,人类来做都非常难,需要非常多的知识和推理,为了更好控制的研究知识推理,构建了该数据集
- 该数据集选择正确的span变得简单,相对于直接生成span,这里把它作为多选题
- 两种推理类型
-
-
- explicit:比较明确的,问的问题就在definition中
- implicit:需要一些commonsense信息
-
-
- 评估方法:accuracy 准确率 + specificity score 特异性
3 对比实验(参数更新方法以及incontext learning方法)
不同的模型架构可能对注入的知识也有影响,所以考虑了left-to-right以及seq-to-seq的架构,使用了GPT-Neo(1.3B)、T5-large、GPT2-XL(和ROME做比较)。
- Finetuing
-
- left-to-right模型(GPT-Neo):在de(定义描述)的数据上做next token prediction
- filling models(T5):随机选择span来mask,注意不与entity重叠
- 采用两种fine-tuning模式,更新全部参数或者last layer的参数
- MEND(没咋看懂)
-
- MEND(Mitchell et al., 2022)可以被视为一种超网络,它有效地将原始微调梯度转换为一次成功编辑基础模型参数的参数更新。这种方法旨在注入或编辑关于实体的单个事实,而不是一组关于实体的事实(即,一个完整的定义所包含的实体知识)。MEND参数在编辑数据集上进行训练,其中每个示例都包括输入-输出对、修改后的输出和局部性示例(用于测量敏感性)。MEND训练的目标是学习一个网络,该网络可以在不影响未修改的事实的情况下修改目标事实。
- 爱可可AI前沿推介(10.23) - 知乎解读:大规模模型快速编辑。虽然大型预训练模型在各种下游任务上取得了令人印象深刻的结果,但最大的现有模型仍然会出错,甚至准确的预测也会随着时间的推移而变得过时。因为在训练时检测出所有这些错误是不可能的,所以让这些模型的开发者和终端用户能够纠正不准确的输出,同时保持模型的完整性是很有意义的。然而,大型神经网络所学习的表示的分布式、黑箱性质使得产生这种有针对性的编辑很困难。如果只有一个有问题的输入和新的期望输出,微调方法往往会过拟合;其他的编辑算法要么在计算上不可行,要么在应用于非常大的模型时根本没有效果。为了大规模实现简单的事后编辑,本文提出梯度分解模型编辑网络(MEND),一种小型辅助编辑网络的集合,使用单一期望输入-输出对,对预训练模型进行快速的局部编辑。MEND学习对通过标准微调获得的梯度进行转换,用梯度的低秩分解来使这种转换的参数化变得可行。即使是100亿以上的参数模型,MEND也可以在一天之内在单GPU上完成训练;一旦训练完成,MEND就可以快速应用新的编辑到预训练的模型上。对T5、GPT、BERT和BART模型的实验表明,MEND是唯一能对具有几千万到一百多亿参数的模型进行有效编辑的方法。
- ROME
-
- 通过将MLP视为键值存储年龄来执行知识编辑:它使用一个主题(如埃菲尔铁塔)来提取MLP中与该主题相关的“价值”。然后,它使用对MLP权重的一级修改来“重写”这个键值对。
- in-context
-
- 将definition加在probe的后面
4 实验结论
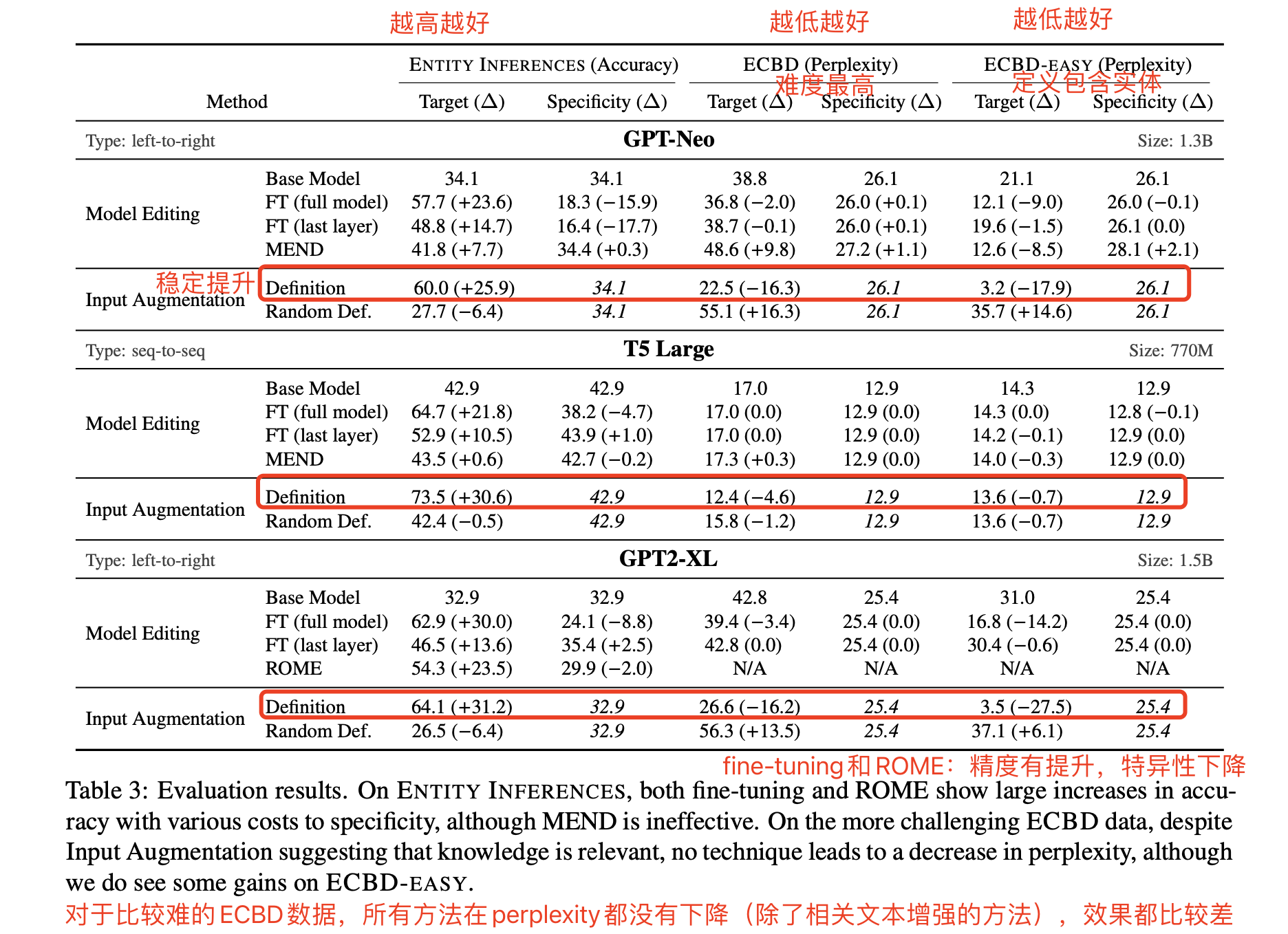
- 总结:
-
- finue-tuning方法,参数修改的方法,整体比较拉垮,MEND,ROME方法的模型在准确率有一定提升,但是有一些也牺牲了特异性,困惑度MEND方法甚至在GPT-Neo上还上升了
- (in-context learning)输入增强的方法,也只有在输入相关的文本下有提升,输入不相关的文本下效果也是变差的













![前沿重器[35] | 提示工程和提示构造技巧](https://img-blog.csdnimg.cn/img_convert/7e58021e19c2a1fd75a3989cf3729549.png)

